딥러닝 프레임워크
딥러닝 프레임워크는 연구자나 엔지니어가 딥러닝 모델을 설계하고 학습시키기 위해 사용하는 소프트웨어 패키지
- 목적 : 복잡한 수학적 알고리즘이나 딥러닝 내부 구조를 깊이 이해하지 않더라도, 모델을 설계하고 학습시킬 수 있게 도와줍니다.
주요 기능
- 계산 그래프 생성 지원
- 연산 과정을 노드로 구성하여 시각화 및 계산 가능
- 뉴럴 네트워크의 기본 구성 요소를 내장하고 있음
- 그래디언트 자동 계산
- 역전파를 직접 구현하지 않아도 됨
- GPU에서 효율적으로 실행 가능
- 대규모 연산을 빠르게 처리할 수 있음
Computational Graph (Numpy Implementation)
계산 그래프(computational graph)는 수학 연산을 노드와 엣지로 시각화하여 연산 과정을 트래킹하는 구조

문제점
- Numpy는 GPU를 사용할 수 없음
- 그래디언트를 직접 수동으로 계산해야함 → 번거롭고 실수하기 쉬움
Numpy vs. PyTorch
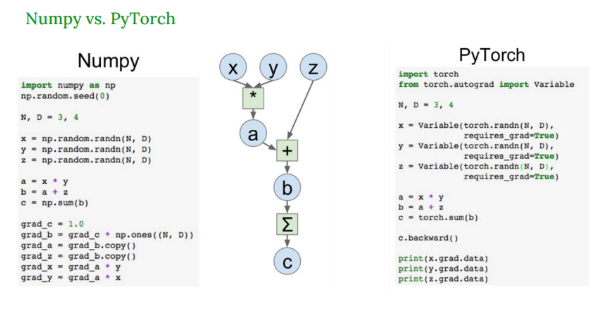
Numpy
- 연산과 그래디언트 계산을 수동으로 작성해야함 (
grad_b,grad_z등 직접 계산)
PyTorch
variable을 사용해requires_grad = True설정만 해주면 자동으로 계산 그래프를 만들고,backward()한 줄로 그래디언트를 자동 계산해줌- 매우 간단하고 실수 없이 빠르게 구현 가능
PyTorch
페이스북의 AI 연구소(FAIR)에서 개발한 딥러닝 프레임워크
특징
- 오픈소스이며, 학계와 산업계 모두에서 널리 사용됨
- 텐서(tensor) 연산을 효율적으로 지원하며, 자동 미분(autograd) 기능을 내장함
- 모델 설계와 학습이 간편하고 직관적임 → 연구자와 실무자 모두에게 인기가 많음
Tensor
Tensor는 벡터(vector)나 행렬(matrix)을 일반화한 다차원 배열
왜 텐서를 사용할까 ?
- 딥 러닝 모델의 입력 데이터가 대부분 다차원이다 !
- 이미지 데이터 (batch, channel, height, width) = 4D 텐서
- 자연어 처리 (batch, sequence_length, embedding_dim) = 3D 텐서
→ PyTorch는 이런 데이터를 통일되게 처리하기 위해서 모든 데이터를 텐서로 표현한다.
차원에 따라 다음처럼 분류가 가능하다
- 1D 벡터
- 2D 행렬
- 3D : 여러 개의 행렬을 포함하는 구조 (예 : RGB 이미지)
- 4D : 보통 딥러닝에서는 (batch, channel, height, width) 구조로 4D 텐서를 많이 사용함
PyTorch에서는 torch.Tensor 가 기본 데이터 구조임
텐서 생성 방법
- Python 리스트로부터 텐서 생성
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
- 지정된 shape로 텐서 생성
shape = (2, 3)
torch.rand(shape) # 0~1 사이의 랜덤 값
torch.ones(shape) # 모두 1
torch.zeros(shape) # 모두 0
텐서 속성들
tensor.shape: 텐서의 차원 정보tensor.dtype: 데이터 타입 (예 :float32,int64)tensor.device: CPU에 있는지, GPU에 있는지
print(f"Shape: {x_data.shape}, Data type: {x_data.dtype}, Device: {x_data.device}")
텐서 연산 지원
- 산술 연산 : +, - , *, /
- 행렬 곱 : @ 또는
torch.matmul() - 브로드캐스팅, 인덱싱, 슬라이싱 등도 가능
x = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
y = torch.tensor([[5, 6], [7, 8]], dtype=torch.float32)
z = x + y # 원소별 덧셈
matmul_result = x @ y # 행렬 곱
Automatic Differentiation (Autograd)
Autograd란 ?
- 텐서의
requires_grad = True설정시, PyTorch가 계산 그래프를 자동으로 생성하고 미분(gradient)를 자동 계산해준다. - 연산 결과로 나온 텐서가 이전 연산을 모두 추적할 수 있도록 연결된다.
Autograd 예시

- 포인트
x.grad:out을x에 대해 미분한 결과- 연산이 일어날 때마다 계산 그래프가 자동 생성
backward()호출 시 역전파 수행
Inference Mode
추론 시 (모델 예측만 할 때)
- 학습(training) : 정답이 있는 데이터(label)로 모델을 학습시키는 과정
- 추론(inference) : 학습이 끝난 모델을 가지고 예측만 하는 과정
→ 추론을 할 때는 오직 forward 연산만 수행하고, 역전파는 하지 않기 때문에 gradient 계산이 필요 없다 !
학습이 아니라 추론(inference)만 할 경우 torch.no_grad() 로 감싸면 성능과 메모리 절약 가능

requires_grad = True를 사용하지 않아도 되고, 계산 그래프도 만들지 않아서 훨씬 빠름
