Word2Vec
- 단어의 의미를 반영한 임베딩 벡터를 만드는 대표적인 방법
- 기본적으로 NNLM을 개선한 모델
- 이전 단어들로부터 다음 단어를 예측하는 목표보다는 임베딩 그 자체에만 집중
- 두 가지 학습 방법이 있음

1) CBoW (Continuous Bag of Words)
- 주변 단어 -> 중심 단어 예측
- 윈도우 크기를 정해주면 주어진 텍스트로부터 훈련 데이터를 자체 구축
- 히든 레이어 없음
- 2개의 가중치 행렬을 가집 (입력: W, 출력: W')
- Projection layer에서 모든 embedding vector들은 평균값을 구하여 M차원의 벡터를 얻음
- M차원의 벡터는 가중체 행렬 W'와 곱하여 소프트맥스 함수 통과
- 이 결과값이 예측값으로 실제 중심 단어의 원-핫 벡턴와 loss를 구하고 역전파
- 단어 순서가 중요하지 않음 (drink coffee, coffee drink - 동일하게 처리)
- 단점: 순서 정보가 없고, 복잡한 문맥 표현 어려움
2) Skip-Gram
- 중심 단어들로부터 주변 단어를 예측
- 윈도우 크기에 따라 데이터셋을 구성
- 히든 레이어 없음
- 입력층, 투사층, 출력층 3개의 층으로 구성된 신경망
- CBoW와 같이 소프트맥스 함수를 지난 예측값과 실제값으로부터 오차를 구함.
- 그리고 이로부터 embedding table 을 업데이트
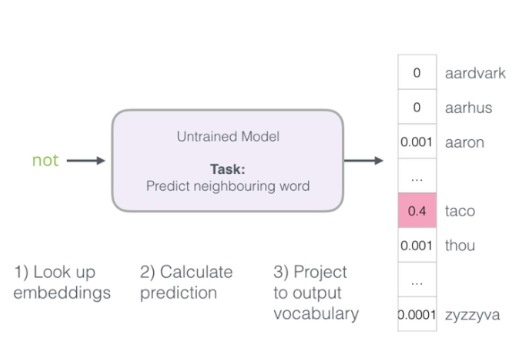
Skip-Gram with Negative Sampling(SGNS)
CBoW, Skip-Gram의 실제 구현 시의 문제
- 실제로 위와 같이 구현하면 너무 속도가 느림 (softmax + cross entorpy 연산이 너무 느림)
- 이진 분류 문제로 바꾸면 연산량을 획기적으로 줄일 수 있음
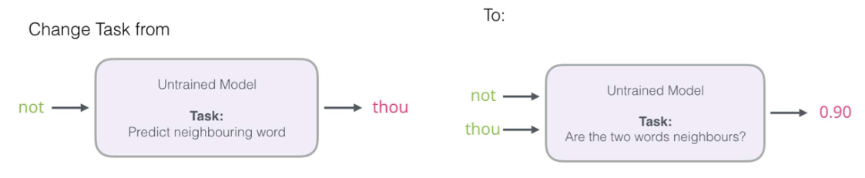
-
이 모델의 목적은 중심 단어와 주변 단어를 입력으로 했을 때, 실제로 이 두 단어가 이웃하는 지 예측하는 것
-
주변 단어와 중심 단어 데이터셋에 True인 1을 할당하고 Negative Sample을 랜덤으로 추가해 줌 (랜덤으로 하는 이유는 다 넣을 경우 데이터셋 크기에 따라 너무 느리기 때문, 다 넣을 수 없으므로 확률적 랜덤 샘플 P(w)∝ 로 대신함)
-
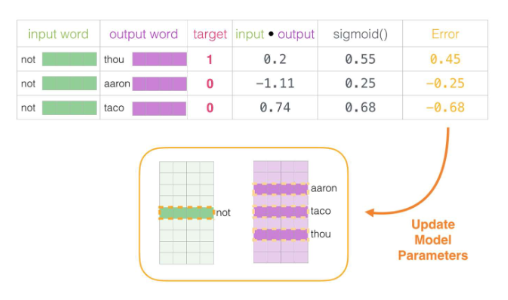
Embedding table도 두 개가 됨 (중심단어, 주변단어)
-
중심 단어와 주변 단어의 내적으로 실제값인 1또는 0을 예측
-
실제값과의 오차를 계산하여 역전파를 통해 두 개의 테이블을 업데이트
실습

오랜시간 망설였던 코딩을 다시 해보려고 노력하고 있는 사람