3D Convolution 구조
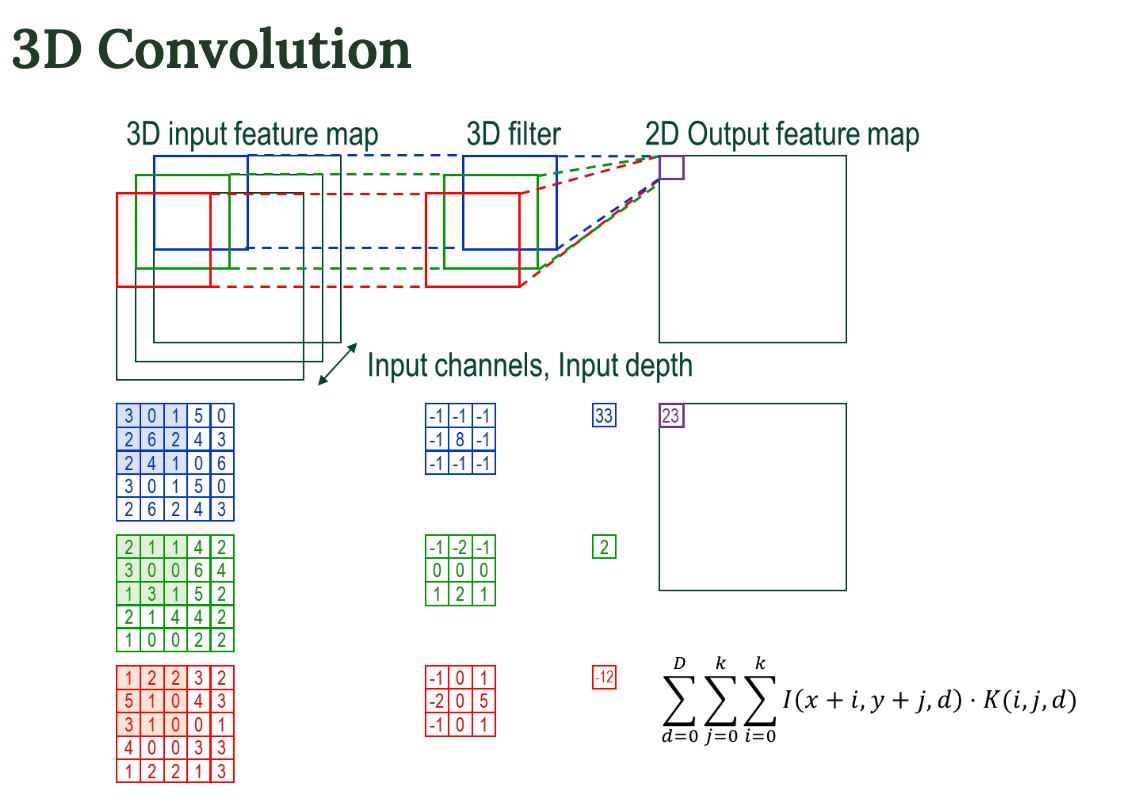
- 입력(3D input feature map) : RGB 이미지라면 3개의 채널이 있고, 각 채널별로 픽셀값이 있다.
- 3D 필터 : 이 필터도 3채널(입력 채널과 동일)을 가짐
이거를 하나의 덩어리로 취급해서 곱하고 더함 - 출력 : 곱하고 더한 결과를 하나의 값으로 만들어서 출력 맵 한 칸에 넣음
Sliding Window
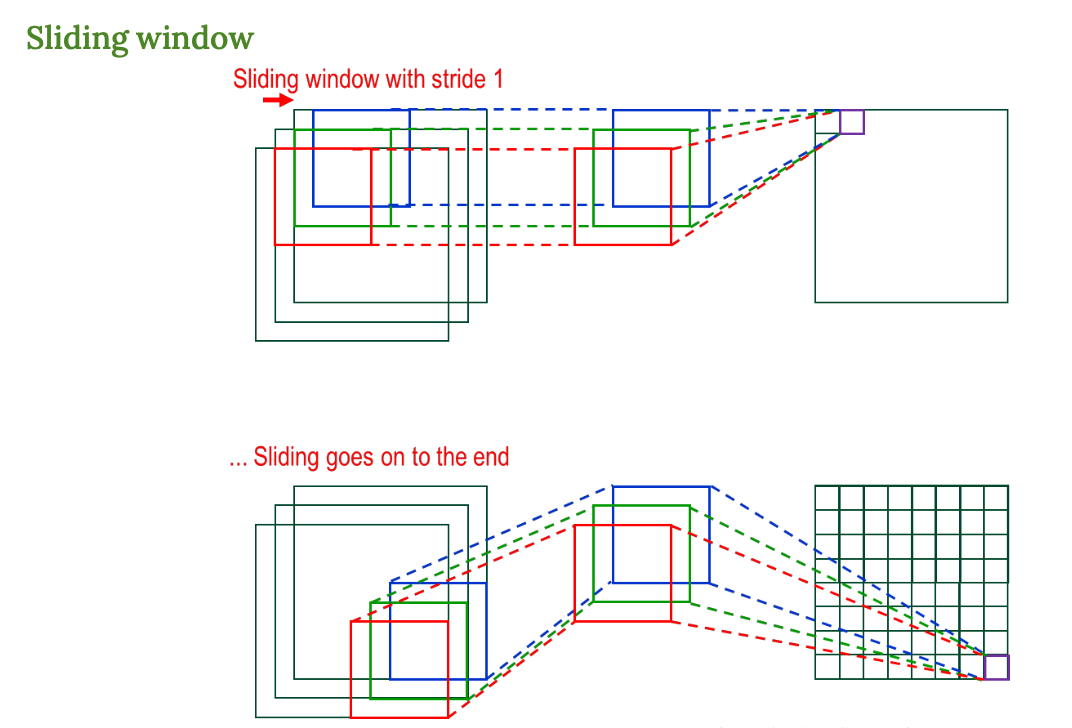
- 위에서 본 필터를 왼쪽 위에서부터 오른쪽 아래까지 계속 옮기면서 계산한다.
- 필터의 크기만큼 '창'을 움직여서 겹치는 부분마다 연산을 반복하는 것을 보여줌
→ 이게 CNN의 핵심 동작 !
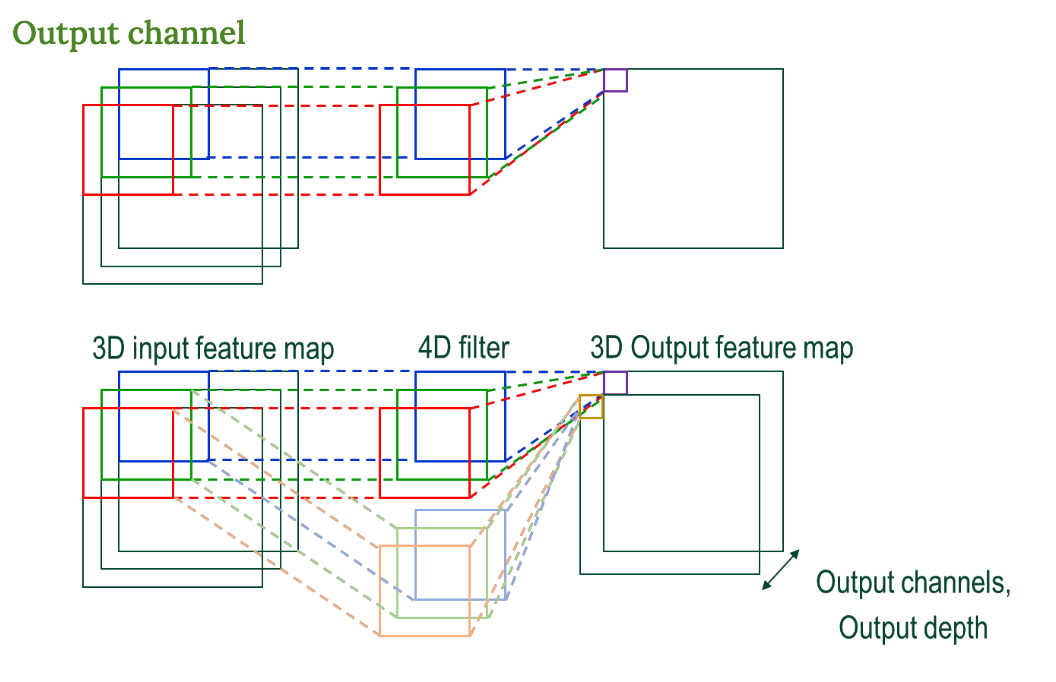
Output Channel
- CNN에서는 필터를 하나만 쓰지 않고 여러 개를 쓴다.
- 그래서 출력도 깊이(channel)이 생김
- 입력 → 필터 여러 개 → 출력도 3D → 이 출력 채널 하나하나가 각각 다른 특징(엣지, 곡선 등)을 잡아냄
요약
입력
- 크기는 W1 × H1 × C
- 하이퍼파라미터
- 필터 개수 K
- 필터 크기 F
- 이동 간격 S (stride)
- 패딩 P
출력의 너비와 높이 계산하는 공식이고, 필터 개수 K가 출력의 깊이가 된다.
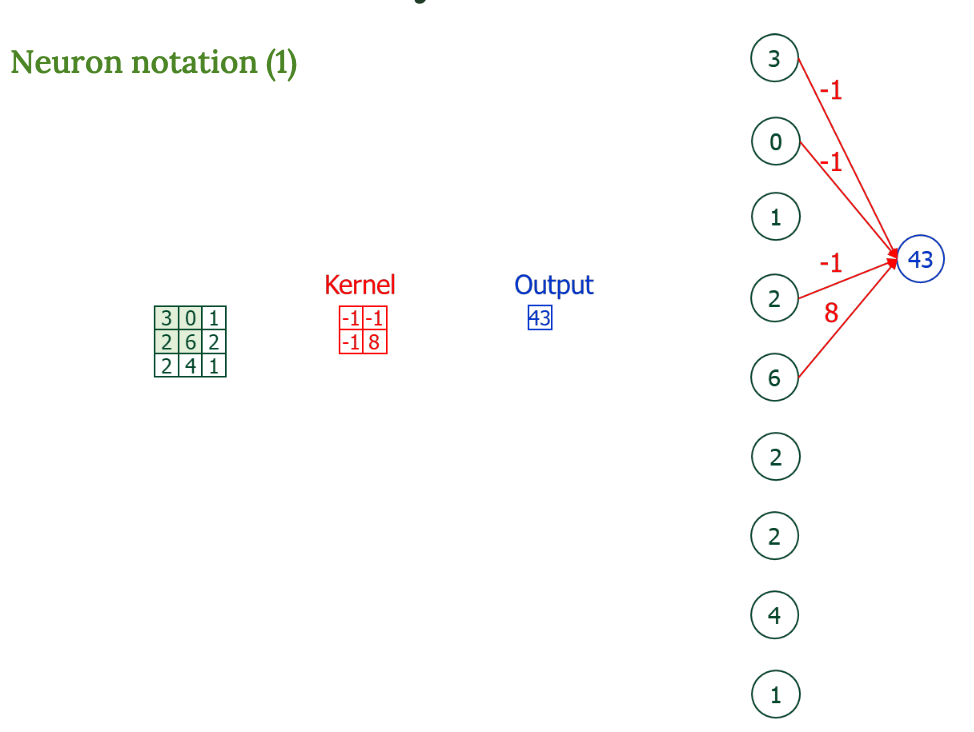
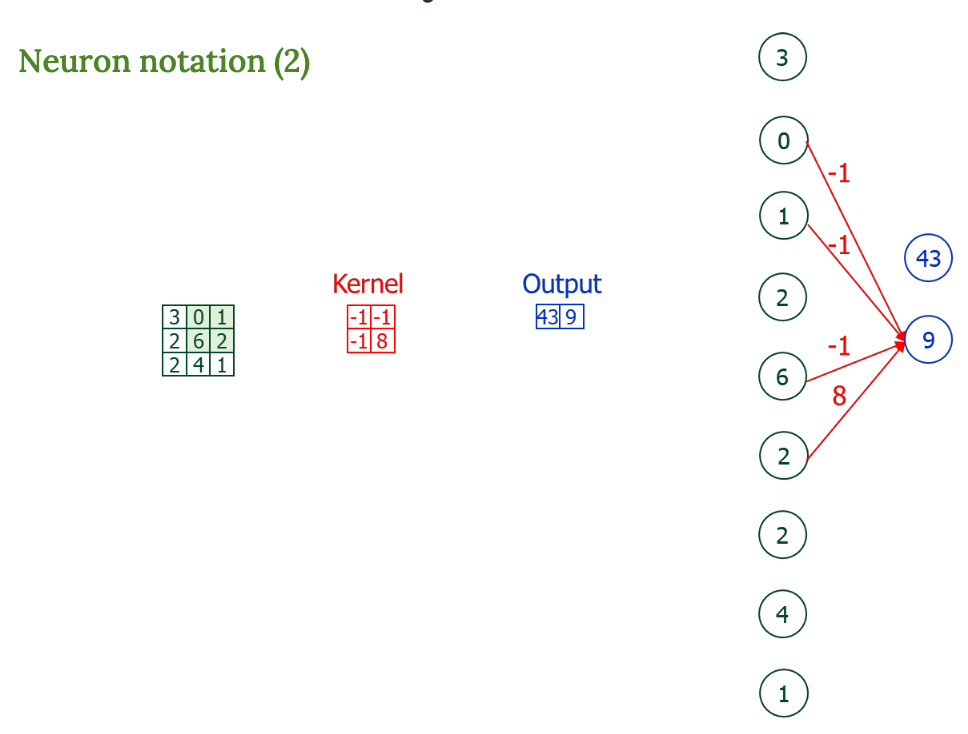
Neuron 표현
이건 위 수식을 뉴런 형태로 시각화한 것
- 입력 픽셀 여러 개 × 커널의 가중치 → 하나의 출력 뉴런 계산
- 그림에서 화살표는 가중치 곱셈을 의미한다.
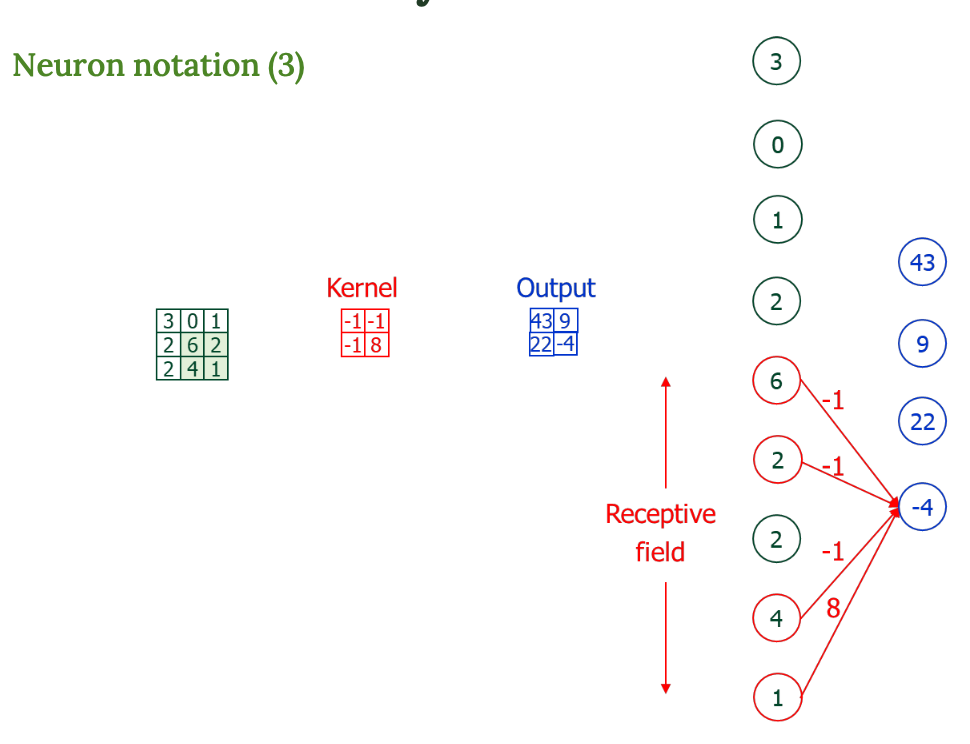
- Receptive field : 하나의 출력값을 만들기 위해 보는 입력의 영역
→ 필터가 움직이면서 각각의 출력을 만들고 있다는 걸 뉴런 관점에서 설명한 것.
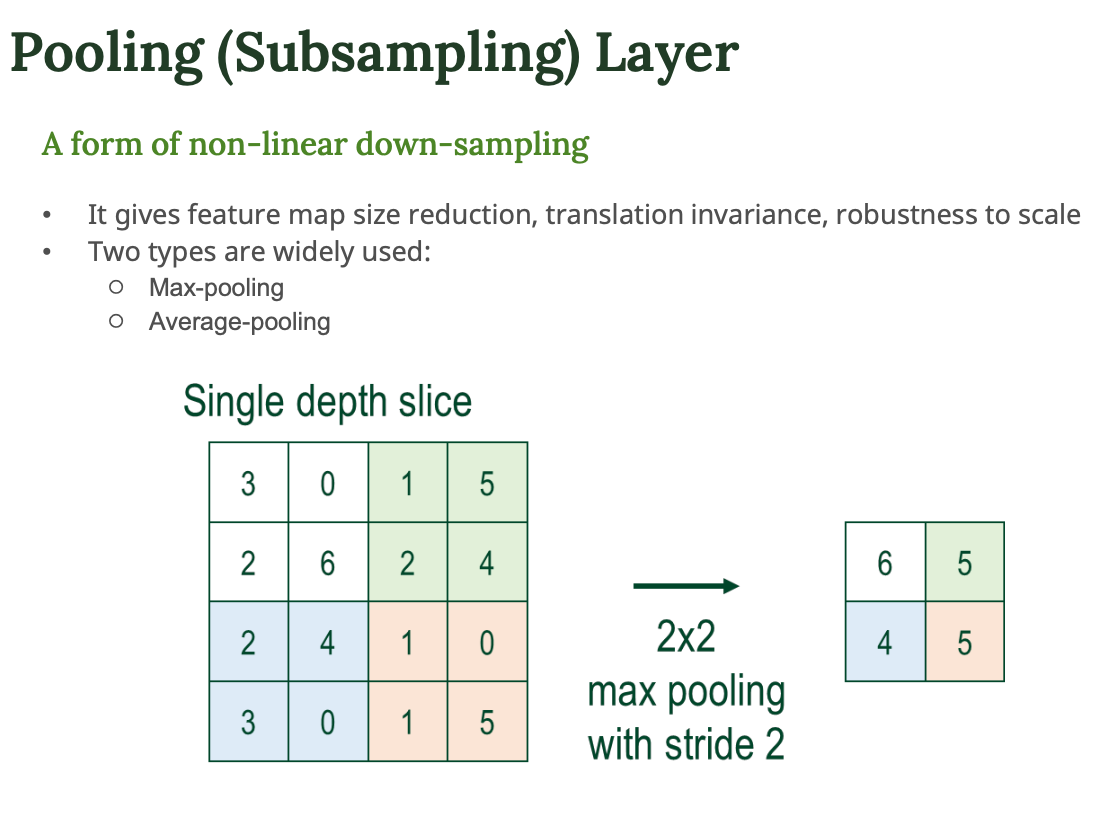
Pooling (Subsampling)
- 폴링은 정보를 압축해서 계산량을 줄이기 위한 단계
- Max pooling : 2 * 2 안에서 가장 큰 값만 가져감 → 중요한 특징만 유지
- Average pooling : 평균값을 사용
→ 이것을 통해서 특징 유지하면서 크기 줄이기 가능함
AlexNet
- AlexNet 은 CNN 구조 중 대표적인 예시
- 구조
- 입력 이미지
- 합성곱 레이어 + ReLU
- Max Pooling
- 완전연결층 (fully connected layers)
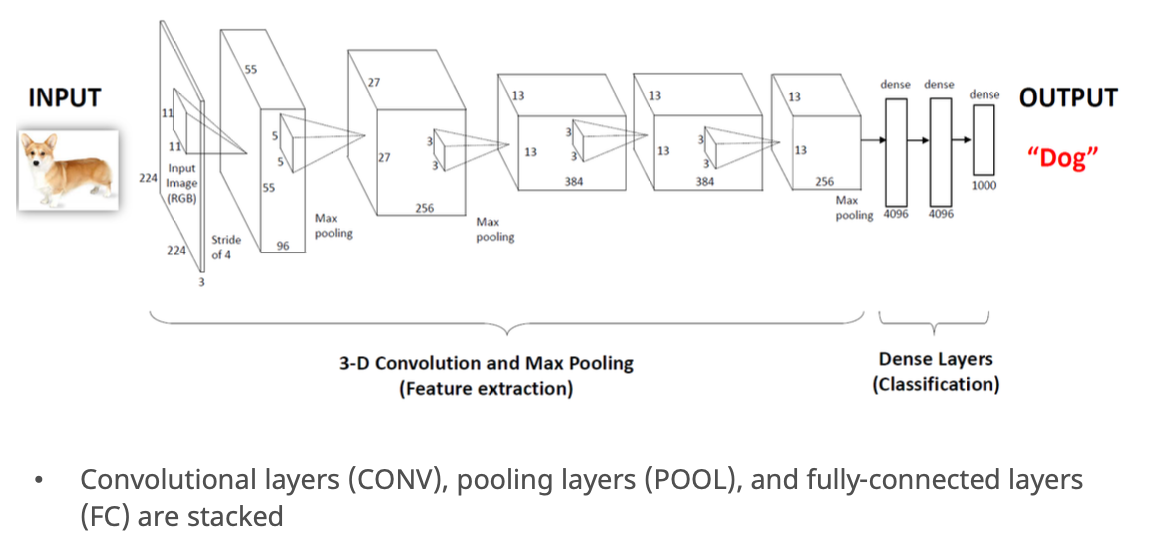

- AlexNet은 총 8개의 학습 가능한 레이어 (5conv + 3fc)
- 각 layer마다 kernel size, padding, stride가 적혀 있음
- ReLU, dropout 등도 들어가서 성능과 일반화 능력을 향상시킴
