Diffusion Model
Discriminative Model (판별 모델) : 조건부 확률을 학습하여 , 이미지가 입력하면 그것이 어떤 클래스인지 예측하는 모델
→ 새로운 데이터를 만들지 않고, 단지 입력을 분류한다.
Generative Model
p(x) (입력 자체의 분포) 를 모델링
- 이미지를 분류하는 게 아니라, 직접 이미지 자체를 만들어 낸다.
- 생성된 이미지는 훈련 데이터를 흉내낸 것이지만, 실제로는 존재하지 않았던 새로운 데이터이다.
VAE (Variational Autoencoder)
구조
- Encoder : 입력 x → 잠재 벡터 z (분포 파라미터로 표현)
- Decoder : 잠재 벡터 z → 재구성된 이미지
특징
- 단순 복사 아님. 확률분포로 인코딩
- Latent space 에서 새로운 샘플 생성 가능
GAN
- Generator = 범죄좌 = 진짜처럼 보이는 가짜 돈을 만듦
- Discriminator = 경찰 = 진짜와 가짜를 구분하려 함
구조
- Generator 는 Discriminator를 속이도록 학습
- Discriminator는 점점 더 잘 구분하려고 학습
- 두 네트워크가 적대적으로 경쟁
결과적으로, Generator는 점점 더 진짜 같은 이미지를 만들게 됨. GAN은 매우 강력하지만, 학습이 불안정하고 mode collapse 문제가 발생할 수 있다.
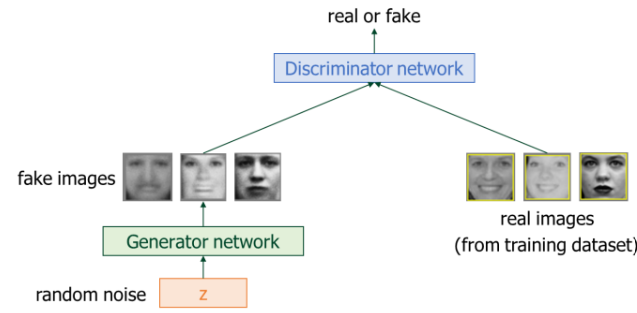
입력 z : 무작위 노이즈 벡터 (latent code)
Generator : z → 가짜 이미지 생성
Discriminator : 진짜 이미지와 가짜 이미지를 비교 → 'real or fake' 판단
💡Diffusion Model
생성 모델의 목적 : 실제와 비슷한 데이터를 샘플링할 수 있도록 데이터 분포 를 학습
기존 방법들
- VAE : 학습이 빠르지만 생성 이미지가 다소 흐림 (blurry)
- GAN : 이미지는 선명하지만 학습이 불안정 (적대적 훈련, 모드 붕괴)
Diffusion Model의 장점
- 강건한 학습 : 확률 기반으로 안정적으로 학습
- 학습이 감독 학습처럼 작동
- Generator/Discriminator 같은 경쟁 구조가 없음
- 훈련이 덜 민감하고 실패 위험이 적음
단점
- 속도가 느림 (학습과 생성 모두 수백~수천 스탭)
🔁 Diffusion Model의 작동 원리
Diffusion Model은 '노이즈를 추가했다가, 다시 제거하는 과정' 을 통해 이미지를 생성한다. 이 과정을 크게 2 단계로 나눌 수 있다.
1. Forward Process (노이즈 추가)
- 깨끗한 이미지 가 가우시안 노이즈를 조금씩 추가한다.
- 이 과정을 T번 반복하면, 결국 완전히 무작위적인 노이즈 이미지 가 된다.
2. Reverse Process (노이즈 제거)
- 이제는 완전히 무작위한 노이즈 에서 시작해서, 깨끗한 이미지 를 복원하는 것
- 이때 사용하는 것이 노이즈 예측 모델
- 이 모델은 주어진 와 시간 t를 입력받아, 그 시점에서 추가되었던 노이즈를 예측한다.
🧠 학습 방법 : 노이즈 예측
Diffusion 모델의 핵심은 노이즈 예측 문제로 바꿔서 학습하는 것에 있다.
- 목표는 노이즈가 추가된 이미지 를 보고 추가된 노이즈를 정확히 예측하는 것
- 이를 위해 사용하는 손실 함수는 단순한 L2 Loss
UNet
Diffusion Model 안에서 사용되는 구조 = 노이즈 제거 네트워크
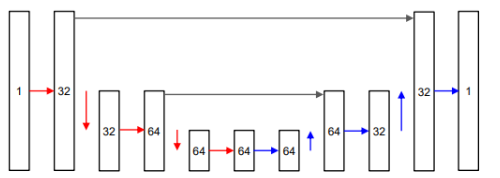
왼쪽 : Encoder (Down path)
- 이미지를 작게 줄여나가면서 특징(feature)을 뽑음
- 여기서 사용된 것은
Residual → GroupNorm → Swish순서로 반복 - 빨간색 ↓ : 해상도 줄이기 (stride=2)
가운데 : Bottleneck
- 해상도는 가장 작고, 대신 Self-Attention으로 전역 정보 처리
오른쪽 : Decoder (Up path)
- 이미지를 다시 크게 키움
- 파란색 ↑ : 해상도 증가 (Transposed Convolution 사용)
- Skip connection으로 왼쪽 정보를 다시 붙여서 복원력을 높임
Time Embedding
- 각 단계 t에 따라 학습 방식이 달라지기 때문에, 시간 정보를 sin/cos → MLP → residual block에 추가
왜 U-Net일까 ?
장점
- 멀티스케일 구조라서, 이미지를 여러 크기 단위로 본다
- Skip Connection 덕분에 Encoder에서 사라졌던 세세한 정보(고주파, 엣지 등)을 다시 복원 가능하다.
- 구조 확장도 쉽다. (채널 수나 블록 수만 늘리면 됨)
Text-to-Image 용 UNet : 텍스트 프롬프트를 따르게 만들기
텍스트도 입력으로 넣어보자 !!
순서
- 텍스트 문장을 Tokenize
- Text Encoder로 임베딩 : 각각의 단어를 벡터로 변환
- 여기서 사용하는 Text Encoder는 보통 CLIP의 텍스트 부분
- 이 단계는 딱 한번만, 그리고 frozen (고정됨!) → 학습 안 함.
- Cross-Attention 으로 텍스트 연결하기 !
- 이미지의 각 부분이 텍스트 벡터들을 참조해서 묻는 것임.
"나는 이미지의 이 위치야. 어떤 단어가 나랑 관련이 있을까?" - 예 : 이미지의 귀 부분 → "cat" 벡터에 집중
이미지의 머리 위 → "hat", "red"에 집중 - 그렇게 해서, 그 단어의 벡터에서 정보를 받아오고 그걸 이용해 해당 위치의 노이즈를 제거함
📌 Cross-Attention ?
이미지의 현재 특징 (=Query)이 텍스트의 의미(Key/Value)을 보면서 '내가 지금 참고할 단어가 뭐지?'를 고르는 매커니즘
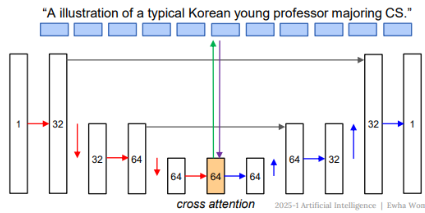
주황색 블록(UNet의 한 지점)이 위쪽 파란 상자들(텍스트 벡터들)을 참조한다.
