들어가며
지금까지는 단일 퍼셉트론(Single Layer Perceptron), 단일 뉴런 구조 에 대해서 배웠다. 단일 퍼셉트론은 뉴런 하나 또는 뉴런들이 한 층만 있는 구조를 말한다. 학습도 이 한 층 뉴런에서만 이루어진다. 또한 은닉층이 없어 복잡한 비선형 문제에서는 학습이 불가능하다는 점이 특징이었다. 어떻게 보면 가장 기초적인 신경망이다.
- 뉴런 : 입력 → 가중치의 곱 → 합산 → 활성화 함수 → 출력
이 하나의 흐름 전체가 뉴런의 작동 과정이다.
다층 퍼셉트론
다시 한 번 봐보면, 왼쪽에서는 단일층 퍼셉트론 에 대해서 보여주고 있다.
- 여러 입력값들을 받아서 하나의 출력으로 연결된 단일 뉴런을 의미
- 입력 벡터 x들을 가중치 w와 곱해서 더하고, 그 합을 활성화 함수 f()에 넣어 결과를 출력하는 구조이다.
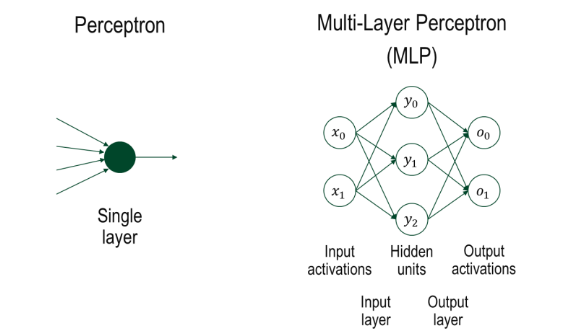
그리고 앞으로 배울 내용은 다층 퍼셉트론(Multi-layer Perceptron) 이다. 오른쪽 사진에 해당한다.
- 퍼셉트론을 여러 층으로 쌓는 구조이다.
- 구조
- 입력층 (input layer) : x0, x1
- 은닉층 (hidden layer) : y0, y1, y2 (입력에서 처리된 결과)
- 출력층 (output layer) : o0, o1 (최종 예측 결과)
핵심 : 단일 퍼셉트론은 단순한 분류만 가능하지만, MLP는 여러 층을 통해 더 복잡한 문제도 해결 가능하다.
입력층의 수식화
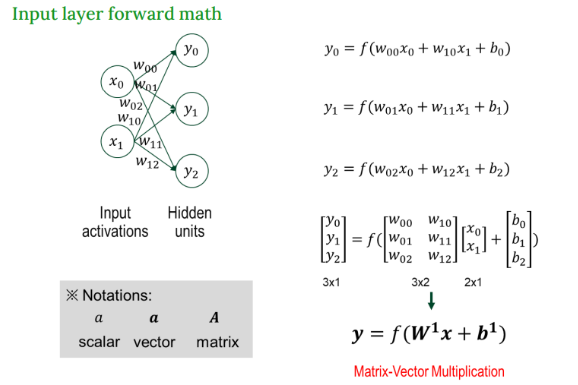
출력층의 수식화

MLP의 전체 수식 정리
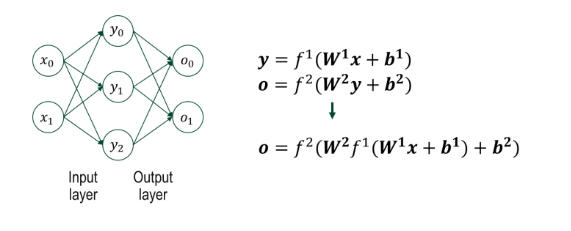
다층 퍼셉트론이 필요한 이유
XOR문제란 ?
두 입력이 다를 때만 출력이 1이 되는 논리 연산
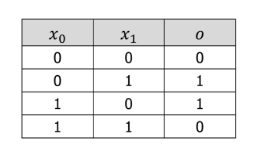
XOR은 선형적으로 분리(linearly separable)되지 않아 → 단일 퍼셉트론으로는 해결 불가능 !
2층 퍼셉트론으로 XOR 해결
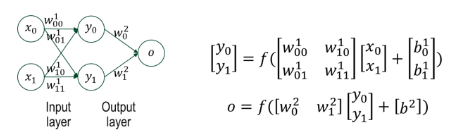
구성
- 입력층 → 은닉층(y0, y1) → 출력층(o)
은닉층이 feature 를 변환해서 출력층이 쉽게 분리 가능하도록 도와준다.
예시
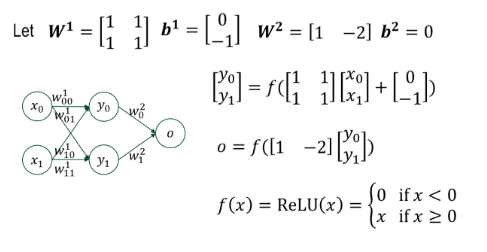
위와 같이 가중치와 바이어스를 설정해보자.
- 바이어스 (bias) : 뉴런의 출력값을 조정하는 추가 상수항으로 기울기(w)와는 별개로 출력에 영향을 주는 절편 역할을 한다. 바이어스가 없으면 모든 결정 경계가 원점을 지나야한다. 바이어스는 뉴런이 더 유연하게 데이터를 학습할 수 있도록 도와주는 튜닝값이다.
활성화함수 f(x) 는 ReLU
f(x) = max(0,x)
이 구조는 XOR을 정확히 학습할 수 있다. 왜냐하면, 중간의 은닉층이 비선형적 feature을 추출하기 때문이다.
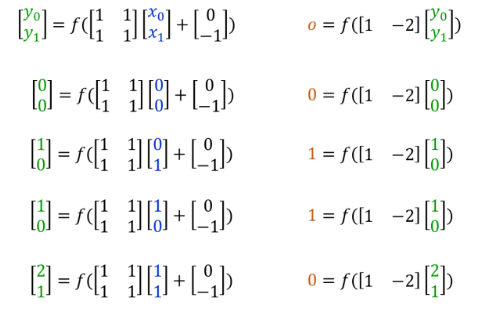
배치 입력 처리
아래는 입력을 한번에 여러 개 처리하는 배치 연산 (batch processing)의 예제이다. 수학적으로 행렬을 사용해 입력 4개를 한꺼번에 계산한다.

이건 실제 딥러닝에서 벡터화 연산을 사용하는 일반적인 방법이다. 훨씬 효율적이고 빠르다.
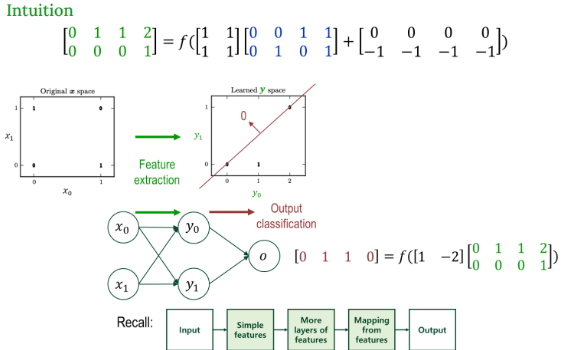
왼쪽 그림에서 보면 원래 입력 공간에서는 XOR이 선형 분리가 안되었다. 그런데 오른쪽 그림을 보면 은닉층으로 변환하면 선형 분리가 가능한 것을 볼 수 있다.
- 중간 은닉층이 하는 일 : 특징 추출
- 출력층이 하는 일 : 분류
→ 여기서 말하는 분류는 은닉층에서 중간 특징을 뽑아냈다면, 출력층은 그걸 최종적으로 판단하는 역할을 한다고 생각하면 된다.
가중치와 바이어스는 어떻게 학습될까 ?
우리가 앞에서 사용한 가중치 값들은 어떻게 정해지는가 ?
훈련 데이터로부터 학습된다. 즉, 값이 스스로 조정된다 !

- 𝑜 : MLP가 계산한 실제 출력
- : 실제 정답 (target label)
- C : 오차 (cost) - 둘 사이의 거리
목표는 이 cost를 작게 만드는 방향으로 가중치와 바이어스를 조정하는 것이다.
경사하강법 (Gradient Descent)
그래서 나온 것이 바로 경사하강법이다.
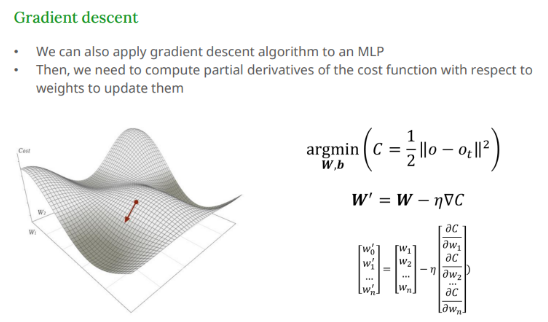
핵심 아이디어
- 손실함수의 기울기를 따라 조금씩 내려간다.
- 수식
W′=W−η⋅∇C
-η = 학습률 (learning rate) : 한 번에 얼마나 움질일지 결정
단일 뉴런 (퍼셉트론)
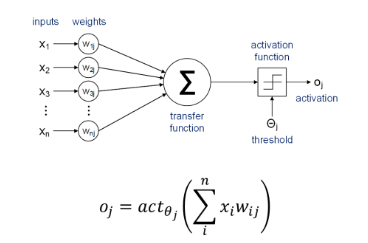
목표 : 가중치 하나에 대한 손실 함수의 기울기를 구하는 것
손실함수 (cost function)
출력 o가 정답과 얼마나 다른지 측정
기울기 계산 (경사 하강법)
우리는 이 오차를 줄이기 위해 각 가중치를 얼마나 바꿔야할지 계산한다.
- 손실함수 미분
- 활성함수 미분 (chain rule) 사용
- 오차 : o -
- 활성화 함수의 도함수 : f'(x)
- 입력값 :

즉, 뉴런 하나에서는
'오차 * 함수 기울기 * 입력값'으로 간단하게 가중치를 업데이트할 수 있다.
다층 퍼셉트론 (Multi-layer Perceptron, MLP)
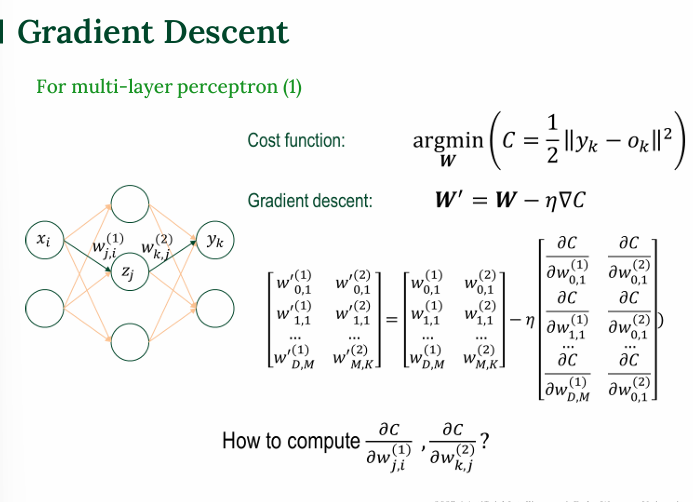
- 오차 함수 (cost function) : 예측값과 실제값 사이의 오차 제곱합을 최소화하는 것이 목표
- 경사하강법
- 목표 : 모든 가중치에 대해 를 계산하는 것
출력층 가중치에 대한 미분
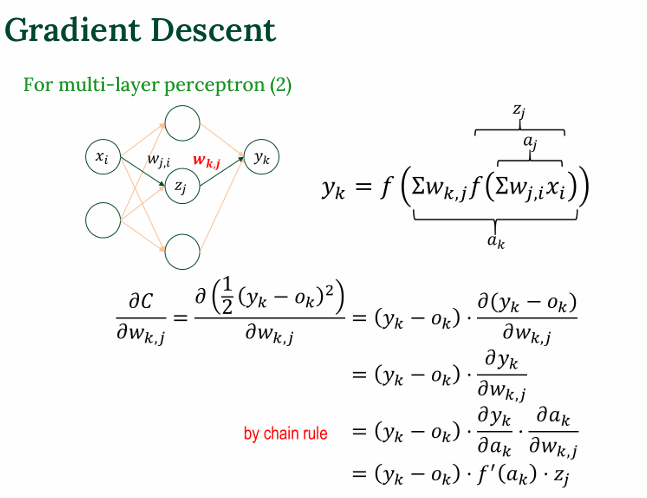
은닉층 가중치에 대한 미분
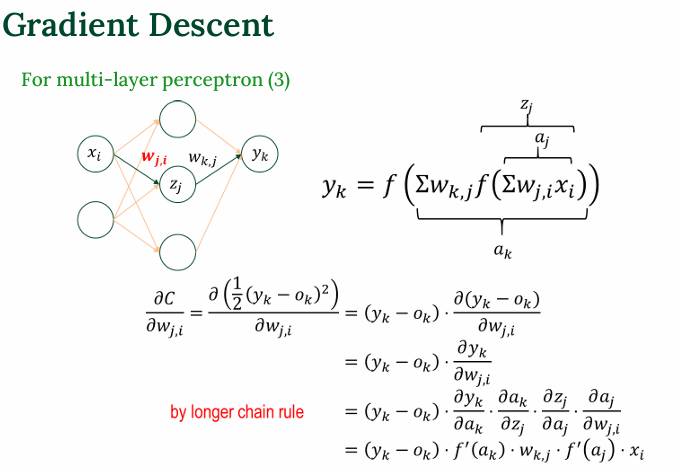
Backpropagation 개념
오차 전파(Backpropagation) 개념
- 출력층에 계산된 오차(error)를 은닉층으로 전달하며, 은닉의 가중치도 업데이트할 수 있게 함
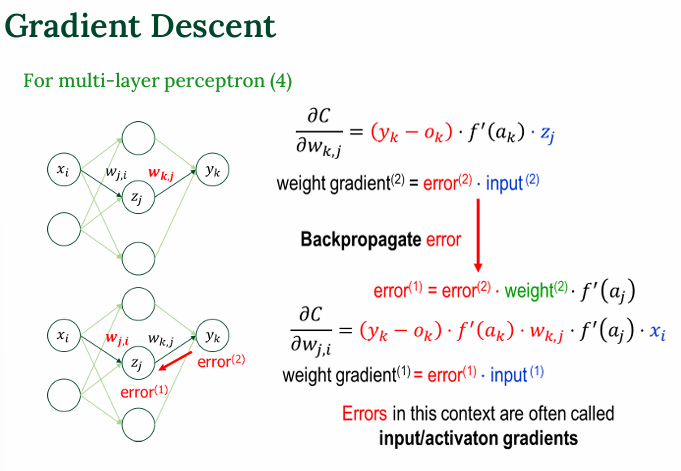
만약, 출력 뉴런이 2개일 경우

- 출력 뉴런이 2개일 경우, 오차도 2개임
- 각각의 오차에 대한 영향을 합산함
다수 출력 뉴런일 경우 → 오차들을 더한 형태로 역전파
전체 학습 과정
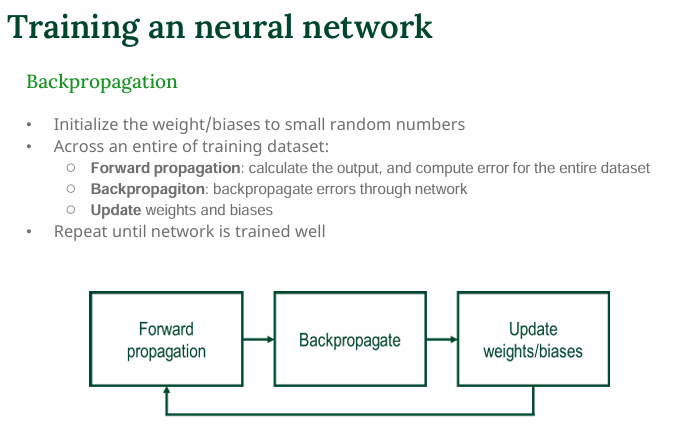
- Forward Propagation : 입력 → 출력 계산
- Backpropagation : 오차를 뒤로 전파하여 가중치에 미치는 영향 계산
- Update : 경사 하강법으로 가중치 업데이트
- 이 과정을 여러 에폭(epoch) 반복
단일 퍼셉트론과 다층 퍼셉트론에서의 경사하강법 차이
1. 구조적 차이
| 항목 | 단일 퍼셉트론 | 다층 퍼셉트론 (MLP) |
|---|---|---|
| 층 수 | 입력층 + 출력층 | 입력층 + 은닉층 + 출력층 |
| 비선형성 | 없음 (선형 분리만 가능) | 있음 (비선형 문제도 해결 가능) |
| 활성화 함수 | 선형 or 간단한 비선형 함수 | 주로 비선형 함수 (ReLU, sigmoid, tanh 등) |
| 표현력 | 제한적 | 고차원 패턴 학습 가능 |
2. 경사하강법 적용 방식 차이
| 항목 | 단일 퍼셉트론 | 다층 퍼셉트론 (MLP) |
|---|---|---|
| 적용 대상 | 출력층 가중치만 | 은닉층 + 출력층 모든 가중치 |
| 미분 방식 | 간단한 chain rule | chain rule + backpropagation 사용 |
| 오차 전파 | 없음 (출력에서 바로 계산) | 있음 (출력 → 은닉층으로 오차 전파) |
| 학습 복잡도 | 간단함 | 복잡함 (layer 수만큼 오차 전파 필요) |
