머신러닝이란?
이전의 머신 러닝은 인간이 기계에 직접 어떤 값이 들어갔을 때의 바른 출력값을 프로그래밍 하는 것이었으나 이는 한계가 있음. 그리하여 기계가 스스로 어떤 패턴을 학습하도록 하는 접근법이 등장
Arthur Samuel의 머신러닝 정의(1995)
Field of study that gives computers the ability to learn without being explicitly programmed.
데이터 베이스 마이닝
수동으로 작성할 수 없는 프로그램
스스로 커스터마이징 하는 프로그램
사람의 학습을 이해하는 것 (brain, real AI)
Tom Mitchelle의 정의
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improvied with experience E.
머신 러닝은 일단 적으로 두가지 범주로 구분됨.
- supervised learning
- unsupervised learning
Supervised learning (지도 학습)
특정 인풋에 대해 정답(label) 아웃풋이 있는 데이터셋이 주어지는 경우를 말함
-
regression: 회귀의 아웃풋은 연속적인 값을 갖는다. 즉 주어인 인풋 변수에 대응하는 어떤 연속함수를 찾는 과정 ex) 집의 넓이에 해당하는 적절한 집값을 추정
-
classification: 아웃풋이 discrete한 값을 가짐. 미리 정의 되어 있는 어떤 카테고리에 속하는지 찾아내는 것 ex) 종양이 악성인지 양성인지 진단하는 문제
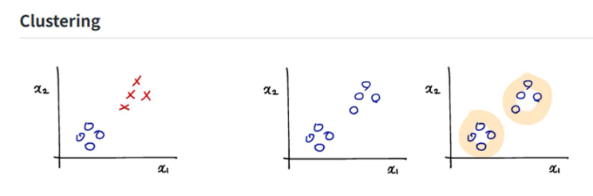
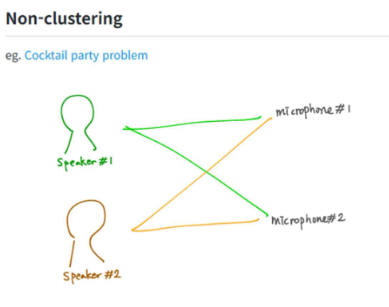
Unsupervised learning (비지도 학습)
Prediction result에 대한 정답(label)을 제공하는 데이터 셋이 없는 경우
이 경우에는 가지고 있는 데이터의 변수들 간의 관계에 기반한 clustering으로 어떤 구조를 도출해낸다.
선형회귀분석
linear regression은 어떤 인풋에 대한 실수의 output을 예측하는 문제
아래의 예시에서는 cost function과 gradient descent 학습법을 사용
예)
https://www.kaggle.com/datasets/threnjen/portland-housing-prices-sales-
jul-2020-jul-2021
어떤 사람이 집의 넓이에 따른 집값을 기준으로 집을 찾으려할 때
이 경우 사전에 수집한 집값 정보라는 정답이 존재하므로 sueprvised learning 이고 추정하는 값이 실수값이므로 regression problem. 선형의 관계가 성립하면 linear regression.
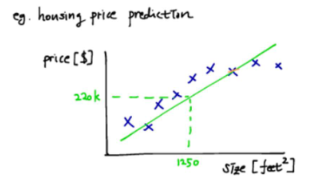
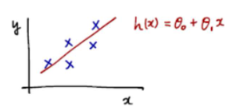
Linear regression은 바로 주어진 데이터를 나타내는 최적의 직선을 찾아냄으로써 input(x)와 output(y)의 사이의 관계를 도출해내는 과정
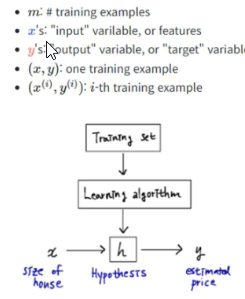
가설의 값을 h function에 넣어서 얼마나 y 값에 가까운지 본다.
Hypothesis 란? (단변량/다변경 선형회귀분석)
input (feature) 과 output(target)의 관계를 나타내는 함수. 모든 변수들을 고려하고 그 변수들 같의 복잡한 방정식을 찾는 대신, 주로 이러 이러한 변수들이 output에 영향을 미칠 거야 라고 추정하고 일종의 가설을 세운다. Hypothesis h는 어떤 함수의 형태든 취할 수 있지만 linear 함수를 자주 사용한다.
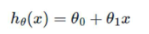
x는 실수값을 취하는 1차원 랜덤변수. 이와 같이 한가지 feature를 이용한 linear regression. 을 "univariate linear regression" 이라고 부르기도 함
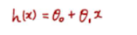
를 구하는데 일단 아무 숫자나 넣어서 계산을 해보면 실제 y 값과 계산값을 비교하면 에러값(빗나간 값)을 구할 수 있다. 여러가지 값들을 시도하여 값을 가장 잘 대표하는 직선을 찾아내는 것이다.
예)
(정확도 측정을 위한) cost function
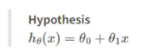
간략히 h(x)라고 표기할 때 세타들은 parameter라고 한다.
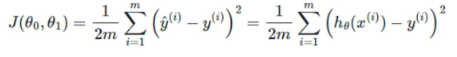
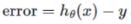
가 최소값을 갖는 것을 찾는다.
위 식에서 이 값이 음수도 양수도 될 수 있기때문에 제곱하였고, data 갯수인 m으로 나누어 평균을 찾아야 하기에 계산 상의 편의를 위해 2를 넣어 2m으로 나눈다.
예시)

hypotehsis를 단순화 하여 살펴보기)
세타0 = 0으로 설정하면 hypothesis는 원점을 지나는 직선이 됨
그리고 트레이닝 데이터도 (1,1), (2,2), (3,3)으로 설정

세타의 cost function 값들을 그래프로 그려보면 포물선 모양이 된다. 여기서 최저값을 찾는다.
이 경우 파라미터 세타1 = 1이 최적의 값이된다.
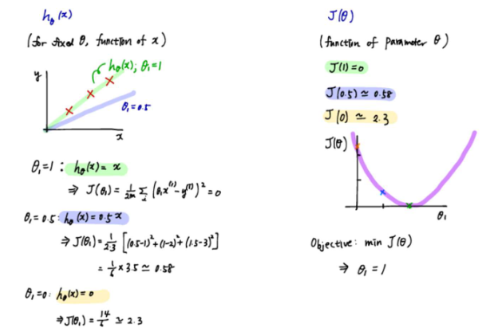
univariate linear regression 일반형
cost function의 그래프를 완성할 수 있지만, 이번에는 변수가 2개 이므로 세타0, 세타1에 따라 크기가 변하는 3차원 그래프가 될 것이다. (그림에서 오른쪽)
예제 코드
1. Data generation
import numpy as np
import matplotlib.pyplot as plt
#data generation
np.random.seed(42)
x = np.random.rand(100, 1)
y = 1 + 2 * x + 1 * np.random.randn(100, 1)
#shuffles the indices
idx = np.arange(100)
np.random.shuffle(idx)
#use first 80 random indices for train
train_idx = idx[:80]
#use the remaining indices for validation
val_idx = idx[80:]
#Generates train and validation sets
x_train, y_train = x[train_idx], y[train_idx]
x_val, y_val = x[val_idx], y[val_idx]
#plot
fig, ax = plt.subplots()
ax.scatter(x_train, y_train, color='C0', label='train', alpha=0.5)
ax.scatter(x_val, y_val, color='C1', label='validation', alpha=0.5)
ax.legend()
ax.grid(True)
fig.show()
data를 train과 validation으로 나누는 이유
Validation set에서 train에 사용하지 않은 데이터를 사용하여 이 모델이 처음 보는 데이터에도 잘 맞는지 확인.
train만 사용하게 되면 모델이 데이터를 외워버릴 수 있기때문에 validation set이 필요하며, 이와 같이 데이터를 외워버리는 것을 Overfitting (과적합) 이라고 한다.
보통 train 70~80%, validation 20~30%
왜 셔플을 하는가
데이터 순서가 일정 규칙을 따라서 배열되어 있을 수 있으므로 한 쪽으로 치우친 데이터를 학습하지 않도록 셔플.
seed(42)의 비밀
랜덤 값은 진짜로 랜덤하지 않고 재현 가능한 값을 생성하기 위해(시드 없이는 매번 다른 값이 생성됨) 시드 값을 줘야하는데 아무 숫자나 상관없지만 42가 유명. The Hitchhiker's Guide to the Galaxy에서 "삶, 우주, 모든 것의 답은 42" 라는 농담이 나오는데 거기서 왔다고 한다.
2. Linear Regression with Numpy
np.random.seed(42)
a = np.random.randn(1)
b = np.random.randn(1)
print(a, b)
#Sets learning rate, 이동하는 보폭(step size), 모델이 틀렸을 때 0.1 만큼 업데이트
lr = 1e-1
#Defined number of epochs, 학습 반복 횟수
n_epochs = 1000
for epoch in range(n_epochs):
#Compute our model's predicted output
yhat = a + b * x_train
# How wrong is our model? That's the error
error = (y_train - yhat)
# It is a regression, so it computes mean sqared error (MSE)
loss = (error ** 2).mean()
#Computers gradients for both "a" and "b" parameters, loss를 미분하면 아래와 같이 됨
a_grad = -2 * error.mean()
b_grad = -2 * (x_train * error).mean()
# Updates parameters using gradients and the learning rate,
# "- lr * gradient" 를 하는 이유는 loss의 반대(-)방향으로 이동하기 위함
a = a - lr * a_grad
b = b - lr * b_grad
print(a, b)
#위는 넘파이를 이용하여 수동으로 구현한 것이고, 아래는 같은 내용을 sklearn을 이용하여 구현
#Sanity Check: do we get the same results as out gradient descent?
from sklearn.linear_model import LinearRegression
linr = LinearRegression()
linr.fit(x_train, y_train)
print(linr.intercept_, linr.coef_[0])
[0.49671415] [-0.1382643]
[1.23540769] [1.68964442]
[1.23540755] [1.6896447]텐서(Tensor)
딥 러닝에서 사용하는 기본적인 데이터 구조
스칼라 - 0차원 텐서
벡터 - 1차원 텐서
행렬 - 2차원 텐서
텐서 - 고차원
PyTorch 텐서는 numpy arrary와 사실상 다를 것이 없다. 그러나 Numpy array와의 다른 점은 CPU와 GPU에서 모두 동작할 수 있다는 점이다.
3. Numpy array를 tensor로 변환
from_numpys는 CPU tensor를 returnm, GPU를 사용하고 싶으면 to() (cuda or cuda:0)
GPU 쓸 수 있는지 판별: cuda.is_available()
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x_train_tensor = torch.from_numpy(x_train).float().to(device)
y_train_tensor = torch.from_numpy(y_train).float().to(device)다시 numpy array로 변환: 그러나 numpy는 GPU tensor를 직접 다룰 수 없기 때문에 먼저 'cpu()'
x_train_numpy = x_train_tensor.cpu().numpy()4. Loading Data, Devices, and CUDA
Data용 tensor와 parameter/weight 용 tensor는, 후자 parameter/weight 용은 gradient 계산을 해서 update할 수 있어야 한다는 점에서 다르다.
그러므로 requires_grad=Ture argument가 사용된다.
주의할 점은 먼저 device로 보내고 requiresgrad() 메서드를 사용해야 한다는 것이다.
Bad example
a = torch.randn(1, requires_grad=True, dtype=torch.float).to(device)
b = torch.randn(1, requires_grad=True, dtype=torch.float).to(device)Working example
a = torch.randn(1, dtype=torch.float).to(device)
b = torch.randn(1, dtype=torch.float).to(device)
# and THEN set them as requiring gradients...
a.requires_grad_()
b.requires_grad_()
print(a, b)tensor를 만들면서 동시에 device에 할당하는 것이 가장 좋다.
Good example
a = torch.randn(1, requires_grad=true, dtype=torch.float, device=device)
b = torch.randn(1, requires_grad=true, dtype=torch.float, device=device)
데이터용 tensor와 파라미터/가중치 tensor
머신러닝/딥러닝 프레임워크에서는 데이터 텐서와 파라미터 텐서를 명확히 구분. 역할과 gradient 처리 방식이 완전히 다르기 때문.
| 구분 | 데이터 텐서 | 파라미터(가중치) 텐서 |
|---|---|---|
| 의미 | 학습에 사용하는 입력 데이터 | 모델이 학습해야 하는 값 |
| 예 | x, y | W, b |
| gradient 계산 | 보통 필요 없음 | 반드시 계산 |
| 업데이트 | 하지 않음 | optimizer가 업데이트 |
예) y = Wx + b
x -> 데이터 텐서
W, b -> 파라미터 텐서
