mPLUG
mPLUG는 2023 EMNLP에서 Alibaba의 DAMO Academy가 제안한 vision-language pre-trained 모델로, 당시 다양한 vision-language task에서 SOTA를 달성했을 뿐 아니라, computation effectiveness와 efficiency를 모두 향상시켰다.
Previous Architectures
기존의 vision-language pre-trained model들은 주로 두 가지 방법으로 이미지와 텍스트의 정보를 align하고 학습했다.
- Connected-attention Network
각 모달리티의 정보를 단일 transformer에서 처리한다. 두 피쳐 벡터 시퀀스가 하나의 긴 시퀀스로 연결되는 방식으로 두 모달리티가 fusion되는데, 이는 긴 시퀀스의 연산으로 time-consuming 및 모달리티 간 정보 불균형으로 인한 성능 저하 문제를 가진다. - Co-attention Network
각 모달리티의 정보를 각각의 transformer에서 처리한다. 두 모달리티 정보의 양이 불균형해지는 문제는 해결되었지만, 두 개의 transformer 네트워크로 인해 계산 비효율성 문제는 남아있다.
→ 위의 두 방법을 보면 크게 두 가지의 문제점을 확인할 수 있다. (1) 계산 효율성이 낮고, (2) 이미지와 텍스트의 정보 불균형 문제가 있다. 정보 불균형 문제는 텍스트는 이미지에 비해 짧고, 축약되어 있기 때문에 발생한다.
mPLUG는 이러한 문제를 해결하기 위해 cross-modal skip-connections를 도입한 새로운 asymmetric vision-language architecture를 제안한다.
Model Architecture
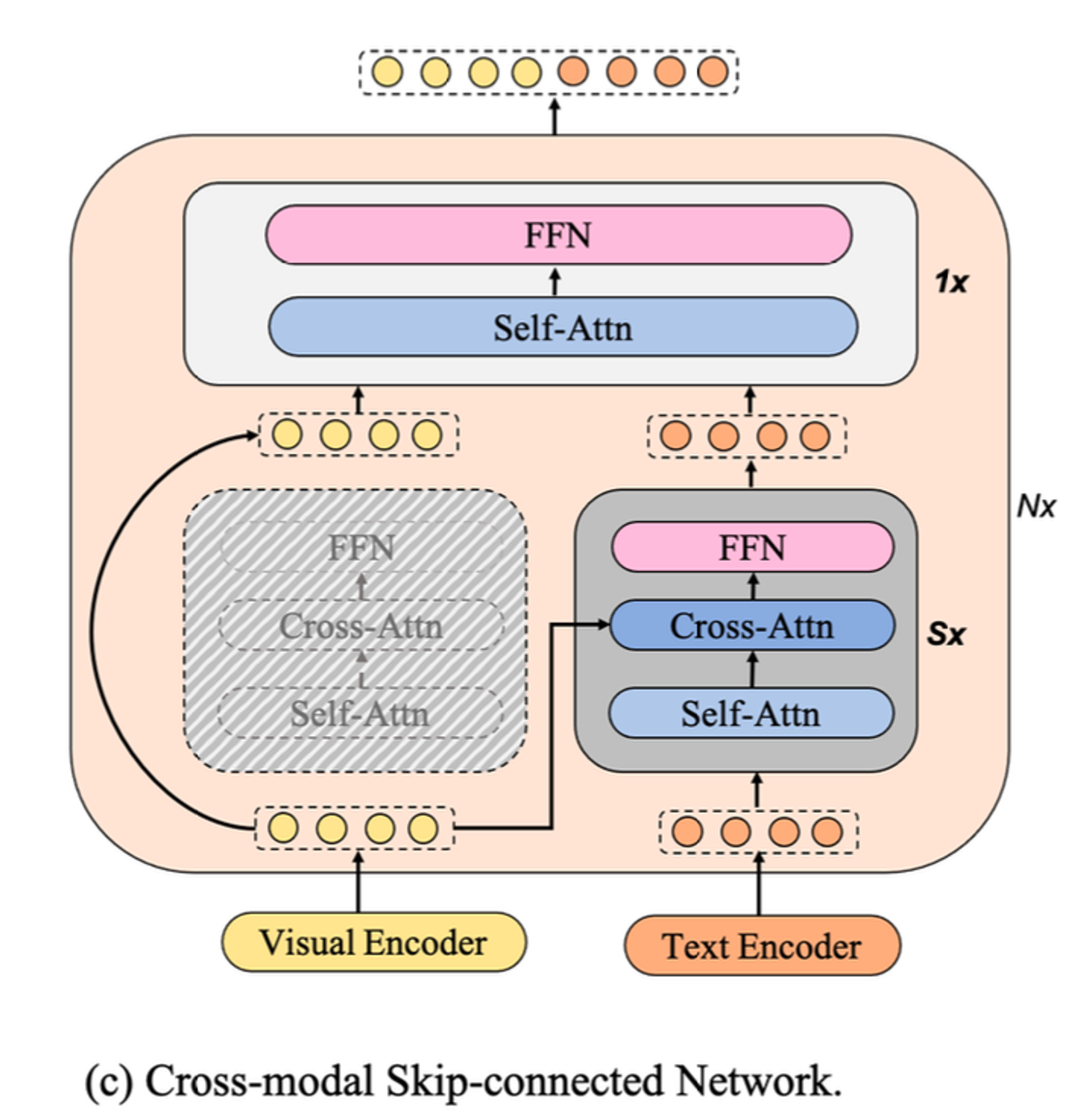
피규어에서 볼 수 있듯이 mPLUG의 가장 큰 특징은 1️⃣ language 정보와 visual 정보가 각각 다른 encoder를 통과하며 2️⃣ 이 중 language 정보만 추가적인 transformer를 거치는데, 3️⃣ 이 transformer에서는 visual encoder를 통과한 image 정보가 입력되어 fusion된다는 점이다.
mPLUG의 architecture는 크게 Encoder part, Cross-modal Skip-connected Network, Decoder part로 나뉜다.
Encoders
- 입력 이미지는 visual encoder에서 patch로 쪼개진 후 시퀀스로 추출된다. 이때, 시퀀스의 제일 앞부분은 token에 해당한다. visual encoder는 CLIP-ViT를 기반으로 초기화되며, ViT-B/16(base) 또는 ViT-L/14(large)를 사용한다.
- 입력 텍스트는 Text Encoder에서 token을 포함한 임베딩 시퀀스로 추출된다. text encoder는 의 first 6 layer로 initialize된다.
Skip-Connected fusion blocks
figure에서 살구색 큰 박스가 “Cross-modal Skip-connected Network”로, mPLUG architecture의 핵심에 해당한다. 이는 N개의 반복적인 skip-connected fusion blocks으로 구성된다.
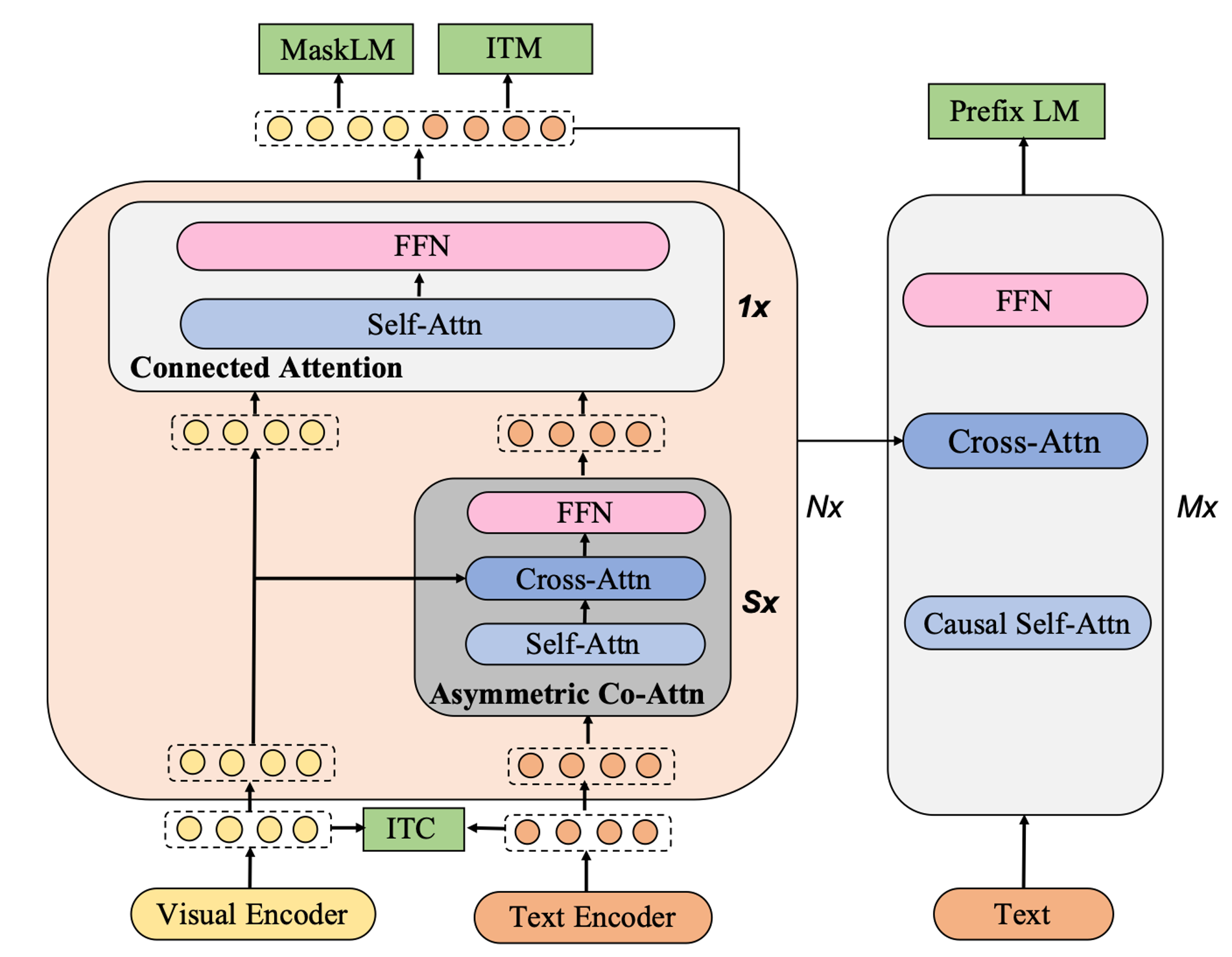
하나의 skip-connected fusion block은 S개의 Asymmetric Co-Attention과 1개의 Connected Attention으로 이루어진다.
이 네트워크의 목표 : 1. 서로 불균형한 두 모달리티의 정보 양을 효율적(efficiency)으로 처리(→반복적인 Asymmetric Co-Attention)함으로써 2. 효과적(effectiveness)으로 두 모달리티의 정보를 fusion(→ Connected Attention)하는 것이다.
-
Asymmetric Co-Attention
Asymmetric Co-Attention layer는 self-attention(SA) layer와 cross-attention(CA) layer, 그리고 feed-forward network(FNN)로 구성된다.
입력된 text feature (n-1번째 block의 output)는 SA layer를 거쳐 가 된다.
이 는 이전 block output의 visual feature인 와 CA layer를 통해 fusion된다.
이렇게 fusion된 결과가 이며, FFN layer를 통해 “visual-aware text representation”인 이 완성된다.
-
Connected Attention
Connected Attention layer는 SA layer와 FFN layer로 구성된다. 이 레이어는 이전 block의 image feature인 과, S개의 Asymmetric Co-Attention layer를 거친 output인 (위 1번 과정에서 마지막 수식의 에 해당)을 연결짓는 역할을 한다. 와 는 concat된 형태로 함께 connected attention layer에 입력되고, 출력된다.
* : layer normalization
skip-connected network는 의 last 6 layer로 initialize된다.
Decoder
mPLUG의 decoder part는 12-layer Transformer를 사용한다. 이를 통해 mPLUG는 ‘understanding’ 능력 뿐아니라, ‘generation’ 능력도 갖게 된다.
Pre-training Tasks
mPLUG는 세 개의 understanding tasks와 하나의 generation task를 통해 pre-train된다. 이 때 사용되는 loss들은 모두 합쳐져서 학습된다.
- Image-Text Contrastive ( ITC ) image와 text의 [CLS] token으로 코사인 유사도를 계산하여 softmax를 취하고, cross entropy loss를 사용한다.
- Masked Language Modeling ( MLM ) BERT의 논문에서 사용한 방법과 유사하다. 문장에서 토큰의 15%를 마스킹하고, 마스킹된 토큰을 예측하는 task이다.
- Prefix Language Modeling ( PrefixLM ) 주어진 image의 caption을 생성하는 작업이다. autoregressive 방식으로 text generation을 하며, cross entropy loss를 사용한다.
Distributed Learning on a Large Scale
mPLUG는 BFloat16, Gradient Checkpoint, ZeRO 등의 기술을 사용하여 학습 throughput을 향상시킨다.
Experiments & Evaluation
Vision-Language Tasks
mPLUG는 MS COCO와 Visual Genome 두가지 데이터셋으로 pre-train한다. 그 후, 이 두 데이터셋과 세 개의 web out-domain datasets(Conceptual Captions, Conceptual 12M, SBU Captions)으로 평가한다.
실험은 총 5가지의 downstream task로 finetuning하여 진행된다. VQA과 image captioning의 두 가지 task에 대해서만 4M dataset에 대해 사진 해상도를 높혀가며 추가 pre-train을 진행하였다.
-
Visual Question Answering
주어진 Image와 자연어 question에 대해 open-vocab answer generation을 진행한다.
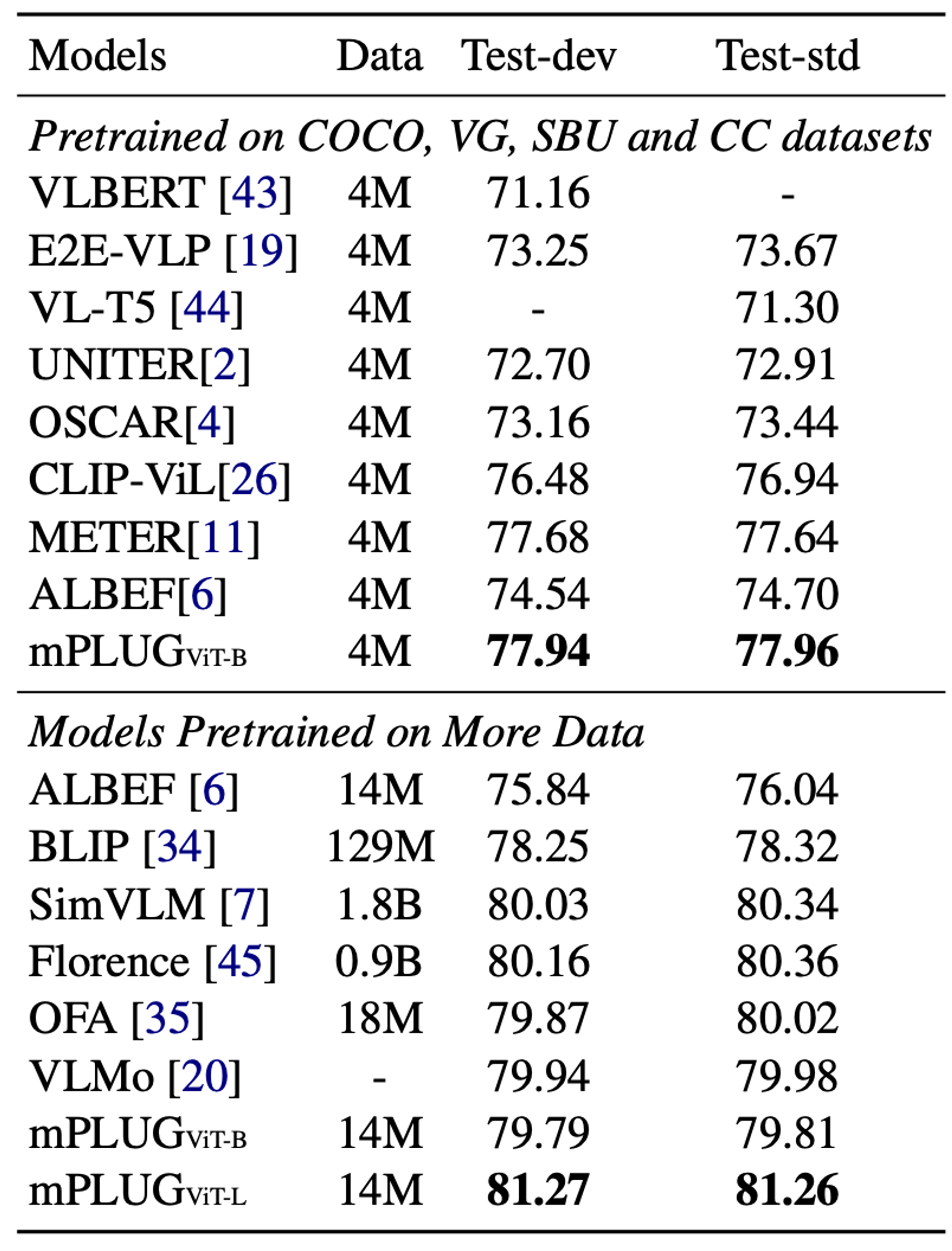 표에서 mPLUG는 기존 SOTA 모델보다 더 좋은 성능을 보인다. 여기서 mPLUG는 같은 visual encoder를 사용하거나, 같은 양의 데이터로 학습된 기존 모델들보다 성능이 좋을 뿐 아니라, 훨씬 더 많은 데이터로 학습된 기존 SOTA 모델(SimVLM과 Florence)을 outperform하는 77.96의 성능을 보인다.
표에서 mPLUG는 기존 SOTA 모델보다 더 좋은 성능을 보인다. 여기서 mPLUG는 같은 visual encoder를 사용하거나, 같은 양의 데이터로 학습된 기존 모델들보다 성능이 좋을 뿐 아니라, 훨씬 더 많은 데이터로 학습된 기존 SOTA 모델(SimVLM과 Florence)을 outperform하는 77.96의 성능을 보인다.이것은 mPLUG가 cross-modal skip-connection으로 구성되어 두 모달리티의 비대칭을 해결할 수 있으며 좋은 성능을 낼 수 있다는 것을 의미한다.
-
Image Captioning
COCO Caption으로 fine-tuning을,COCO Caption test set과NoCaps로 evaluation을 진행한다. 먼저 cross-entropy loss로 fine-tuning을 진행하고, 추가 5epoch은CIDEr optimization으로 진행한다. mPLUG는 14M의 데이터로 학습되었음에도, 더 많은 데이터셋으로 학습된 기존 SOTA 모델(LEMON, SimVLM)을 능가한다. 특히,CIDEr optimization을 진행할 때 뛰어난 성능을 보인다. -
Image-Text Retrieval
image-to-text retrieval(TR, image에서 text를 검색)과 text-to-image retrieval(IR, text쿼리를 통해 image를 검색)을 모두 진행한다.
COCO와Flickr30K를 사용하고 fine-tuning을 위한 Loss로 ITC loss와 ITM loss를 함께 고려한다. mPLUG는 Image-Text Retrieval task에서 매우 뛰어난 성능을 보이며, 훨씬 많은 데이터로 학습된 모델들보다도 좋은 recall성능을 보인다. -
Visual Grounding
이미지가 주어졌을 때, 쿼리에 따라 이미지의 해당 부분을 잘라내는 task이다. mPLUG가 기존 SOTA 모델 대비 좋은 성능을 보인다. visual feature와 textual feature를 concat하여 decoder가 그 coordinate를 예측하도록 학습이 진행된다. 이러한 visual grounding task에서 mPLUG가 뛰어난 성능을 보인다는 것은, mPLUG가 cross-modal skip-connections를 통해 multi-modal interaction에 뛰어나며, 복잡한 이미지와 긴 쿼리를 잘 처리한다는 것을 의미한다.
-
Visual Reasoning
NLVR2와SNLI-VE에 대해 visual reasoning을 진행한다. Visual Reasoning을 진행할 때에는 decoder를 제거하고, encoder를 통해 출력된 [CLS] token을 사용함으로써 computation cost를 줄인다. mPLUG는 visual reasoning task에 대해 SOTA 성능을 보이지는 않지만, 더 많은 양의 task 맞춤 데이터로 학습되어 visual reasoning에 최적화된 기존 SOTA모델에 비교할 만한 성능을 보인다.
Effectiveness and Efficiency
mPLUG는 뛰어난 성능을 보임과 동시에 효율적이고 효과적인 학습 과정을 갖는다. 이또한 mPLUG의 cross-modal skip-connected network의 결과이다.
mPLUG는 BFloat16, Gradient Checkpoint, ZeRO의 기법을 통해 Training Throughput을 늘릴 수 있게 되었다.
Zero-shot Vision-Language Tasks
mPLUG는 fine-tuning을 진행하지 않은 zero-shot task에서도 우수한 성능을 보인다. 특히 pre-training 단계에서 ITC loss와 prefixLM의 Loss를 고려하여서 image-text retrieval 과 image captioning task에서 zero-shot generalization ability를 가질 수 있었다.
- Image Captioning
- “
A picture of”라는 prefix prompt를 입력하고NoCaps eval set에 대해 평가한다. COCO Caption에 대해 fine-tuning하고NoCaps에 대해 zero-shot task를 진행했을때, 훨씬 사이즈가 크고 더 많은 데이터로 학습된 모델들에 비해 꽤 좋은 성능을 보이며 SOTA 모델을 달성했다.
- “
- Image-Text Retrieval
- Zero-shot Transfer to Video-Language Tasks mPLUG는 video-text Retrieval, Video Question Answering, Video Caption task에 대해서도 zero-shot 실험을 진행했으며 video-language task에 대해서도 BLIP에 비해 좋은 성능을 보였다.
