Sequential Data
- 기존의 신경망 (CNN, FCN)은 입력 간에 시간적 순서나 연관성이 없다고 가정했다.
- 하지만, 현실의 많은 데이터는 순서가 중요하다
→ 이런 것들을 시퀀스 데이터라고 한다.
어떤 데이터가 시퀀스 데이터일까 ?
- 자연어 (Natural Language) : 문장의 의미는 단어의 순서에 따라 달라진다.
- 시계열 데이터 (Time Series) : 주가, 날씨, 심전도 등은 시간 순서대로 분석해야 의미가 있다.
- 음성 인식 (Speech Recognition) : 음소(발음 단위)는 시간 순서대로 발생한다.
왜 기존 신경망으로는 부족할까 ?
Fully Connected Layer와 CNN 은 모든 입력을 독립적으로 처리한다. 하지만 시퀀스 데이터는 과거 정보에 따라 현재 해석이 달라져야한다.
- 시간 개념이 없다 (No temporal memory)
- 순서 정보 손실 (Loss of sequential order)
- 고정된 입력/출력 크기만 가능 (fixed input/output size)
- 문맥 의존성 모델링 불가능
- 장기 의존성 (long-term dependency)에 대한 일반화 부족
- 많은 목적은 시간 흐름을 인식해야함
RNN
RNN은 입력 시간 순서대로 하나씩 처리하며, 이전 정보를 기억하는 hidden state 를 유지하는 구조이다.

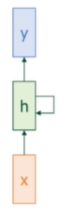
- x : 현재 입력
- h : 현재 hidden state (기억)
- y : 현재 출력
모든 시점에서 같은 가중치 W를 재사용함.
즉, 시간에 따라 모델 구조는 같고, 파라미터도 공유된다. → 시간에 따른 일반화에 유리하고, 학습 파라미터도 줄어든다.
RNN Unrolling
RNN을 시간 축으로 펼쳐서 이해를 해보면
RNN은 '하나의 셀' 을 매 시간마다 반복해서 재사용한다. 단, 그 내부 hidden state는 이전 시간 정보를 다음 셀로 전달하면서 기억을 이어나간다.
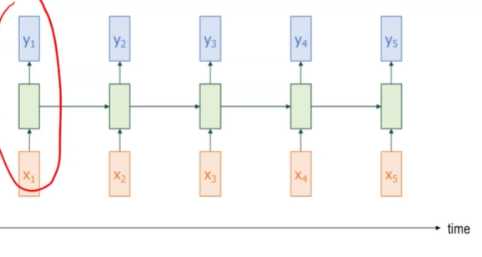
- 하나의 RNN 셀이 반복적으로 재사용됨
→ 매 시점마다 입력을 받고, 이전 hidden state와 함께 현재 출력을 계산한다. - hidden state 가 앞으로 전달되며, 네트워크는 기억을 유지하게 된다.
- 이런 구조 덕분에 RNN은 '이전까지의 맥락'을 이해하면서 현재를 판단할 수 있다.
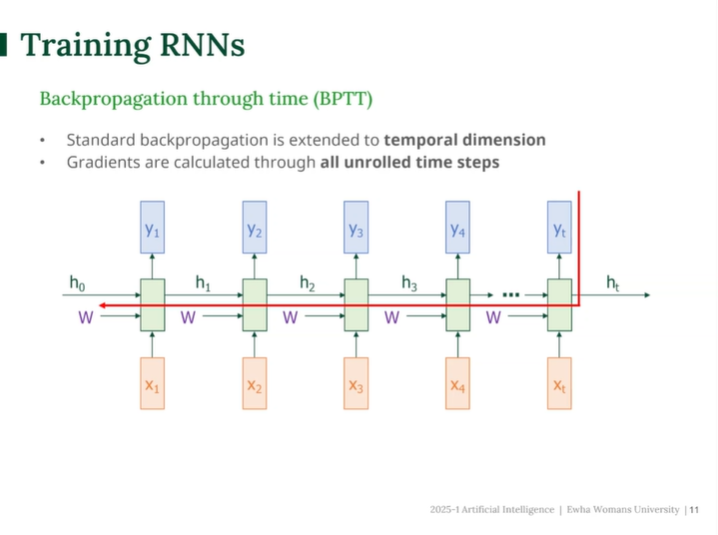
BPTT (Backpropagation Through Time)
RNN 학습 : 시간에 따른 역전파
일반적인 신경망은 '정방향 → 역방향'으로 학습하지만, RNN은 시간 축으로 펼쳐(unroll)있기 때문에 모든 시간 단계 전체에 대해 역전파를 진행해야한다.
RNN의 대표적인 활용 사례
- 감정분석 (sentiment analysis)
- 언어 모델링 (language modeling)
- 시계열 예측 (time series forecasting)
- 음성 인식 (speech recognition)
Vanishing Gradient Problem (기울기 소실 문제)
RNN은 시간축을 따라 긴 입력 시퀀스를 학습하지만, 그만큼 이전 시점으로 멀리 갈 수록 gradient가 급격히 작아지는 문제가 생긴다.
BPTT (Backpropagation Through Time) 흐름
- 출력 에서 발생한 손실을 시간축을 따라 역으로 까지 전파해야한다.
문제 핵심
- 여기서 tanh` (tanh의 미분값)는 그래프를 보면 대부분 입력 영역에서 값이 0에 가까움.
- 이 작은 값들이 시간 단계마다 계속 곱해지면, gradient는 지수적으로 줄어들어 사라지게 된다.
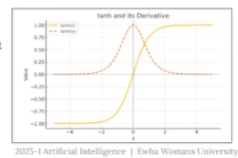
- 노란선 : tanh 함수 (출력 -1 ~ 1로 제한)
- 주황선 : tanh 미분값
입력이 크거나 작을수록 도함수 값은 0에 수렴함. 즉, 역전파 중에 gradient가 거의 전달되지 않음
Short-term Memory
RNN은 이전 정보를 hidden state로 계속 전달하지만, 시간이 지나면 초기 정보가 희미해져서 잊혀진다. → 장기 의존성 (long-term dependency) 을 기억하기 어려움
LSTM (Long Short-Term Memory) 0
장기 기억 유지를 위해 정보 흐름을 게이트로 조절하는 구조
- 기존 RNN은 기억을 hidden state 하나에만 의존했기 때문에 정보가 쉽게 사라졌다.
- LSTM은 cell state 라는 별도의 통로를 만들어 정보를 오래 보관할 수 있도록 설계하였다.
- 이를 위해 3개의 게이트를 도입하였다.
LSTM 구조 : 3가지 게이트
- Forget Gate : 이전 셀 상태에서 무엇을 잊을지 결정
- Input Gate : 새로운 정보를 얼마나 저장할지 결정
- Output Gate : 최종 hidden state 를 얼마나 출력할지 결정
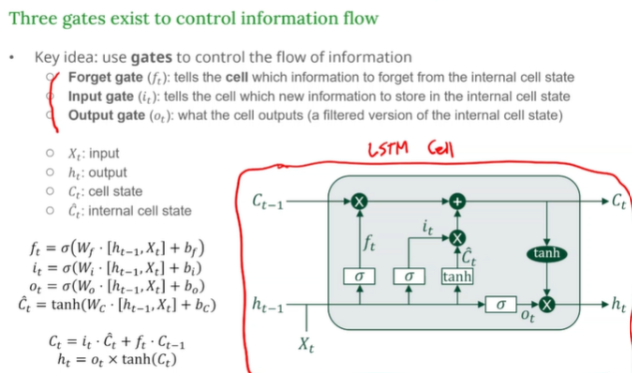
과정
- 입력 와 이전 hidden state 가 들어온다.
- 위쪽 cell state 은 직접 흘러가면서 정보를 유지한다.
- 세 개의 게이트가 정보 흐름을 조절한다.
- 최종적으로 , 가 각 각 새로운 셀 상태, 출력으로 나간다.
LSTM이 Vanishing Gradient 를 막는 핵심 구조
덧셈 기반 경로로 gradient가 사라지지 않고 흐를 수 있도록 만든다.
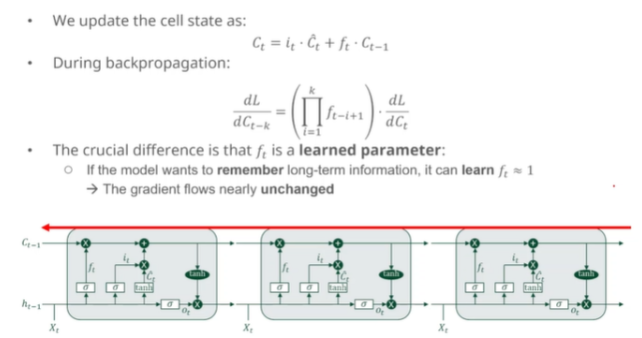
- 각 시점의 셀 상태 들이 쭉 연결된다.
- 이 연결은 덧셈 구조 기반이라서 gradient가 줄어들지 않고 전달된다.
- 즉, LSTM은 장기 의존성을 유지할 수 있는 구조이다
Seq2Seq : Sequence-to-Sequence
하나의 시퀀스를 입력받아, 또 다른 시퀀스를 출력하는 모델
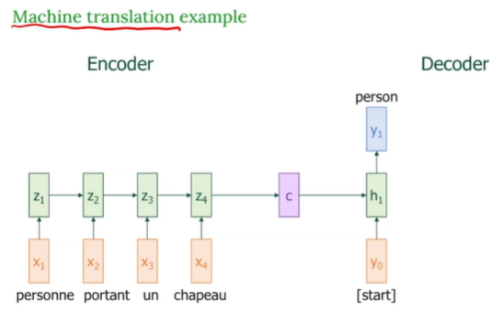
Encoder
입력 문장 : personne portant un chapeau
불어로 '모자를 쓰고 있는 사람'
- 각 단어는 embedding 후 RNN (혹은 LSTM) 에 들어감.
- 마지막 hidden state 가 문장 전체의 정보를 압축해서 c라는 context 벡터로 전달됨
Decoder
- 시작 토큰을 입력으로 넣고, context c와 함께 첫 hidden state 계산
- h1을 기반으로 첫 단어 y1을 예측
- 이후에는 이전 출력 y1을 다음 입력으로 사용하여 반복 예측
