드디어 마지막 수업!
마지막 수업은 양자화와 LoRa에 대해 배웠다.
성능 좋은 LLM 모델을 로드해서 학습시킬려면 하드웨어 쪽으로 천문학적인 비용이 드는데,
이를 경량화하는 기법들이 양자화와 LoRa이다.
양자화
LLM 모델의 파라미터들이 있는데 이는 보통 정수나 소수 값으로 이루어져있다.
그래서 이를 표현하기 위해 0과 1로 이루어진 비트 여러개를 사용하는데
개발 단계에서는 32bit으로 표현을 많이 한다.

양자화는 이런 비트 수를 줄여나가면서 메모리 사용량을 줄이는 방식이다.
16비트, 8비트, 4비트 표현으로 바꾸면 메모리 사용량이 절반 이하로 절약할 수 있다.
그러나 비트 수를 줄일수록 원래 값과 오차가 증가할 수 있어, 정확도와 하드웨어 간의 균형을 잘 맞추는 것이 중요해 보인다.

- Float16 (fp16): 32비트 대비 메모리 사용량 절반, 대부분의 GPU에서 지원
- BFloat16 (bf16): Float16과 동일한 16비트를 사용하지만, 지수부를 8비트로 유지해 더 넓은 동적 범위를 제공 (NVIDIA A100, Google TPU 등에서 지원)
- INT8 / INT4: 정수 표현으로 오차가 크지만, 매우 적은 메모리와 연산량으로 추론 속도 최적화에 유리
LoRa (Low-Rank Adaptation)
LoRA는 LLM의 파라미터 전체를 업데이트하는 대신, 특정 레이어의 가중치에 해당하는 행렬에 작은 행렬을 추가로 학습하는 방법이다.
행렬곱의 특징을 사용했는데, 특정 레이어에서 작은 행렬을 곱해서 계산해야할 파라미터 수를 확 줄이는 것이다.

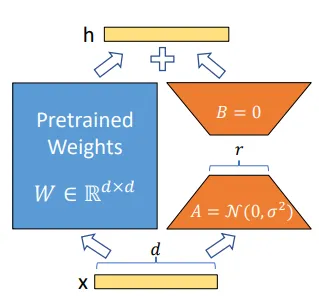
W : 원본의 가중치 (d * k)
output = W * x원래(왼쪽 파란색 사각형 이미지)는 큰 가중치 행렬 W에 입력인 X 행렬을 곱해서 학습하는 느낌이라면
output = (W + A*B) * x W : 미리 학습된 원본 가중치 (d×k)
A: d×r 행렬 (r ≪ d,k)
B : r * k 행렬
LoRa를 사용하면 쪼그만 행렬 A를 한번 곱해줘서 크기를 확 줄이고, 다시 B를 곱해서 파라미터를 원래 크기를 맞춰줘서 메모리와 학습 시간을 절약할 수 있다.
🎭 기본과제 - LoRA rank에 따른 학습 성능 비교해보기
학습 환경
Colab Enterprise
머신 유형: g2-standard-4
GPU 유형: NVIDIA_L4 x 1
지역: asia-northeast3
시스템 RAM : 15.6 GB
GPU RAM : 22.5 GB
모델
facebook/opt-350m
데이터셋
sahil2801/CodeAlpaca-20k
- 빠른 성능 비교를 위해 split 50%만 사용
- https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k
LoRa config
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=r_value,
lora_dropout=0.1,
lora_alpha=r_value * 4,
target_modules=["q_proj", "k_proj", "v_proj"]- r_value = [8, 128, 256]
- lora_alpha 값은 r * 4으로 랭크의 값과 비례하게 조정
- 타겟 모듈 : 어텐션 메커니즘의 q, k, v 레이어
train/loss
https://api.wandb.ai/links/soyeon-bubbles/y5q8y7ko
- 안정권으로 들어가는 시점
- r=256: 2회차 만에 1.5 이하로 진입 → 빠르게 안정권으로
- r=128: 3회차에 1.5 이하 → 중간
- r=8: 5회차가 돼야 겨우 1.75 정도 → 느림
- 학습 속도(Runtime)
- r=8 ⇒ 761.3346
- r=128 ⇒ 822.9918
- r=256 ⇒ 907.3956
- 최종 손실 값
- r=256: 1.33 (최저)
- r=128: 1.43 (r=256 대비 +0.10)
- r=8: 1.72 (r=128 대비 +0.29)
- 용량 대비 효과
- r 값 8→128로 키우면 손실 감소폭이 크지만, 128→256 구간은 효과가 점점 줄어든다. (=기울기 감소)
결론
- 성능 우선 ⇒ r=256이 가장 좋음. 빠른 안정화.
- 효율적인 선 ⇒ r=128
- 리소스가 한정적이고, 최소한의 학습만 ⇒ r=8 (그러나 손실이 크다)
GPU Memory Allocated
https://api.wandb.ai/links/soyeon-bubbles/lkaxivz4
| rank (r) | 평균 GPU Memory Allocated (%) |
|---|---|
| 256 | 약 20.6% |
| 128 | 약 19.9% |
| 8 | 약 18.8% |
- 차이가 1-2%p 정도로 미미함
Process Memory In Use (MB)
https://api.wandb.ai/links/soyeon-bubbles/0qfyanlj
| rank r | 평균 메모리 (MB) | 표준편차 (MB) | 최소 (MB) | 최대 (MB) |
|---|---|---|---|---|
| 8 | 1898 | 58.7 | 1874 | 2402 |
| 128 | 1917 | 17.4 | 1885 | 1932 |
| 256 | 1964 | 47.0 | 1879 | 2026 |
- 메모리 사용량 증가
- r 값이 커질수록 메모리 사용량도 증가함
- r=8 → 약 1898 MB, r=128 → 약 1917 MB (+19 MB), r=256 → 약 1964 MB (+66 MB) 정도 차이.
- 초기 스파이크 & 변동성
- r=8은 첫 측정 시 2400 MB까지 찍고 곧바로 1880 MB 선으로 내려감 → 모델 로딩, 캐시 구축 등에 따른 일시적인 현상으로 추정
- 이후 r=8은 크게 변하지 않고, r=128은 ±20 MB 내에서, r=256은 ±50 MB 내에서 비교적 주기적인 메모리 할당/해제가 반복됨
- 안정성 관점
- r=128 ⇒ 표준편차가 가장 작음
- r=8 ⇒ 일회성 스파이크를 제외하면 낮은 메모리를 사용함.
- r=256은 당연히 가장 많은 메모리 사용함. 큰 랭크 연산을 지속해야 하므로 메모리 풀링/해제가 반복되며 변동 폭은 중간
결론
- 메모리 절약이 최우선 ⇒ r=8
- 메모리 안정성이 중요 ⇒ r=128
- 성능 최우선 ⇒ r=256
GPU Time Spent Accessing Memory (%)
https://api.wandb.ai/links/soyeon-bubbles/grpmpy33
- 메모리 대역폭 의존도
- r=256 > r=128 > r=8 순으로 메모리 대역폭 의존도가 높아짐
- 안정성
- r=128이 가장 일관된 메모리 접근 패턴을 보임
- 병목 파악
- r=256 쪽 병목이 더 두드러짐
결론
- 연산/메모리 효율이 가장 안정적 → r=128
🦜프로젝트 근황 - Langsmith로 LLM 애플리케이션 평가하기
LangSmith로 LLM 애플리케이션 추적 평가 파이프라인 만들기
- Langsmith란?
랭체인에서 만든 LLM 애플리케이션 모니터링, 테스트 지원을 해주는 도구
여기서는 챗봇에 쓰인 LLM 체인을 추적하거나, 하나의 데이터셋에 대한 성능 비교를 할 때 쓰였다.
이렇게 체인이 한 번 invoke 되는 과정을 추적해줘서, 레이턴시, 토큰, 비용, 참조한 문서들을 알 수 있다.
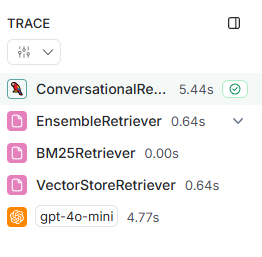
환경변수를 설정하고 chain을 생성하는 함수 위에 @traceable() 데코레이터를 쓰면 끝
@traceable(run_type="llm")
def get_conversation_chain(retriever, open_ai_key, model):
llm = ChatOpenAI(model=model, api_key=open_ai_key, temperature=0)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
chain_type="stuff",
retriever=retriever,
memory=ConversationBufferMemory(memory_key="chat_history", return_messages=True, output_key="answer"),
get_chat_history=lambda h: h,
return_source_documents=True,
verbose=True,
combine_docs_chain_kwargs={"prompt": PromptTemplate.from_template(template)}
)
return conversation_chainLangsmith + openevals로 LLM-as-Judge 쉽게 하기
https://github.com/langchain-ai/openevals
langchain에서 만든 LLM-as-Judge 라이브러리
- 평가에 필요한 프롬프트를 제공해주기 때문에 간편하고, langsmith의 평가 모듈과도 잘 맞음
- create_llm_as_judge -> 평가 클래스를 생성하고
- evaluator -> 인풋과 아웃풋을 연결 (인풋, 아웃풋은 langsmith의 evaluate 메서드를 쓰면 알아서 집어넣어줌)
- 이걸 langsmith의 evaluate()의 evaluators 리스트에 넣어주면 알아서 테스트 데이터셋의 input과 output, 그리고 내가 만든 llm chain의 답변을 비교해서 평가를 해준다.
def correctness_evaluator(inputs: dict, outputs: dict, reference_outputs: dict):
evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="openai:o3-mini",
feedback_key="correctness",
)
eval_result = evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
return eval_result
experiment_results = client.evaluate(
target,
data=dataset_name,
evaluators=[
correctness_evaluator
],
experiment_prefix=f"{model_id} + ensemble retriever + llm as judge",
max_concurrency=2,
)✨LLM 애플리케이션 성능 지표
| Experiment | Bleu | Correctness | Helpfulness | Meteor | Rouge | tokens | P50 Latency(s) |
|---|---|---|---|---|---|---|---|
| gpt-4.1-nano + multi-query | 0.15 | 0.40 | 0.60 | 0.37 | 0.19 | 55,628 | 9.497 |
| gpt-4o-mini + multi-query | 0.18 | 0.60 | 0.95 | 0.45 | 0.24 | 47,226 | 12.083 |
| gpt-4.1-nano + ensemble | 0.14 | 0.45 | 0.47 | 0.36 | 0.17 | 39,132 | 8.626 |
| gpt-4o-mini + ensemble | 0.15 | 0.60 | 0.85 | 0.42 | 0.21 | 37,905 | 9.956 |
| gpt-4.1-nano + dense | 0.15 | 0.45 | 0.85 | 0.37 | 0.19 | 30,864 | 7.939 |
| gpt-4o-mini + dense | 0.18 | 0.50 | 0.90 | 0.46 | 0.24 | 30,428 | 9.297 |
| gpt-4o | 0.12 | 0.20 | 0.80 | 0.31 | 0.16 | 7,239 | 6.076 |
| gpt-4.1-nano | 0.14 | 0.20 | 0.90 | 0.31 | 0.17 | 6,559 | 4.843 |
| gpt-4o-mini | 0.12 | 0.30 | 0.90 | 0.33 | 0.16 | 7,110 | 7.896 |
1위: gpt-4o-mini + multi-query retriever
- 모든 지표에서 고른 성장을 보여 평균 0.48로 압도적 1위.
- 특히 Helpfulness(0.95)와 Correctness(0.60)가 가장 높아 ‘정확하면서도 친절한’ 답변을 잘 뽑아냄.
2~3위: dense vs ensemble (gpt-4o-mini 계열)
- Dense retriever 조합(0.456)은 Bleu·Meteor·Rouge 모두 최상위권, Helpfulness(0.90)·Correctness(0.50)도 견고.
- Ensemble retriever 조합(0.446)은 Correctness(0.60)가 최고지만 Helpfulness(0.85)가 약간 낮아 2위와 근소한 차이.
4위: gpt-4.1-nano + dense retriever
- gpt-4o-mini 계열보단 평균이 낮지만, gpt-4.1-nano 중에서는 제일 균형 잡힌 조합(0.402).
중하위권 (5~7위): 기본 모델 vs gpt-4.1-nano + multi-query
- 기본 gpt-4o-mini(0.362)와 gpt-4.1-nano-59c63224(0.344)는 retrieval 전에도 Helpfulness가 0.90으로 높음.
- gpt-4.1-nano + multi-query(0.342)는 정확도 개선(0.40)에도 불구하고 Helpfulness 하락(0.60) 탓에 순위가 밀림.
꼴찌권: gpt-4o & gpt-4.1-nano + ensemble
- Avg 0.318로 타 모델 대비 낮은 편.
- 특히 ensemble 조합은 과도한 앙상블로 Helpfulness(0.47)가 크게 떨어져 전반적 성능이 저하됨.
결론:
- 최고 성능은 gpt-4o-mini + multi-query retriever
- 토큰 수 vs 속도 vs 품질 균형을 중시할 땐 gpt-4o-mini + dense retriever가 무난한 선택
- gpt-4.1-nano 계열은 dense 조합만 고려해 볼 만함.
마지막 수업을 마치며
드디어 이 지옥캠프가 끝이 났다...
글 쓴 날짜 기준 어제 수료식을 진행했었는데
다음 글에 수료식 및 항해 플러스 AI 코스 솔직 후기에 대해 작성해보겠다.
항해 플러스에서 현재 백엔드, 프론트엔드 코스 수강생을 모집 중입니다!
추천 코드를 입력하시면 등록금 20만원을 할인받을 수 있어요. (커리어 코칭 제외)
관심 있으신 분들은 아래 링크에서 확인해보세요
추천 코드: 9T8Rkv
https://hanghae99.spartacodingclub.kr/hhplus-hub
