인공지능
1.[인공지능] Course Introduction

위키피디아에 따르면 'AI는 기계에 의해 나타나는 지능이다.' 그렇다면, 지능(intelligence)란 ? 인간처럼 행동하는 것인지, 아니면 올바르게 생각하는 것인지에 따라 기준이 달라짐 사고 과정과 추론 능력을 중요시할 수도 있고, 지능적인 행동을 할 수 있는지를
2.[인공지능] 딥러닝 (Deep Learning)
이것은 고전적 조건화 (Classical Conditioning)을 신경망과 연결해서 설명한 것이다. 실험 (1) 강아지는 음식을 보면 침을 흘린다. 생물학적으로 음식 자극이 salivation neuron(침 흘리는 신경)을 자극해서 반응이 일어나는 구조이다. 실험
3.[인공지능] 인공 신경망 (Artificial Neural Networks)
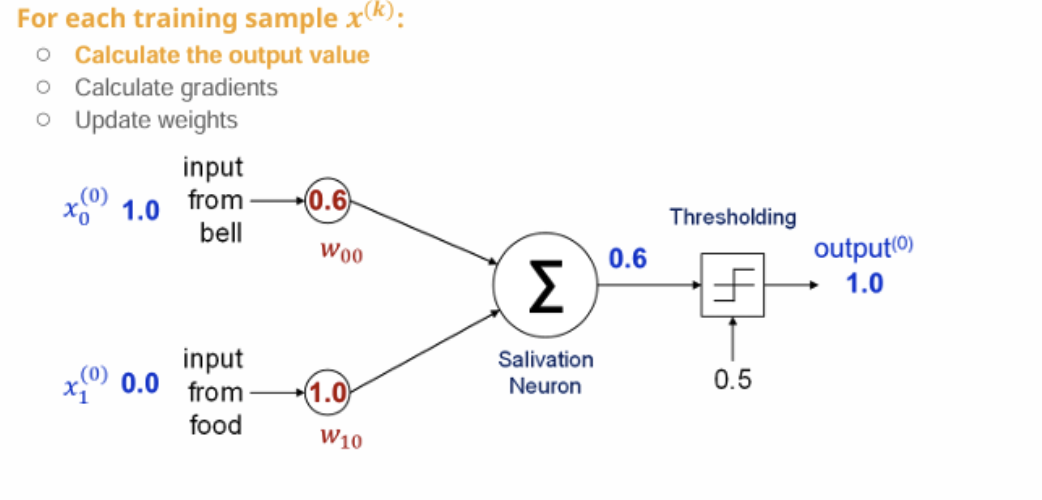
Pavlov's Dog 실험을 신경망으로 설명하기 음식만 제공 → 반응함 벨만 주면 → 반응 없음 → 사진이 잘못되어있지만, 그 input from bell 부분에 1.0 이 되고 input from food 부분이 0.0 이 되어야한다. 훈련하는 단계 음식과
4.[인공지능] 다층 퍼셉트론 (Multi-Layer Perceptron)
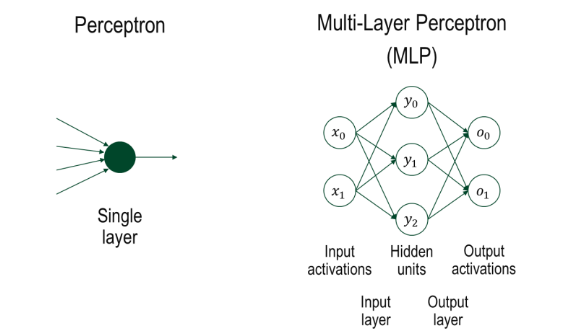
지금까지는 단일 퍼셉트론(Single Layer Perceptron), 단일 뉴런 구조 에 대해서 배웠다. 단일 퍼셉트론은 뉴런 하나 또는 뉴런들이 한 층만 있는 구조를 말한다. 학습도 이 한 층 뉴런에서만 이루어진다. 또한 은닉층이 없어 복잡한 비선형 문제에서는 학습
5.[인공지능] 심층 신경망 (Deep Neural Network)
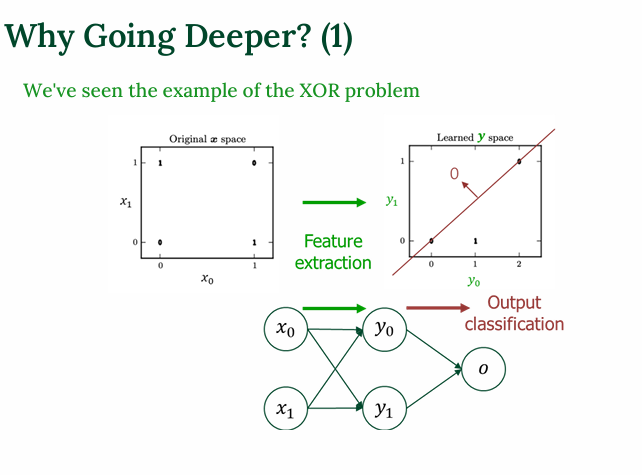
앞에서는 지금까지 단일 퍼셉트론부터, 은닉층이 존재하는 다층 퍼셉트론에 대해서 보았다. 지금 볼 심층 신경망은 Deep Neural Network에 해당하며 여러개의 은닉층을 가지고 있다. 이는 MLP(Multi-layer Perceptron)의 확장된 형태라고 보면
6.[인공지능] 활성화 함수 (Activation Function)
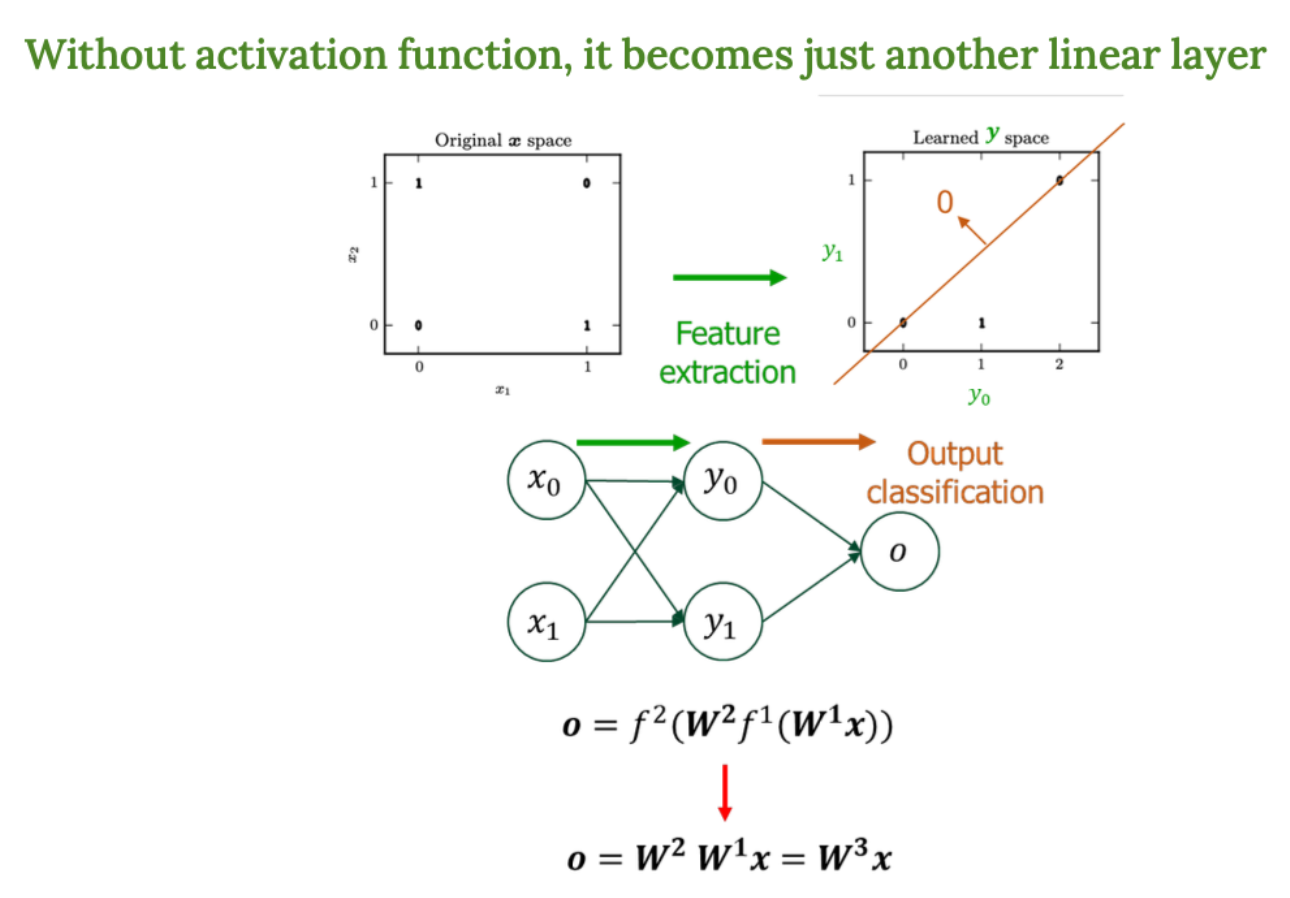
활성화함수가 없으면 신경망은 그냥 선형 함수의 조합일 뿐이다. original x space 입력 벡터 x의 원래 공간 선형적으로 이 데이터를 구분할 수 없음 learned y space 은닉층을 통과한 후의 공간 (feature extraction 완료된 공간) 이제
7.[인공지능] 딥러닝 기반 얼굴 인식 모델
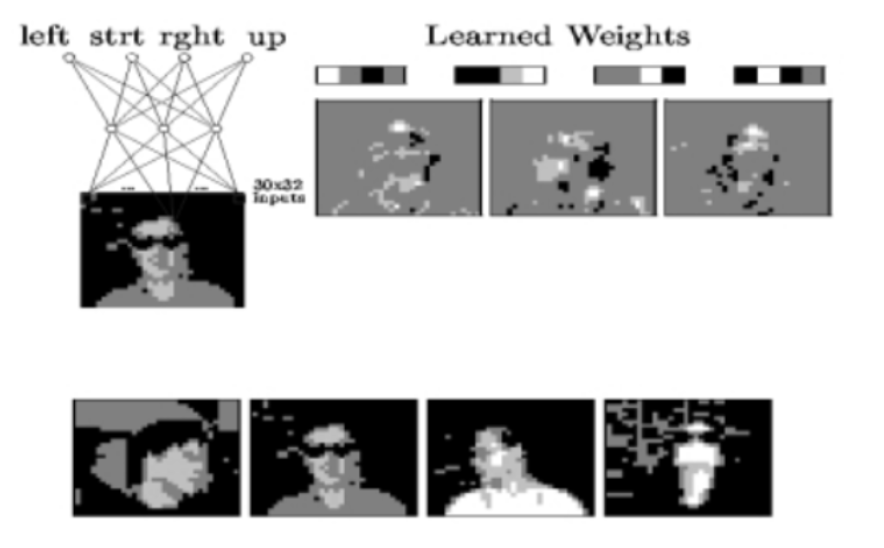
사람이 정면(straight), 좌(left), 우(right), 위(up)을 바라보는지를 예측한다. 입력 : 사람의 얼굴 이미지 (흑백) 출력 : 그 사람이 어디를 바라보는지 예측 (left, right, straight, up) 총 624장의 이미지 (20명 \*
8.[인공지능] Training Dynamics
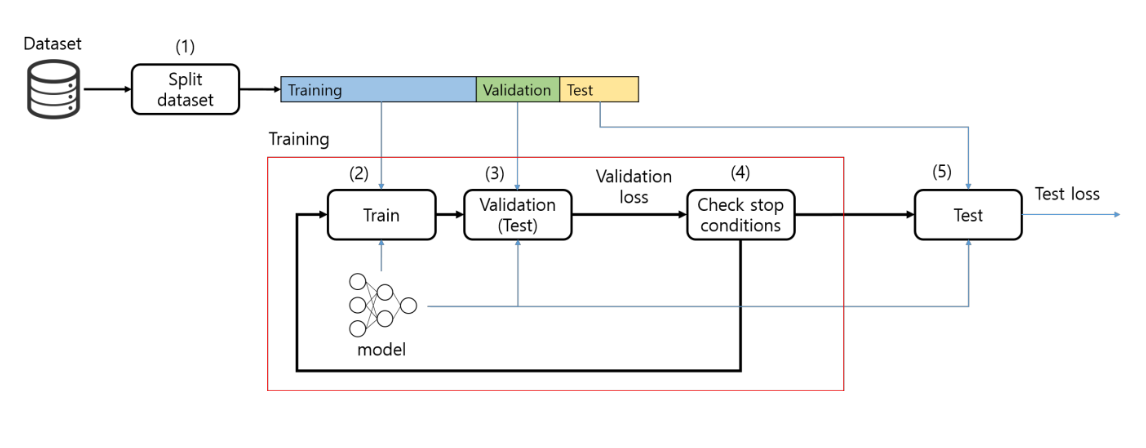
데이터셋을 3부분으로 나눔 Training Set (훈련셋) : 모델이 학습하는 데 사용하는 데이터 이걸로 가중치를 조정한다. Validation Set (검증셋) : 학습 도중 모델이 잘 학습하고 있는지, 과적합(overfitting) 되고 있는지를 판단하기 위해 사
9.[인공지능] PyTorch (파이토치)

딥러닝 프레임워크는 연구자나 엔지니어가 딥러닝 모델을 설계하고 학습시키기 위해 사용하는 소프트웨어 패키지 목적 : 복잡한 수학적 알고리즘이나 딥러닝 내부 구조를 깊이 이해하지 않더라도, 모델을 설계하고 학습시킬 수 있게 도와줍니다. 계산 그래프 생성 지원 연산 과정을
10.[인공지능] PyTorch로 Neural Network 만들고 학습하기
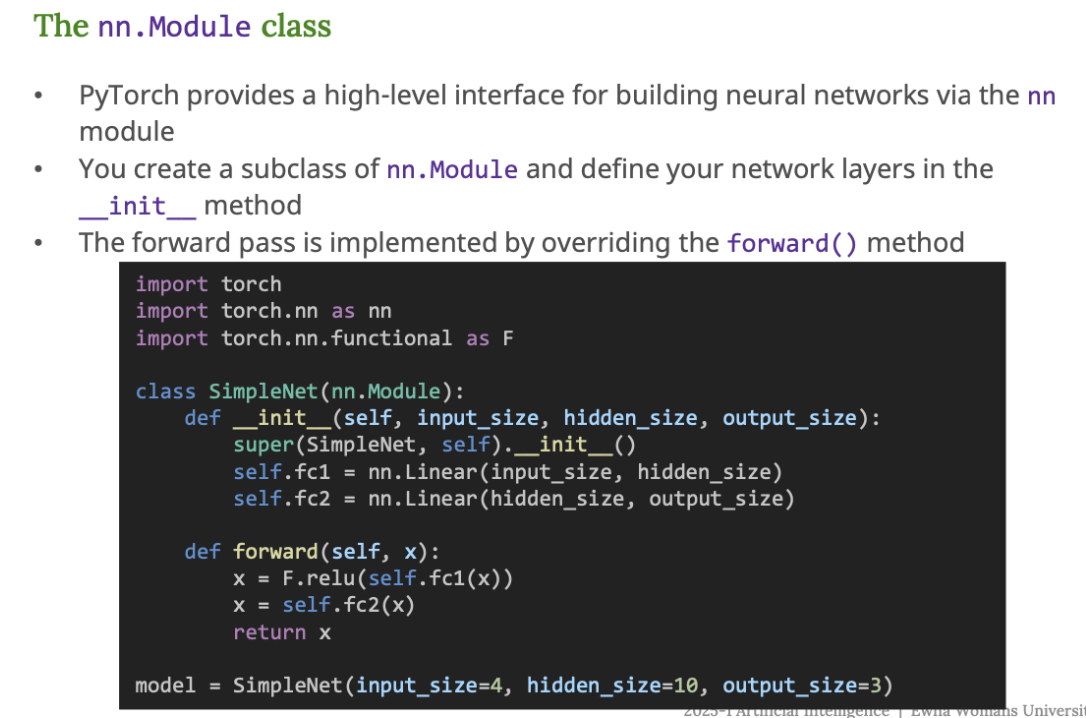
잠깐 다시 Neural Network란 뭘까, 생각해보면, Neural Netword(신경망) 은 간단히 말해 사람 뇌의 뉴런 구조를 본떠서 만든 수학적 모델이다. 사람 뇌와 비교해보자면, 사람 뇌에는 뉴런이 있는데 뉴런은 신호를 받아서 처리한 뒤 다른 뉴런에게 전달을
11.[인공지능] PyTorch로 분류 모델 만들기 정리
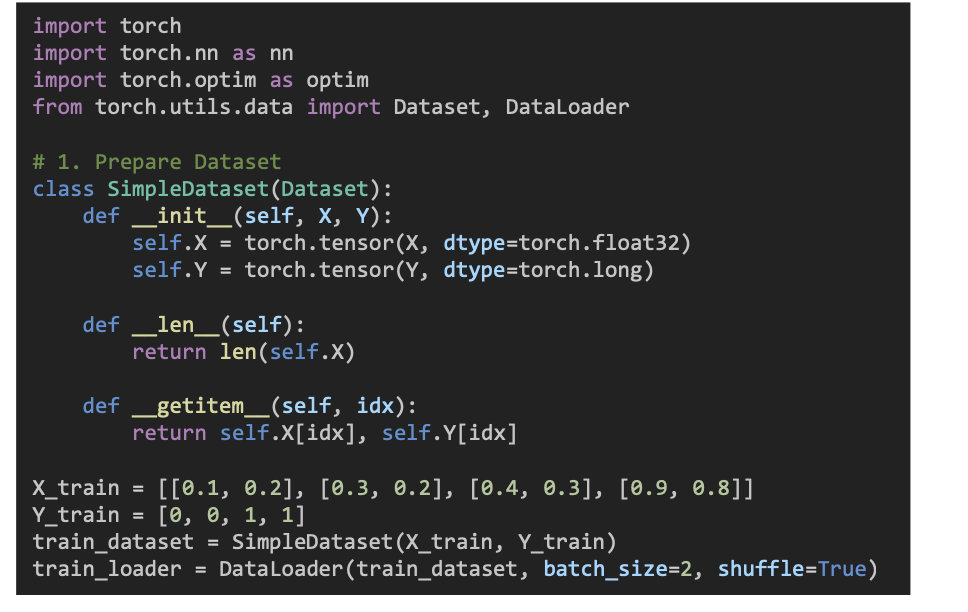
X : 입력 데이터 (예 : 키, 몸무게) Y : 정답 클래스 (예 : 0 = 남자, 1 = 여자) 둘을 PyTorch가 처리할 수 있게 Tensor로 변환 데이터를 2개씩 나눠서(batch) 학습하고, 순서도 섞어서 (shuffle) 학습 효과를 높이려는 설정 fc1
12.[인공지능] CNN (Convolutional Neural Network, 합성곱 신경망)
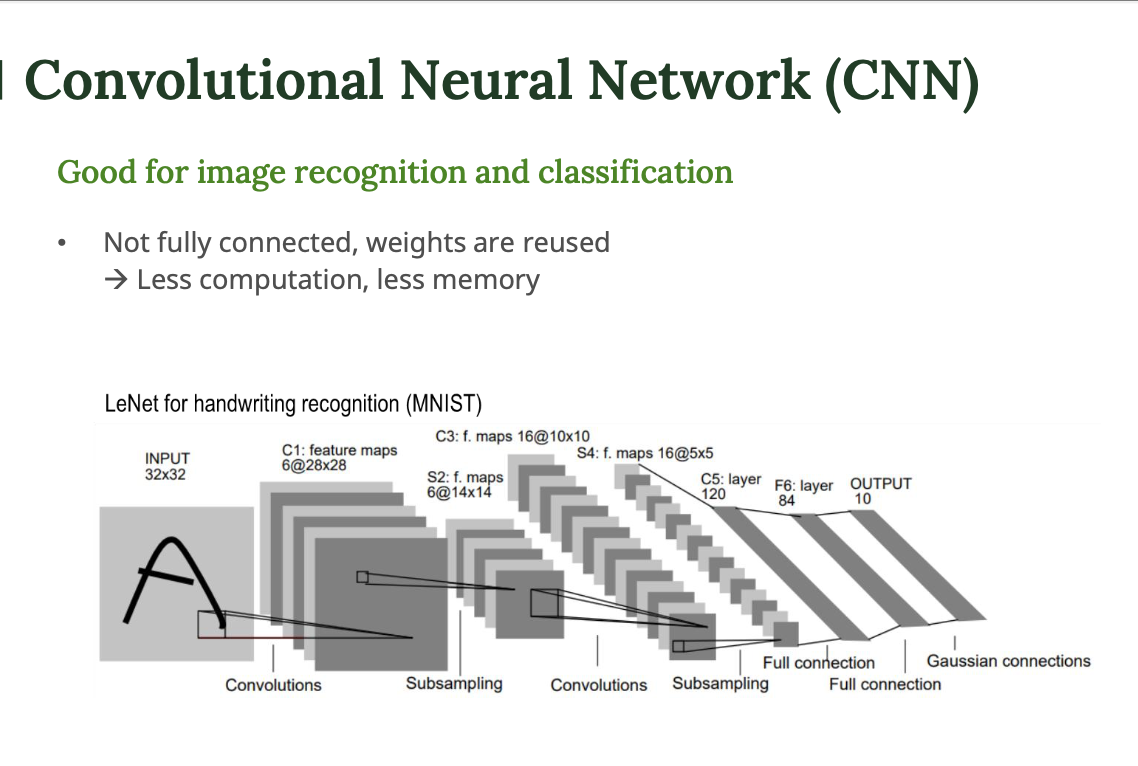
잠깐 CNN을 이야기하기 전에 Fully-connected Layer 에 대해서 이야기를 해보자면 일반적인 인공신경망에서는 모든 입력 노드가 모든 출력 노드와 연결되어 있다. 이를 fully-connected layer라고 한다.
13.[인공지능] 완전한 합성곱 계층
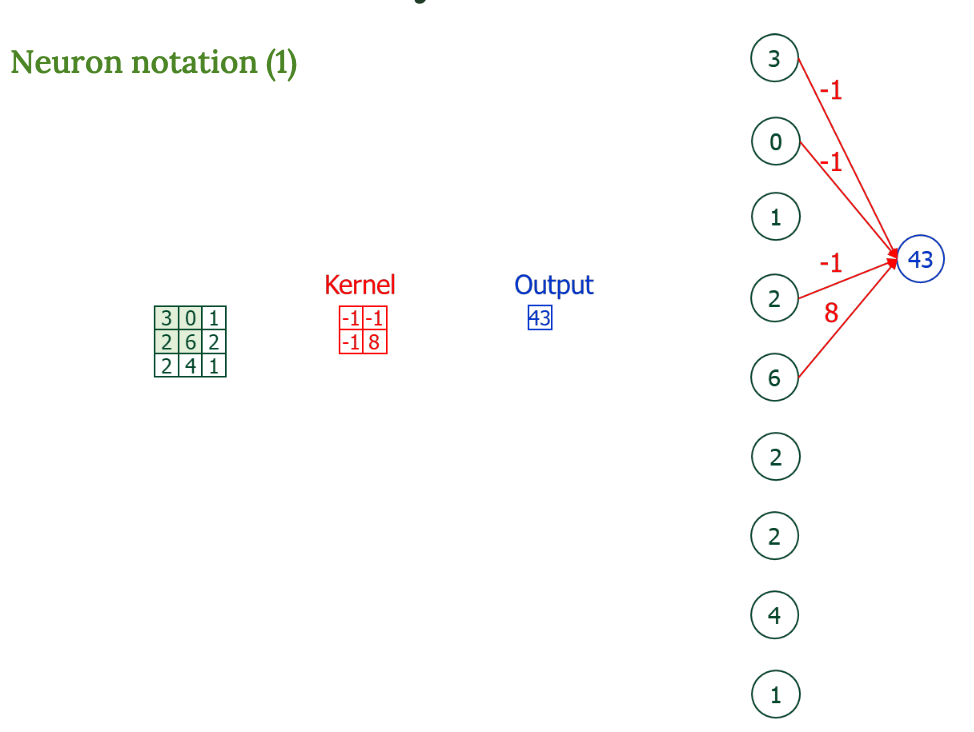
입력(3D input feature map) : RGB 이미지라면 3개의 채널이 있고, 각 채널별로 픽셀값이 있다. 3D 필터 : 이 필터도 3채널(입력 채널과 동일)을 가짐이거를 하나의 덩어리로 취급해서 곱하고 더함출력 : 곱하고 더한 결과를 하나의 값으로 만들어서
14.[인공지능] Various CNN Model
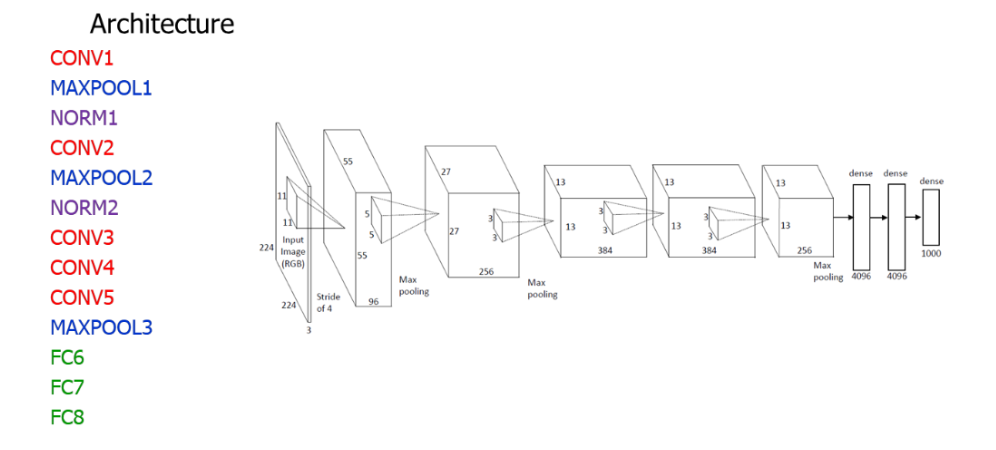
AlexNet 은 Alex Krizhevsky라는 사람이 만든 모델 2012년 ILSVRC(이미지넷 대회)에서 우승하면서 엄청 유명해짐 모델 구조는 아래처럼 진행됨 구조 그림을 보면 처음엔 큰 입력 이미지 (224x224x3) 여러 번 Convolution + Pool
15.[인공지능] MobileNet
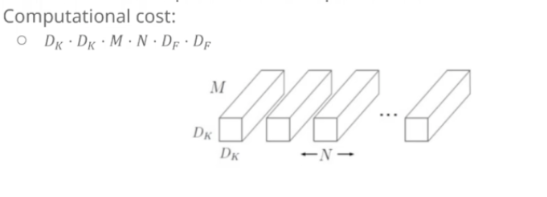
Standard Convolution 표준 합성곱은 계산량이 엄청 많다. 특히, 입력 채널수와 출력 채널수가 많은 경우 더더욱 많다. 표준 합성곱에서는 특징 추출(filtering features)와 combining(결합)이 반복되면서 이루어지게 된다. 이를 해결하기
16.[인공지능] CNN (Convolutional Neural Network)
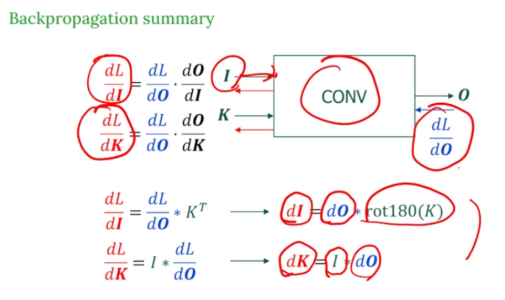
전체 구조 : Forward → Backward 입력 I와 필터 K를 convolution을 하여 출력 O를 계산한다. 우리가 구해야 하는 gradient는 2개이다. 입력에 대한 loss 변화율 필터에 대한 loss 변화율
17.[인공지능] RNN (Recurrent Neural Network)
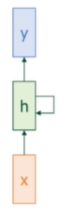
기존의 신경망 (CNN, FCN)은 입력 간에 시간적 순서나 연관성이 없다고 가정했다. 하지만, 현실의 많은 데이터는 순서가 중요하다 → 이런 것들을 시퀀스 데이터라고 한다. 어떤 데이터가 시퀀스 데이터일까 ? 자연어 (Natural Language) : 문장의 의미는
18.[인공지능] Attention (어텐션)
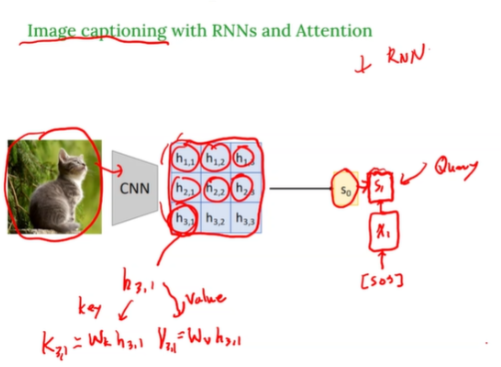
기본 Seq2Seq의 한계 Seq2Seq : LSMT을 기반으로 구성된 Encoder-Decoder 구조 Encoder가 전체 입력 문장을 하나의 벡터 c로 요약했기 때문에, 긴 문장에서는 정보 손실이 발생 → Decoder가 제대로 번역하지 못함 문제점 긴 문장을
19.[인공지능] Transformer
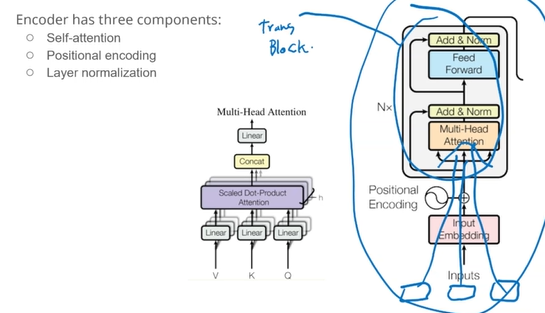
기존 RNN, LSTM의 한계를 극복함 병렬 처리 가능 → 속도 개선 긴 문맥 의존성 처리 가능 → 문장 길이가 길어도 성능 유지 기계 번역 (Machine Translation) 분야에서 SOTA (최신 최고 성능)을 달성 BERT (Bidirectional Enco
20.[인공지능] Transformer Models
Transformer Models
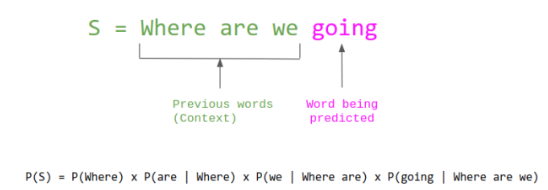
21.[인공지능] Large Language Model (LLM)
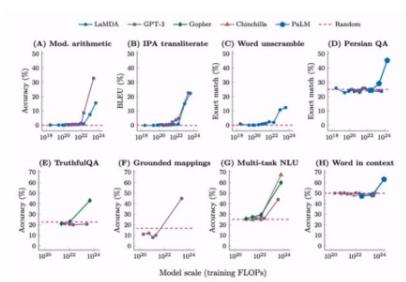
LLM은 매우 큰 규모의 파라미터와 데이터를 기반으로 훈련된 Autoregressive Transformer 모델을 의미한다. 보통 GPT 계열처럼 Decoder-only 구조를 따르며, 다음 단어를 예측하는 방식으로 작동한다. Autoregressive 모델 : 순차
22.[인공지능] Vision Transformer
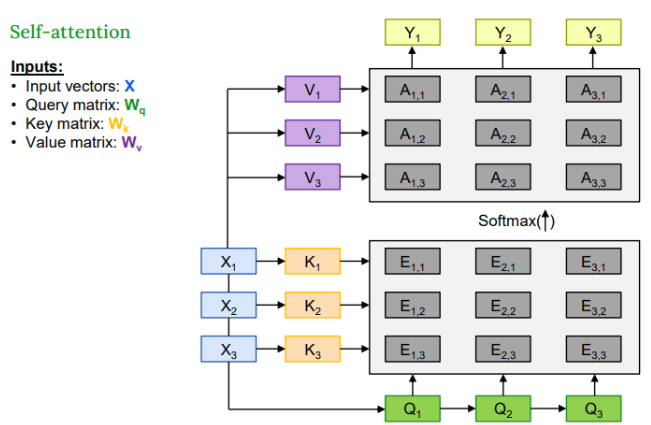
CNN은 필터를 사용하여 이미지의 공간적 패턴을 학습한다. 모델이 훈련 데이터 밖의 일반화를 가능하게 해주는 선천적인 가정들 예시 local connectivity : 각 뉴런은 입력의 일부분만 본다. translation equivariance : 필터가 어디를 보든
23.[인공지능] Diffusion Model
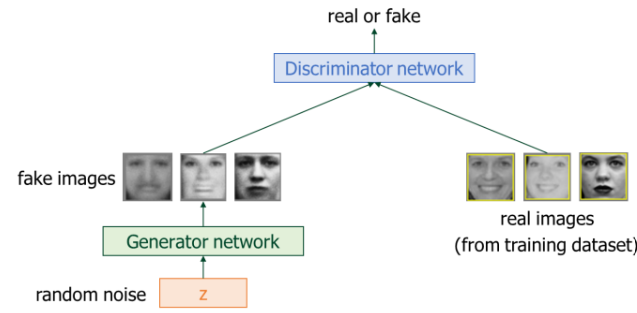
Discriminative Model (판별 모델) : 조건부 확률을 학습하여 , 이미지가 입력하면 그것이 어떤 클래스인지 예측하는 모델 → 새로운 데이터를 만들지 않고, 단지 입력을 분류한다. p(x) (입력 자체의 분포) 를 모델링 이미지를 분류하는 게 아니라, 직