Early CNN models
AlexNet
- AlexNet 은 Alex Krizhevsky라는 사람이 만든 모델
- 2012년 ILSVRC(이미지넷 대회)에서 우승하면서 엄청 유명해짐
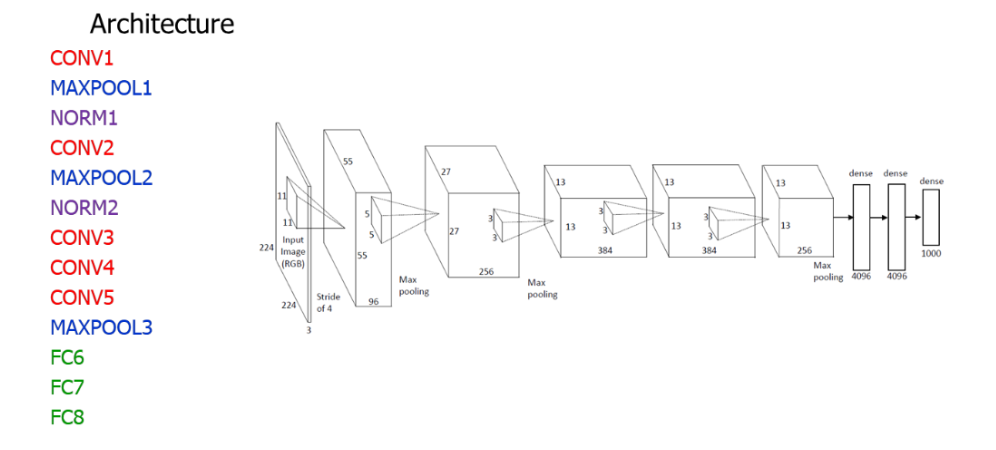
- 모델 구조는 아래처럼 진행됨
- 구조 그림을 보면
- 처음엔 큰 입력 이미지 (224x224x3)
- 여러 번 Convolution + Pooling 하면서 점점 크기를 줄이고
- 마지막에는 Fully Connected (FC) layer 로 분류를 한다.
CONV1
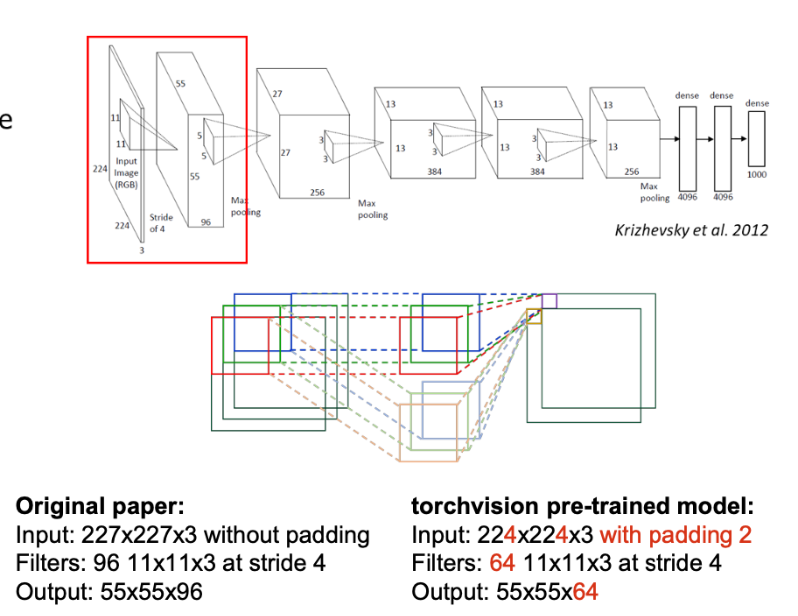
- 첫번째 레이어 (CONV1)
- Original Paper 기준
- 입력 : 227x227x3 이미지
- 필터 : 96개, 필터 크기 11x11, 스트라이드(한 번 이동하는 칸 수) 4
- torchvision(요즘 모델 라이브러리 기준)
- 입력 : 224x224x3 dlalwl
- padding2 를 추가해서 모양을 맞춤
- 필터 64개
- 출력 : 55x55x64
MAXPOOL1
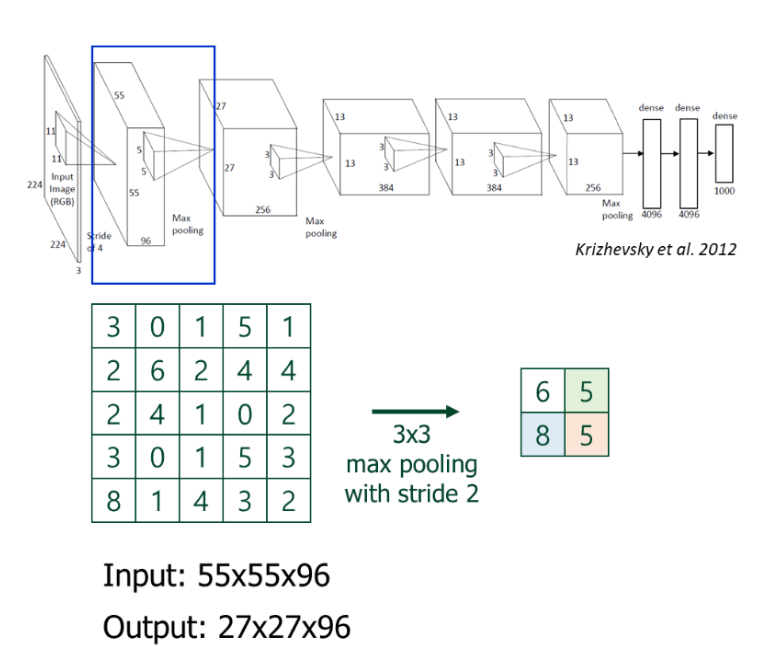
- MaxPooling 레이어를 설명하고 있다.
- 큰 영역에서 가장 큰 값만 남기고 나머지는 버리는 것
- 이것으로 크기 줄이기 + 특징 강조를 할 수 있다.
여기에서는
- 입력 : 55x55x96
- 출력 : 27x27x96
- 방법 : 3x3 윈도우에 stride 2
→ 이미지 사이즈를 줄이면서 중요한 특징만 남긴다 !
Remaining Layers
CONV2 부터 마지막 FC8까지 나머지 구조를 요약해 보여주고 있다.
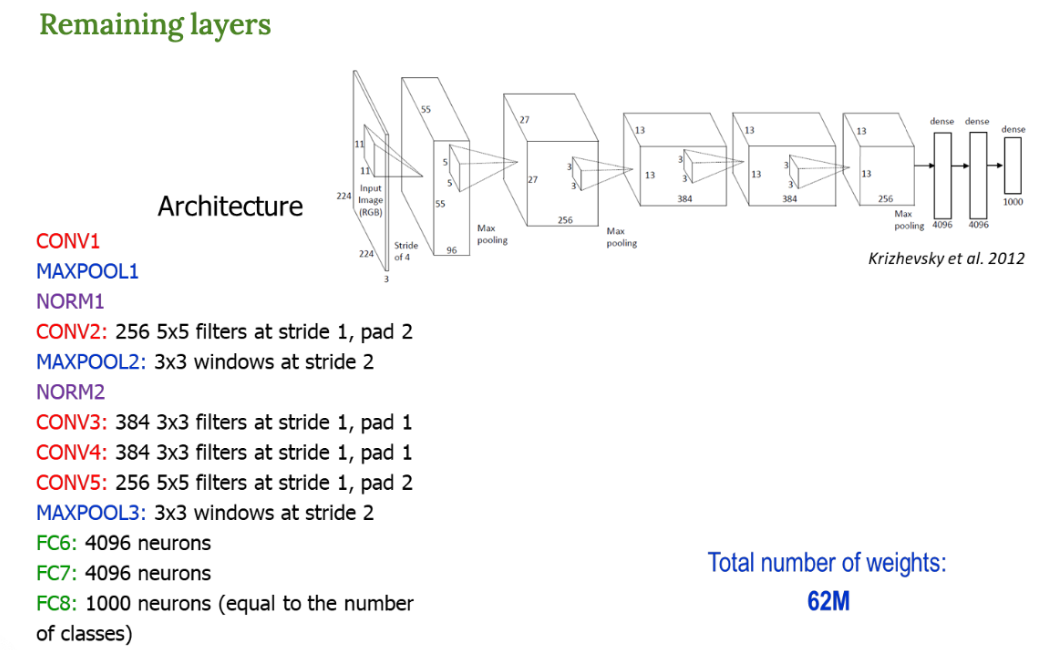
특징
- 5개의 Convolution, 3개의 FC Layer → 그 당시 기준으로 '아주 깊은' 모델에 해당함
- ReLU 활성화 함수 사용 (빠른 학습 가능)
- 2개의 GPU를 써서 학습 속도 개선 (당시 GPU 메모리가 작아서 분산시킴)
- local response normalization (LRN) 사용 : 특징 강조
- overlapping max pooling (stride 보다 필터 크기가 큼) : 더 부드러운 특징 추출 가능
- data augmentation : 데이터를 회전/자르기/뒤집기 등으로 늘림
- dropout : 0.5확률로 뉴런 끄기 → 과적합 방지
VGG
VGG 모델의 핵심 아이디어는 작은 필터를 여러 번 쌓아서 깊게 만든다.
AlexNet보다 작고 규칙적인 필터를 더 깊게 쌓아서 성능을 올린 모델
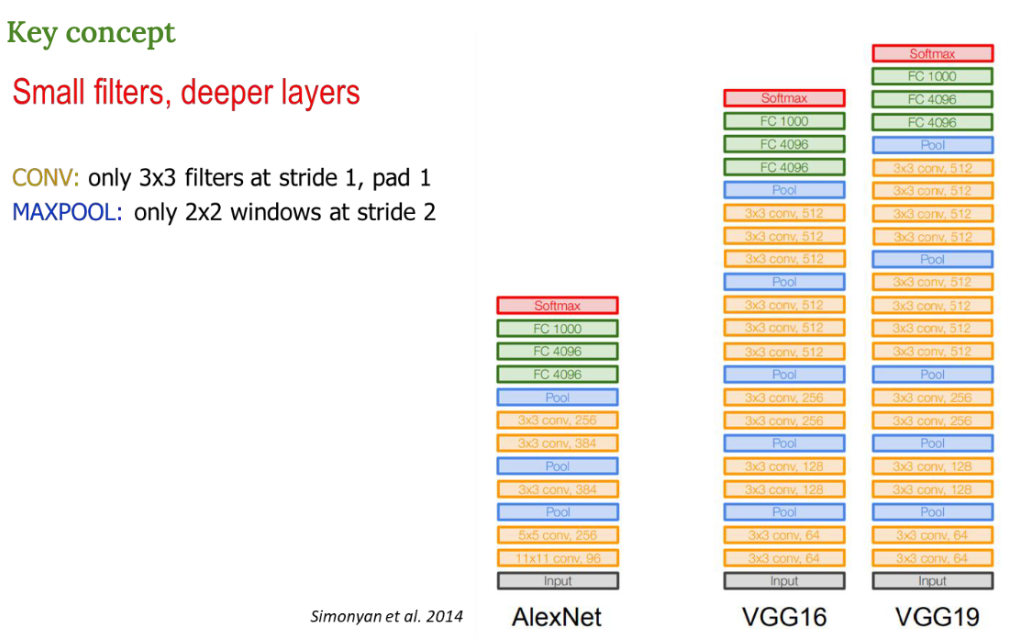
- Convolution : 무조건 3x3 필터, stride 1, padding 1
- MaxPooling : 무조건 2x2 필터, stride 2
AlexNet과 비교해서 VGG는 훨씬 많은 Convolution layer를 가지고 있다.
그리고 모든 Convolution이 3x3 으로 통일되어 있다는 특징이 있다.
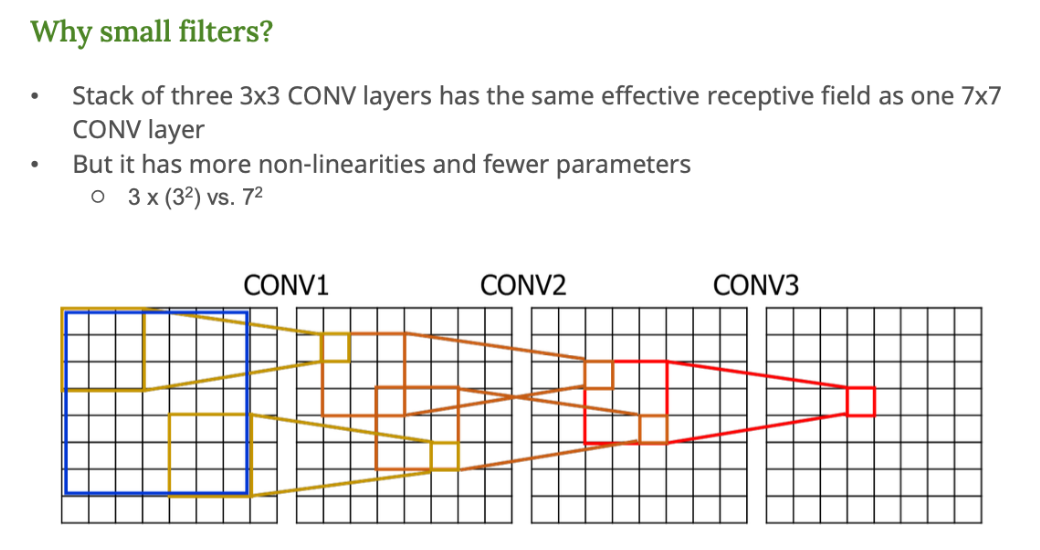
3x3 필터를 3번 연속으로 적용하면 7x7 필터 한 번을 쓴 것과 비슷한 효과를 얻을 수 있다.
장점
- 중간에 ReLU같은 비선형성을 더 많이 넣을 수 있다
- 파라미터 수도 줄어든다.
특징
- 구조가 단순하다 3x3 conv반복
- 모듈화(modularity) : 같은 구조를 반복해서 모델 짜기가 쉽다
- 점진적으로 채널 수가 증가 : 깊어질 수록 채널 수가 커짐
- 규칙적인 다운샘플링 : 폴링을 통해 사이즈를 주기적으로 줄인다.
- 학습이 쉽다 : 심플해서 딥러닝 프레임워크에 맞추기도 쉽다.
- 단점
- 계산량이 엄청 많다.
- 메모리도 많이 쓴다.
GoogLeNet
깊게 만들되, 계산량은 효율적으로
특징
- 단순히 레이어만 쌓는게 아니라,
inception module이라는 특별한 구조를 반복해서 사용 - 아래 그림에 보이는 것처럼, 네트워크가 복잡하게 분기되면서 진행됨
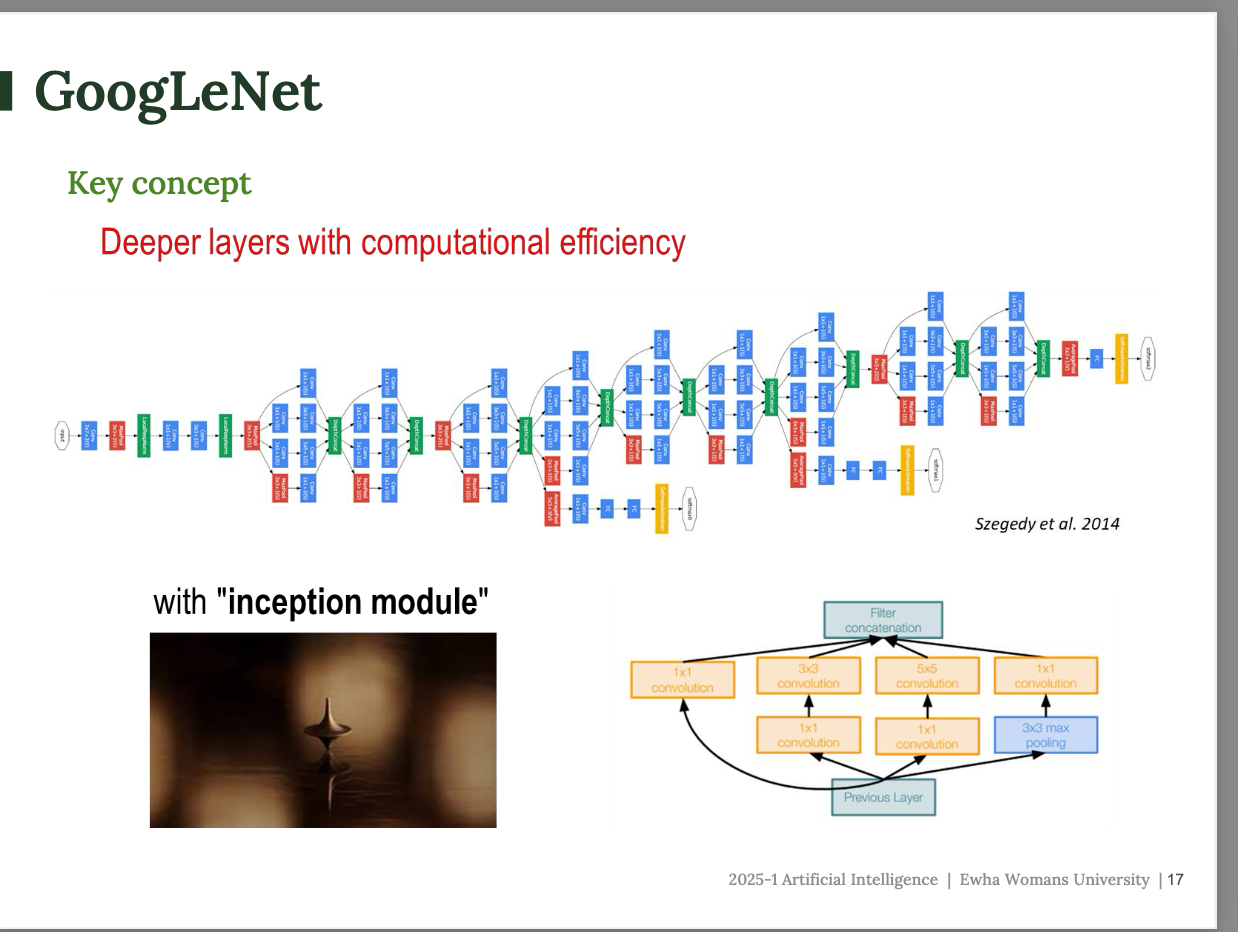
Inception module
영화 '인셉션' 처럼 하나 안에 여러 층이 동시에 들어간 구조
초기 버전 (Naive)
- 이전 레이어의 출력에 대해
- 1x1, 3x3, 5x5 필터를 한 번에 병렬로 적용하고
- 3x3 Max Pooling도 추가한 다음
- 결과를 이어 붙인다.
그러나, 이 방법은 너무 계산량이 많다는 문제가 있다 !
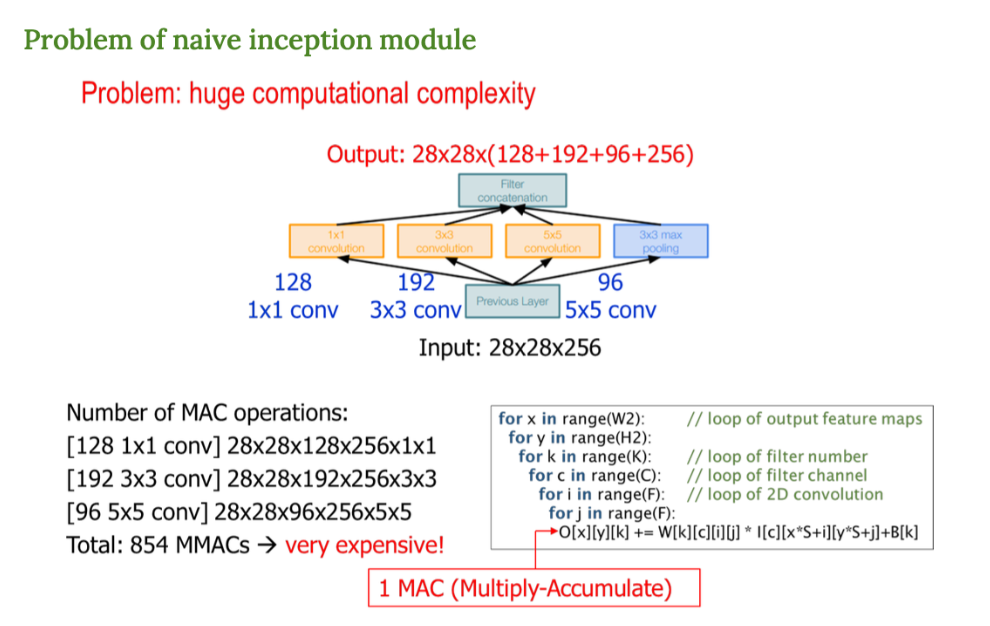
다양한 필터를 한꺼번에 쓰니깐 연산량이 폭발함
MAC 계산
- MAC(Multiply-Accumulate) : 곱셈 + 덧셈 연산 수
- 엄청난 연산량 !!
그냥 필터 여러 개를 병렬로 쓴다고 좋은게 아니라, 계산량 폭발 문제가 생긴다.
1x1 Convolution
그래서 무거운 연산을 하기 전에 1x1 필터로 채널 수를 줄이자.
공간 크기는 유지하면서, 채널 수(depth)만 줄인 것
예를 들어,
- 원래 : 56x56x64
- 1x1 Convolution으로: 56x56x32로 채널 수 절반 줄이기!
장점
- 연산량 대폭 감소
- 연산하면서 가볍게 정보 요약 가능
1 x 1 conv는 '가볍게 요약하는 필터' 로 이해하면 됨
개선된 Inception Module
1x1 Convolution을 중간에 끼워 넣어 채널 수를 미리 줄이고 → 3x3, 5x5 같은 무거운 연산을 진행.
주요 포인트
- stack of inception modules : 다양한 필터를 동시에 쓰는 inception 구조를 여러 번 반복해서 깊게 만든다. (한 층이 다양한 시야를 동시에 가지는 느낌)
- auxiliary classifier : 네트워크 중간에 보조 미션을 둬서 '야 , 중간부터 잘해 !' 하면서 학습을 도와준다.
- classifier (최종 분류기) : 마지막에는 무거운 레이어 대신 average pooling + 간단한 fc layer 하나로 깔끔하게 결과를 뽑는다. (과적합을 줄이기 위해서)
- 5M 파라미터 : 전체 학습해야할 양이 아주 적다
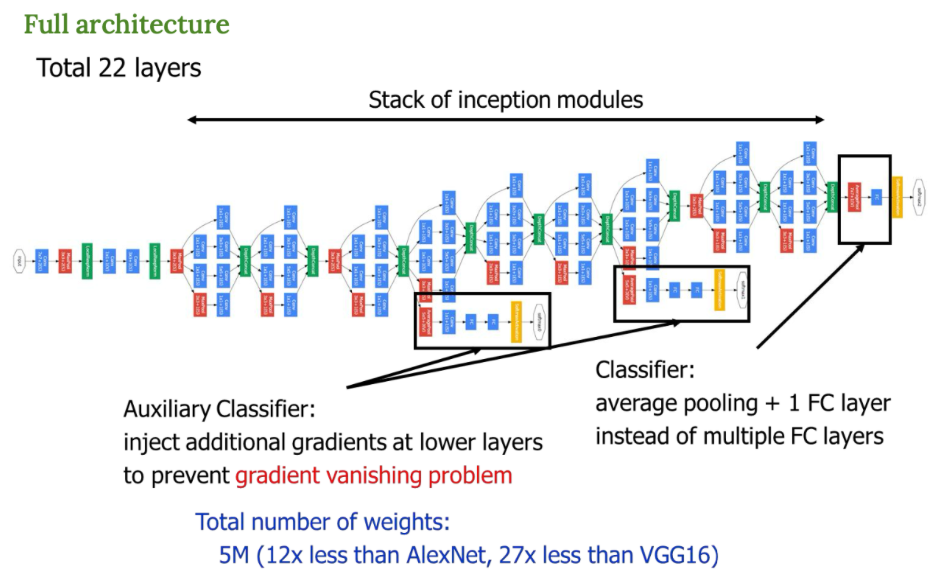
- 총 22개의 레이어로 이루어져 있다.
- 거의 대부분이 Inception Module을 여러 번 쌓은 구조임
ResNet
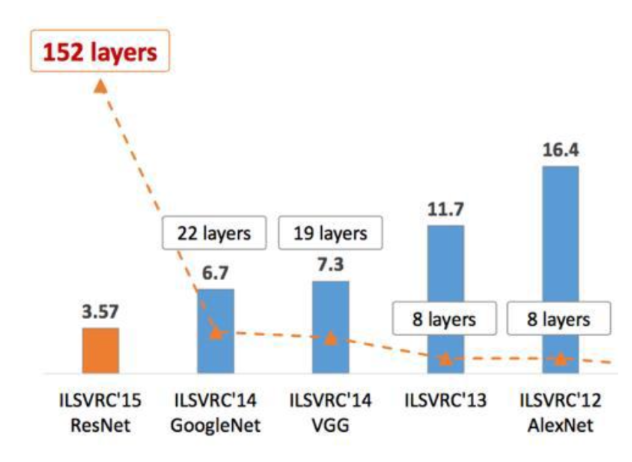
ImageNet 대회에서 해마다 우승한 모델들과 그 모델들의 깊이(depth)와 오류율(error rate)의 변화를 보여주고 있다.
여기서 보면, 깊어질수록 성능이 좋아진다는 흐름을 보이기는하는데 갑자기 2015년에 152층 ResNet 이 등장하면서 성능이 확 좋아지고 된다 !
그럼 그냥 레이어를 무작정 깊게 쌓으면 되지 않나
→ 아니다 ! 문제가 생긴다 !
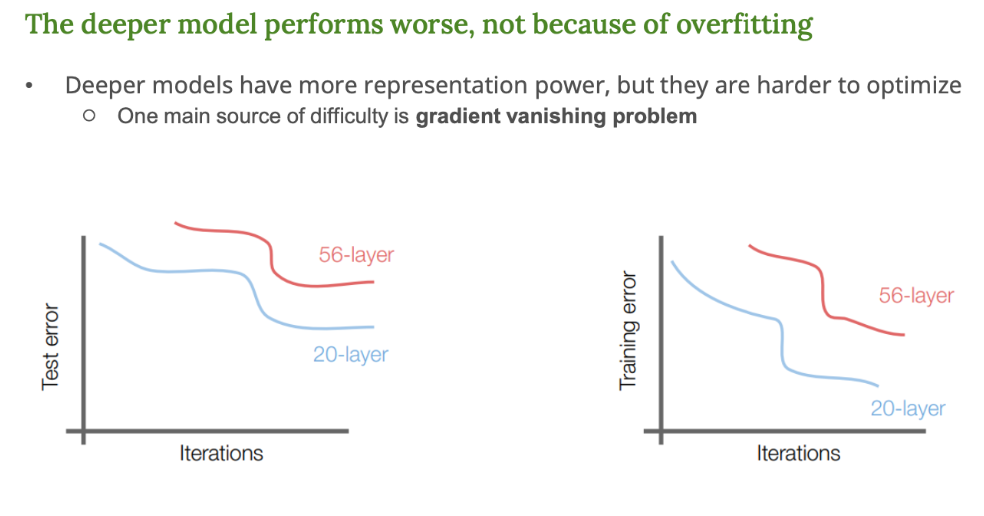
- 깊은 모델은 이론적으로 표현력(representation power)은 좋지만
- 학습(optimization)이 어려워진다.
- 특히, gradient vanishing problem 기울기 소멸 문제가 생긴다.
그래프 설명
- 왼쪽 그래프 : 테스트 에러
- 오른쪽 그래프 : 학습 에러
- 파란색 : 20층 모델 (얕은 모델)
- 빨간색 : 56층 모델 (깊은 모델)
결과
- 20층은 학습되고 에러가 줄어듦
- 56층은 오히려 더 깊은데 에러가 더 높아짐
왜냐 ?
- 레이어가 깊어질 수록 학습하는 도중 '기울기(gradient)' 가 작아져서
- 앞쪽(초기층)까지 제대로 학습이 전달되지 못한다.
key idea : skip connections
- 깊은 모델은 학습이 어렵다.
- 그래서 입력 x를 그대로 통과시켜버리는 통로(=skip connection)을 만들어준다.
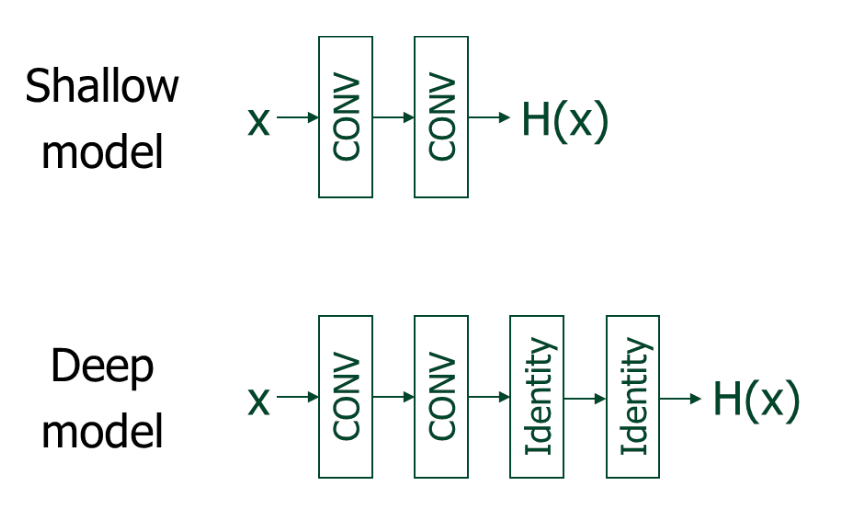
-
shallow model (얕은 모델)
그냥 Conv → Conv만 해서 H(x)를 만든다. -
deep model (깊은 모델)
Conv → Conv 하고 중가에 identity(그냥 입력 그대로)를 끼워넣어서 H(x)를 만든다.
Plain Layers vs. Residual Block 비교
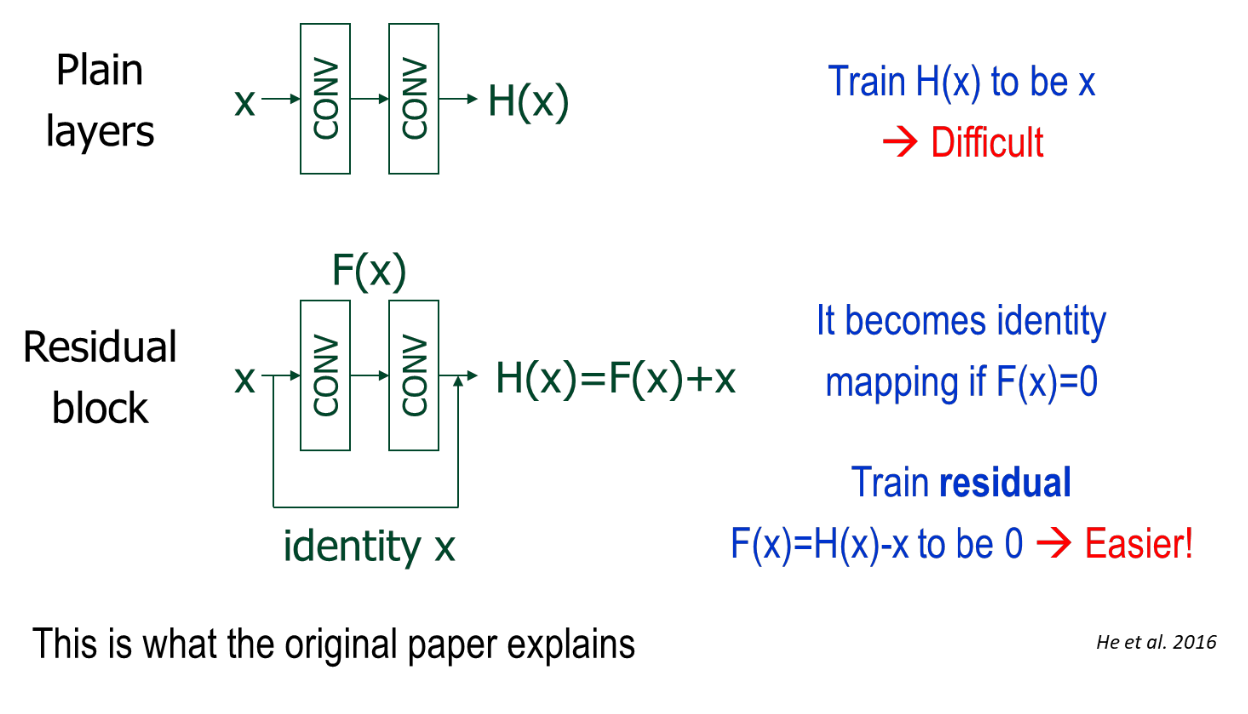
Residual Block를 사용하면 기울기 소실 문제를 막을 수 있다.
두 가지 기본 구조
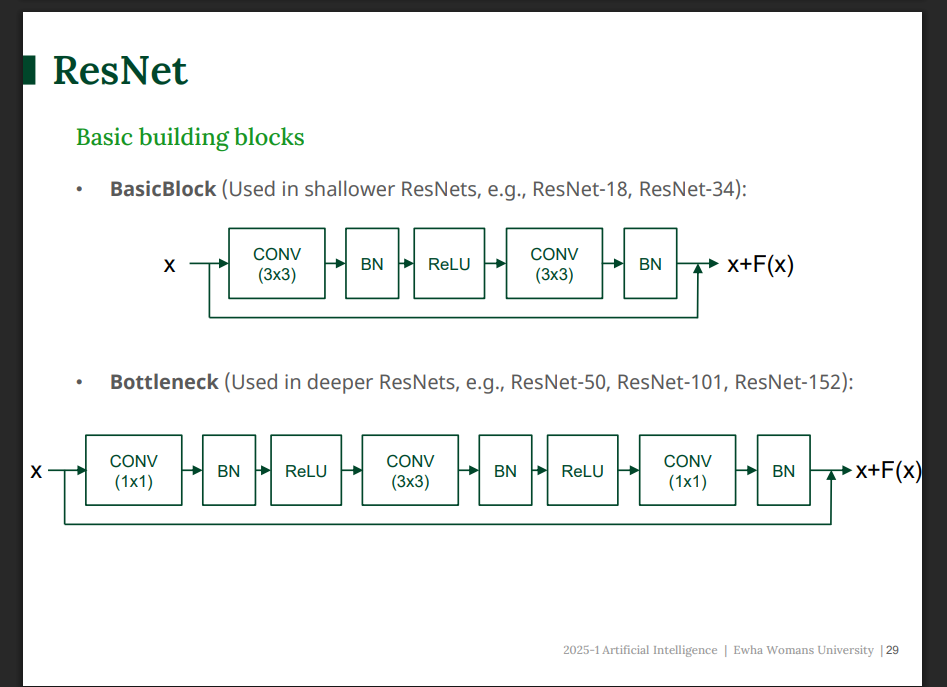
- BasicBlock : 얕은 ResNet에서 사용
3*3 conv 2개로 구성 - Bottleneck : 깊은 ResNet에서 사용
1×1으로 채널 줄이기 → 3×3로 특성 추출 → 1×1로 채널 늘리기
얕은 네트워크는 단순 블록, 깊은 네트워크는 효율성을 위해 Bottleneck 블록 사용
identity shortcut vs. projection shortcut
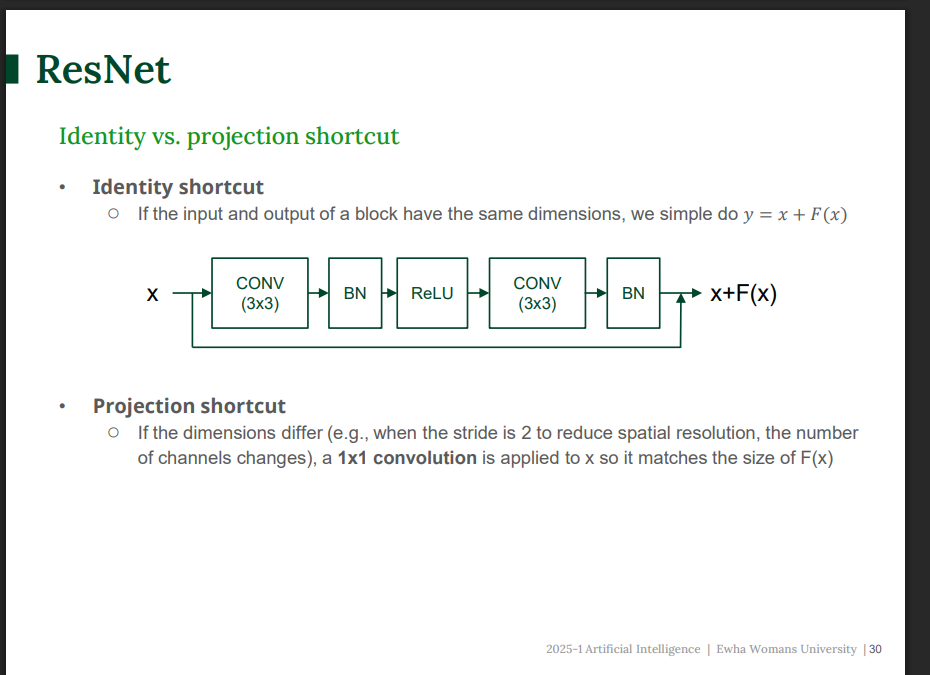
- identity shortcut : 입력과 출력의 크기가 같으면 그냥 x+ f(X) 로 더한다.
- projection shortcut: 입력과 출력의 크기가 다르면 1*1 convolution으로 x를 변형해서 맞춰준다.
전체 구조 흐름
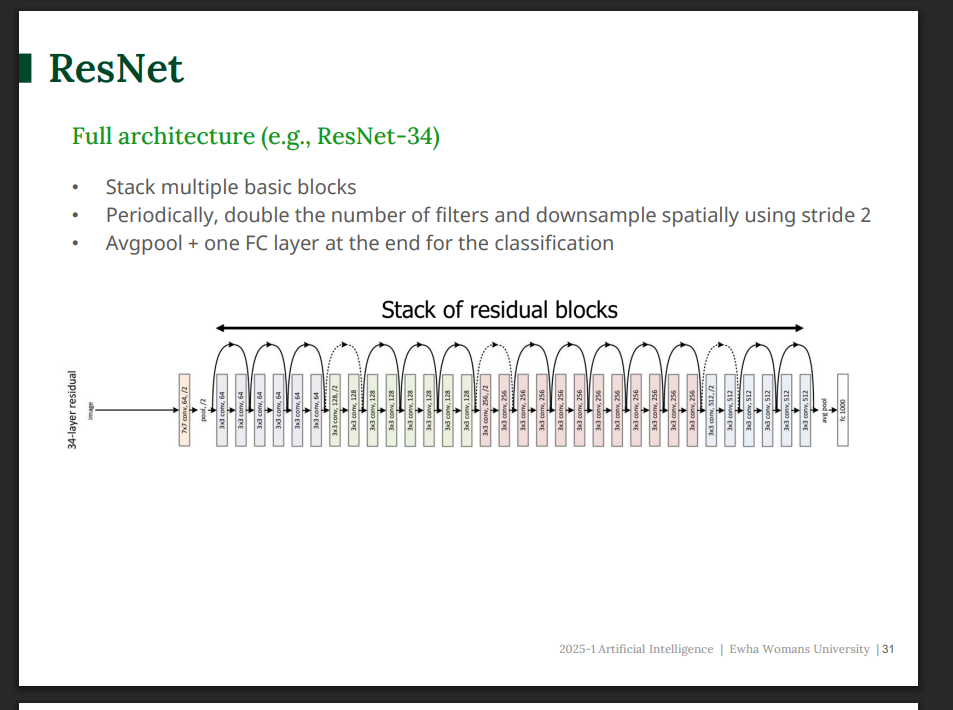
- 7*7 conv -> maxpooling
- 여러 residual block을 쌓는다.
- 중간중간 stride = 2를 줘서 다운샘플링 (크기 줄이기)
- 마지막에 global average pooling
- fully connected layer로 최종 분류
ResNet Variants
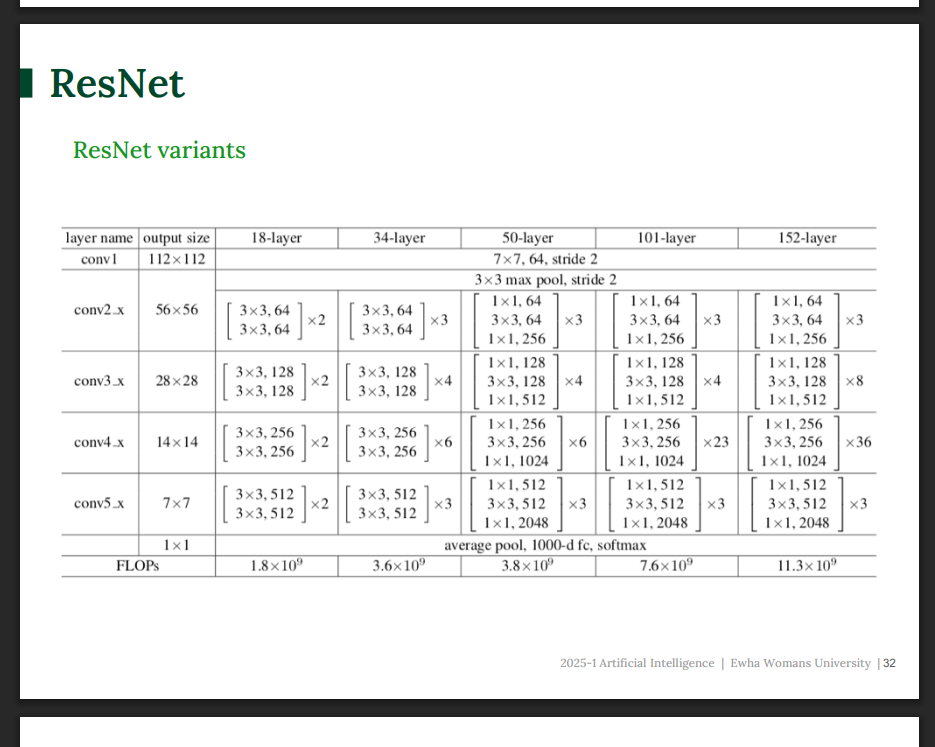
다양한 ResNet 버전 의 차이는 주로 '블록의 개수' 와 '블록 안 구조' 에서 나온다.
버전 특징
- ResNet-18, 34 : BasicBlock 사용
- ResNet-50, 101, 152 : Bottleneck 사용 (1×1 → 3×3 → 1×1)
훨씬 깊지만, 연산량 대비 효ㅛ율적이다.
성과
- ImageNet 대회에서 최상위 성능 모델
- 다양한 작업에서도 잘 전이됨
영향
- Residual learning 을 통해 매우 깊은 네트워크도 안정적으로 학습이 가능해짐
- 나중에 Transformer 모델들도 skip connection 개념을 가져감
