PaLM2 VAdapter
Frozen Pre-trained Vision Encoder와 LLM을 align 시키는 방법으로 vision-language adapter를 사용, 이 adapter로 언어 모델(TinyPaLM2)을 사용하자는 아이디어이다.
Introduction
Large Vision-Language Models (LVLMs)의 발전
- Vision-Encoder와 LLM을 연결한 후, 함께 학습(or Fine-tuning)
- Frozen pre-trained Vision-Encoder와 LLM을 그대로 사용하고, 이 둘을 align시키는 무언가를 학습
- Adapter ( perceiver resampler )
- Q-Former (in blip-2)
- …
PaLM2-VAdapter
- 비전 모델과 언어 모델 간의 정보를 더 효율적으로 연결하기 위한 새로운 Adapter 방법
- 이를 통해 기존 방법보다 더 빠른 수렴과 높은 성능, 강력한 확장성을 보임.
- 30-70%적은 파라미터를 가지고도, Visual Captioning과 VQA 벤치마크의 SOTA 성능에 도달.
Related Work
Vision-language Pre-training
- Multi-modal representation이 목적
- image-text matching
- image-text contrastive learning
- auto-regressive image captioning
- Image-Text pairs로 pre-train되어,
- image caption에만 초점을 맞추고 있으며,
- LLM이 가진 복잡한 reasoning 능력과 few-shot learning 능력을 가지지 못하는 경우가 많음.
Large Language Models(LLMs)
- 대규모 데이터와 모델을 바탕으로 LLMs는 zero-shot generalization, in-context learning에 뛰어난 능력을 가짐.
- 본 논문에서는 PaLM2 시리즈의 LLM의 능력을, vision-encoder와 연결하려는 시도를 하는 것. 이때 LLM의 능력 유지하기 위해 LLM은 frozen 상태로 유지.
Large Vision-language Models(LVLMs)
멀티모달 입력을 처리하는데 중점을 둠.
- Flamingo, OpenFlamingo, BLIP-2, InstructBLIP, MiniGPT-4, LLaVA
이러한 방법은 많은 파라미터/복잡한 학습과정을 필요로 한다는 단점이 있어, 새로운 어댑터 방식을 제안.
[ Adapter ]
VLMs에서 시각적 정보를 언어모델에 연결하기 위한 중간 단계의 구성요소.
- Vision Encoder에서 나온 시각적 정보를 언어 모델이 이해할 수 있는 representation space로 align 시키는 것
Cross-attention based adapter.
- Vision Encoder가 추출한 visual features는 learnable queries와 cross-attention으로 결합됨.
- adapter는 6-layer perceiver resampler를 사용.
Self-attention based adapter.
- representation quality를 향상시키는데 기여.
- pre-trained LM을 초기화에 사용하여 더 나은 convergence, 향상된 성능이 가능해짐.
[ Perceiver Resampler ]
Vision Encoder에서 추출한 시각적 정보를 LLM에 연결(매핑)하는 역할 → resampler
- 다양한 이미지/비디오 →
Vision Encoder→ spatio-temporal feature →Perceiver Resampler→ 고정된 수(64시퀀스)의 시각적 출력 - 동일한 visual token 수를 생성하기 때문에(고정) 이후 계산 복잡도를 줄일 수 있고, 이 점은 특히 비디오 처리에서 큰 장점이 된다.
Method
Visual-language Alignment with Adapter
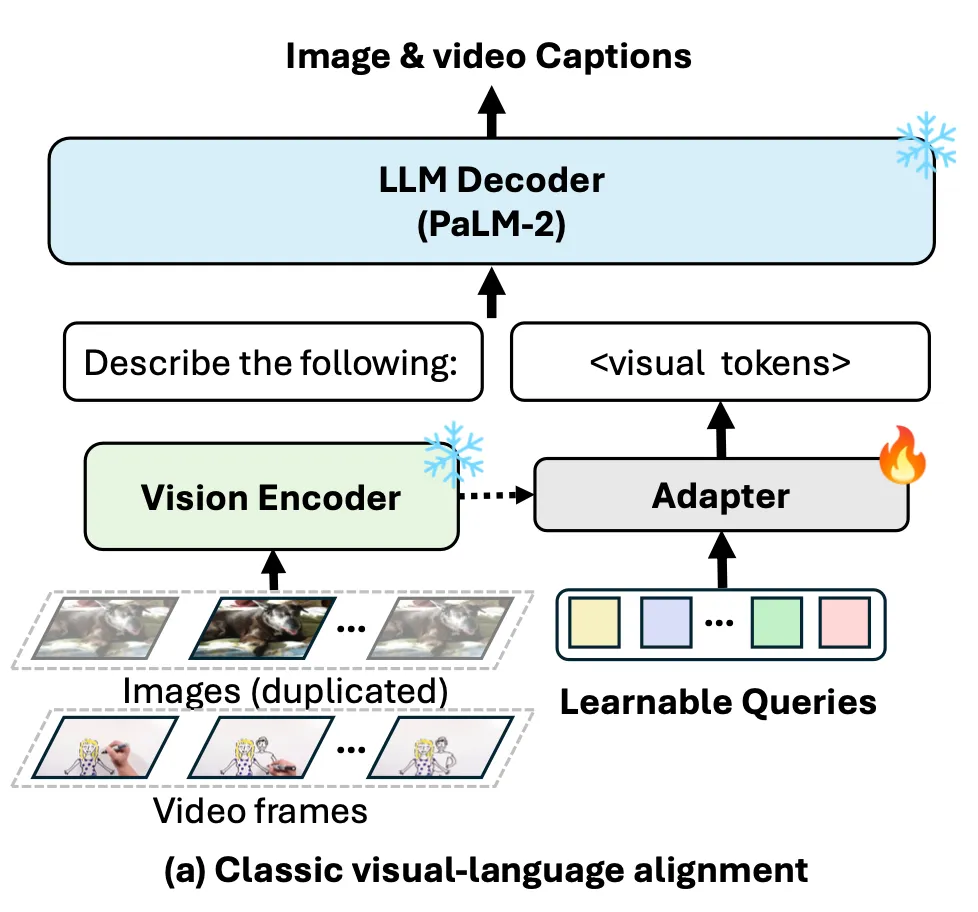
[Vision Encoder (frozen)]
CoCa vision encoder
[Adapter]
Tiny PaLM2
visual feature token들이 LLM representation space로 변환
[LLM (frozen)]
PaLM 2 as LLM decoder
Progressive Visual-language Alignment
Tiny PaLM2를 Adapter로 사용!
- Tiny PaLM2 : ~108M의 LM
아래 두 단계로 구성된 점진적인 학습 방법을 통해 Tiny PaLM2(TLM)을 학습.
Stage 1. TLM trained as the decoder
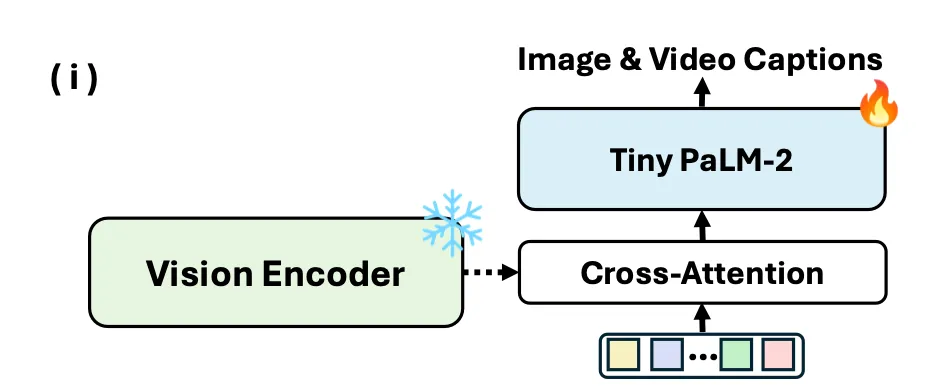
TLM을 시작으로, vision-language alignment 작업으로 파인튜닝
Stage 2. TLM trained as the adapter

1단계의 TLM과, 그 앞에 추가적인 1-layer의 perceiver resampler를 연결. (LLM과 연결을 위함)
이렇게 두 단계로 학습된 TML adapter는,
- SOTA adapter인 perceiver resampler보다 더 빠른 수렴, 향상된 성능, 더 강력한 확장성을 가짐.
- progressive alignment strategy(위의 두 단계에 걸친 학습)는 vision-language alignment에 뛰어난 향상을 보임 + 매우 효율적.
Experiments
Implementation Details
Model
- Vision Encoder :
CoCapretrained ViTs.- input resolution: 288
- patch size: 18x18
- LLM :
PaLM2pretrained model - baseline adapter architecture:
Perceiver Resampler- 256 learnable queries.
- Proposed adapter
- 1-layer
perceiver resampler - tiny transformer-based language model (~110M)
- 1-layer
- 2 FC-layers.
- dimension matching을 위해 adapter의 앞/뒤에 부착
Data
WebLIdataset: image-text paired dataVTPandSMITdataset: video-text paired data- 8 frames로 duplicated/sampled
Training
- learning rate:
- training batch size: 2048
- steps: 250K
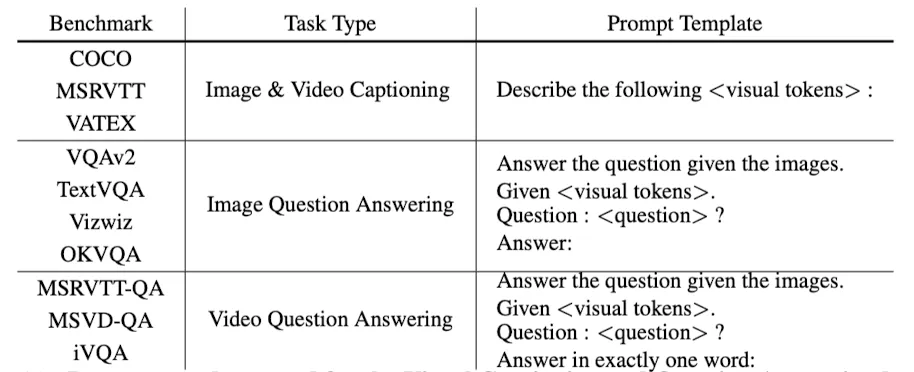
- prompt template: “
Describe the following: *<visual tokens>*”
Evaluation
- Image-based evaluation:
COCO,VQAv2,TextVQA,VizWiz,OKVQA - Video-based evaluation:
MSRVTT,VATEX,MSVD-QA,iVQA
Faster, Higher, and Stronger
SOTA adapter 모델인 Perceiver Resampler는 합리적인 성능을 보이지만, 제한된 확장성, 느린 수렴 속도의 단점이 존재.
→ SOL) 작은 언어 모델을 adapter로 사용하여 점진적으로 학습하자는 아이디어!
-
Faster Convergence
-
Higher Performance
-
Stronger Scalability
: ViT-B → ViT-L 에서 성능 향상의 폭이 큼

Results
Visual Captioning
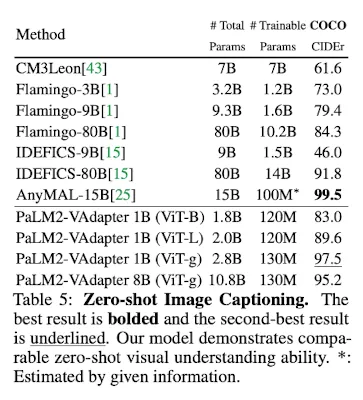
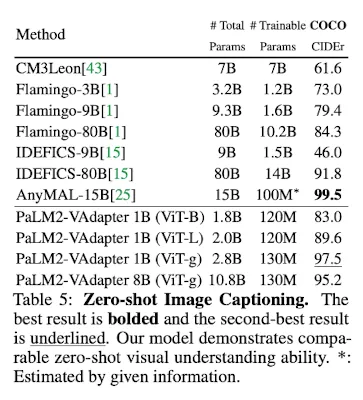
Image Captioning (zero-shot)
COCOdataset으로 SOTAAnyMALmodel과 비교했을 때,- Comparable capability
- 70% parameters(10.8B v.s. 15B)
- → Effectiveness of Progressive Alignmnet Strategy

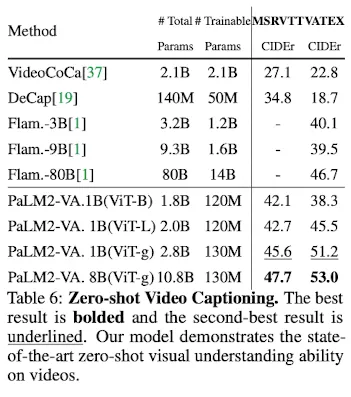
Video Captioning
MSRVTTandVATEXdatasets으로, SOTAFlamingomodel과 비교했을 때,VATEXdataset에서 SOTA 성능 (10.8B v.s. 80B)- strong scalability

Visual Question Answering
Image Question Answering
VQAv2,TextVQA,VizWiz, andOKVQAdatasets- SOTA
IDEFICSmodel과 비교했을 때,- comparable VQA성능
- 14% parameters (10.8B v.s. 80B)
- Very Strong Scalability
Video Question Answering
MSRVTT-QA,MSVD-QAandiVQAdatasets- SOTA
Flamingomodel과 비교했을 때,- SOTA 성능 달성
- 14% parameters (10.8B v.s. 80B)
- → Remarkable Effectiveness
- Strong Scalability
Limitation & Conclusion
높은 efficiency(적은 parameter수, 적은 training cost)에도 불구하고,
- LLM decoder의 크기가 커질 수록, alignment가 어려워진다는 한계가 여전히 존재.
- visual embedding 자체가 언어 단어 하나하나로 “번역”되지는 않음
simple but effective framework
- PaLM2-VAdapter를 통해 효율적이며
- 좋은 성능의,
- 높은 확장성의 프레임워크를 제안했을 뿐 아니라,
- 다른 modal들의 multi-modal alignment에도 가능성을 보임
