VLMs
1.[PAPER REVIEW] LXMERT
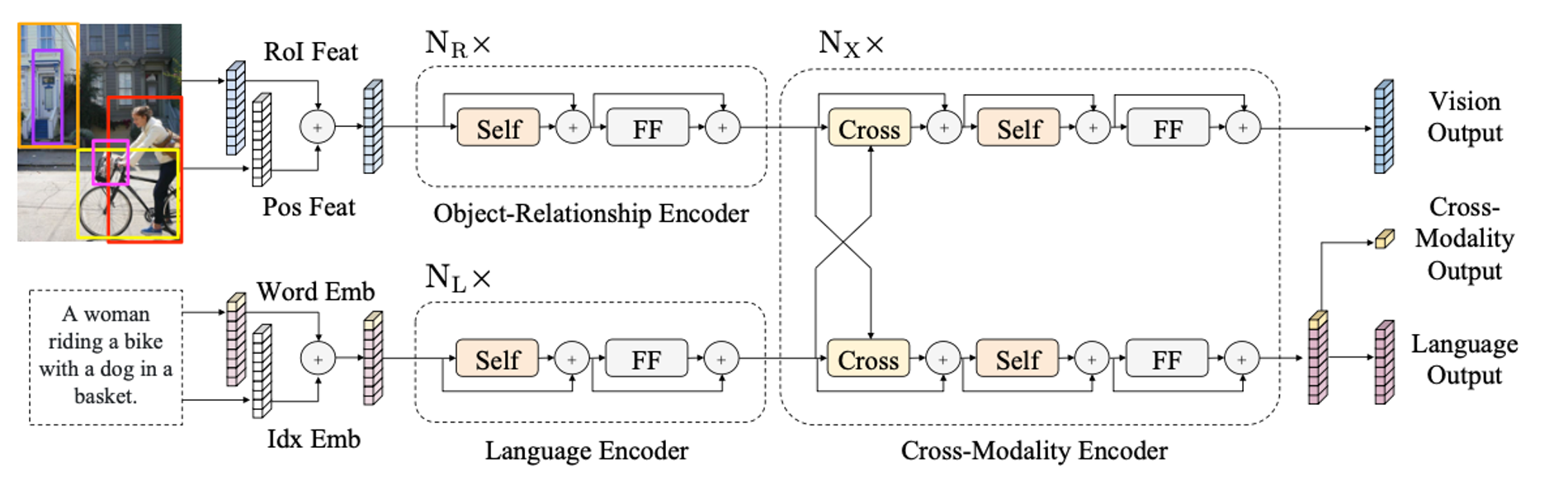
Vision-and-language reasoning에서는 각 모달리티에 대한 이해와 두 모달리티 간의 alignment와 관계 파악이 중요하다. LXMERT는 vision과 language의 두 모달리티를 연결짓는 cross-modality framework이다.
2024년 4월 15일
2.[PAPER REVIEW] mPLUG
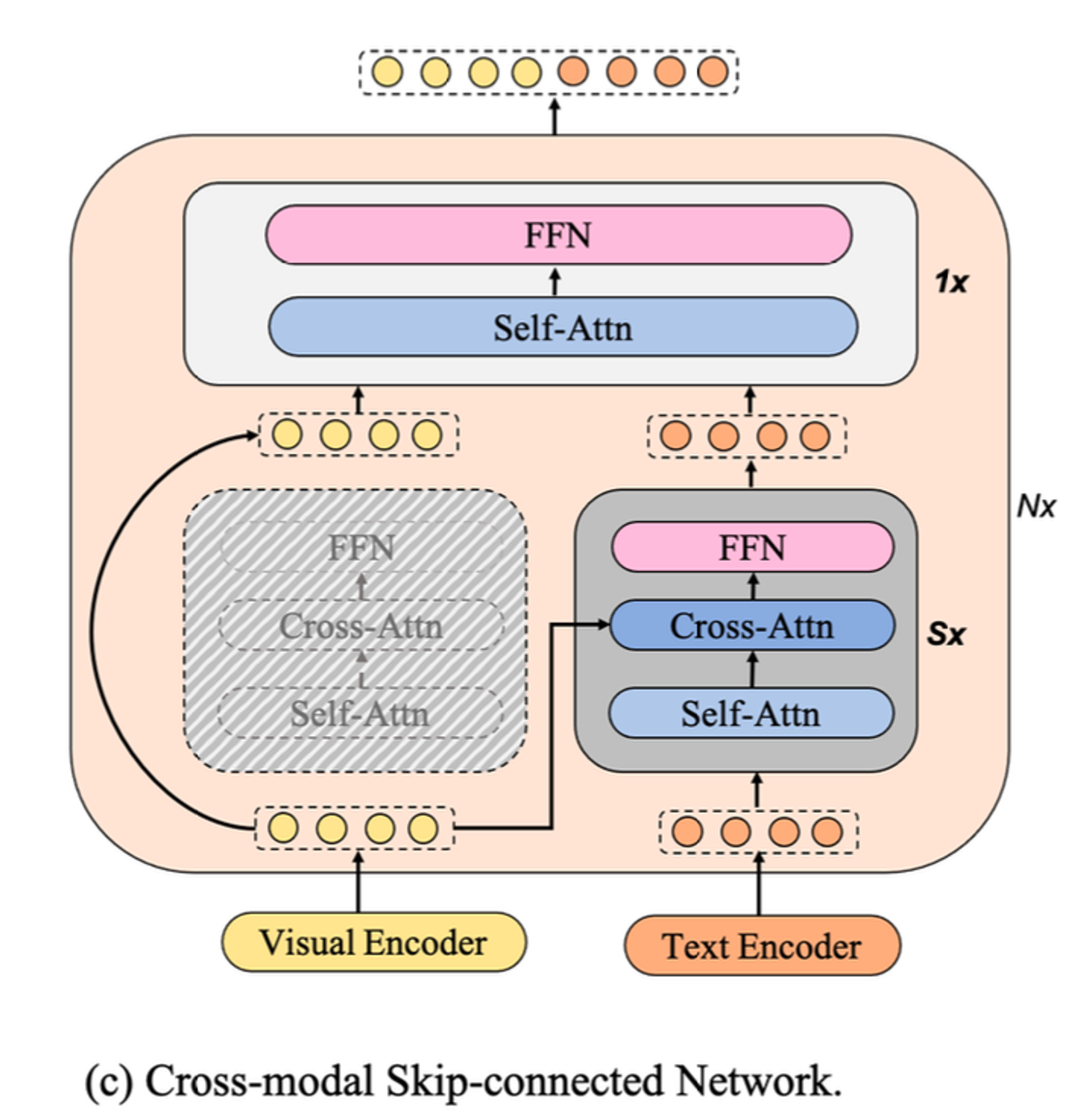
mPLUG는 2023 EMNLP에서 Alibaba의 DAMO Academy가 제안한 vision-language pre-trained 모델로, 당시 다양한 vision-language task에서 SOTA를 달성했을 뿐 아니라, 계산 효율성을 가진다.
2024년 4월 15일
3.PaLM2-VAdapter
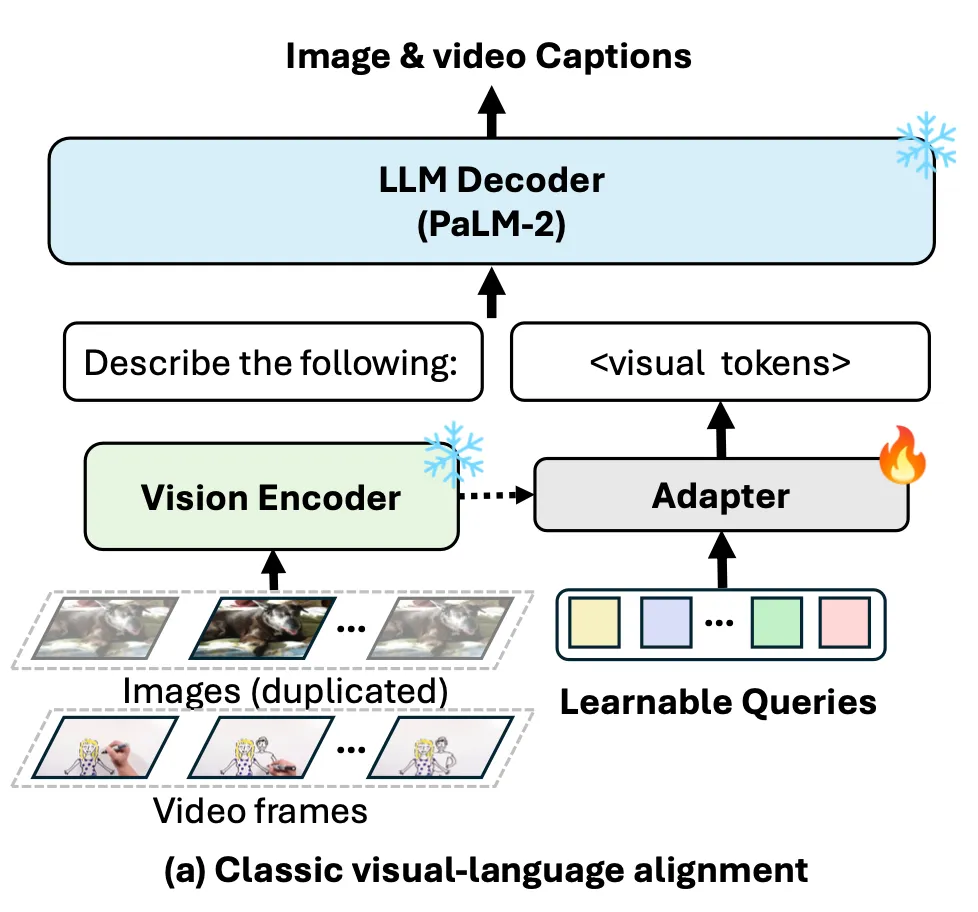
Frozen Pre-trained Vision Encoder와 LLM을 align 시키는 방법으로 vision-language adapter를 사용, 이 adapter로 언어 모델(TinyPaLM2)을 사용하자는 아이디어이다.
2024년 10월 1일