앙상블 모델 - voting ensemble 구조
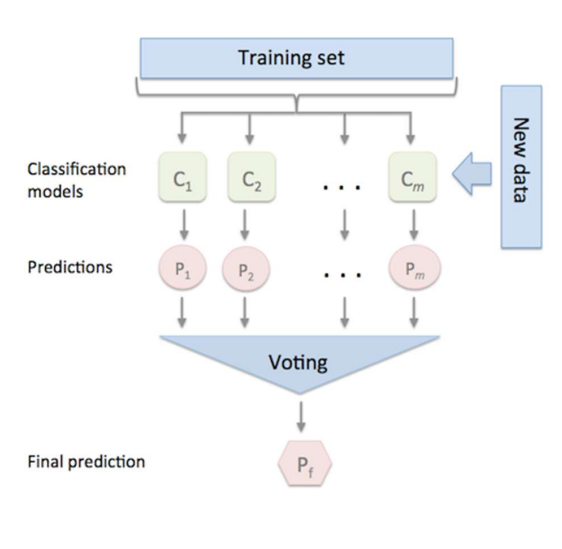
여러 개의 분류 모델이 각각 예측하고, 마지막에 다수결(또는 평균)로 최종 예측을 내리는 방식
- 하나의 데이터(train set)로 여러 모델을 학습시키고, 각 모델의 예측을 모아서 최종 예측을 더 안정적으로 만드는 방법
1) Training set
전처리/EDA/피처 엔지니어링을 거친 후 모델 학습에 넣는 데이터
X = features
y = target (credit)
2) Classification models
C1, C1 ... Cm
C들은 서로 다른 분류 모델로 예를 들면...
C1 = Logistic Regression
C2 = Random Forest
C3 = XGBoost
...
3) Predictions
각 모델이 학습 후에 예측을 내놓음.
P1, P2 ... Pm
4) Voting
각 모델의 예측을 "투표"로 합쳐서 최종 결과를 정함
5) Final prediction
맨 아래의 Pf -> 최종 예측 결과
앙상블을 쓰는 이유
단일 모델보다 더 안정적이고 성능이 좋은 경우가 많기 때문
Voting의 두 가지 방법**
1) Hard Voting (다수결 투표)
각 모델이 최종 클래스(label)를 바로 예측하고, 그 중 가장 많이 나온 클래스를 선택하는 방식
2) Soft Voting (확률 평균)
각 모델이 클래스별 확률(probability)을 내놓고, 그것을 평균 내서 최종 클래스를 정하는 방식.
앙상블 모델의 장점과 단점
장점:
- 성능 향상 가능성: 단일 모델보다 좋을 수 있음
- 예측 안정성 증가: 한 모델의 실수를 다른 모델이 보완할 수 있음
- 과적합 완화 가능성: 특정 모델 하나에 과하게 의존하지 않음
단점:
- 학습 시간 오래 걸림
- 해석이 어려워 짐: 왜 이 예측이 나왔는지 설명이 더 어려워짐
- 잘못 섞으면 오히려 별 차이 없을 수 있음
앙상블 모델 - Bagging (Bootstrap Aggregating)
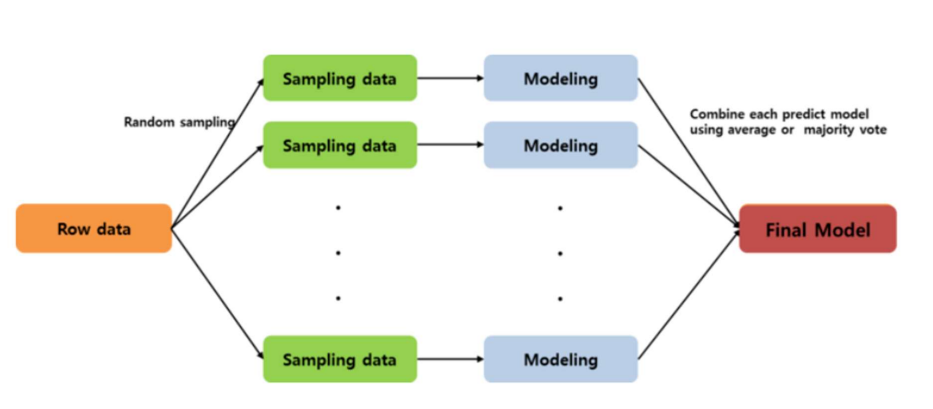
원본 데이터에서 여러 개의 샘플 데이터를 랜덤하게 뽑아 각각 모델을 만들고, 마지막에 예측을 합치는 방식 (같은 데이터에서 여러 번 랜덤하게 다르게 뽑아서 여러 모델을 학습시키고, 그 결과를 평균/다수결로 합쳐서 더 안정적인 최종 모델을 만드는 방법)
왜 굳이 여러번 샘플링하나?
한 모델만 만들면 그 모델이 우연히 특정 데이터 패턴에 치우칠 수 있음
그래서
- 어떤 샘플에서는 조금 다르게 학습하고
- 또 어떤 샘플에서는 또 다르게 학습하게 해서
개발 모델의 불안정성(variance)을 줄일 수 있다.
Final Model
마지막에 하나의 결과로 합치는 것
회귀(regression)이면 -> 평균
분류(calssicification)이면 -> 다수결
로 합친다
Voting Ensemble은 같은 데이터를 사용하여 모델만 다르게 하는 데 반해, Bagging은 다르게 샘플링한 데이터를 사용하고 보통 같은 종류의 모델을 여러 개 사용한다.
대표적인 Bagging 모델 - Random Forest
Random Forest는 Decision Tree를 여러 개 만든 대표적인 Bagging 모델
- 원본 데이터에서 램덤 샘플링
- 각 샘플로 Decision Tree 하나씩 학습
- 트리 여러 개 생성
- 마지막에 투표/평균으로 예측
의사결정 나무(Decision Tree)
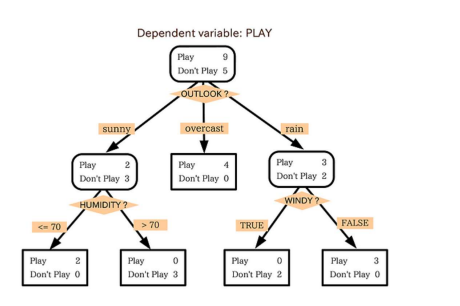
의사결정나무는 사람처럼 질문을 하나씩 하면서 결정:
- 날씨가 맑은가?
- 흐린가?
- 비 오는가?
...
Bootstrap Sampling
Bagging에서 샘플링은 보통 복원추출(with replacement) 을 사용, 이를 Booststrap Sampling이라고 함.
- 복원 추출이란 한 번 뽑은 데이터를 다시 뽑을 수 있게 하는 방식
- 어떤 샘플은 두 번 뽑히고, 어떤 샘플은 안 뽑힐 수도 있음
- 각 모델이 조금씩 다른 데이터 분포를 보게 됨
Bagging의 장점
1) 과적합 완화
- 특히 Decision Tree처럼 분산(variance)이 큰 모델에 효과적
- 하나만 쓰게 되면 데이터에 따라 결과가 확 바뀔 수 있으나 여러개를 평균내면 그 불안정성이 줄어듦
2 예측 안정성 증가
- 특정 데이터에 우연히 맞춘 패턴이 줄어듦
3) 성능 향상 가능성
Bagging의 단점
1) 해석이 어려워짐 (너무 많은 트리는 직관적으로 이해하기 어려움)
2) 계산량 증가
3) 너무 단순한 모델에는 효과가 제한적일 수 있음
코드 예
Bagging Classifier
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging_model = BaggingClassifier(
estimator=DecisionTreeClassifier(),
n_estimators=100,
random_state=42
)
bagging_model.fit(X_train, y_train)
pred = bagging_model.predict(X_valid)Random Forest
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging_model = BaggingClassifier(
estimator=DecisionTreeClassifier(),
n_estimators=100,
random_state=42
)
bagging_model.fit(X_train, y_train)
pred = bagging_model.predict(X_valid)Boosting - AdaBoost
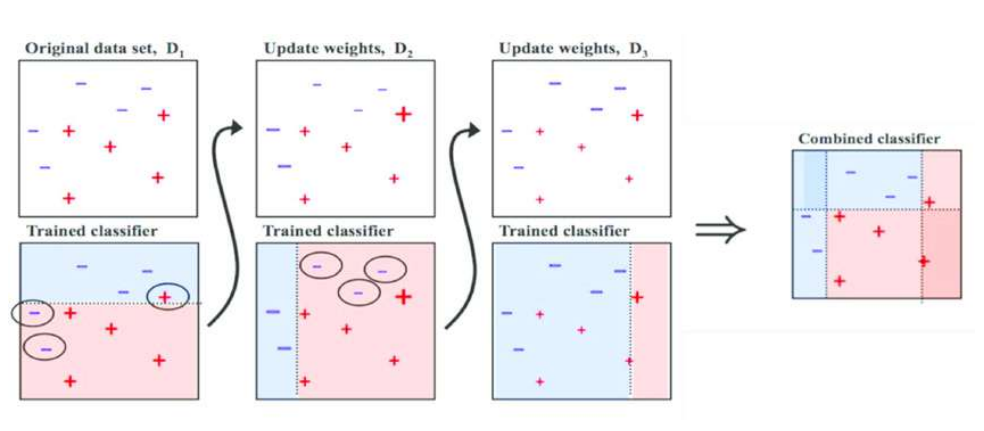
약한 분류기(weak learner)를 여러 개 순서대로 학습시켜서, 틀린 데이터에 점점 더 집중하게 만든 뒤, 마지막에 함쳐서 강한 분류기(strong classifier)를 만든다.
1) Original Data set,
+, - 는 두개의 클래스 즉 + = 클래스 1, - = 클래스 0
이진 분류(binary classification)문제를 나타내는 데이터셋
2) Trained classifier
첫번째 분류기를 학습 시킴
파란 영역 = - 로 예측
분홍 영역 = + 로 예측
가운데 점선 = 결정 경계(decision boundary)
첫번째 모델은 단순하게 위쪽 - 아래쪽 + 로 나눔
-> 그러나 동그라미 친 점들은 틀리게 분리된 샘플
3) Update weights,
첫번째 모델이 틀린 샘플에 대해:
- 가중치(weight)를 올려서 다음 학습 때 더 중요하게 취급
- 두 번째 데이터 셋은 데이터 자체가 바뀐 것이 아니라 어떤 샘플을 더 중요하게 볼 것인가가 바뀐 상태
4) 두 번째 Trained classifier
이번에는 세로 방향 경계를 사용해서, 이전 모델이 놓친 부분을 보완하려고 함
5) Update weights,
- 이번에도 틀린 샘플의 가중치를 올림
6) 세 번째 Trained classifier
7) Combined classifier
- 앞에서 만든 여러 개의 약한 분류기를 합친 결과
- 더 복잡한 결정 경계
Boosting의 장점과 단점
1) 장점
- 성능이 매우 강력한 경우가 많음
- 표(tabular) 데이터에서 특히 강함
2) 단점
- 순차 학습이라 느릴 수 있음
- 노이즈/이상치에 과하게 집착할 수 있음
- 너무 학습하면 과적합 가능성도 있음
- 틀린 샘플에 계속 집중하기 때문에 그 샘플이 사실은 노이즈거나 잘못된 라벨이면 쓸데없는 데 노력을 많이 쓰게 될 수 있음
XGBoost, LightGBM
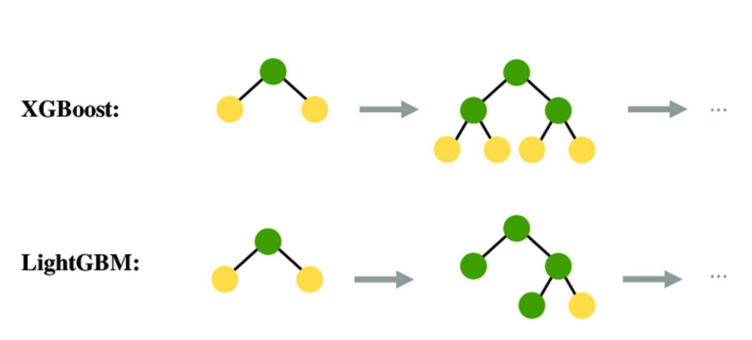
XGBoost는 트리를 비교적 "균형 있게(level_wise)" 확장하고, LightGBM은 가장 성능 향상 여지가 큰 가지를 먼저 "집중적으로(leaf-wise)" 확장한다.
1) XGBoost = Level-wise Tree Growth
장점
- 비교적 안정적
- 과적합(overfitting) 위험이 상대적으로 덜함
- 해석이 조금 더 직관적일 수 있음
단점
- 꼭 필요한 곳만 파고들지 않아서 계산이 조금 비효율적일 수 있음
- 속도가 LightGBM 보다 느린 경우가 많음
2) LightGBM = Leaf-wise Tree Growth
장점
- 더 빠르고, 같은 깊이/노드 수 조건에서 더 높은 성능이 나오는 경우가 많음
- 큰 데이터에서 특히 강함
단점
- 특정 가지를 너무 깊게 파면서 과적합되기 쉬움
- 파라미터 조절이 더 중요함
비교표
| 방법 | 핵심 아이디어 | 모델 구성 | 데이터 사용 방식 | 학습 방식 | 대표 예 |
|---|---|---|---|---|---|
| Voting | 여러 모델 예측을 투표로 합침 | 보통 서로 다른 모델 | 같은 데이터 | 병렬 | VotingClassifier |
| Bagging | 다른 샘플 데이터로 같은 모델 여러 개 학습 | 보통 같은 모델 | 샘플링 다름 | 병렬 | Random Forest |
| Boosting | 이전 모델의 실수를 다음 모델이 보완 | 보통 같은 계열 약한 모델들 | 같은 데이터(가중치/잔차 변화) | 순차 | XGBoost, LightGBM |
| Stacking | 여러 모델 예측값을 다시 학습 | 서로 다른 모델 + 메타 모델 | 같은 데이터 + 예측값 | 2단계 학습 | StackingClassifier |
