Parameter Learning (Gradient Desent)
- cost function을 최소하하기 위해 이용할 수 있는 방법 중 하나
Gradient Descent의 전략
- start with some 0, 1 (say 0=0, 1=0)
- keep changing 0, 1 to reduce J(,) until we hopefully end up at minumum

1) : Learning rate
- 얼마나 크게 이동할지 결정
- 너무 크면 발산
- 너무 작으면 학습이 매우 느림
2) : Cost Function
- 예측값과 실제값의 오차
3) : 편미분 (partial derivative)
-
편미분은 함수가 여러 변수를 가질 때 사용 예) z=
-
를 조금 바꿨을때 Cost Function J 가 얼마나 변하는지를 나타내는 기울기(gradient)
-
- 이 기호는 편미분(partial derivative)을 의미
-
일반 미분 기호는 , 하지만 변수가 많이 있을 때는
의 의미를 쉽게 쓰면 "에 대해 편미분을 하라, 다른 변수들은 고정하고 만 변화시키면서 미분하라"는 것
주의할 점 - parameter들을 한번에 업데이트 해야 함. 만약 0을 먼저 업데이트하여 hypothesis가 바뀌고 숫자를 대입해 1을 구하면 예상치 못한 문제가 발생할 수 있다.
Learning rate (알파)
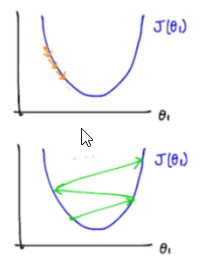
만약 Learning rate이 너무 작으면 수렴하는데에 오래걸리는 문제가 생기고, 너무 크면 최소값에 이르지 못해 수렴하지 못하거나 심지어 지나쳐 버리는 발산 문제가 일어날 수 있다. 그러므로 적절한 Learning rate을 고르는 것이 중요하다.
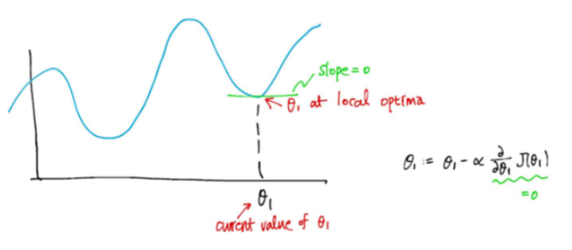
Gradient descent가 local optima (slope = 0)에 이르면 편미분항이 0이 되므로 더이상 업데이트 되지 않는다.
Learning rate은 직접 실행하여 적절한지 아닌지 판단할 수밖에 없는가?
: 파라미터
: Learning rate
: gradient
발산방지방법
1) Learning rate을 작게 시작
일반적인 경험값:
| 모델 | 초기 LR |
|---|---|
| 선형 모델 | 0.01 |
| 딥러닝 | 0.001 |
| Adam optimizer | 0.001 |
2) Learning Rate Scheduler
훈련 중에 learning rate을 점점 줄이는 방법
3) Adaptive Optimizer
learning rate을 자동으로 조절하는 알고리즘
- Stochastic Gradient Descent
- Adam Optimizer
- RMSProp
4) Gradient Clipping
gradient가 너무 커지면 강제로 제한
5) Feature Scaling
데이터가 스케일이 다르면 gradient가 폭발할 수 있음
그래서 Feature Scaling, Standardization 을 사용 (스케일을 맞추기 위해)
6) Loss 모니터링
예제 - Pytorch: Autograd
Autograd는 자동으로 미분을 구해주는 패키지
- 모든 gradient를 구하려면 backward() method를 사용.
- Gradient 계산의 출발점은 loss.
- 그러므로 loss.backward()와 같이 해당 변수로부터 backward() 메서드를 invoke 한다.
Gradient는 accumulate 되므로(이전 gradient + 새 gradient -> 이렇게 되지 않도록 ), parameter 업데이트에 gradient를 사용하고 나면 항상 0으로 만들어야 함 (zero_() 메서드 사용). 그래야 다음번 그라디언트는 업데이트된 gradient로 사용할 수 있기 때문.
학습 루프에서는 항상 아래 코드가 필요:
optimizer.zero_grad()
또는
model.zero_grad()
-
In PyTorch, every method that ends with an underscore (_) makes changes in-place.
-> PyTorch에서 함수 이름 끝에 _가 붙으면 원래 데이터를 직접 수정한다. -
torch.no_grad()
- syic computation graph와 혼동되지 않고 일반 python 연산을 tensor에 수행할 수 있도록 하기 위해...
- gradient 계산을 하지 말라는 뜻
- 예를 들면 evaluation 과정에 쓰임, evaluation에는 학습 과정이 필요 없기에.
lr = 1e-1
n_epochs = 1000
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error**2).mean()
with torch.no_grad():
a -= lr * a.grad
b -= lr * b.grad
a.grad.zero_()
b.grad.zero_()예제 - Pytorch: Optimizer
만약 parameter 갯수가 아주 많다면?
Pytorch의 SGD나 Adam과 같은 optimizer를 써서 쉽게 해결할 수 있다.
Optimizer는 update할 parameter와 learning rate 및 여러 다른 hyper-parameter를 받아 step() 메서드를 통해 업데이트 한다.
Gradient를 0으로 만드는 것도 optimizer의 zero_grad() 메서드가 해결해 준다.
import torch.optim as optim
optimizer = optim.SGD([a, b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
error = y_train_tensor - yhat
loss = (error ** 2).mean()
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(a,b)| 코드 | 의미 |
|---|---|
b.grad.zero_() | 특정 파라미터 하나의 gradient만 0으로 초기화 |
model.zero_grad() | 모델 전체 파라미터의 gradient 초기화 |
optimizer.zero_grad() | optimizer가 관리하는 모든 gradient 초기화 |
예제 - Pytorch: Loss
Pytorch는 여러가지 loss function을 제공. regression 문제를 위해서는 mean-squared error (MSE) loss 가 적절
torch.nn.MSELoss:
https://docs.pytorch.org/docs/stable/generated/torch.nn.MSELoss.html#torch.nn.MSELoss
import torch.nn as nn
loss_gn = nn.MSELoss(reduction='mean')
optimizer = optim.SGD([a,b], lr=lr)
for epoch in range(n_epochs):
yhat = a + b * x_train_tensor
loss = loss_fn(y_train_tensor, yhat)
loss.backward()
optimizer.step()
optimizer.zero_grad()