Pavlov's Dog 실험을 신경망으로 설명하기
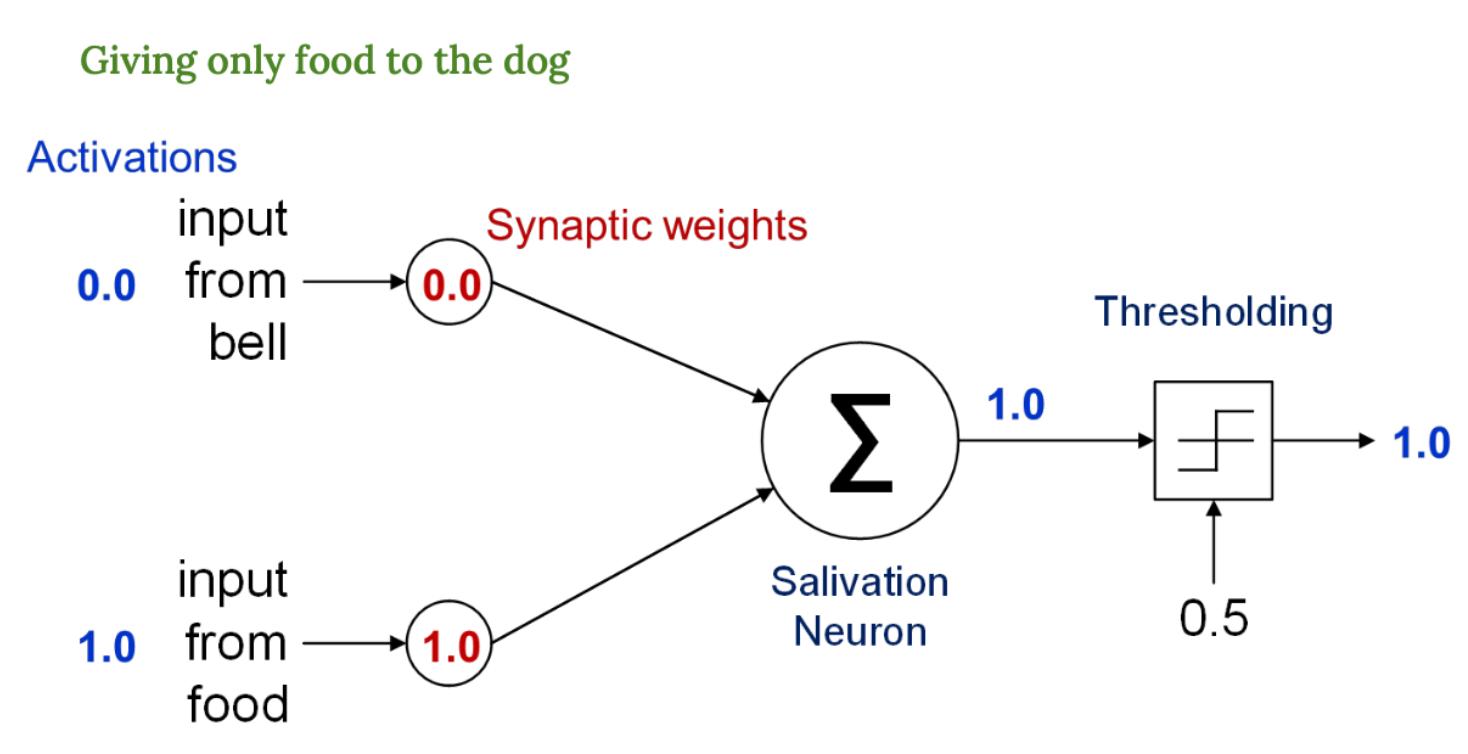
음식만 제공 → 반응함
벨만 주면 → 반응 없음
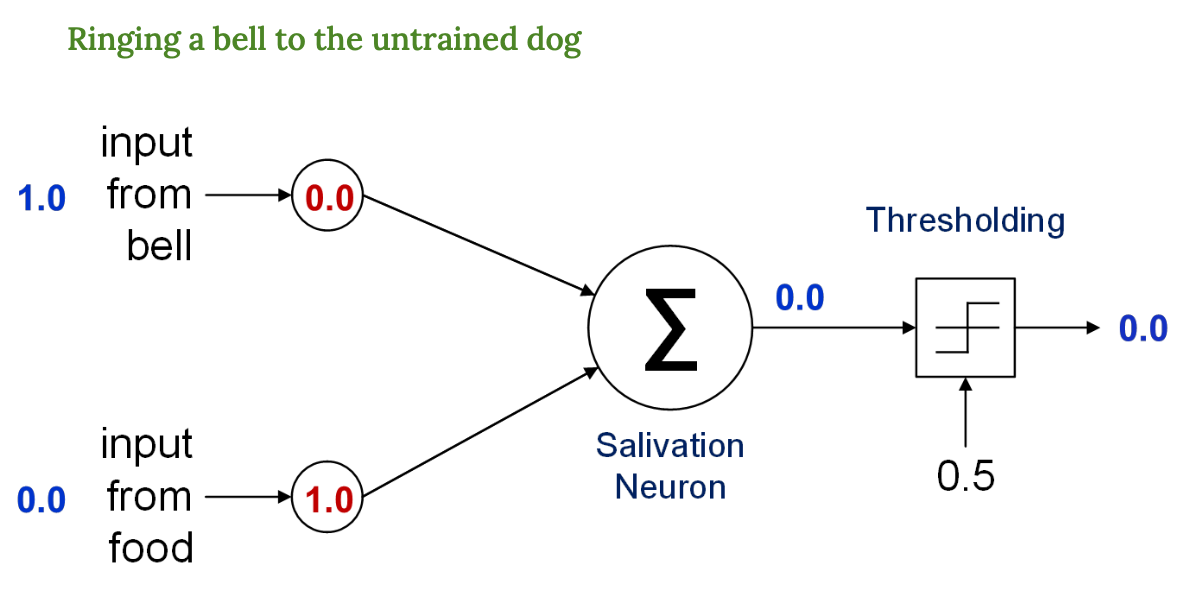
→ 사진이 잘못되어있지만, 그 input from bell 부분에 1.0 이 되고 input from food 부분이 0.0 이 되어야한다.
훈련하는 단계
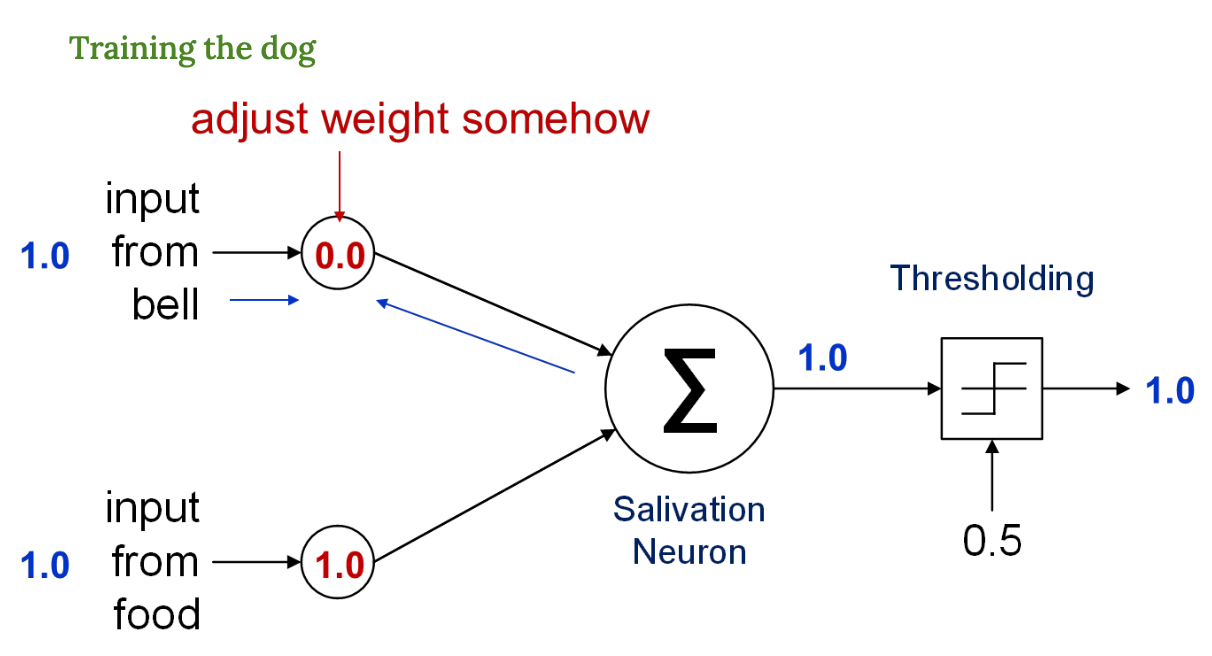
음식과 벨을 같이 줬더니 → 침을 흘린다.
벨의 가중치가 0이라 음식 가중치만 작동한 상황
(벨은 존재하지만, 그건 의미 없는 자극인 상태)
이 반복을 통해 벨의 가중치를 점점 증가시켜야함
이게 바로 학습 = '가중치를 조정하는 것'
훈련 완료된 퍼셉트론
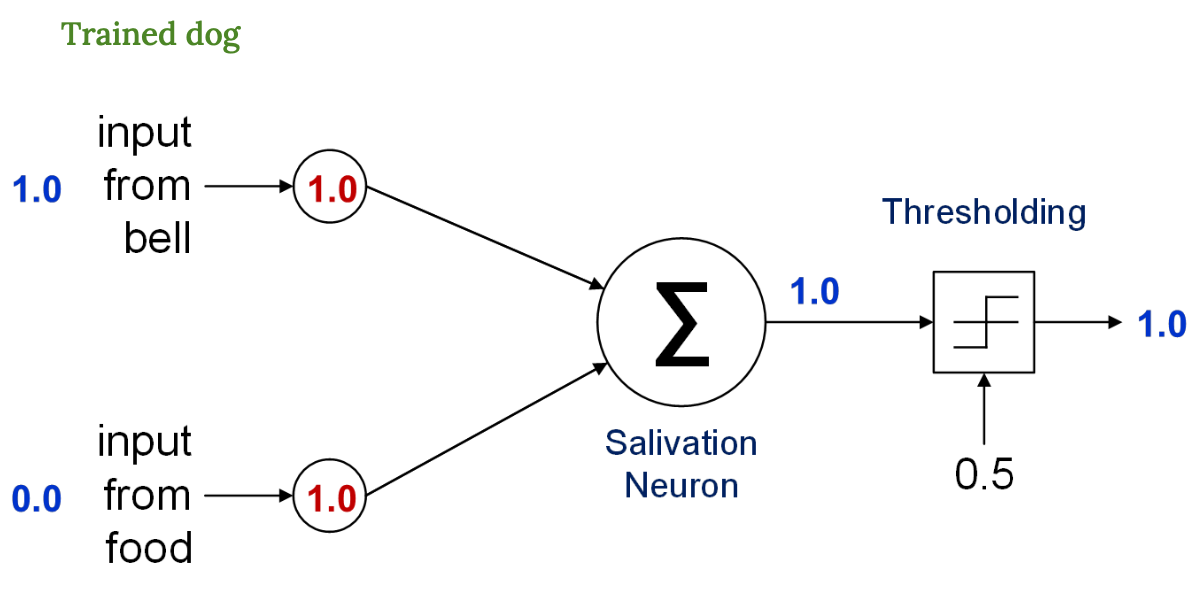
벨 입력 = 1.0
음식 입력 = 0.0
벨 가중치 = 1.0 → 학습 결과
음식 가중치 = 1.0
총합 = 1.0 → 임계값 0.5 넘음 → 침을 흘림
이젠 음식 없이도 벨 소리만 울려도 침을 흘린다.
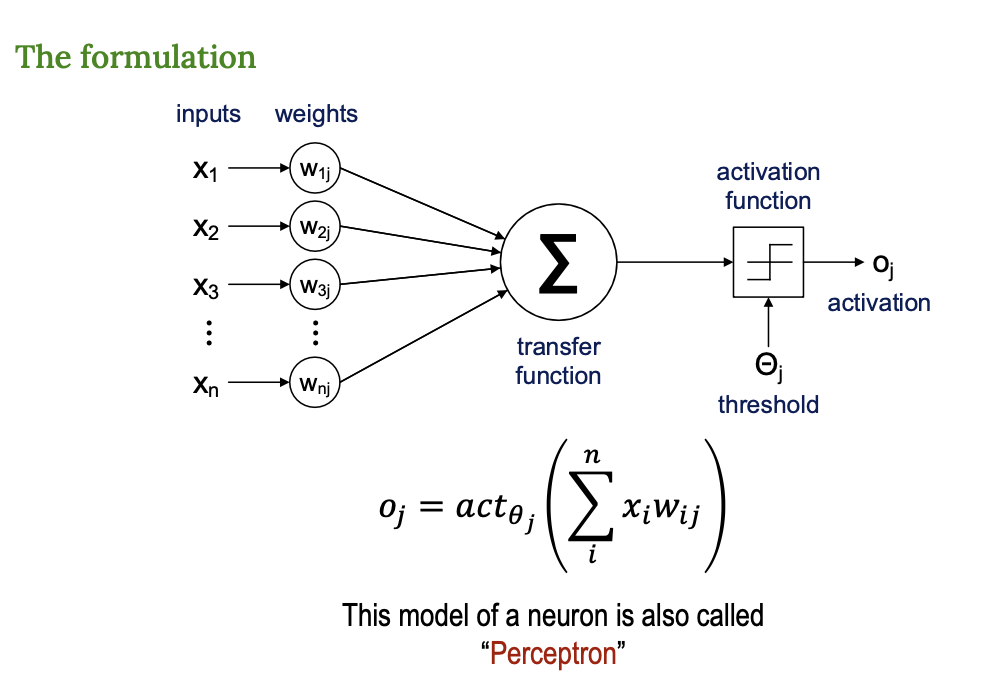
수학적 표현
이 신경망은 다음 식을 표현된다.
이 수식은 한 뉴런의 출력을 구하는 식이다.
- 입력과 가중치를 곱한 후 전부 더하고
- 그 값을 임계값과 비교해서
- 활성화 함수 act로 최종 결과를 결정한다.
퍼셉트론이 학습(가중치 조정)을 어떻게 수행하는가 ?
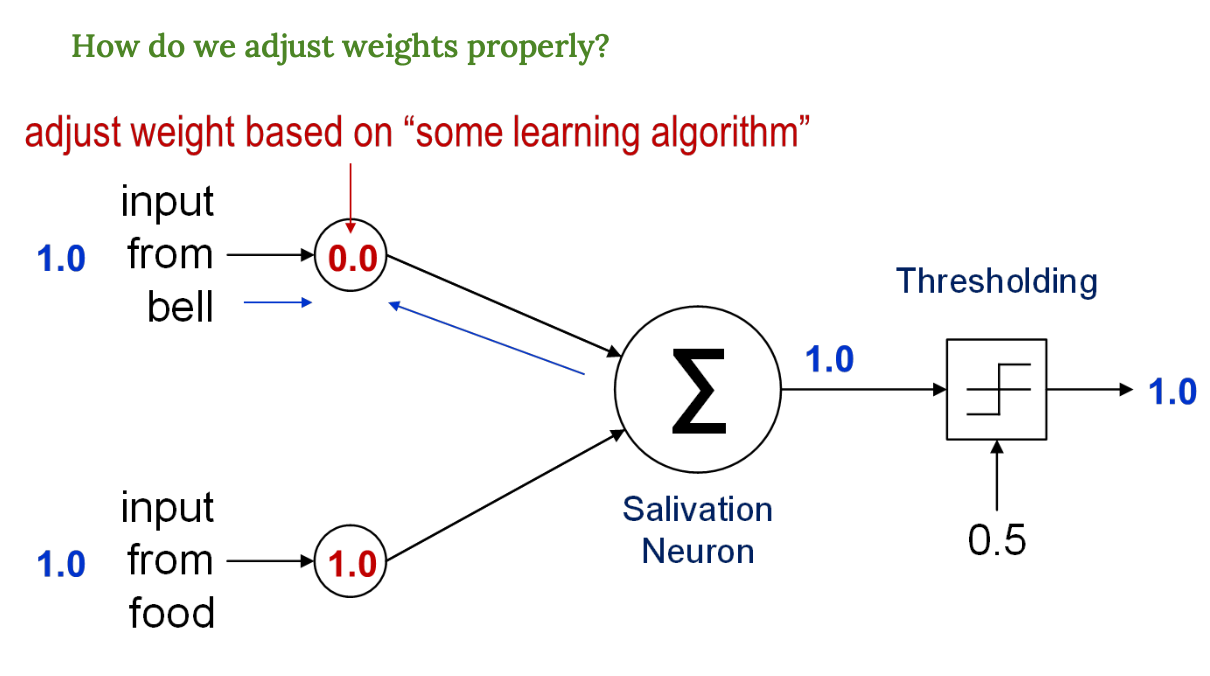
벨 입력도 있었지만, 실제로는 음식만 반응한 것이다. 벨의 가중치는 아직 0이기 때문이다.
그래서 학습 알고리즘이 이렇게 말한다.
'벨이 있었는데 침 흘림이 일어났네?' → 벨의 가중치를 올려야겠다 !
some learning algorithm은 우리가 배울 경사하강법이나 퍼셉트론 규칙 등을 의미한다.
학습이 반복되면 벨 가중치가 점점 증가해서 결국 벨만으로도 침을 흘리게 된다.
경사하강법 (Gradient Descent)
머신러닝과 딥러닝에서 가장 널리 사용되는 최적화 알고리즘
비용함수(cost function)을 최소화(minimize)하기 위해, 기울기(gradient)의 반대 방향으로 조금씩 이동하며 최적값을 찾아가는 방법이다.
- 가장 가파르게 감소하는 방향 =
기울기(gradient)의 반대 방향 - 한 번에 최적점을 찾는 것이 아니라, 여러 번 반복해서 점점 더 나은 값으로 이동한다.
수식
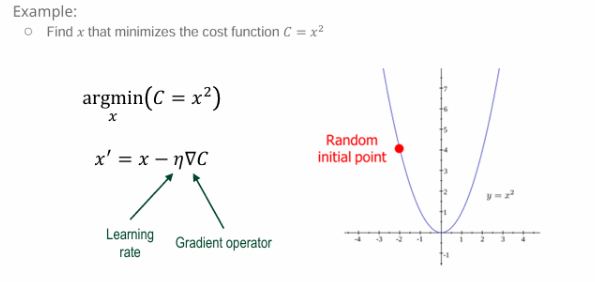
1. 최적화 문제 정의
argmin_x (C = x²)
- 라는 비용 함수 C를 가장 작게 만드는 x의 값을 찾는 것이 목표이다.
- 여기서 C는 비용함수 (cost function)이고, x는 우리가 찾으려난 값이다.
2. 업데이트 수식
x' = x - η∇C
- x : 현재 값
- x' : 다음 단계의 값 (업데이트된 값)
- η : 학습률 (learning rate) : 얼마나 크게 이동할지를 결정
- ∇C : 기울기 (gradient) : 함수 C의 변화율을 나타냄
핵심 : 현재 위치에서 기울기의 반대 방향(-∇C) 으로 학습률 만큼 이동
오른쪽 그래프 설명
- 파란 곡선 : 비용 함수 y = x^2
- 빨간 점 : Random initial point (초기값)-경사 하강법은 어디서 시작하느냐에 따라 경로가 달라짐
- 이 점에서부터 기울기 방향으로 점점 아래쪽을 향해 이동하며 최적점(최솟값)을 찾게 된다.
단일 뉴런을 학습시키는 과정
Training a Neuron
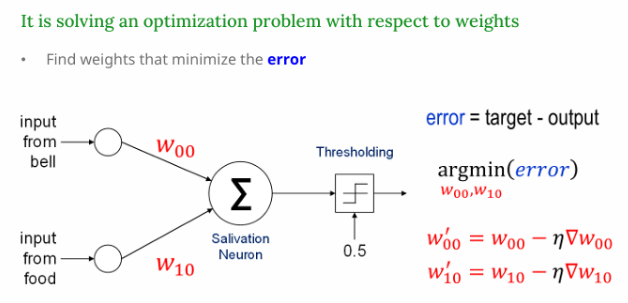
- 목표 : 오차(error)을 줄이는 방향으로 가중치(weight)를 조정함
- 오차 =
error = target - output - 사용되는 알고리즘 : 경사하강법 (Gradient Descent)
- 가중치 업데이트 식 : w' = w - η∇w
→ 여기서 학습률 = η, ∇w = 오차에 대한 기울기
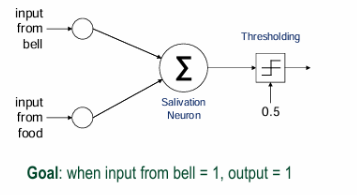
목표 설정
우리의 목표는 종소리에 반응하여 침을 흘리게 만들기
1. 초기 가중치 설정
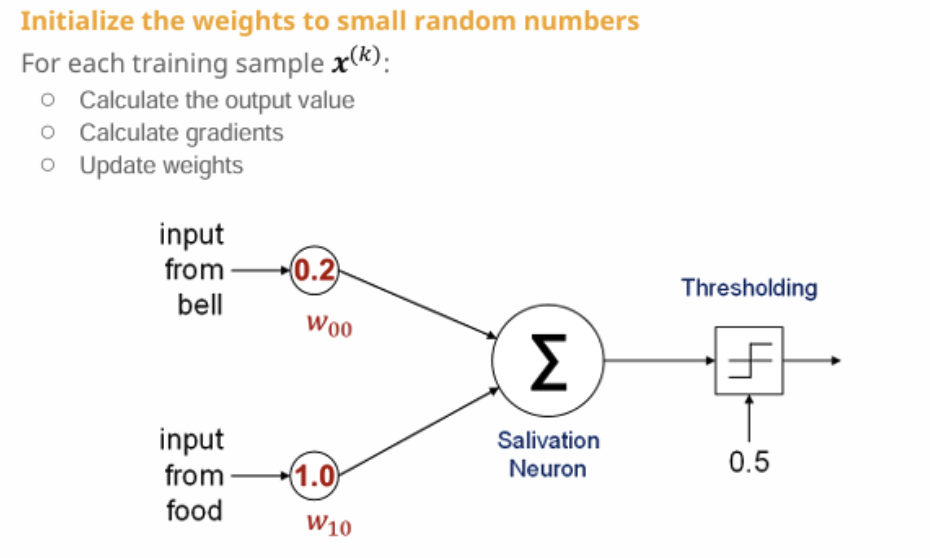
초기 가중치
- 종소리 입력에 대한 가중치 w00 = 0.2
- 음식 입력에 대한 가중치 w10 = 1.0
아직 학습 전, 그냥 초기 상태임.
2. 출력 계산
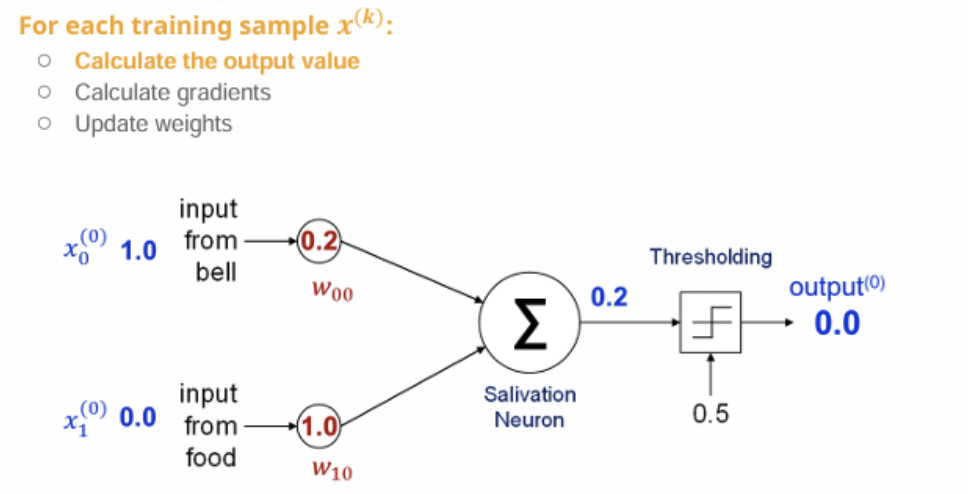
입력 값
- 벨 입력 x0 = 1.0
- 음식 입력 x1 = 0.0
계산 → z = x0 ⋅ w00 + x1 ⋅ w10 = 1 ⋅ 0.2 + 0 ⋅ 1.0 = 0.2
임계값 = 0.5
결과 = 0.2는 0.5보다 작으므로 output = 0.0
기울기 계산
타겟이 1인데 출력이 0이므로 학습이 필요하다 !!
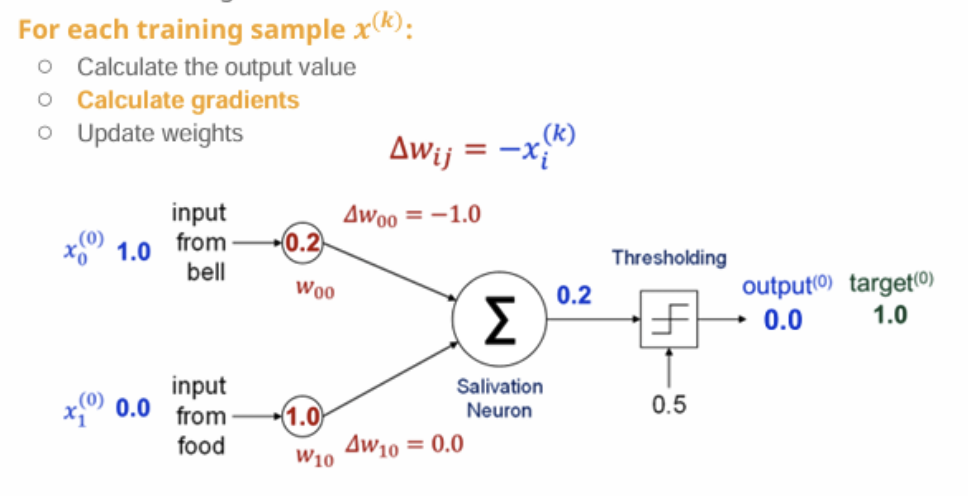
오차 기울기 계산식
→ 벨 입력에 대해 = - 1.0,
음식 입력은 사용되지 않았으므로 변화 없음 = 0
3. 가중치 업데이트
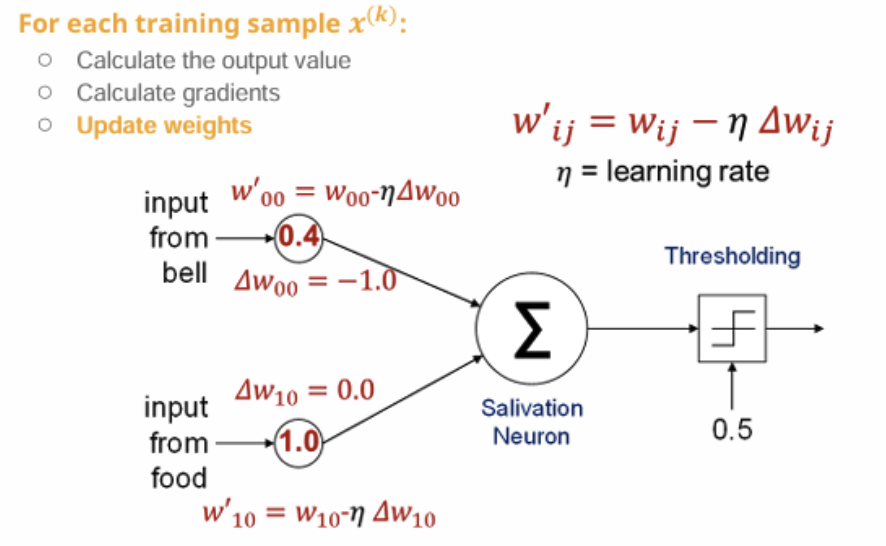
경사 하강법을 적용하여 w′=w−η⋅Δw
예시에서 η = 0.2라고 가정하면
w'00 = 0.2 - (-1.0) * 0.2 = 0.4
→ 가중치 증가 !
w10은 변화 없음 (입력이 0이었기 때문)
4. 업데이트된 가중치로 다시 예측
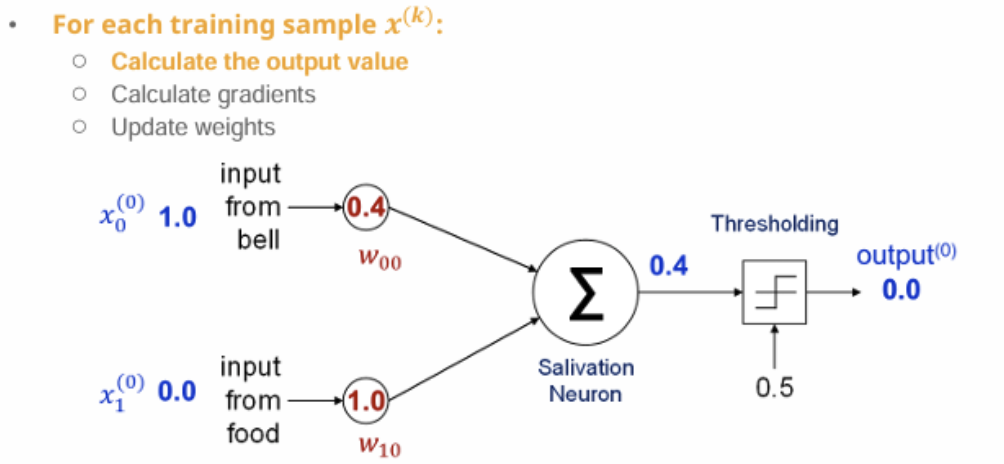
-
가중치
w00 = 0.4
w10 = 1.0 -
입력
벨 = 1.0
음식 = 0.0
계산 z = 1⋅0.4+0⋅1.0=0.4<0.5 → output = 0.0
여전히 목표값 1에 도달하지 못함
5. 또 다시 기울기 계산
오차가 여전히 존재하기 때문에 또 학습을 한다.
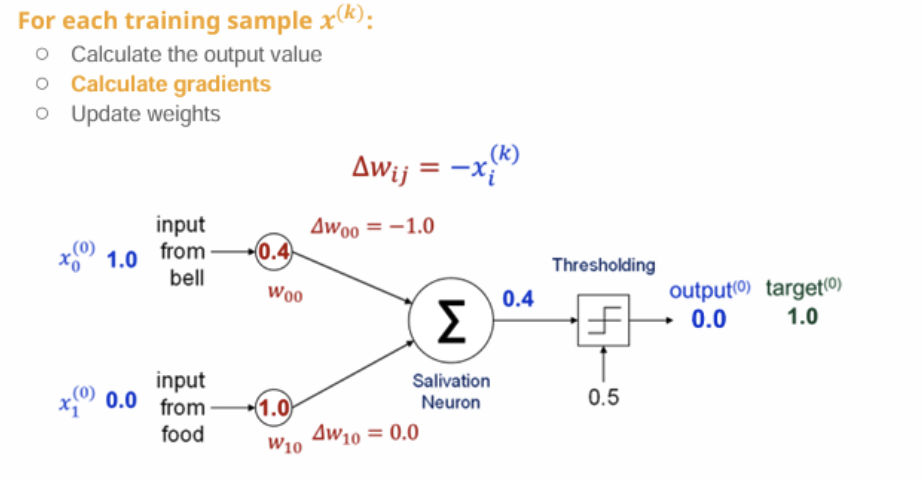
- 입력
벨 = 1.0
음식 = 0.0
= -1.0
= 0.0
6. 가중치 업데이트
다시 업데이트를 한다.
= 0.4 - (-1.0) * 0.2 =0.6
= 1.0
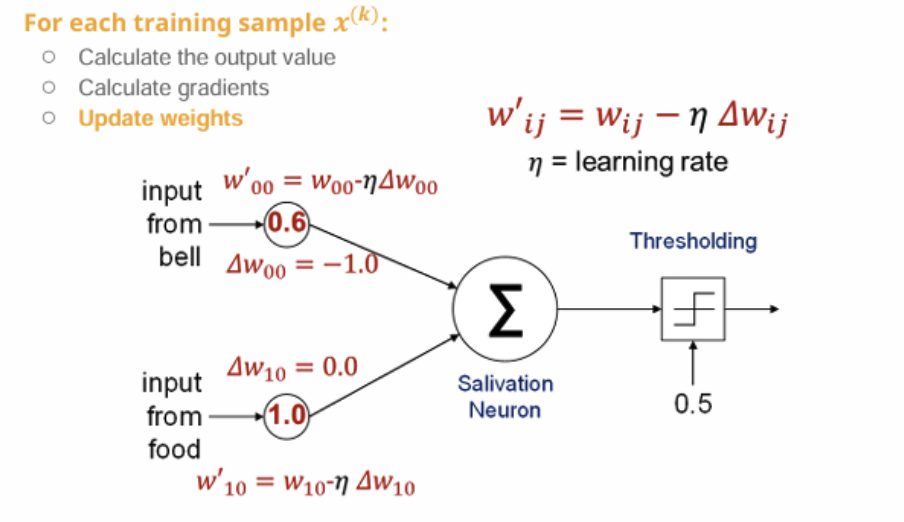
7. 드디어 성공 !
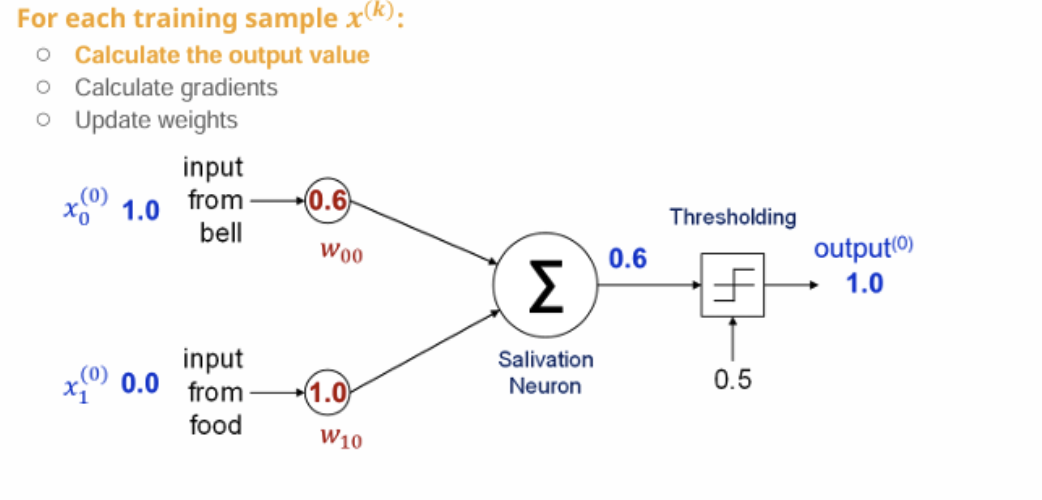
-
입력
벨 : 1.0
음식 : 0.0 -
가중치
w00 = 0.6
w10 = 1.0
계산 z=1.0⋅0.6+0.0⋅1.0=0.6>0.5 → output=1.0
목표값에 도달 ! 학습 성공함 !
정리
- 초기 가중치 설정
- 입력값으로부터 출력 계산
- 목표값과 비교 → 오차 계산
- 오차를 줄이기 위해 기울기 계산
- 가중치 업데이트
- 다시 출력 계산 → 목표에 도달할 때까지 반복
Matrix Notation
1. 출력 계산
핵심 목표
입력값과 가중치가 주어졌을 때, 출력을 계산하는 단계이다.
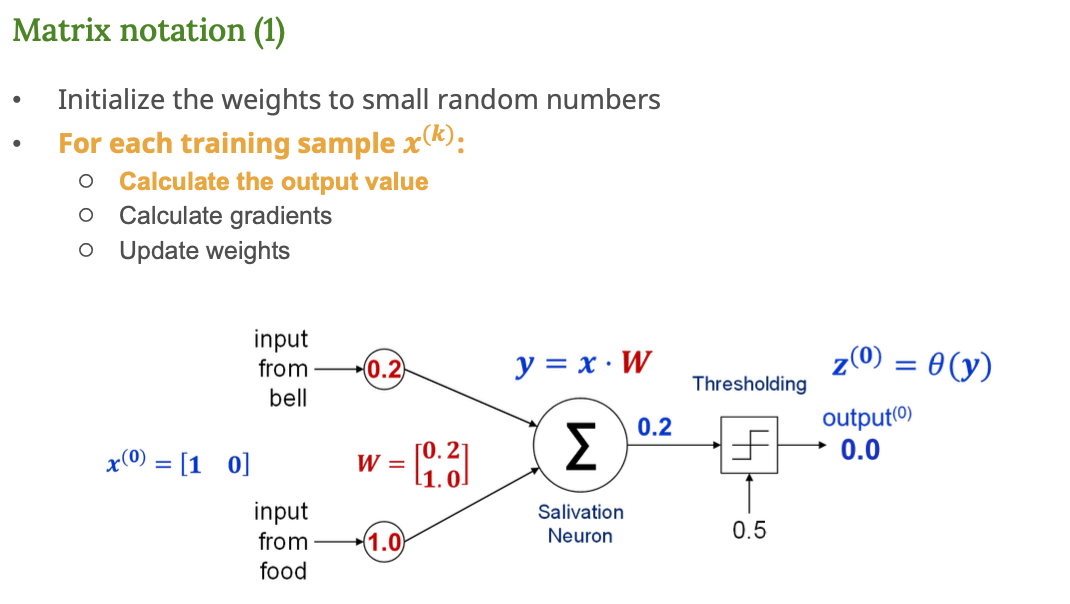
구성 요소 해석
-
입력 벡터 = [1, 0]
→ 종소리(bell) 는 1, 음식(food) 는 0 -
가중치 벡터 W = [0.2, 1.0]
→ 종소리에 대한 가중치는 0.2, 음식에 대한 가중치는 1.0 -
출력 계산식
y = x W = 1 0.2 + 0* 1.0 = 0.2 -
임계값(threshold) = 0.5
→ 결과가 0.5 보다 작으므로 출력은 0 (침을 흘리지 않음)
2. 기울기 계산
핵심 목표
출력이 틀렸으므로, 가중치 어떻게 바꿔야 할지 방향을 계산하는 단계
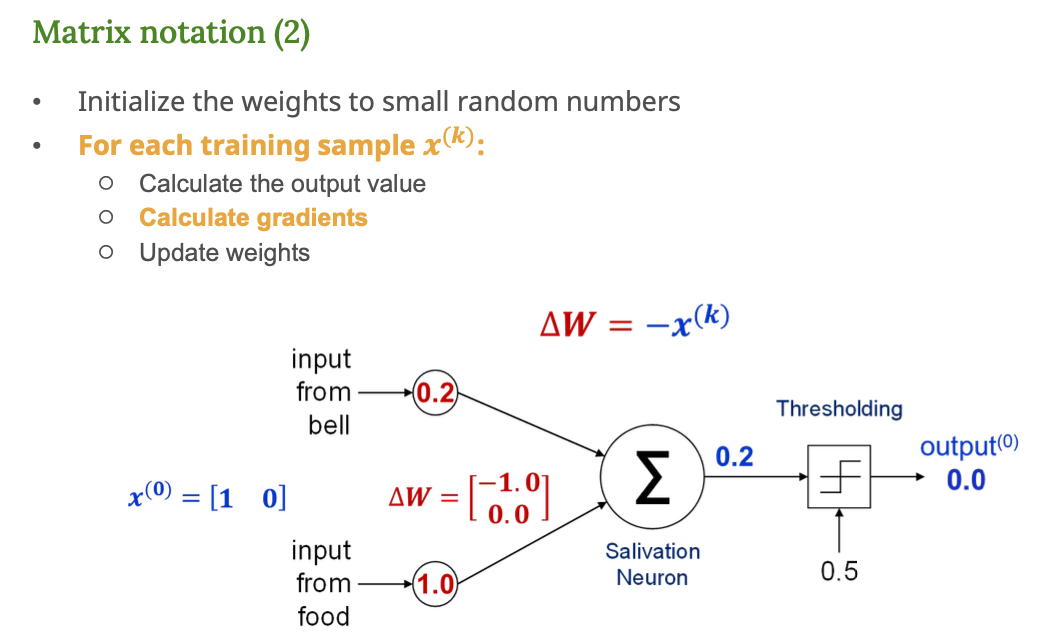
내용 해석
여전히 입력은 = [1 0]
출력이 0인데, 목표는 1이다. → 오차 발생
- 학습 규칙
→ 종소리 입력이 1이었으나 그 부분의 가중치를 올려야 한다는 의미(기울기 = -입력)
3. 가중치 업데이트
핵심 목표
계산된 기울기를 활용해 가중치를 실제로 업데이트하는 단계
수식 적용
학습률 η=0.2 라고 가정하면, 업데이트 공식은 다음과 같아
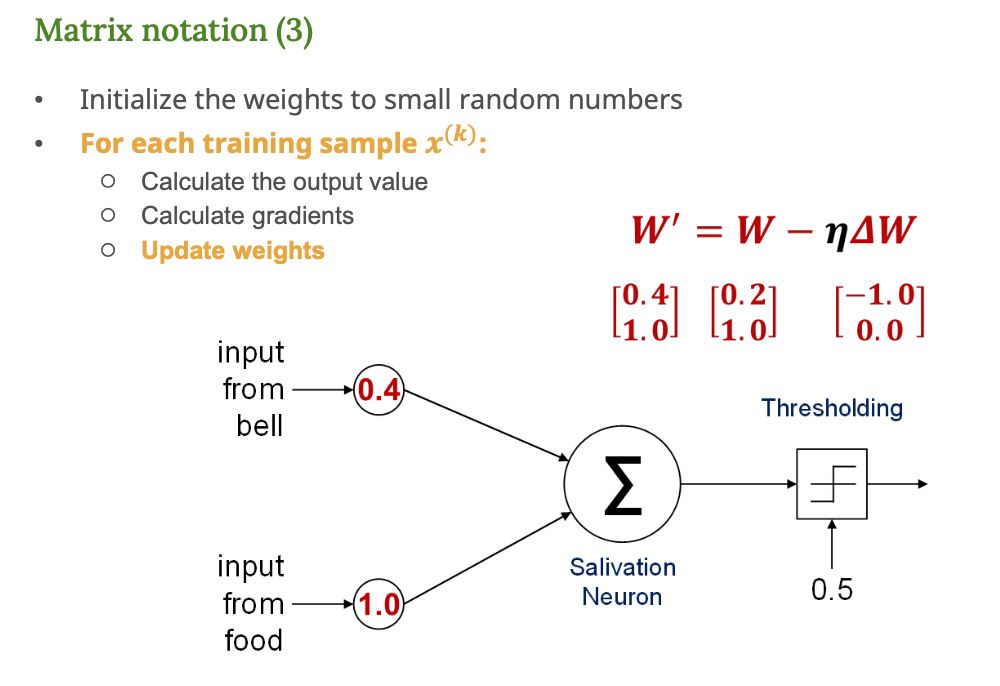
의미
- 종소리에 대한 가중치가 0.2 → 0.4로 증가함
- 이제 종소리만으로도 침을 흘릴 가능성 더 높아짐
- 이 과정을 반복하면 점점 학습이 된다
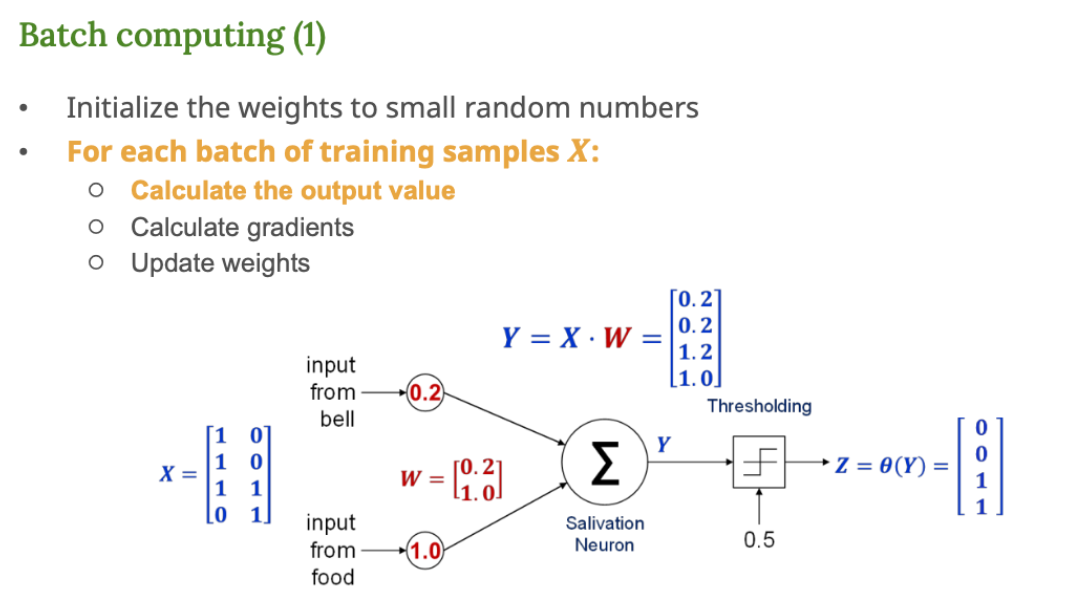
배치 학습 (Batch Computing)
1. 여러 샘플의 출력 계산
핵심 개념
여러 입력을 한꺼번에 넣고, 출력값을 한 번에 계산한다.

2. 오차 계산 & 기울기 계산
핵심 개념
출력값이 틀린 샘플들에 대해 전체적으로 기울기를 계산
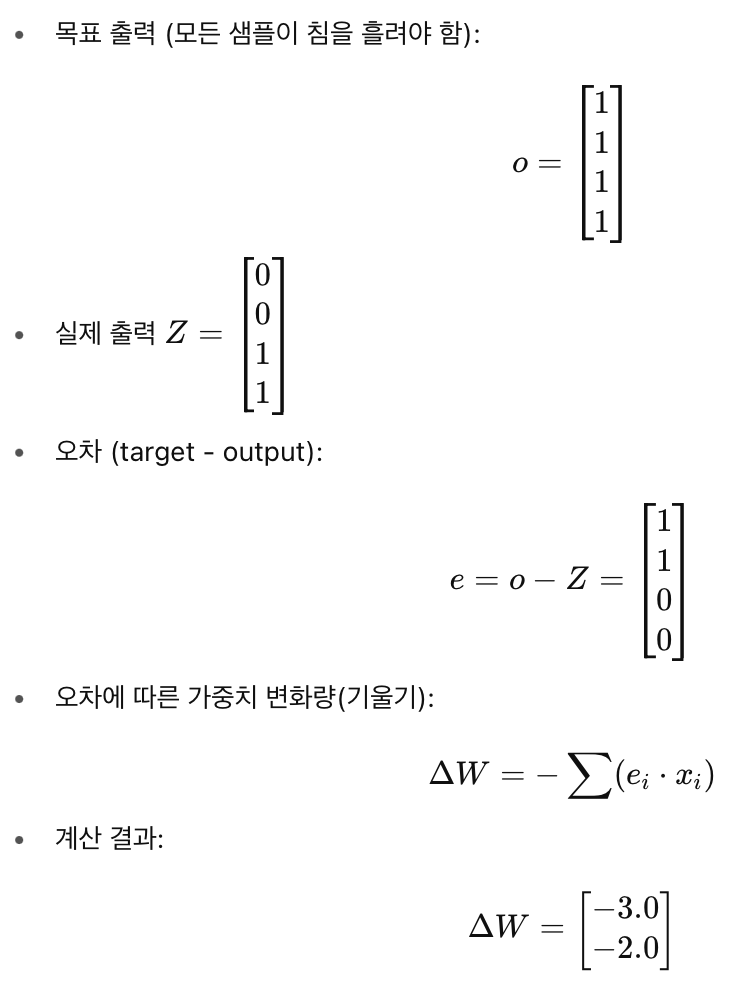
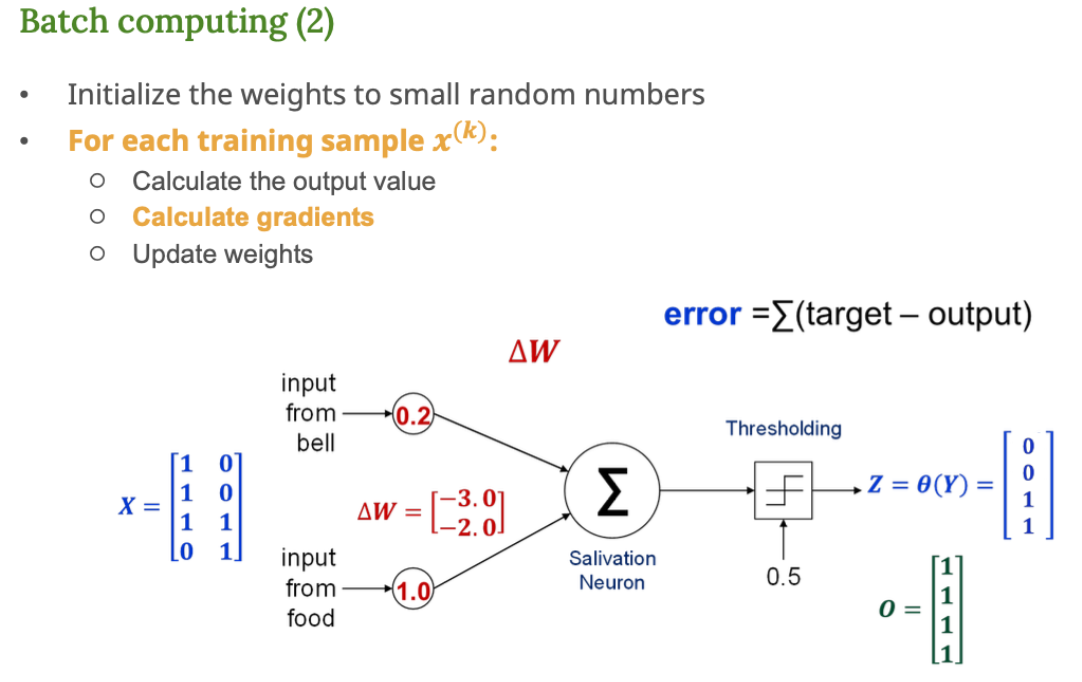
3. 가중치 업데이트
핵심 개념
아까 구한 기울기를 이용해서 가중치를 조정하는 단계

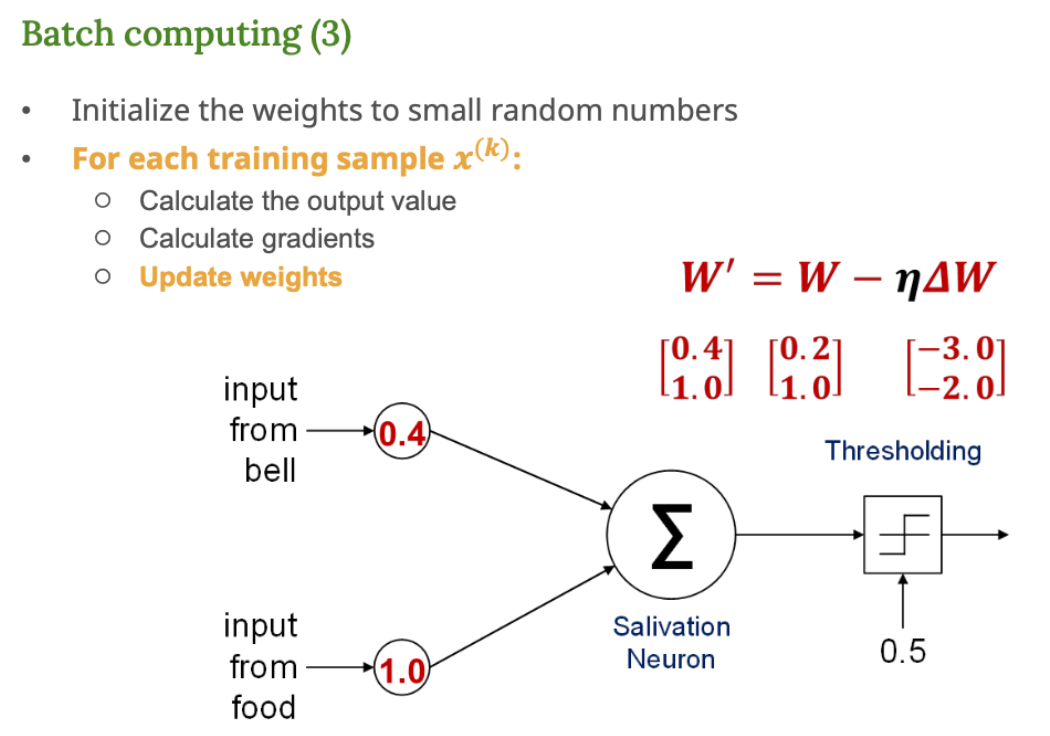
Batch Computing
Batch Computing 은 신경망 학습에서 일반적으로 사용되는 방식이다.
왜 Batch Computing 을 쓰는가?
- 전체 데이터셋을 한 번에 처리해서 효율적으로 학습
- 실제 신경망 학습에서는 보통 수천~ 수백만개의 데이터가 있다.
- 이것을 하나씩 처리하면 너무 느리고 때문에
- 한 번에 여러 샘플(=배치)를 동시에 넣어서 계산하면 시간도 절약되고 효율도 높아짐
- 벡터나 스칼라보다 행렬 연산이 훨신 빠름
- 벡터 연산 : 샘플 하나씩 곱셈 → 반복
- 행렬 연산 : 샘플 여러 개 한꺼번에 곱셈 → 병렬 처리 가능
- 특히 GPU 같은 병렬 연산 환경에서는 행렬 연산의 성능이 훨씬 좋음
이미지 분석
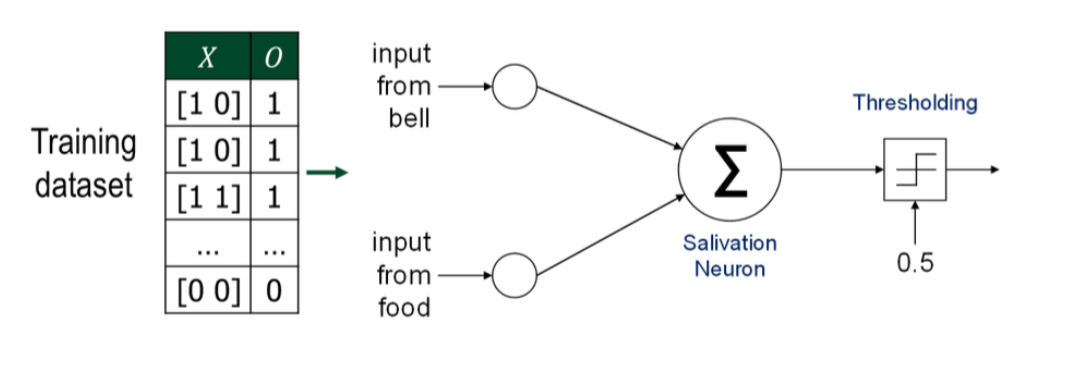
- 왼쪽은 입력 X와 목표 출력 O 를 나타낸 훈련 데이터셋
- 전체 데이터셋을 한꺼번에 퍼셉트론(뉴런)에 넣어서 학습시킴
Epoch과 미니 배치(Mini-Batch)
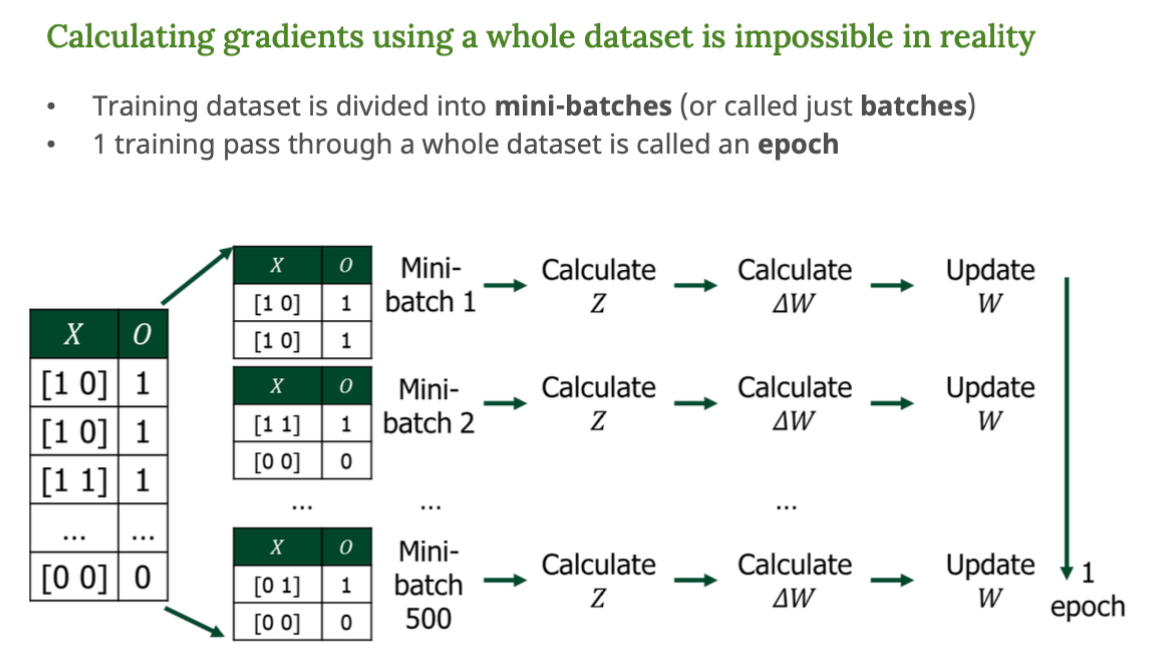
전체 데이터셋을 한 번에 학습시키는 건 현실적으로 어렵다.
→ 그래서 조금식 나눠서(mini-batch) 학습하고
→ 그걸 여러 번 반복해야한다.
- Batch : 여러 개의 샘플을 한 번에 학습하는 단윙
예) 10개의 샘플을 한꺼번에 - Mini Batch : 전체 데이터셋을 나눈 작은 조각
예) 2개씩 500조각 - Epoch : 전체 데이터를 한 번 전부 학습한 것
예) 500 미니 배치 모두 학습 완료 → 1 epoch 끝
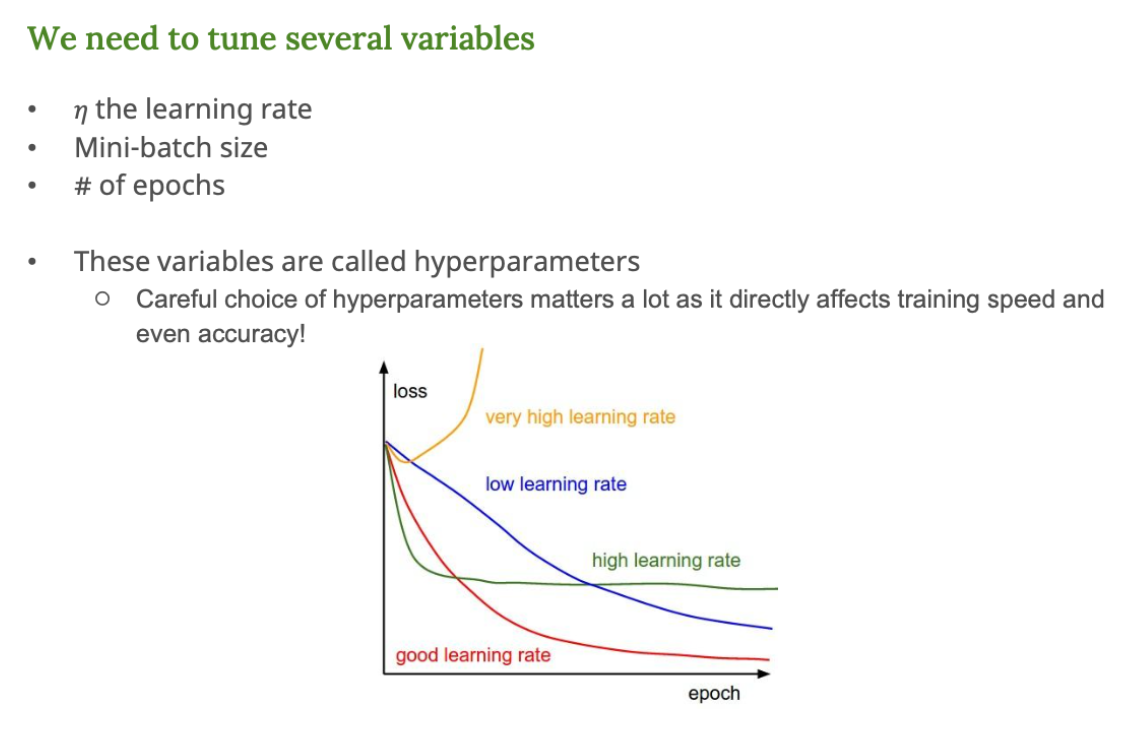
하이퍼파라미터 (Hyperparameters)
학습 성능은 '하이퍼파라미터(hyperparameter)' 에 크게 좌우된다.
주요 하이퍼파라미터
- 학습률 (learning rate) : 얼마나 크게 weight를 업데이트할지 결정
- Mini batch size : 한 번에 학습할 데이터 개수
- number of epochs : 전체 데이터를 몇 번 반복해서 학습할지