1주차 WIL
이번 글에서는 딥러닝의 개념과 선형회귀에 대해서 공부한 것들에 대해 간략하게 적어보려고 한다.
정기 모임에서 배운 것 + 사전 지급 강의에서 배운 것 + 내가 따로 찾아보면서 공부한 것들을 내 표현대로 정리해보았다.
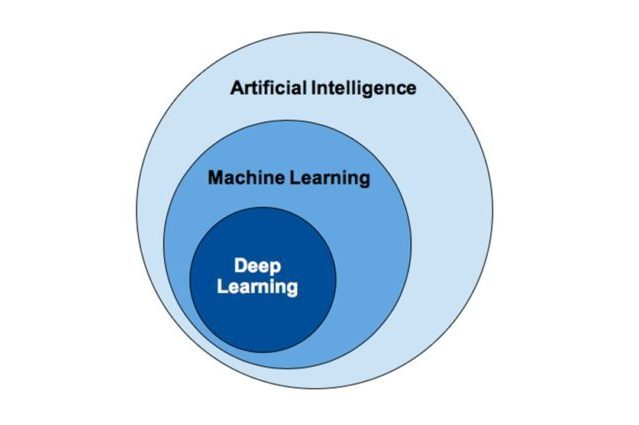
1. 딥러닝의 개념
인공지능, 머신러닝, 딥러닝의 차이점
- 인공지능 : 인간의 지능을 모방하여 문제를 해결하는 기술. 규칙 기반부터 자율 학습까지 다양한 방식이 있음
- 머신러닝 : 데이터를 이용해 모델을 학습 → 예측, 결정
- 딥러닝 : 머신러닝의 하위 분야. 신경망을 여러층으로 쌓아서 데이터를 학습. 대규모 데이터, 복잡한 문제에 강함 (대신 학습에 비용이 많이 발생)
딥러닝의 개념
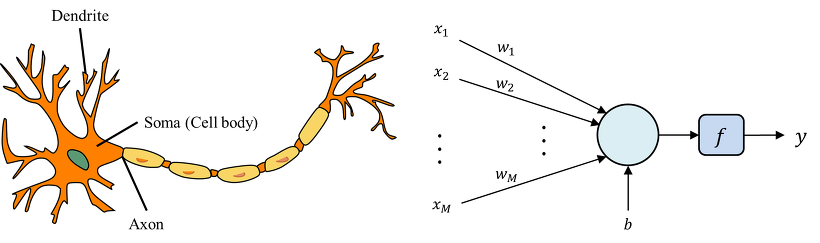
출처:https://ars.els-cdn.com/content/image/1-s2.0-S1746809422002270-gr1.jpg
{kind=link}
- 인공신경망을 기반으로 한 머신 러닝의 한 분야
- 인공신경망 : 인간의 두뇌를 수학적으로 모방한 것!
- 인공신경망의 층을 쌓아올려서 데이터로부터 특징을 자동으로 학습하고, 이를 통해 복잡한 문제를 해결함
- 입력 데이터에서 중요한 패턴 추출 → 예측, 분류, 생성 등 다양한 작업 수행
- 이 중요한 패턴은 컴퓨터 기준이라서 사람의 기준과 다름!
- 이미지, 자연어, 음성, 의료 다양한 분야에 쓰임
💡 사람의 뇌 구조를 따와서 컴퓨터에 적용시킨 느낌?!
머신러닝의 과정
- 태스크 정의 → 평가 지표 정의 → 최적화
- 태스크 정의 : AI가 해결해야할 문제를 정의 - 입력과 예측값 출력.
- 평가 지표 정의 : AI가 예측한 값과 실제 값(정답)을 비교해서 정확도를 계산하는 방식으로 정의 - 함수로 표현
- 최적화 : 평가 지표가 가장 좋은 AI 모델을 찾기
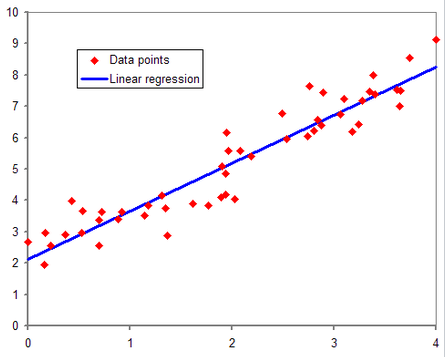
🌟선형 회귀 (linear regression)
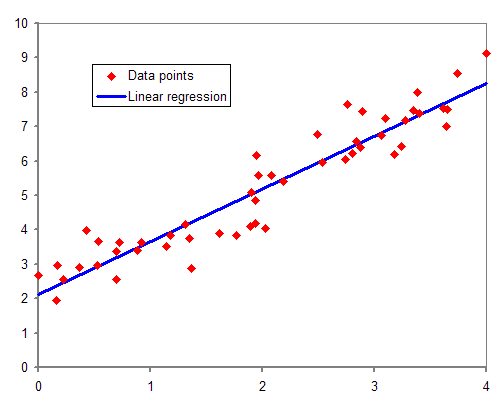
출처 : https://blog.kakaocdn.net/dn/dkPQPp/btrgCGYXkSv/ScgHHGULTWFRY4HYrrY7h0/img.png
{kind=link}
https://youtu.be/LZe94nm1lZg?si=VPzeHicu6uJRvCo1
- ✅ 머신러닝의 기본 작동 원리!
- 알고 있는 데이터 값을 사용하여 모르는 데이터의 값을 예측하는 데이터 분석 기법
- 그래프 위에 점이 우리가 알고 있는 데이터 값이고, 데이터 값들의 경향성을 선으로 그려낸 것
- 최적의 선을 찾기 위해 계속 방향을 수정해서 try (사람이랑 닮았죠?)
- 원인에 해당하는 변수 x (=독립 변수)
- 결과에 해당하는 변수 y (=종속 변수)
- 직선 그래프니까 f(x) = wx + b 이런 식으로 표현할 수 있음.
최적의 선을 찾기 위한 여정 - MSE(평균 제곱 오차)
- 최적의 선을 찾기 위해서는 우선 오차를 계산해야함.
- 여기서는 오차의 제곱의 평균을 구해서 AI가 내놓은 예측 값과 실제 값의 오차를 계산하고 있다.
- N : 데이터의 총 개수
- : 머신러닝 모델이 예측한 값
- :실제 값. 모델이 맞춰야할 정답
- : 모델이 예측한 값과 실제 값의 차이 (= 오차)
- : 제곱하는 이유 - 오차가 양수, 음수 상관없이 양수로 만들어서 평가하기 위해
- : 모든 데이터에서 발생한 오차를 다 더한다.
- : 평균을 내기 위해 데이터 포인트의 개수대로 나누기!
(예시)
- 실제 피규어 가격 = 100만 원
- 모델이 예측한 피규어 가격 = 120만 원
- 오차 = 120−100= 20 (만원)
- 오차 제곱 = 400
좋아.. 오차까지는 구하는 방법을 알았다. 이걸로 성능 평가도 할 수 있을 것 같다.
그러면 기울기를 수정해야하는데, 여기서는 경사하강법이라는 것을 배웠다.
경사하강법
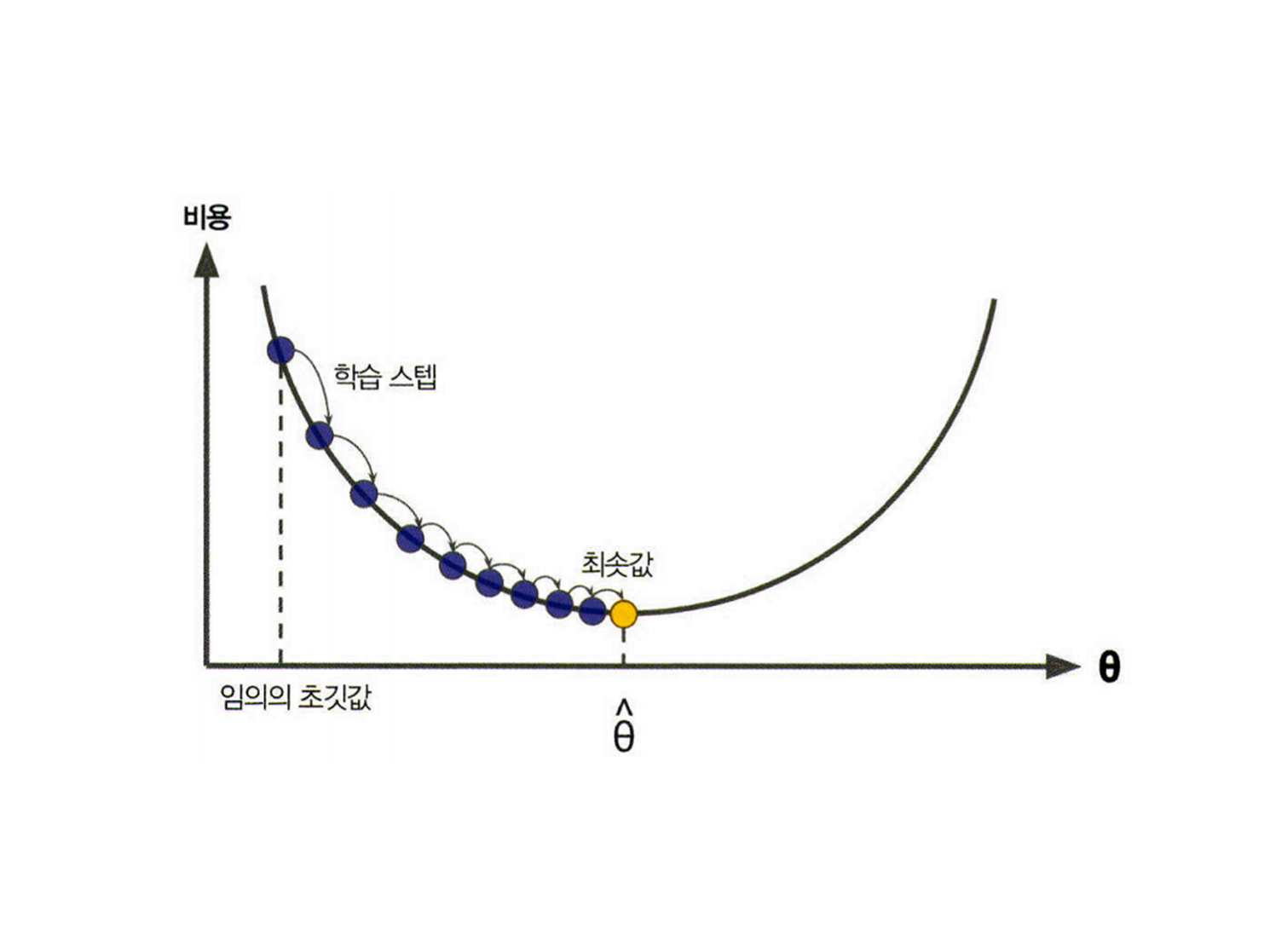
출처 : https://hwk0702.github.io/img/gradient.png
- 처음에는 모델 그래프의 직선인 에서 기울기를 결정하는 와 의 값을 랜덤하게 초기화를 함.
- 그런 다음, 오차를 계산하고 업데이트 방향을 결정함. 이 때 기울기(미분)를 사용해 업데이트 방향을 정함
- 이렇게 기울기 값을 이용해 와 를 계속 수정하면서 오차가 점점 줄어드는 방향으로 이동함
- 이 과정은 기울기가 거의 0에 가까워질 때까지 반복됨.
- 오차가 최소로 되는 지점을 찾는 여정이라 할 수 있겠다
선형 회귀는 XOR 문제를 해결할 수 없다?!
- 단일 퍼셉트론 - 선형 분류(y = ax + b로 표시되는 선형(직선) 함수)
- ⇒ XOR(베타적 논리합) 같은 비선형(곡선) 문제 해결 X
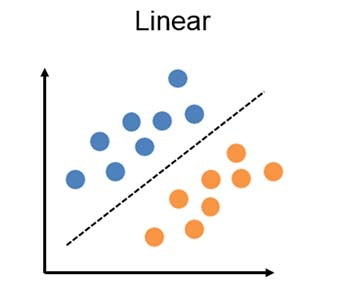
선형 함수(선형적 = 직선 line)
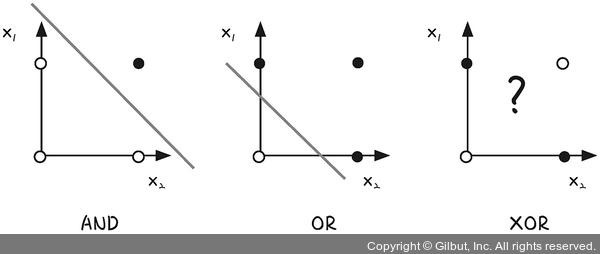
- XOR 문제는 두 입력이 다를 때만 True(1)을 출력하기 때문에, 단일 퍼셉트론으로는 해결X
- BUT 다중 퍼셉트론은 은닉층을 통해 비선형성을 학습할 수 있어서 XOR 문제를 해결할 수 있음
🧠 퍼셉트론과 다층 퍼셉트론
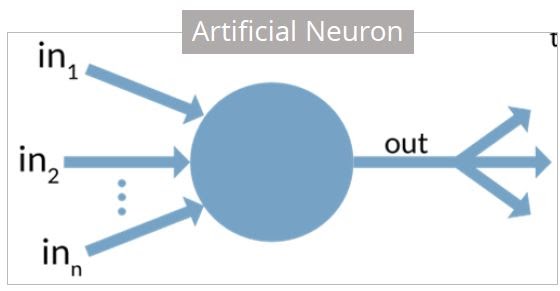
퍼셉트론
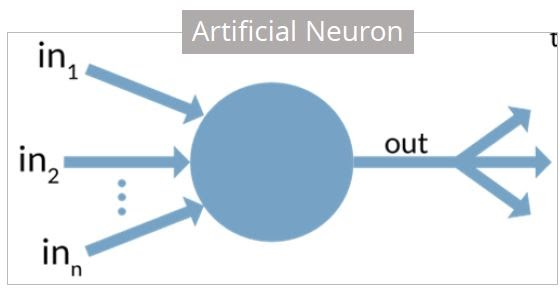
{kind=link}
- 사람 뇌의 뉴런을 수학적으로 흉내낸 것
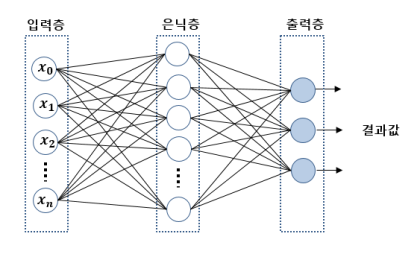
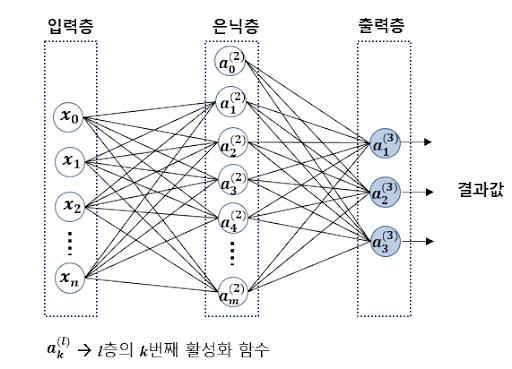
다층 퍼셉트론(MLP 멀티 레이어 퍼셉트론)
출처 : https://blog.kakaocdn.net/dn/bWGJOk/btqCAPoyI6J/pN7cSTLpzyIX3ekApv040k/img.png
{kind=link}
- 위에서 설명한 뉴런 같은 퍼셉트론을 여러 층으로 쌓은 것
- 입력층, 은닉층, 출력층으로 구성됨
- 입력층 : 각각의 입력을 처리
- 은닉층 : 복잡한 문제 계산
- 출력층 : 결과 출력
인공신경망은 어떻게 작동하나요?
- 입력값(x) 받음 → 입력값에 가중치(weight)를 곱하고 편향(bias)을 더함.
💡 가중치(weight)
- 입력 데이터의 중요도를 조절하는 값 ⇒ “이 입력이 결과에 얼마나 영향을 미칠까?”
- 예시 ) 라면을 끓일 때 넣는 물, 라면, 스프, 계란이 맛(결과)에 영향을 줌!
그러나 각 재료의 중요도는 다를 수 밖에 없음
스프에 중요도(가중치)를 높게 줄 수도 있고, 계란에 상대적으로 낮은 중요도(가중치)를 줄 수도 있다~
💡 편향(bias)
- 만일 입력값이 0일 때 가중치를 아무리 곱해도 결과는 0으로 나옵니다.
- 이걸 방지하기 위해 입력값이 0이어도 어떤 출력을 만들게끔 더해주는 값이 편향!
- 가중치과 편향이 적용된 계산 결과를 활성화 함수(activation function)를 통과시킴
- 이 과정이 없으면 복잡한 문제를 풀 수가 없어요
- 출력 값 계산
- 결과값이 나옵니다.
- 오차 계산 및 학습
- 예측 값과 정답의 차이를 계산 (오차) ⇒ 손실 함수
- 오차를 최소화하기 위해 가중치와 편향을 조정
- 이 과정을 여러 번 반복해서 학습함
활성화 함수
- 입력값을 비선형적으로 변환하여 신경망이 더 복잡한 패턴을 학습할 수 있도록 돕는 함수
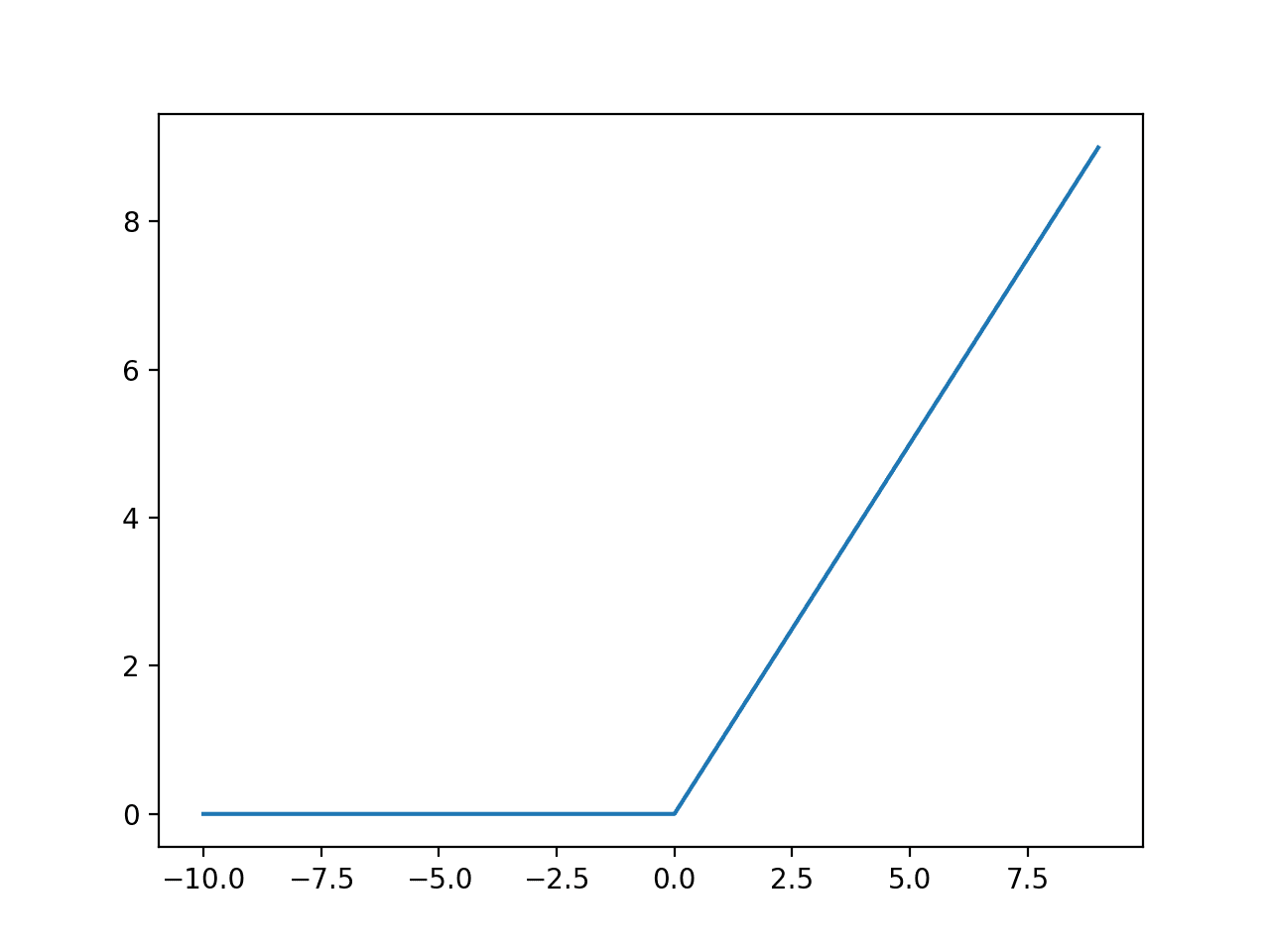
- ReLU:
f(x) = max(0, x)- 0과 x 사이의 max 값을 반환, 음수는 0으로 출력. 계산이 간단하다.
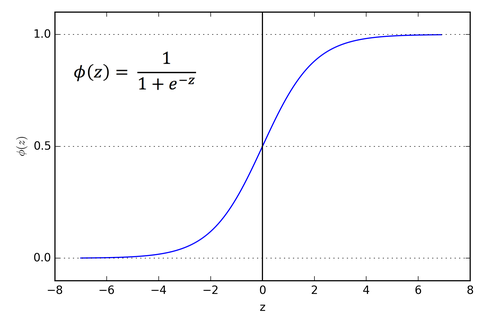
- Sigmoid:
f(x) = 1 / (1 + e^(-x))- 출력값을 0과 1 사이로 변환 ⇒ 확률 표현하기 적합
⚙️ 작동 과정
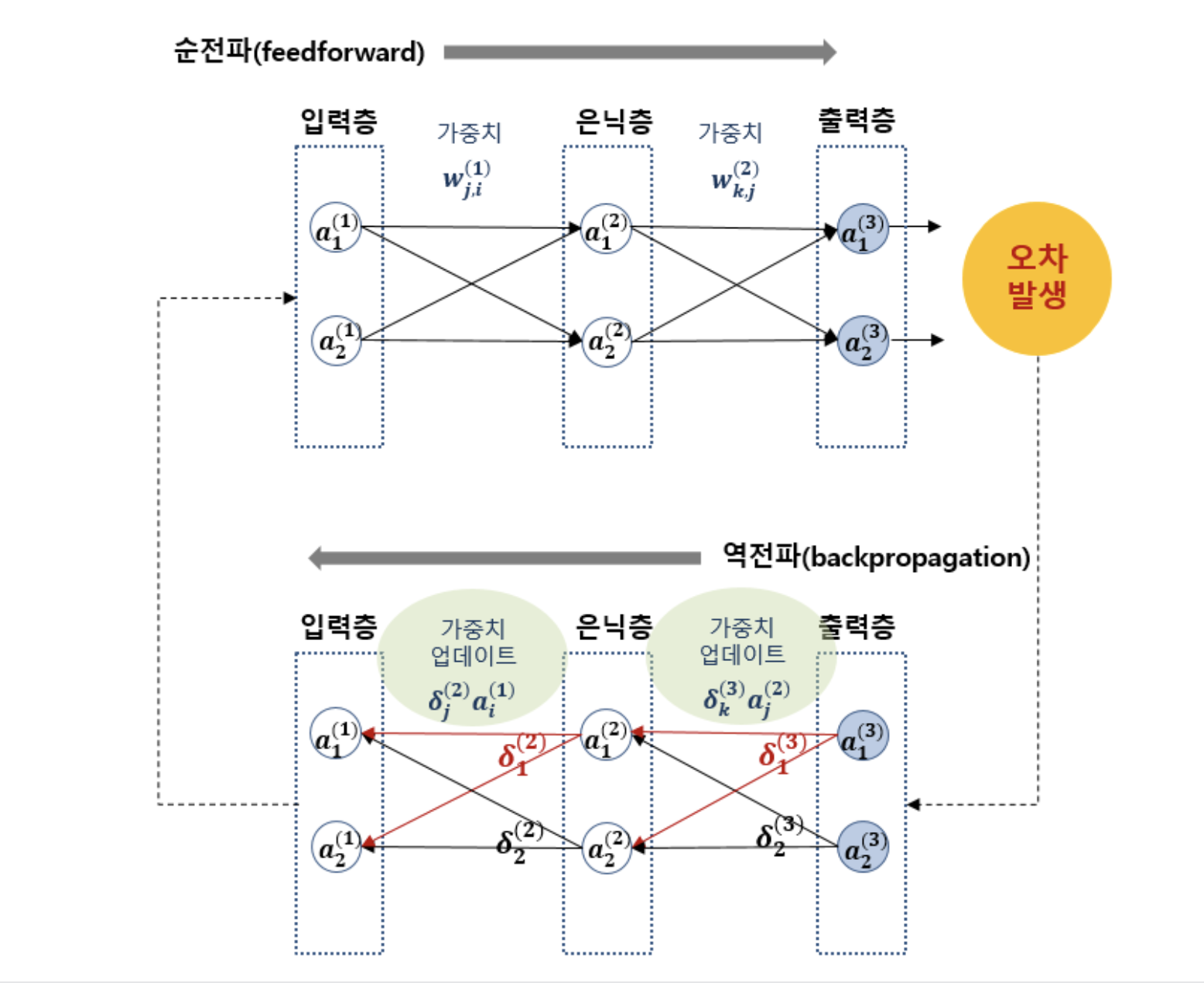
출처 : https://blog.kakaocdn.net/dn/Og5eJ/btsr0sPDvBx/9lmqMnuJJZWQqKxKNCqS3K/img.png
{kind=link}
- 입력 데이터 각 뉴런에 전달 (입력층)
- 숫자(벡터) 형태
[0.2, 0.5, 0.1]
- 숫자(벡터) 형태
- 각 뉴런은 가중치와 편향을 적용해서 활성화 함수로 보냄 (은닉층)
- 활성화 함수를 통해 출력값을 결정! (출력층)
- 예측 값과 실제 값(=기대값)의 차이를 계 (손실 계산)
- 적절한 선을 찾기 위해 가중치와 편향의 값을 조정 하여 다시 1번으로 돌아감 (반복 학습!)
1~3번까지 예측값을 얻어내는 과정 = “순전파”
5번의 오차를 줄이는 과정 = “역전파”
이렇게 딥러닝과 인공신경망의 동작 원리에 대해 정리해봤다.
이 외에도 딥러닝에 필요한 테크닉에 대해서도 배웠는데 이거는 직접 과제를 해결해보면서 정리해보겠다. 다음주에 따로 포스팅을 하든, 이 포스트에 수정해서 올리든 할 것 같음
지적 언제나 환영합니다^^
#항해99 #항해 플러스 AI 후기 #AI 개발자 #LLM
