Backpropagation
전체 구조 : Forward → Backward
Forward 순전파
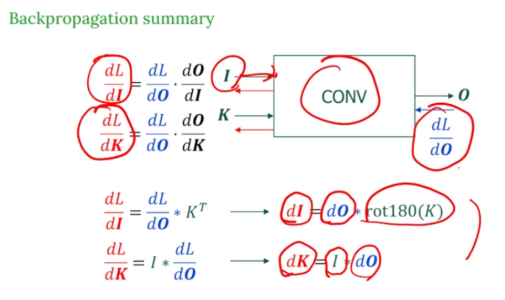
입력 I와 필터 K를 convolution을 하여 출력 O를 계산한다.
Backward 역전파
우리가 구해야 하는 gradient는 2개이다.
- 입력에 대한 loss 변화율
출력에 대한 gradient가 주어졌을 때, 필터를 180도 회전시켜서 convolution하면 입력에 대한 gradient가 계산된다. - 필터에 대한 loss 변화율
입력값 I와 출력값에 대한 gradientn를 convolution 하여 그 결과가 필터 K에 대한 gradient가 계산된다.
(필터는 입력을 보고 출력을 만들었기 때문에, 입력과 출력의 오차를 비교해서 필터를 얼마나 조절할지 결정해야한다.)
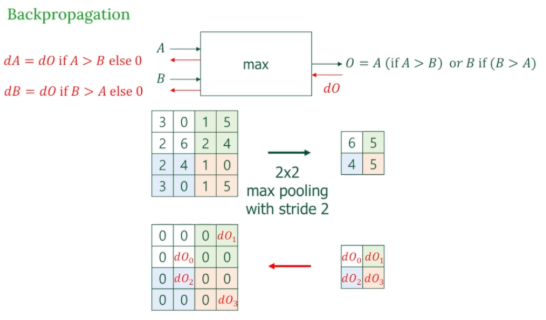
Maxpooling
Maxpooling은 가장 큰 값만 전달하기 때문에 역전파의 경우에도 가장 큰 값 위치에만 gradient를 보내고 나머지는 0으로 채운다.
Batch Normalization(BN)
동기
왜 Batch Normalization을 사용해야할까 ?
- 학습이 느리다 : 손실이 줄어들기까지 시간이 오래걸린다.
- 학습이 불안정하다 : gradient가 폭발하거나 사라진다.
- 초기값에 예민하다 : 가중치를 어떻게 초기화하느냐에 따라 성능이 크게 달라진다.
왜 이런 문제가 생길까 ??
내부 표현의 분포가 계속 바뀌기 때문이다.
앞 레이어의 가중치가 바뀌면, 뒤 레이어로 전달되는 값의 분포도 바귀기 때문에 이렇게 계속 변하면, 학습이 매번 적응해야하니까 느리고 불안정해진다.
이런 현상의 이름을 Internal Covariate Shift 이다.
Internal Covariate Shift
레이어마다 입력 데이터의 분포가 훈련 중에 계속해서 바뀌는 것을 말한다. 즉, 레이어가 학습 중에 계속 움직이는 목표를 따라가야한다. 모델 입장에서는 적응하기 힘들고 불안정해진다.
그래서 BN이 필요하다
BatchNormalization은 이 분포 변화를 줄여서 학습을 빠르고 안정적으로 만드는 역할을 한다.
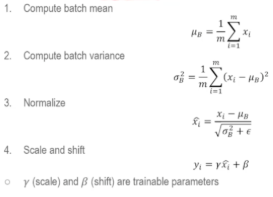
과정
각 레이어의 입력을 정규화 시켜서 평균이 0, 분산이 1이 되도록 만든다.
학습 중에 각 mini-batch 마다 평균과 분산을 계산해서 정규화한다.
각 feature map 채널마다 따로 평균/분산을 계산해서 정규화한다.
효과
-
학습 속도 증가 : 값들이 정규화되어있기 때문에 각 레이어가 더 예측 가능하고 안정적인 환경에서 학습할 수 있다. 그래서 learning rate도 더 크게 설정이 간으하다.
-
초기값에 덜 민감해진다 : 일반적으로 딥러닝은 가중치의 초기값에 따라 성능이 갈리기도 하는데, BN은 초반의 비정상적인 분포도 정규화해주기 때문에 초기화에 덜 민감하고 좀 더 튼튼한 모델을 만들 수 있다.
-
일종의 규제 역할을 하기도 한다 : mini-batch 단위로 평균/분산을 추정하기 때문에 작은 잡음 (noise)가 포함되기도 한다. 그래서 이게 마치 dropout처럼 일부러 살짝 흔들어주는 것과 비슷한 효과를 준다. 즉, 과적합을 줄이는데 효과도 있다.
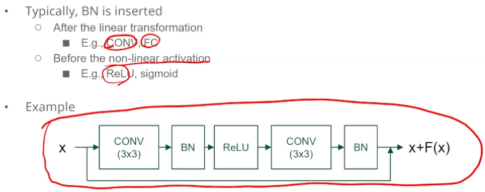
위치
보통, 선형 연산 뒤에, 비선형 활성화 함수 앞에 BN을 넣는다.
추론
추론할 때는 BN이 미니배치의 평균/분산을 사용하지 않는다.
왜냐하면 추론할 때는 여러 데이터를 한 번에 넣고 평균과 분산을 계산해서 정규화하는 학습 과정과 달리, 보통 한 개씩 예측할 때가 많다. 이럴 때는 평균과 분산을 새로 구하면 너무 들쭉날쭉해지게 된다.

그래서, 추론할 때에는 학습할 때 미리 저장해둔 평균과 분산을 그대로 사용한다 !
Regularization (정규화)
정규화는 과적합을 막기 위한 기술이다.
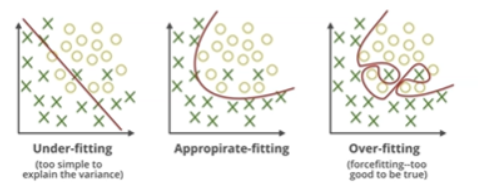
Overfitting
모델이 너무 똑똑해지면, 훈련 데이터에만 딱 맞게 외워버리게 된다. 그 결과, 새로운 데이터(테스트)에는 잘 못 맞춘다. 마치 학생이 시험 문제 답만 외우고 개념을 이해 못한 상태와 유사하다.
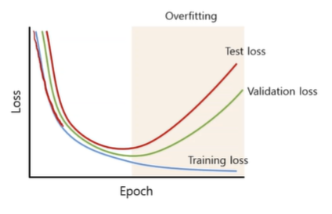
학습하면서 모든 loss가 빠르게 감소되는 것을 볼 수 있다. 이는 모델이 잘 배워가고 있다는 것을 시사하며 training loss는 계속해서 낮아지지만 validation과 test loss 는 다시 올라가게 된다. 이때가 바로 Overfitting 발생 구간이라고 보면 된다 ! 모델이 훈련 데이터를 너무 외워버려서, 새로운 데이터에서는 일반화가 되지 않는 상황이다.
정규화 방법
정규화 방식 중 가장 간단하는 것은 '많은 데이터셋을 구한다.' 이다.
더 많은 데이터는 과적합을 방지한다. 데이터가 너무 적으면 모델이 각 점을 외워버리기 쉽다. 데이터가 많아질 수록 전체적인 패턴을 추정하는 데 유리하며, 노이즈를 무시하고 진짜 함수를 따라가게 되어 과적합 위험이 줄어든다.)
근데, 데이터가 적으면 어떻게 해야하나 ??
Data Augmentation (데이터 증강)
데이터를 인위적으로 늘리는 기법이다. (특히 이미지 데이터에서 자주 사용된다.)
예 : 회전, 이동, 확대/축소, 밝기 변화 등
Weight Decay (가중치 감쇠)
모델이 과적합하지 않도록 가중치를 너무 크지 않게 억제하는 방법이다.
L2 정규화
가중치가 너무 커지지 않도록 손실함수에 벌점(페널티)를 추가한다.
기존에 과적합 모델은 데이터에 딱 맞추기 위해 가중치를 크게 조정한다. 그래서 오히려 새로운 데이터엔 약하다. 그래서 Weight Decay가 하는 일은 큰 가중치를 억제함으로써 너무 예민하게 반응하지 않도록 제한하고 작은 가중치를 유지하며 모델이 더 부드럽고 일반화가 잘 되게 한다.
L1 정규화
모델이 복잡해지지 않게 하려고, 손실 함수에 가중치의 절댓값 합을 더하는 방식이다. 불필요한 가중치는 아예 0으로 만들어서 모델을 단순하게 만든다. (희소성 유도)
Early Stopping
검증 데이터의 성능이 더 이상 좋아지지 않으면, 학습을 조기 종료하는 기법
모델은 훈련을 계속하면 training loss는 계속 줄어든다. 하지만 validation loss 는 어느 순간부터 다시 증가한다. 이 순간에 과적합을 시작하는것이다. 이때 계속 학습하면, 훈련 데이터에만 너무 잘 맞추게 되고, 새로운 데이터에 일반화 성능이 떨어지게 된다. 그래서 Early Stopping 을 통해 검증 손실이 최저가 되는 순간에 멈추는 것이다 !
Dropout
학습할 때 일부 뉴런을 무작위로 꺼서 과적합을 방지하는 기법이다. 뉴런이 일부러 꺼지니까 의존도가 줄고, 일반화 능력이 증가하게 된다.
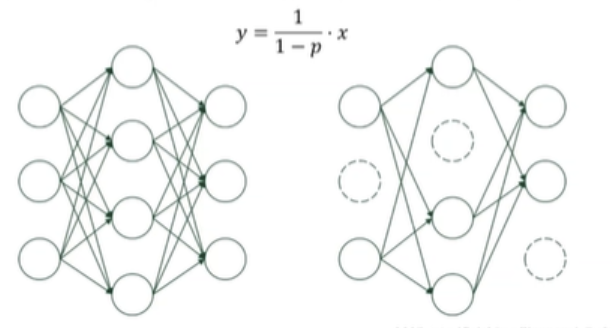
학습할 때는 뉴런을 끄지만, 추론할 때는 모든 뉴런을 켠 채로 예측을 수행한다.
추론 시
- dropout 은 꺼짐 : 더 이상 뉴런을 무작위로 제거하지 않음
- 모든 뉴런이 켜짐 : 네트워크 전체가 동작해야 예측 결과가 안정적으로 나옴
- scaling 불필요 : 학습 시 dropout 때문에 출력을 보정했었지만, 추론 시에는 뉴런을 모두 쓰기 때문에 스케일링이 더 이상이 필요 없음
왜냐, 추론 시에는 매번 예측 결과가 다르면 안되고 drop없이 전체 뉴런을 이용해 예측해야 정확하다 !
