잠깐 다시 Neural Network란 뭘까 ?
Neural Netword(신경망) 은 간단히 말해 사람 뇌의 뉴런 구조를 본떠서 만든 수학적 모델이다.
사람 뇌와 비교해보자면, 사람 뇌에는 뉴런이 있는데 뉴런은 신호를 받아서 처리한 뒤 다른 뉴런에게 전달을 하게 된다. 그리고 인공신경망에서는 이 뉴런을 수학적인 노드(node)로 흉내를 낸 것 이다.
입력값을 받아서 여러 단계의 계산을 거쳐 결과(출력)을 만들어내는 함수들의 조합 = Nerual Network
PyTorch를 사용해서 신경망을 만드는 방법
nn.Module 을 활용한 신경망 구축
- PyTorch에서 신경망을 만들때는
nn.Module클래스를 상속받아서 새로운 클래스를 만든다. - 네트워크 구조는
__init__()안에서 정의하고 - 실제 데이터가 들어왔을 때의 처리 방식은
forward()함수에서 정의한다.
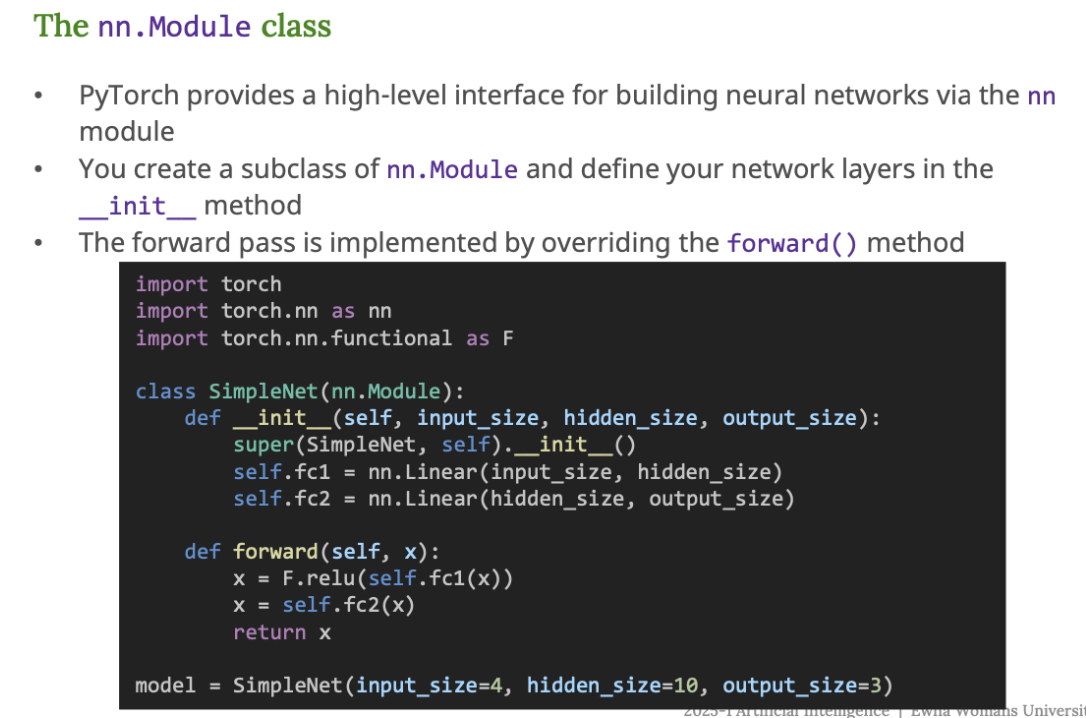
코드 설명
import torch
import torch.nn as nn
import torch.nn.functional as F
- PyTorch의 핵심 모듈들을 불러온다.
nn: 신경망 관련 모듈들F:ReLU같은 활성화 함수 등 함수형 API 사용 시 씀
신경망 클래스 정의
class SimpleNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 입력 → 은닉층
self.fc2 = nn.Linear(hidden_size, output_size) # 은닉층 → 출력층
nn.Module을 상속받아서SimpleNet이라는 클래스를 만든다.fc1: 첫 번째 선형 계층 (예 : 4개의 입력 → 10개의 뉴런)fc2: 두 번째 선형 계층 (예 : 10개의 뉴런 → 3개의 출력값)
Forward 함수
def forward(self, x):
x = F.relu(self.fc1(x)) # 첫 번째 레이어 후 ReLU
x = self.fc2(x) # 두 번째 레이어 통과
return x
- 입력
x를 받아서fc1 → ReLU → fc2순으로 처리한다. - 출력층에서는 활성화 함수를 사용하지 않는다.
은닉층에서는 ReLU, Tanh, Sigmoid 와 같은 비선형 활성화 함수를 꼭 사용해야한다.
→ 신경망이 복잡한 문제를 풀 수 있게 하려면 비선형성이 필요하기 때문
그러나, 출력층에서는 상황에 따라 활성화 함수를 생략하거나 나중에 처리하는 경우가 많음
- 이진분류면 : Sigmoid 사용
- 다중클래스분류면 : Softmax 사용
- PyTorch에서는 Loss 함수가 알아서 Softmax 까지 해줌 → 그래서 보통 생략함 !
분류에서 CrossEntropyLoss 를 사용할 때 Softmax를 생략함
CrossEntropyLoss()는 내부적으로 LogSoftmax와 NLLLoss를 합쳐놓은 함수이다.- 즉, 우리가 따로 Softmax를 사용하지 않더라도 CrossEntropyLoss가 자동으로 softmax를 적용해서 Loss를 계산해준다.
모델 인스턴스 생성
model = SimpleNet(input_size=4, hidden_size=10, output_size=3)
- 이 코드로 실제 모델을 만들 수 있다.
- 입력 크기 4, 은닉층 10개, 출력 크기 3 (예 : 3개 클래스 분류 문제)
SimpleNet이라는 신경망 구조 '틀(class)' 를 만들었다 → 이제 model이라는 실제 객체(instance)를 만든 것이 된다.- model 을 만들었다고 똑똑한 상태인 것은 아니다. 그저 아무 의미 없는 가중치를 가진 신경망일 뿐이다.
- 그래서, 모델 인스턴스를 만든다 (= 신경망 틀을 만들었다.)
- 이젠 학습 데이터를 통해서 학습시키는 과정이 필요하다 (= 가중치/편향 값을 조정해서 성능 좋은 모델로 바꾸자!)
자주 쓰는 레이어들
PyTorch에서 신경망을 만들 때 자주 사용하는 레이어와 함수들
1. Linear Layer (완전 연결 계층)
가장 기본적인 레이어
입력 벡터를 받아서 가중치를 곱하고 바이어스는 더하는 선형 연산을 수행
nn.Linear(in_features, out_features)
2. Convolutional Layer (합성곱 계층)
- 이미지나 시계열 데이터를 처리할 때 자주 사용
in_channels: 입력 채널 수out_channels: 필터의 개수kernel_size: 필터의 크기
nn.Conv2d(in_channels, out_channels, kernel_size, ...)
3. Recurrent Layer (순환 신경망)
- 시계열 데이터나 텍스트 처리할 때 사용
nn.RNN: 기본 RNNnn.LSTM: 장기 기억 가능nn.GRU: LSTM 보다 가볍지만, 유사한 성능
4. 비선형함수
입력값에 비선형성을 부여해 더 복잡한 표현을 가능하게 함
nn.ReLU(): 0보다 작으면 0, 크면 그대로 출력nn.Sigmoid(): 값을 (0,1) 사이로nn.Tanh(): 값을 (-1, 1) 사이로- 또는
torch.nn.functional.relu()처럼 함수형으로도 사용 가능
모든 층이 선형이면, 아무리 많이 쌓여도 결국 하나의 큰 선형식으로 단순화된다 (= 의미가 없다 !)
그래서, ReLU, Tanh, Sigmoid 와 같은 비선형 함수를 꼭 중간에 넣어줘야한다.
5. Dropout
nn.Dropout(p=0.5)
- 과적합을 막기 위해 무작위로 뉴런 일부를 끈다.
p = 0.5는 50% 확률로 끄겠다는 의미이다.
정리
- PyTorch에서는
nn.Module을 상속해서 모델을 만든다. __init__()에서 구조를 설정하고,forward()에서 흐름 정의Linear,Conv2d,ReLU,Dropout등 다양한 레이어 조합으로 원하는 모델을 구축할 수 있다.
Training Nerual Networks
1. 데이터 전처리 (Preprocessing)
- 정규화 (Normalization) : 데이터를 일정 범위로 바꿔줘야 학습이 잘됨.
- Tensor 변환 : PyTorch는 데이터를
torch.Tensor로 처리해야함
x = torch.tensor(data, dtype=torch.float32)
2. 데이터셋 정의하기 (Dataset 클래스 만들기)
torch.utils.data.Dataset을 상속해서 커스텀 Dataset을 정의한다.- 필요한 메서드
__init__: 데이터 저장__len__: 데이터 전체 길이__getitem__: 하나의 데이터와 정답 반환
class MyDataset(Dataset):
def __getitem__(self, idx):
return x_tensor, y_tensor
내장된 MNIST, CIFAR10 같은 Dataset도 존재
→ PyTorch가 기본적으로 제공해주는 학습용 데이터셋들이 있다는 의미임
- MNIST : 숫자 손글씨 데이터
- CIFAR10 : 일반 사물 이미지 데이터
3. DataLoader 로 배치 구성
DataLoader는 데이터셋에서 데이터를 미니배치 단위로 꺼내주는 도구- shuffle = True : 데이터 순서 섞기
- batch_size : 몇 개씩 묶을지
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
4. 손실함수 (Loss Function)
모델이 정답과 얼마나 다른지 계산하는 함수
분류 문제는 보통 CrossEntropyLoss() 사용
loss_fn = nn.CrossEntropyLoss()
CrossEntropyLoss() 는 내부적으로 Softmax + Log 계산이 포함되어 있어서 모델의 출력에 Softmax 를 쓰지 않아도됨
5. 옵티마이저 (Optimizer)
손실값을 줄이기 위해 가중치를 어떻게 조절할지 결정
가장 많이 쓰는 옵티마이저
- SGD (경사하강법)
- Adam (학습률 자동 조절, 빠름)
6. 학습 루프 (Training Loop)
학습을 반복해서 아래 과정을 돌린다.
num_epochs = 5
for epoch in range(num_epochs): # ❶ 에폭을 5번 반복
for batch_data, batch_labels in dataloader: # ❷ 데이터로더에서 미니배치를 하나씩 가져옴
# Forward pass
outputs = model(batch_data) # ❸ 모델에 데이터를 넣어서 예측
loss = loss_fn(outputs, batch_labels) # ❹ 예측값과 정답(label)을 비교해서 loss 계산
# Backpropagation
optimizer.zero_grad() # ❺ 그래디언트(미분값) 초기화
loss.backward() # ❻ loss를 기준으로 모든 파라미터에 대해 미분(역전파)
# Update weights
optimizer.step() # ❼ 미분값을 이용해서 파라미터(가중치) 업데이트
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}") # ❽ 에폭마다 loss 출력
정리
- 데이터 정규화 + Tensor 변환
- Dataset 만들기 (혹은 불러오기)
- DataLoader 로 배치 구성
- 모델 설계 (nn.Module)
- 손실함수 정의
- 옵티마이저 정의
- 학습 루프 → forward → loss → backward → step 반복!
GPU
딥러닝은 수많은 연산을 반복하기 때문에 병렬 연산에 특화된 GPU를 사용하면 훨씬 빠르다.
- PyTorch는 CUDA가 설치되어 있으면 자동으로 GPU 사용 가능
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
먼저 CUDA(GPU)가 가능한지 확인하고 그렇지 않으면 CPU로 fallback 함
for batch_data, batch_labels in dataloader:
batch_data = batch_data.to(device)
batch_labels = batch_labels.to(device)
데이터도 반드시 GPU로 이동해야함 !
모델과 데이터가 같은 장치에 있어야 연산이 가능하다.
모델 저장과 불러오기
PyTorch에서는 학습이 끝난 모델을 저장하고 다시 불러올 수 있다.
1. state_dict 저장하기
# 저장
torch.save(model.state_dict(), 'model_weights.pth')
# 불러오기
model = SimpleNet(...)
model.load_state_dict(torch.load('model_weights.pth'))
model.eval() # 평가 모드로 전환
state_dict()는 모델의 가중치와 편향 값만 저장함- 다시 모델을 사용할 때에는 모델 구조를 먼저 만들고, 그 후에 가중치를 불러옴
2. 전체 모델 저장하기 (비추천)
torch.save(model, 'model.pth')
model = torch.load('model.pth')
model.eval()
- 전체 구조까지 저장됨
- PyTorch 버전이 바뀌면 호환성 문제가 생길 수 있음
모델 저장은
state_dict()방식이 더 안전하고 유연하다. 그리고 불러온 후에는model.eval()을 꼭 해줘야한다.
자주하는 실수 (Common Pitfalls)
zero_grad()안함
- 기울기가 누적되어서 이상한 학습을 할 수 있음
- 매 반복마다 꼭 해줘야함
.eval()호출 안함
- 모델을 추론할 때는
model.eval()을 호출해야
→ dropout, batchnorm 같은 걸 꺼줘서 안정적인 출력이 가능함.
- 손실함수, 출력층 잘못 사용
- 다중 클래스 분류
- 마지막 레이어는 Softmax 없이
- 손실함수는
CrossEntropyLoss
- 이진 분류
- 출력층 : 1개의 뉴런 + Sigmoid 생량
- 손실함수는
BCEWithLogitsLoss사용
- 입력 형태 오류
예 : CNN은(batch_size, channels, height, width)형태가 필요
→ 1D로 넣으면 에러 나거나 이상한 결과가 나올 수 있다.
(부연 설명을 하자면, CNN은 이미지를 다룰 때 사용하는 모델이기에 CNN이 기대하는 데이터 형태가 존재한다. 그런데 1D로 넣는다는 것은 마치 사진을 쭉 펼쳐서 긴 줄을 만든다는 것이다. 이렇게 되면 에러가 나거나 이상한 결과가 나올 수 있다.)
- CPU, GPU 장치 불일치
- 모델과 데이터가 다른 장치에 있으면 에러 발생
- 항상
.to(device)로 통일시켜야함
