활성화 함수
활성화함수가 없으면 신경망은 그냥 선형 함수의 조합일 뿐이다.
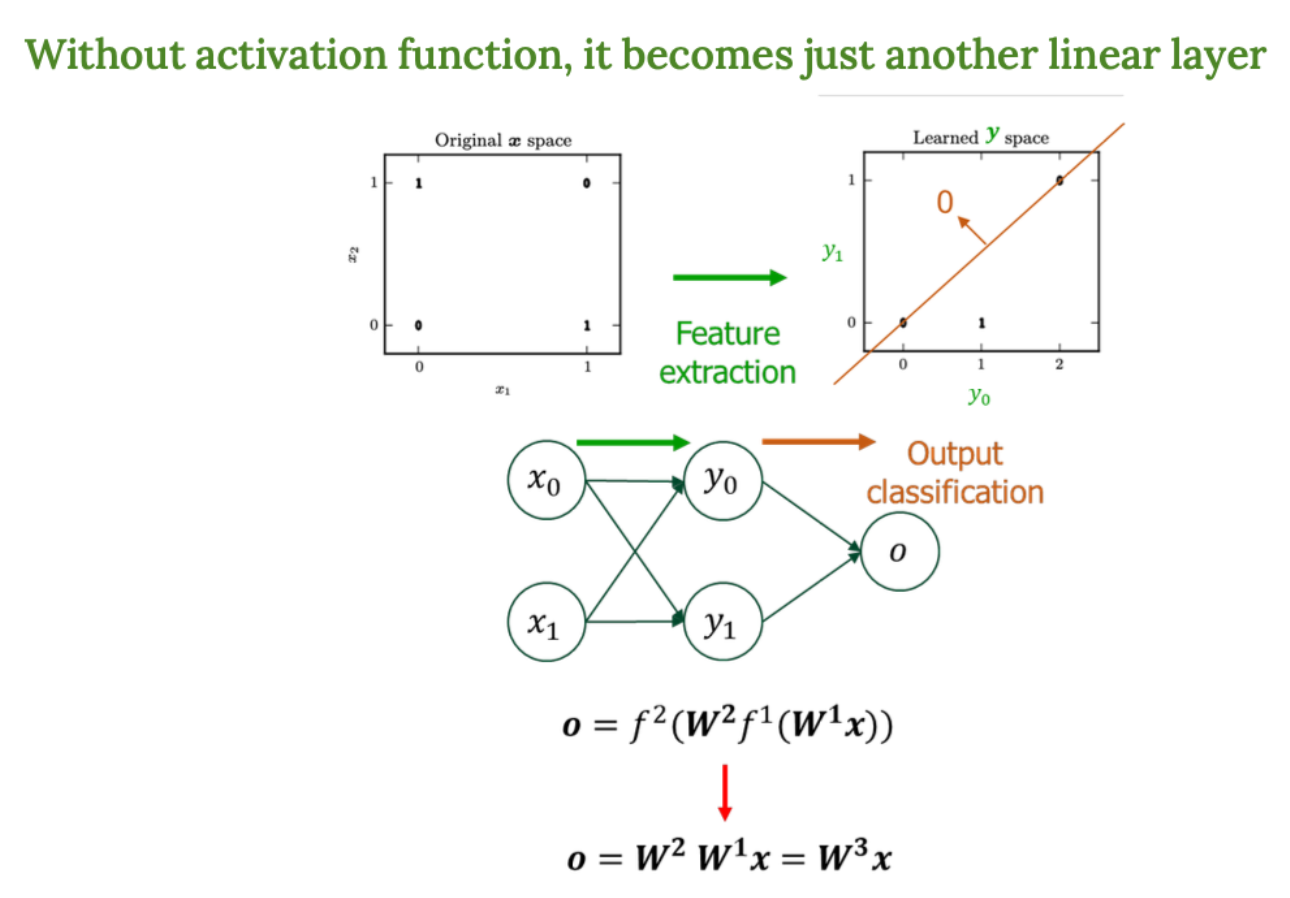
-
original x space
입력 벡터 x의 원래 공간
선형적으로 이 데이터를 구분할 수 없음 -
learned y space
은닉층을 통과한 후의 공간 (feature extraction 완료된 공간)
이제는 선형 분리가 가능하다 → 선형 분류기(직선)으로 구분 가능
다양한 활성화 함수
다양한 활성화 함수들이 존재하며 각기 장단점이 있다.
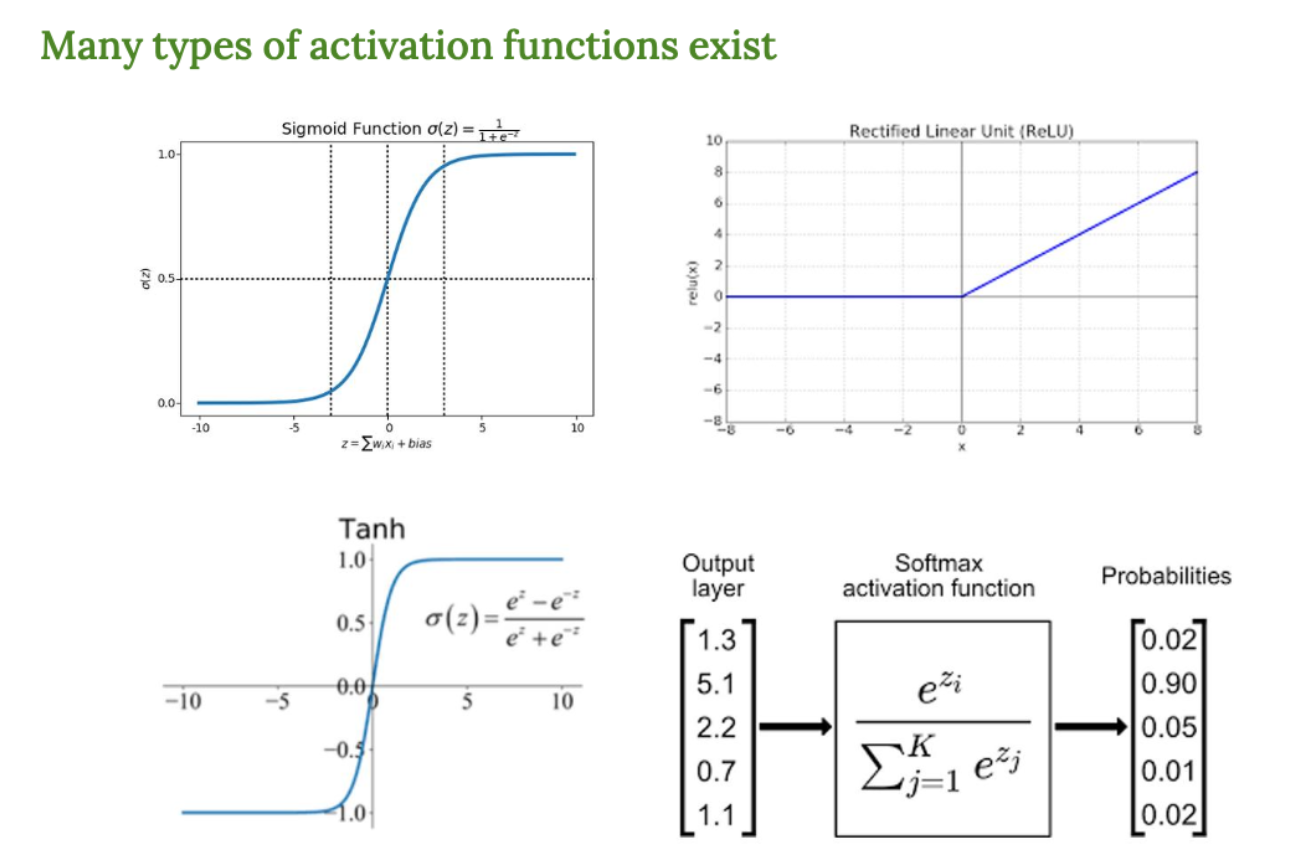
- Sigmoid
- 출력 : 0 ~ 1
- 장점 : 확률처럼 해석 가능
- 단점 : 기울기가 작아지며 학습이 느려짐
- Tanh(Hyperbolic Tangent)
- 출력 : -1 ~ 1
- Sigmoid 보다 중심이 0이라 학습이 더 안정적임
- ReLU (Rectified Linear Unit)
- f(x) = max(0, x)
- 간단하지만 매우 강력함
- 음수 입력에 대해 0 출력 → sparse한 활성화 유도
- Softmax
- 다중 클래스 분류에 사용
- 각 클래스의 확률값으로 변환
- 출력의 합은 1이 되도록 정규화
ReLU ?
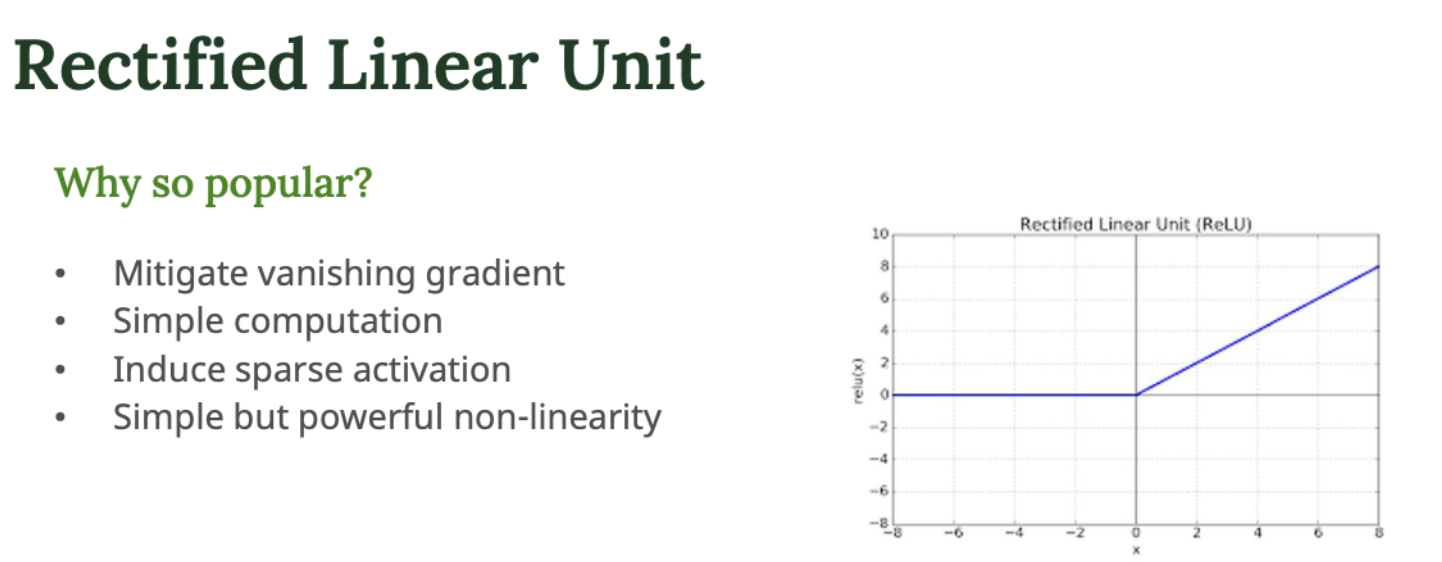
장점
- vanishing gradient 완화
→ Sigmoid 처럼 기울기 작아지는 현상이 적다. - 계산이 간단하다.
→ max(0,x) 라 연산 비용이 낮다. - sparse activation
→ 일부 뉴런만 활성화 → 과적합을 줄이는 데 도움 - 간단하지만 강력한 비선형성 제공
→ 여러 층이 쌓여도 복잡한 문제 학습 가능
