Vision Transformer
🔁 Recap : CNN
CNN은 필터를 사용하여 이미지의 공간적 패턴을 학습한다.
🧠 Inductive Bias (귀납적 편향)
모델이 훈련 데이터 밖의 일반화를 가능하게 해주는 선천적인 가정들
예시
| 모델 | 내재된 가정 (Built-in Assumptions) | 결과 (Consequence) |
|---|---|---|
| Linear Regression | 선형성 (Linearity) | 해석이 쉬움, 간단함 |
| CNN | 지역성, 이동 불변성 | 이미지에 적합, 데이터 효율성이 좋음 |
- local connectivity : 각 뉴런은 입력의 일부분만 본다.
- translation equivariance : 필터가 어디를 보든 간에 같은 패턴을 감지할 수 있도록 이동 불변성을 보장한다.
장점
- 효율적이고, 데이터가 적어도 잘 학습한다.
- 이미지처럼 그리드 구조의 데이터에 적합하다.
한계
- receptive field 가 천천히 넓어짐 : 멀리 떨어진 정보는 깊은 층에 가서야 통합이 가능하다.
- long-range dependency : 멀리 떨어진 픽셀 간의 관계를 모델링하는 데 불리하다.
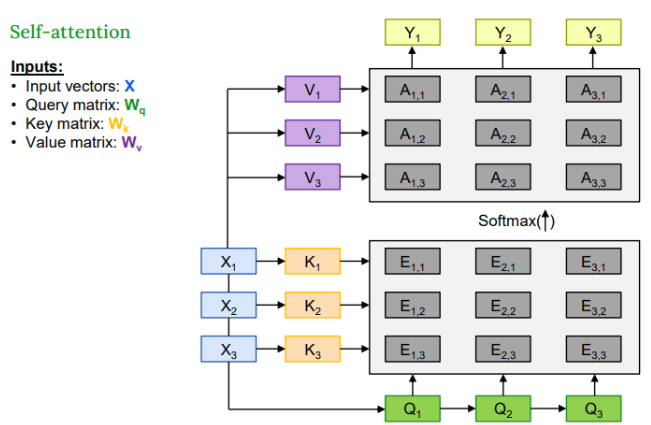
🔁 Recap : Self-Attention
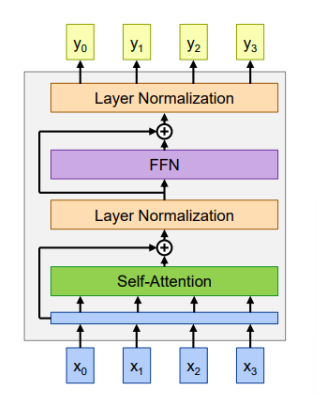
🔁 Recap : Transformer
Vision에서의 과제
- 이미지는 2D 격자 구조로, Transformer에 넣기 위해서는 이미지르 1D 토큰 시퀀스로 바꿔야한다.
- 보통 ViT에서는 이미지를 16*16 같은 패치 단위로 잘라서, 각 패치를 1개의 토큰으로 임베딩한다.
ViT
- Vit는 ImageNet을 포함한 다양한 이미지 분류 작업에서 최고 성능을 기록하고 있다.
- ICLR 2021에서 최초로 제안한 Google의 논문
주요 아이디어
이미지를 패치로 나누고, 단어처럼 처리하자 !
CNN 없이 순수 Transformer만으로도 뛰어난 성능이 가능하다.
사전학습 (pre-training)을 통해 다양한 벤치마크에서 우수한 결과 달성
Patch Embedding (패치 임베딩)
핵심 과정
-
이미지를 고정 크기 패치로 자른다.
예) 224224 이미지를 1616 패치로
→ 총 14*14 = 196패치 -
각 패치를 '평탄화(flatten)' 해서 벡터로 만든다.
-
선형변환을 통해 D차원 임베딩 벡터로 투영 → 이것이 바로 patch token
즉, CNN에서의 Convolution Filter 출력 대신, 고정 패치를 임베딩으로 사용한다.
Vision Transformer 구성 요소
1. Class Token ( [CLS] )
- 학습 가능한 벡터 (초기값은 랜덤)
- 이미지 전체 정보를 요약하기 위해 Transformer 입력 맨 앞에 추가
- 마지막에 classification head에 이 토큰만 사용함
2. Positional Encoding
- Transformer는 위치 정보를 모으므로, 각 패치의 위치 인코딩이 필요하다.
3. Transformer Encoder Stack
- 동일한 구조의 블록을 L개 반복
- 각 블록은
- Multi-head Self-Attention
- MLP (GELU 활성화 함수 사용)
- Residual + LayerNorm
4. Classification Head
- [CLS] 토큰에만 MLP를 붙여 최종 클래스 예측
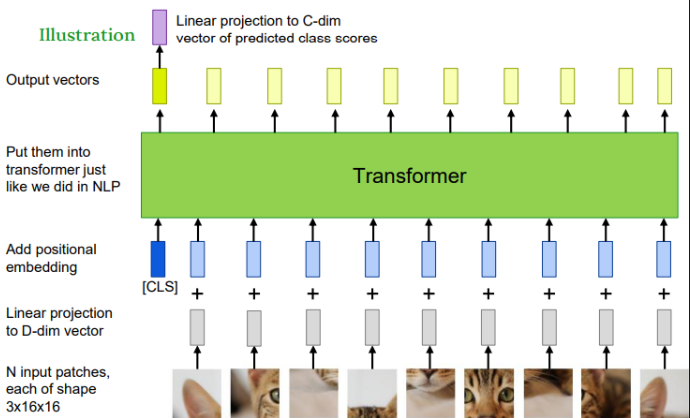
- 이미지를 패치 분할
- 각 패치를 D차원 벡터로 변환 (Linear Projection)
- 위치 인코딩 추가
- CLS 토큰도 같이 입력
- Transformer에 입력 → 여러 레이어를 통과
- 출력 중 [CLS] 토큰을 Linear Projection → Class Score
Training Pipeline (학습 흐름)
1. Pre-Training
- JFT-300M, ImageNet-21k 등 거대한 데이터셋에 먼저 학습
- self-supervised 방식이나 supervised 방식 모두 가능
2. Fine-tuning
- 실제 사용 목적에 맞는 작은 데이터셋에 미세 조정
- 예 : ImageNet-1k, CIFAR-10 등
3. Regularization Tricks (정규화 기법)
- Strong Augmentation : 데이터 다양하게 증강
- Token/channel dropout : 일부 입력 무작위 제거
- Stochastic Depth : 일부 레이어를 확률적으로 생략하며 regularization
Accelerating ViT Inference
핵심 개념 : 토큰 수를 줄여 추론 속도를 높이자.
1. Token Pruning (토큰 제거)
- 중요하지 않은 토큰 제거 → 연산 감소
- 정보 손실 위험이 있음
2. Token Merging (토큰 병합)
- 비슷한 토큰을 합침 → 정보 유지하면서 연산량 감소
→ ViT는 입력 토큰 수가 많을수록 연산이 많아지므로, 효율적 추론을 위해 토큰 수를 줄이는 기법들이 필수적이다.
