단일 퍼셉트론(=선형 레이어)에서는 XOR 문제를 해결할 수 없음
- 단일 퍼셉트론 - 선형 분류(y = ax + b로 표시되는 선형(직선) 함수)
- ⇒ XOR(베타적 논리합) 같은 비선형(곡선) 문제 해결 X
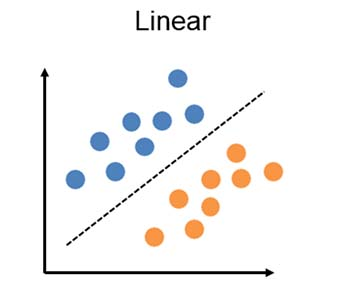
선형 함수. (선형적 = 직선 line)
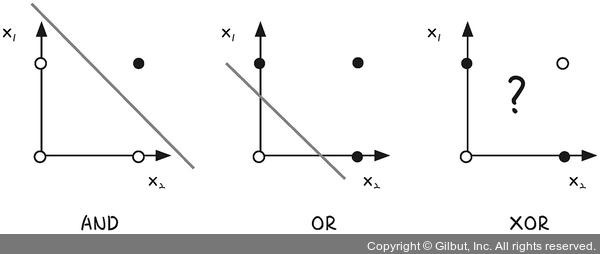
(직선 하나로 같은색끼리 분류를 할 수가 없다는 뜻) - XOR 문제는 두 입력이 다를 때만 True(1)을 출력하기 때문에, 단일 퍼셉트론으로는 해결X
- BUT 다중 퍼셉트론은 은닉층을 통해 비선형성을 학습할 수 있어서 XOR 문제를 해결할 수 있음
- 활성화 함수가 x → 신경망은 그저 단순 선형변환만 OK ⇒ 복잡한 패턴 학습X
- 비선형성을 도입해서 신경망이 복잡한 패턴을 학습할 수 있게 함
MLP 모델 구현
https://tutorials.pytorch.kr/beginner/basics/optimization_tutorial.html
- randomness seed 고정
import random
# randomness(무작위 생성)하는 값들을 seed로 통해 고정시킬 수 있음
seed = 7777
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False- 데이터 생성
x = torch.tensor([
[0., 0.],
[0., 1.],
[1., 0.],
[1., 1.]
])
y = torch.tensor([0, 1, 1, 0])
print(x.shape, y.shape)- x가 입력값, y가 비교해볼 정답값
- y의 shape는 1차원 벡터 torch.Size([4]) 1*4
- x의 shape는 2차원 벡터 4*2
- x의 특성의 개수(=행렬의 열 개수) → 2
- y의 특성의 개수(=행렬의 열 개수) → 1
- 모델 정의
from torch import nn
class Model(nn.Module):
def __init__(self, d, d_prime):
super().__init__()
self.layer1 = nn.Linear(d, d_prime) #입력 -> 은닉층
self.layer2 = nn.Linear(d_prime, 1) #y의 특성의 개수
self.act = nn.ReLU()
def forward(self, x):
# x: (n, d)
x = self.layer1(x) # (n, d_prime) 은닉층
x = self.act(x) # (n, d_prime) 활성화 함수 적용
x = self.layer2(x) # (n, 1)
return x
model = Model(2, 10) //model(x의 특성 개수, 은닉충의 노드 수)- 파이토치에서 nn.Module class를 상속받아서 구현함
- nn.module : abstract 클래스. 순전파 메서드 (def forward)를 구현하도록 abstract method를 제공함
- nn.Linear(입력 데이터의 특성 개수, 출력 데이터의 특성 개수) : 선형 함수
- nn.Relu : 활성화 함수의 하나인 Relu도 import해서 사용할 수 있음
- model(x의 특성 개수, 은닉충의 노드 수) 은닉층을 더 크게 잡으면 학습이 잘 됨(적당히 컴퓨팅 환경 성능 봐가면서)
순전파 설명
-
self.layer1(x) → 입력값을 은닉층의 크기에 맞게 변환해서 학습 가능한 데이터로 만드는 작업
입력값 (4,2)에 10차원 행렬곱 → (4, 10)
-
self.act(x) → ReLU : 양수면 그대로, 음수면 0 처리. 결과의 shape는 변하지 않음 (4,10)
-
self.layer2(x) → 예측 값을 만들기 위해 1차원 행렬곱해서 1차원으로 변환
-
최적화 함수(경사하강법) 설정
from torch.optim import SGD
optimizer = SGD(model.parameters(), lr=0.1)- 에폭마다 검증/테스트
- 학습
def train(n_epochs, model, optimizer, x, y):
for e in range(n_epochs):
model.zero_grad()
y_pred = model(x)
loss = (y_pred[:, 0] - y).pow(2).sum()
loss.backward()
optimizer.step()
print(f"Epoch {e:3d} | Loss: {loss}")
return model
n_epochs = 100
model = train(n_epochs, model, optimizer, x, y)- zero_grad() : 기울기 초기화
- loss.backward() : 로스에 대한 기울기 계산
- optimizer.stop : 기울기 계산한 것을 가지고 파라미터 업데이트
- 테스트
print(model(x))
print(y)
tensor([[0.0208],
[1.0484],
[1.0156],
[0.0496]], grad_fn=<AddmmBackward0>)
tensor([0, 1, 1, 0])- 예측 잘 됨

📚 배운 것을 정리하는 프론트엔드 개발자