[Pandas] 1-3
1.판다스 시작하기
2.판다스 데이터프레임과 시리즈
3.그래프 그리기
1. 판다스 시작하기
1-1.데이터 집합 불러오기
1.데이터 불러오기
- read_csv 메서드
쉼표(,)로 열이 구분되어 있는 데이터를 불러옴
열이 탭(tab)으로 구분되어 있을 경우 => sep속성값으로 '\t'지정
- 시리즈와 데이터프레임
시리즈=> 엑셀 시트의 열 1개 의미
데이터프레임 => 엑셀의 시트와 동일한 개념
- type메서드
- shape메서드 : 데이터의 행과 열의 크기에 대한 정보
- columns메서드: 열 이름 확인 가능
- dtypes 속성이나 info메서드 :데이터프레임 구성하는 값의 자료형
1-2. 데이터 추출하기
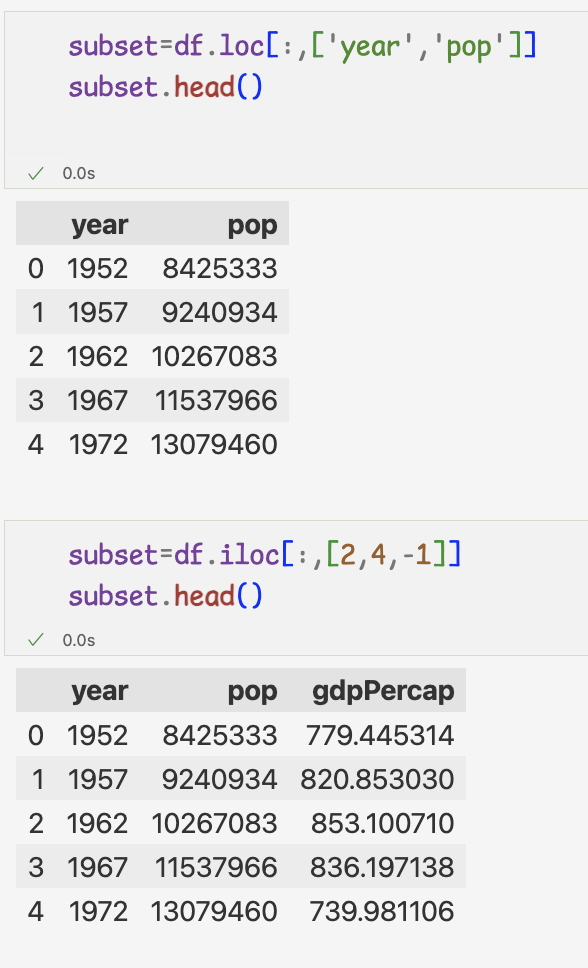
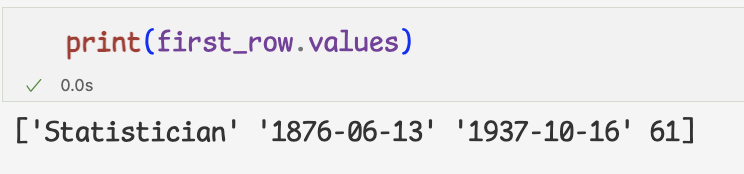
1.열 단위 데이터 추출하기
- 데이터프레임에서 데이터를 열 단위로 추출하려면 대괄호와 열 이름 사용
->열 이름은 꼭 작은따옴표로 지정
->1개의 열만 추출하면 시리즈,2개 이상의 열은 데이터프레임 얻음
2.행 단위 데이터 추출하기
- loc: 인덱스 기준으로 행 데이터 추출
- iloc: 행 번호를 기준으로 행 데이터 추출
✳️ 인덱스:변할수 있으며 숫자가 아니라 문자열을 사용할 수도 있다
✳️ 행 번호: 데이터의 순서를 따라가므로 정수만으로 데이터를 조회하거나,
추출할 수 있음. 실제 데이터프레임에서는 확인할 수 없는 값.
✳️ tail 메서드와 loc속성 반환하는 자료형 다름 => dataframe,series
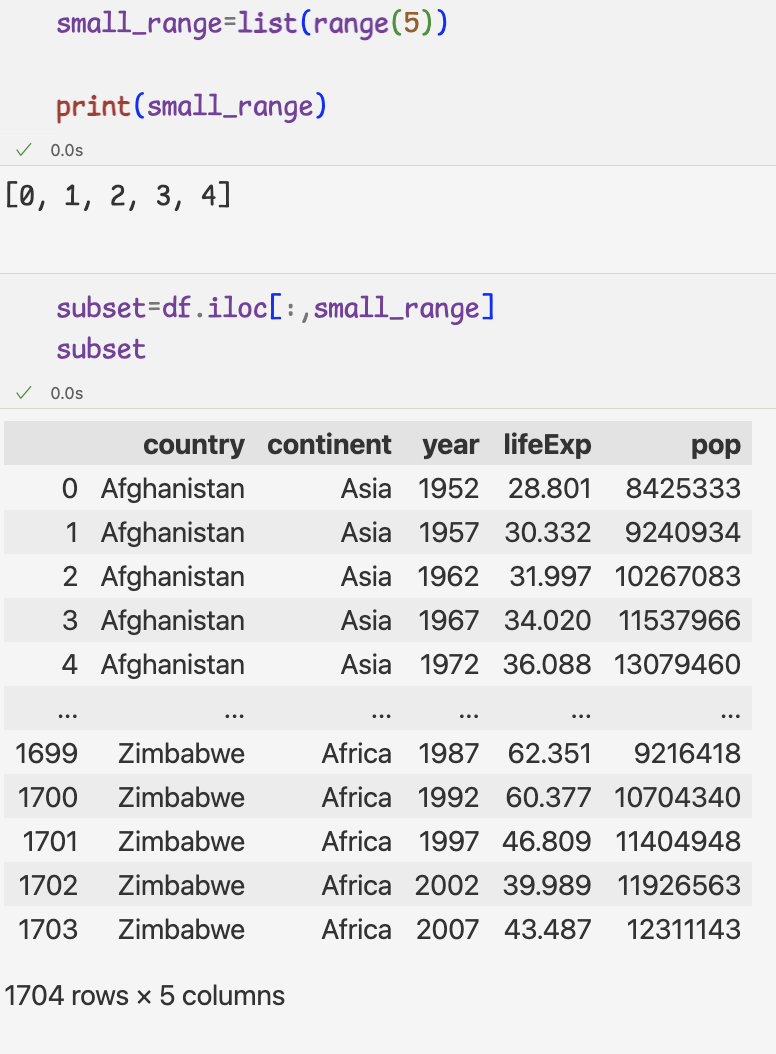
3.loc,iloc 속성 자유자재로 사용하기
행과 열을 지정하는 방법은 슬라이싱 과 range메서드를 사용하는 방법이 있다.
- 1) 슬라이싱 구문으로 데이터 추출하기
전달하는 열 지정값은 반드시 형식에 맞게 전달!!
-loc 속성 : 열 지정값에 정수 리스트 x
-iloc 속성: 열 지정값에 문자열 리스트 x
- 2) range 메서드로 데이터 추출하기
1-3.기초적인 통계 계산하기
1. 그룹화한 데이터의 평균 구하기
- lifeExp 열을 연도별로 그룹화하여 평균 계산하기
df.groupby('year')['lifeExp'].mean()
- lifeExp,gdpPercap 열의 평균값을 연도,지역별로 그룹화하여 계산
df.groupby(['year','continent'])[['lifeExp','gdpPercap']].mean()
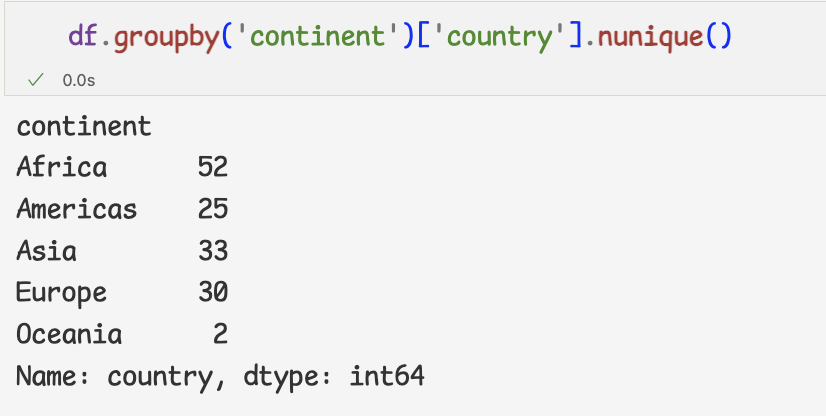
- 그룹화한 데이터 개수 세기
그룹화한 데이터의 개수 = 빈도수=>nunique메서드 사용
2.판다스 데이터프레임과 시리즈
2-1.나만의 데이터 만들기
1.시리즈와 데이터프레임 직접 만들기1) 시리즈 만들기
s=pd.Series(['banana',42])-시리즈를 생성할 때 문자열을 인덱스로 지정할 수 있다.
=>Series메서드의 index인자를 통해 전달2) 데이터프레임 만들기
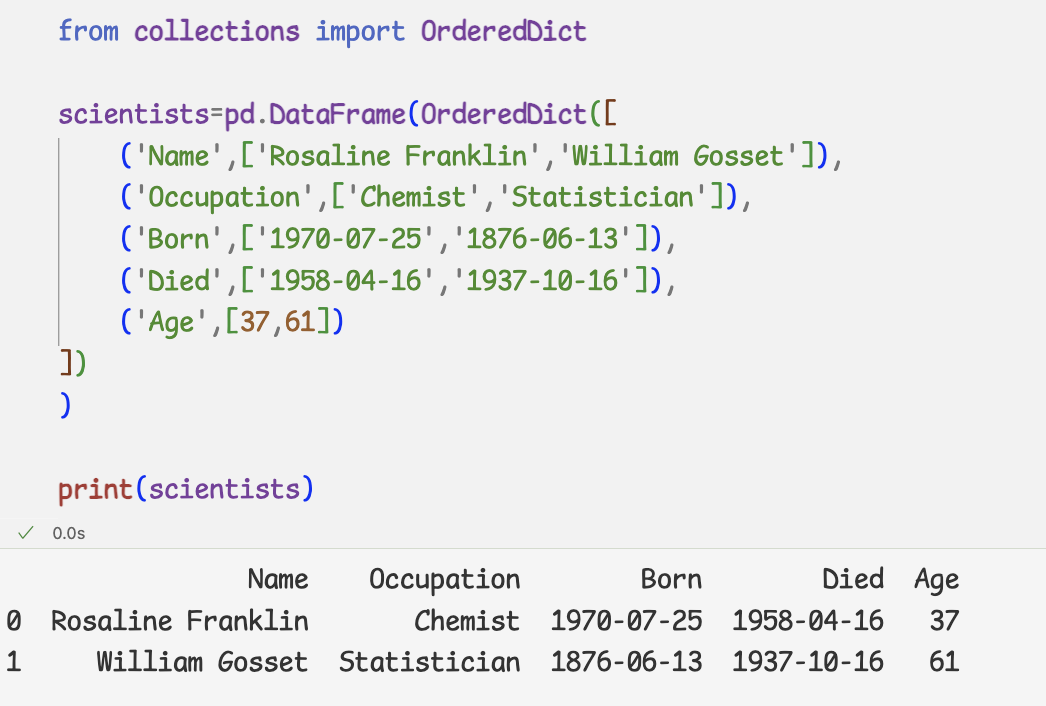
데이터프레임을 만들기 위해서는 딕셔너리를 Dataframe클래스에 전달
-시리즈와 같이 ,인덱스를 따로 지정하지 않으면 0부터 자동으로 생성
-따로 지정하려면, index 인자에 리스트 전달
-column 인자로 열 순서 지정-순서가 보장된 딕셔너리를 전달하려면, orderdDict클래스 사용
=>딕셔너리 데이터 순서 유지하며 데이터프레임 만들 수 있다
2-2.시리즈 다루기 -기초
판다스의 데이터를 구성하는 가장 기본단위는 시리즈
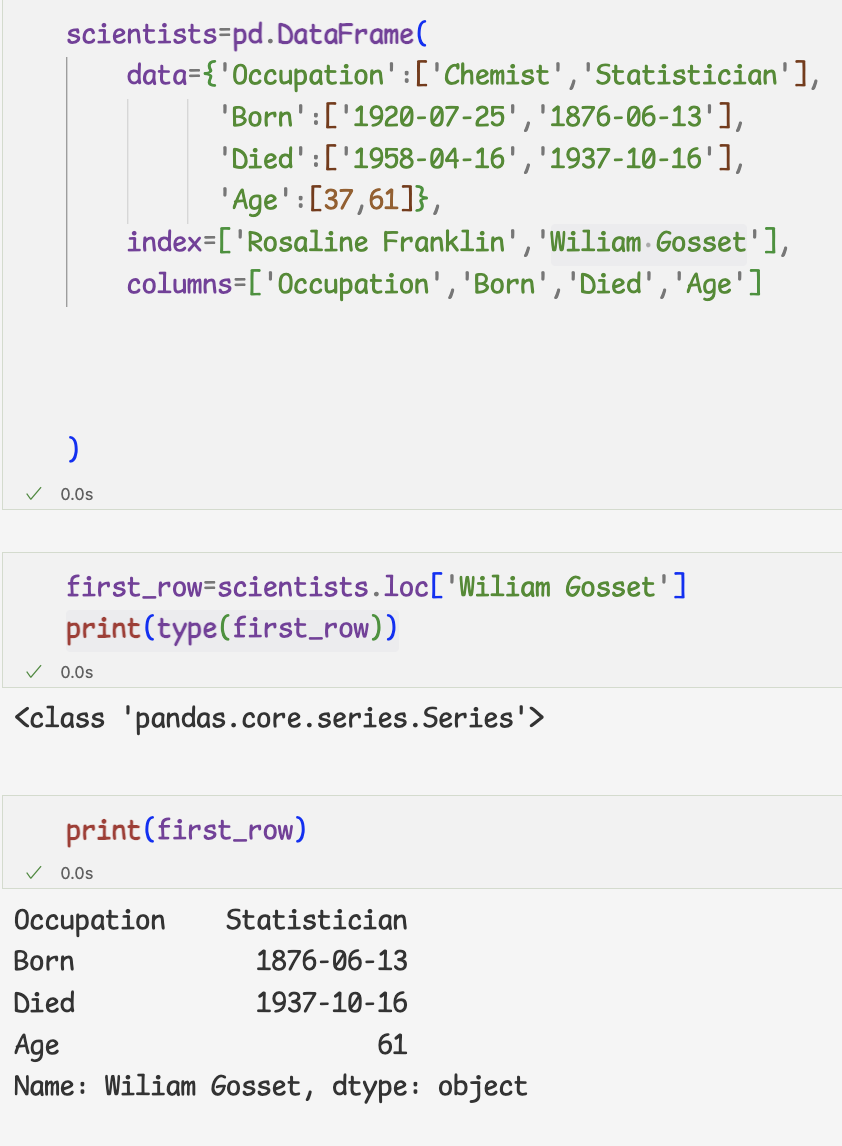
1.데이터프레임에서 시리즈 선택하기
- loc속성에 인덱스를 전달
2.시리즈 속성과 메서드 사용하기 -index,values,keys1) index 속성 사용하기
index속성에는 시리즈의 인덱스가 들어 있다.
2)value속성 사용하기
시리즈의 데이터가 저장되어 있다.
3) keys 메서드 사용하기
keys메서드는 index 속성과 같은 역할을 함
3.시리즈의 기초 통계 메서드 사용하기
- append: 2개 이상의 시리즈 연결
- describe: 요약 통계량 계산
- drop_duplicates: 중복값이 없는 시리즈 반환
- equals: 시리즈에 해당 값을 가진 요소가 있는지 확인
- get_values: 시리즈 값 구하기 (values 속성과 동일)
- isin: 시리즈에 포함된 값이 있는지 확인
- min: 최솟값 반환
- max:최댓값 반환
- mean: 산술 평균 반환
- median: 중간값 반환
- replace : 특정 값을 가진 시리즈 값을 교체
- sample : 시리즈에서 임의의 값 반환
- sort_values: 값을 정렬
- to_frame: 시리즈를 데이터프레임으로 변환
2-3. 시리즈 다루기 - 응용
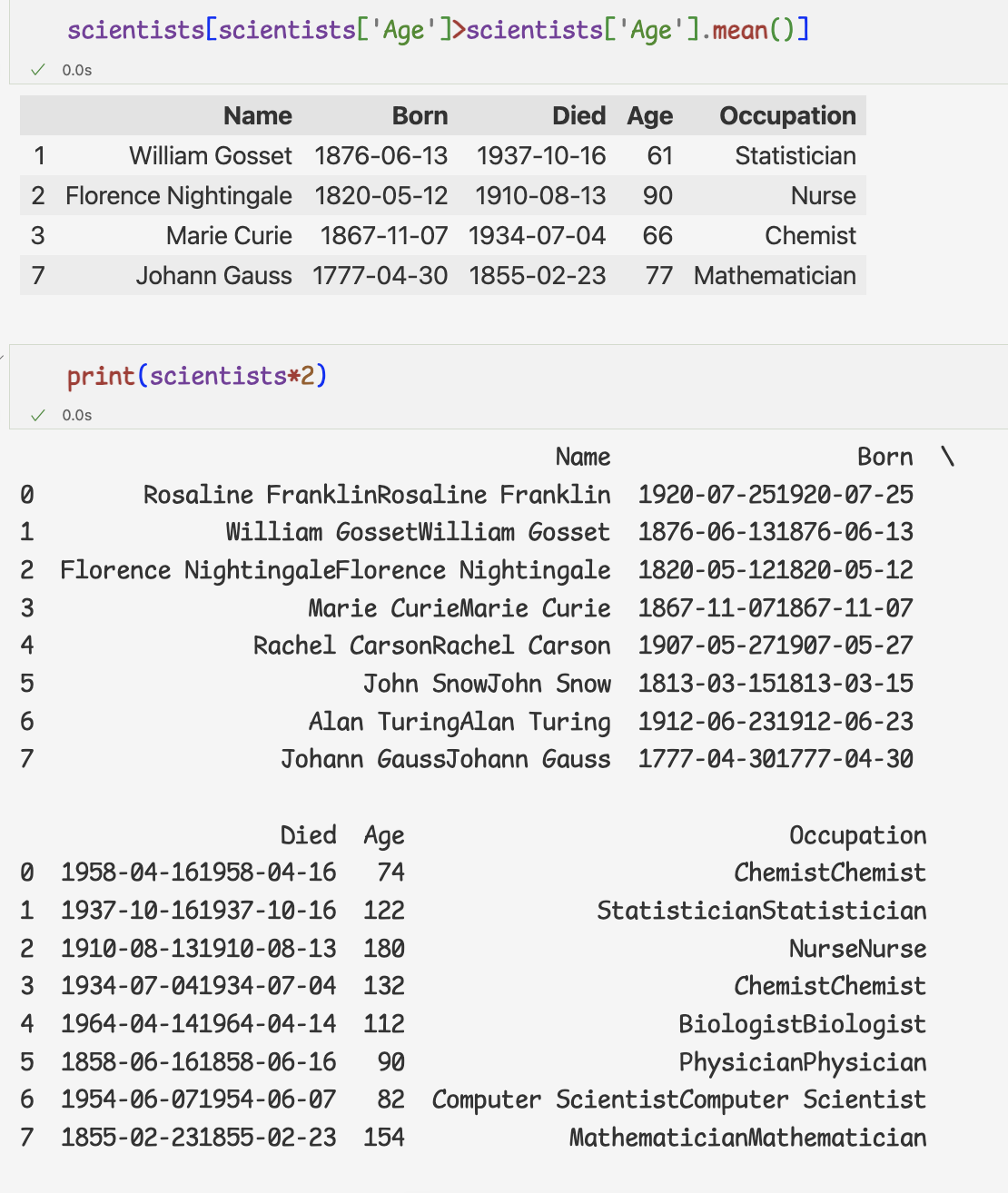
1.시리즈와 불린 추출
정확한 인덱스를 모르는 경우 사용하는 방법이 불린
불린 추출: 특정 조건을 만족하는 값만 추출할 수 있다.
- 시리즈와 불린 추출 사용하기
-리스트 형태로 시리즈에 전달하면 참인 인덱스만 추출
-ex)평균 나이보다 나이가 많은 사람의 데이터 추출ages[ages>ages.mean()]
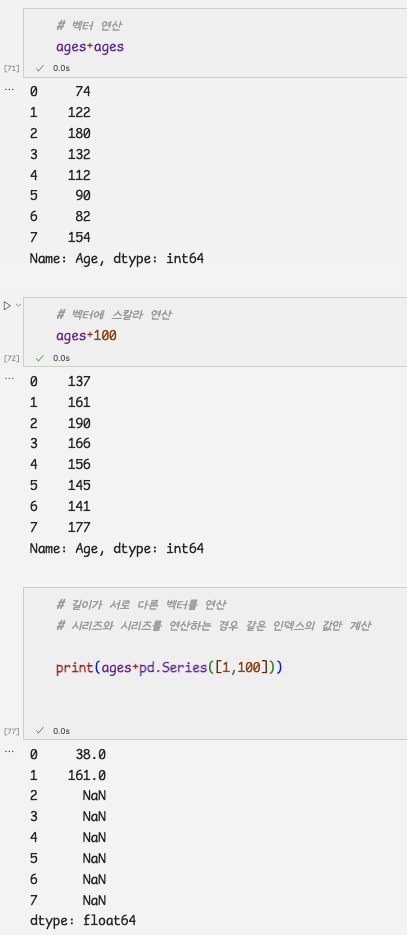
2.시리즈와 브로드캐스팅
- 브로드캐스팅: 시리즈,데이터프레임에 있는 모든 데이터를 한번에 연산
- 벡터: 시리즈처럼 여러 개의 값을 가진 데이터
- 스칼라: 단순 크기를 나타내는 데이터
- 벡터와 스칼라로 브로드캐스팅 수행하기
=>결괏값으로 같은 길이의 벡터가 출력됨
2-4. 데이터프레임 다루기
1.불린 추출과 브로드캐스팅
2-5. 시리즈와 데이터프레임의 데이터 처리하기
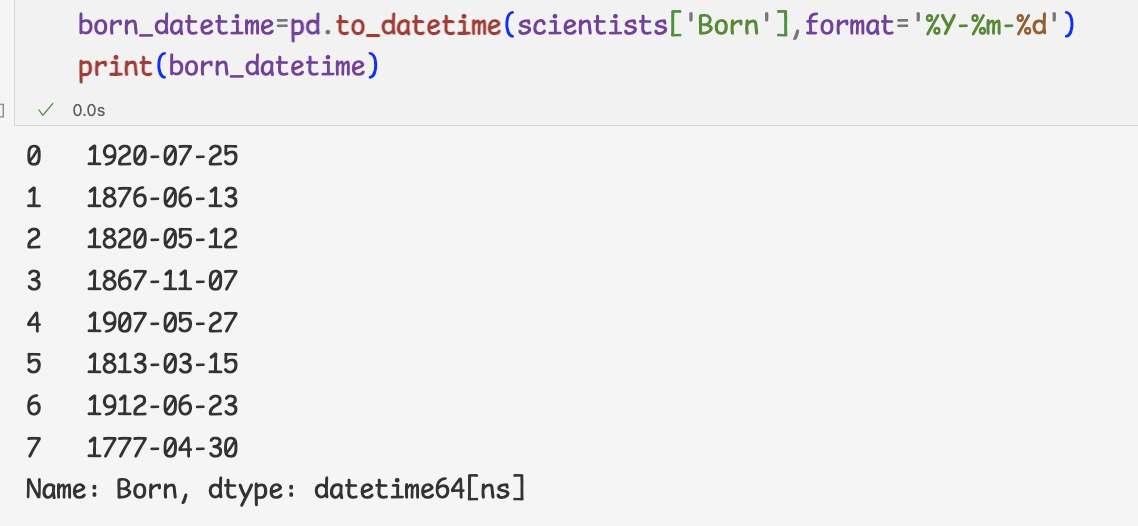
1.시리즈와 데이터프레임의 데이터 처리하기1.열의 자료형 바꾸기와 새로운 열 추가하기
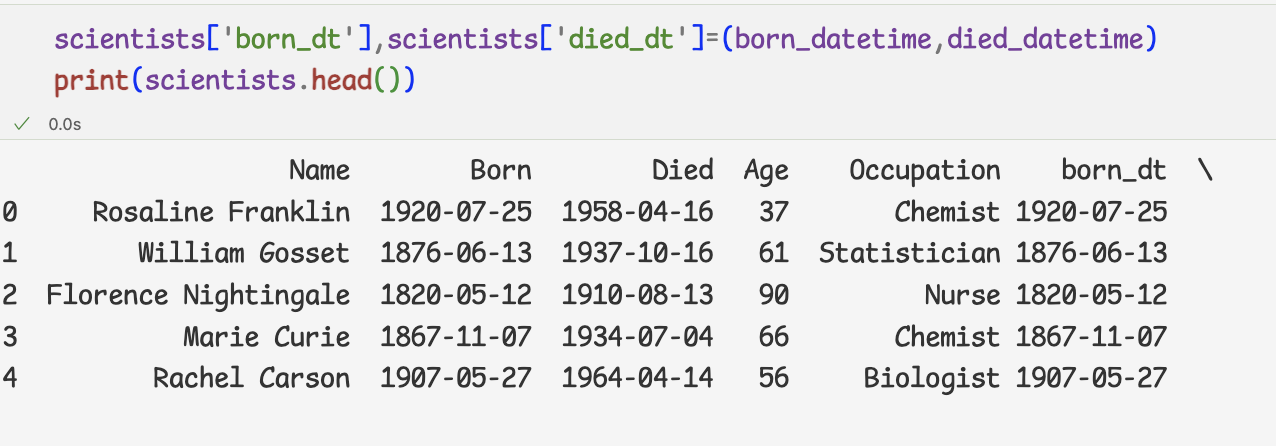
- 문자열 -> datetime자료형으로 바꾸기
- 열 추가
- 데이터프레임의 열 삭제하기
2-6. 데이터 저장하고 불러오기
1.피클로 저장하기
-데이터를 바이너리 형태로 직렬화한 오브젝트를 저장하는 방법
-피클로 저장하면 스프레드시트보다 더 작은 용량으로 저장 가능
-피클로 저장하려면 to_pickle메서드 사용
=>이때 저장 경로를 문자열로 전달해야 함
-피클 데이터는 반드시 read_pickle메서드로 읽어야함names.to_pickle("../data/scientists_names_series.pickle")
- CSV파일과 TSV 파일로 저장하기
-CSV파일: 데이터를 쉼표로 구분하여 저장한 파일
-TSV:데이터를 탭으로 구분하여 저장한 파일# CSV 파일 names.to_csv("../output/scientist_names_series.csv") # TSV 파일 scientists.to_csv("../output/scientist_df.tsv",sep='\t')



3.그래프 그리기
3-1 matplotlib 그래프 그리기
1.전체 그래프가 위치할 기본 틀을 만든다.
2.그래프를 그려 넣을 그래프 격자를 만든다.
3.격자에 그래프를 하나씩 추가한다. 순서는 왼쪽에서 오른쪽방향
4.만약 격자의 첫 번째 행이 꽉 차면 두 번째 행에 그래프를 그려 넣는다.
1.한번에 4개의 그래프 그리기# 그래프 격자가 위치할 기본 틀 fig=plt.figure() # add_subplot 메서드로 그래프 격자를 그린다. # 첫번째 인자에는 행 크기,두번째 인자에는 열 크기 지정 axes1=fig.add_subplot(2,2,1) axes2=fig.add_subplot(2,2,2) axes3=fig.add_subplot(2,2,3) axes4=fig.add_subplot(2,2,4) # plot 메서드에 데이터를 전달하여 그래프를 그리면 된다. axes1.plot(dataset_1['x'],dataset_1['y'],'o') axes2.plot(dataset_2['x'],dataset_2['y'],'o') axes3.plot(dataset_3['x'],dataset_3['y'],'o') axes4.plot(dataset_4['x'],dataset_4['y'],'o') fig # 격자에 제목 추가 => set_title 메서드 axes1.set_title('dataset_1') axes2.set_title('dataset_2) axes3.set_title('dataset_3) axes4.set_title('dataset_4) # 기본 틀(fig)에 제목 추가 => suptitle메서드 사용 fig.suptitle('Anscombe Data') # 각 그래프의 이름과 숫자 겹쳐 보이는경우=>tight_layout메서드로 레이아웃 조절 fig.tight_layout()
3-2.matplotlib 라이브러리 자유자재로 사용하기
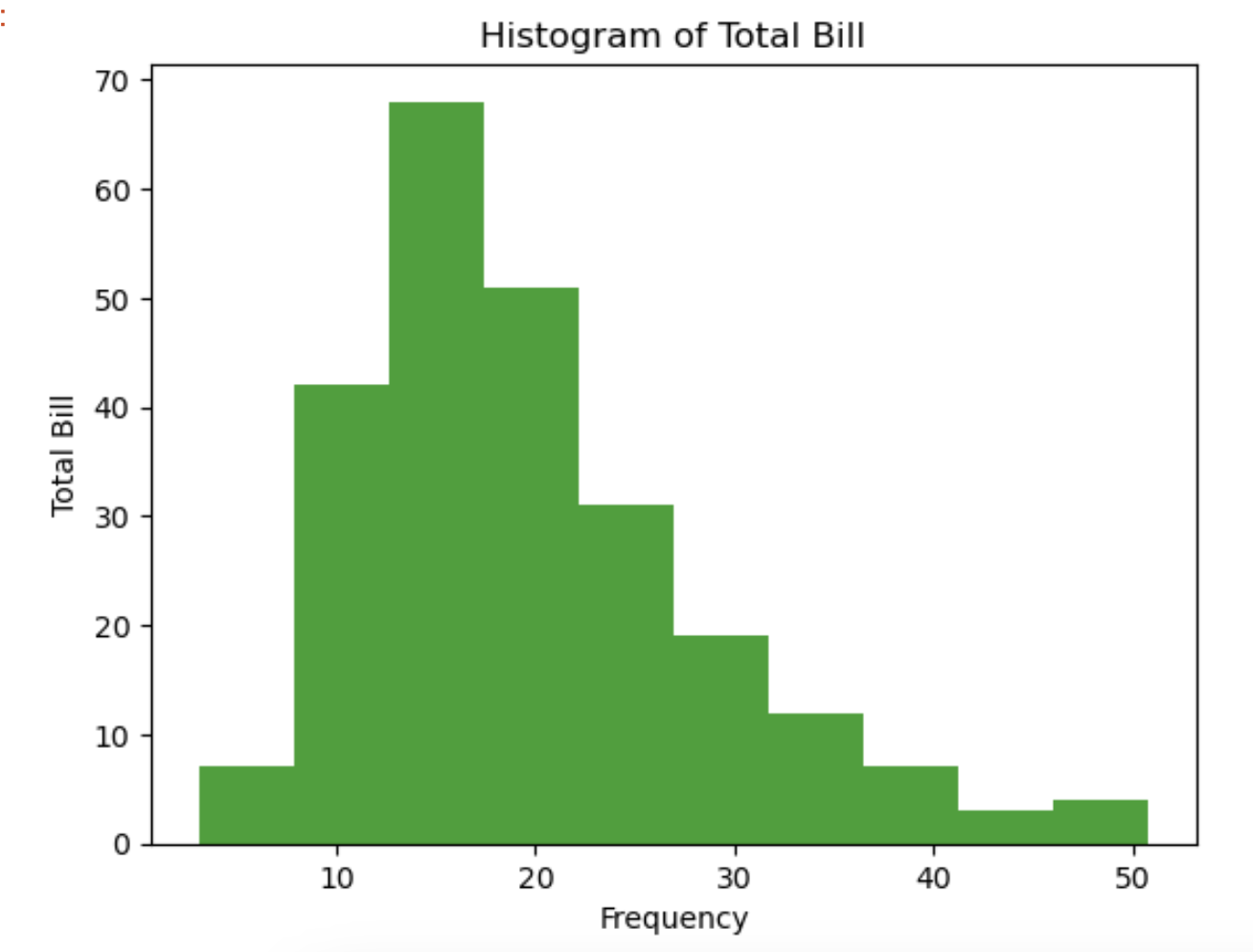
기초 그래프 그리기-히스토그램,산점도 그래프,박스 그래프1.히스토그램
데이터프레임의 열 데이터 분포와 빈도를 살펴보는 용도fig=plt.figure() axes1=fig.add_subplot(1,1,1 axes1.hist(tips['total_bill'],bins=10) # bin: x축 간격 조정 axes1.set_title('Histogram of Total Bill') axes1.set_xlabel('Frequency') axes1.set_ylabel('Total Bill') fig
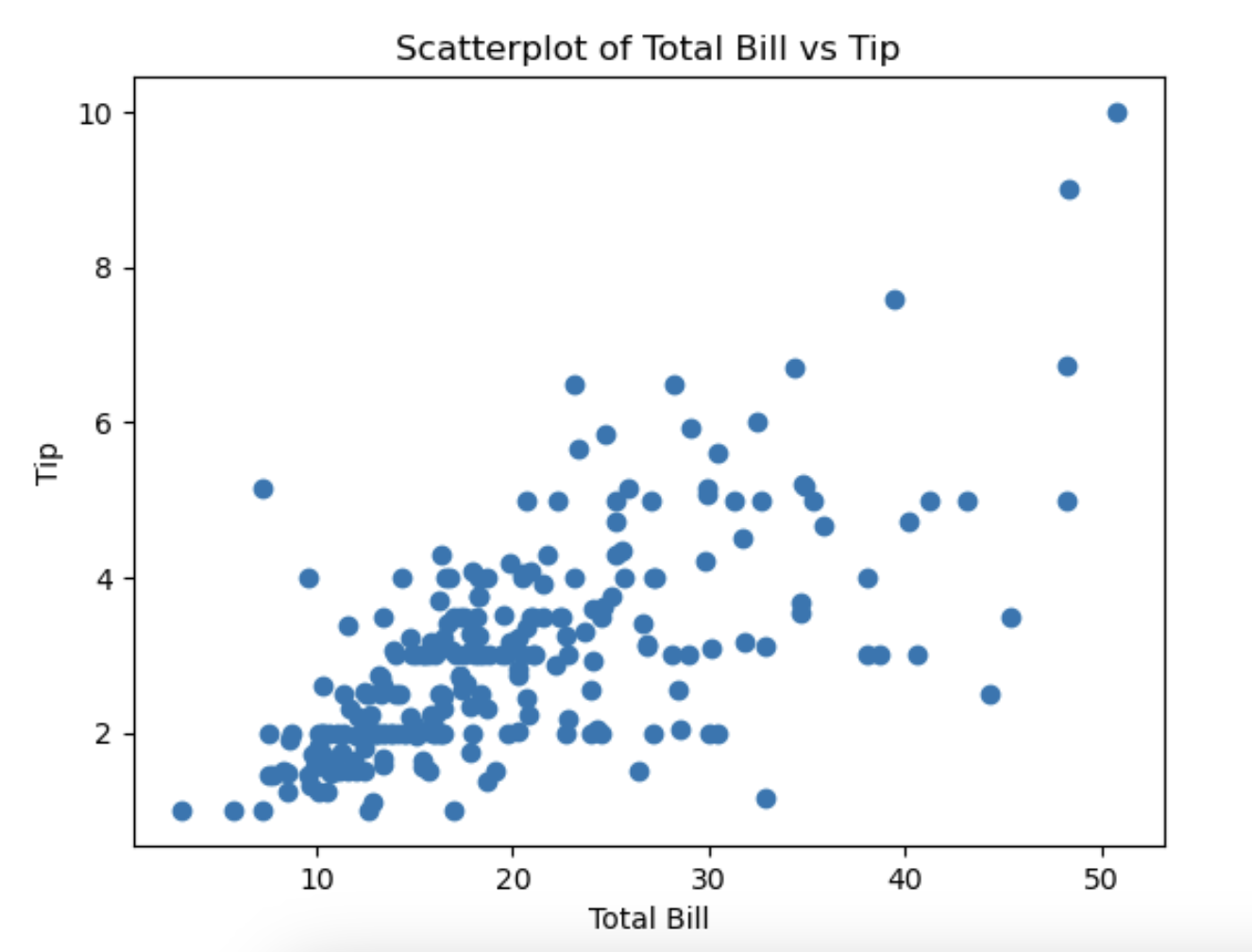
2.산점도 그래프
변수 2개를 사용해서 만드는 그래프,이변량 그래프scatter_plot=plt.figure() axes1=scatter_plot.add_subplot(1,1,1) axes1.scatter(tips['total_bill'],tips['tip']) axes1.set_title('Scatterplot of Total Bill vs Tip') axes1.set_xlabel('Total Bill') axes1.set_ylabel('Tip')
3.박스 그래프
이산형 변수와 연속형 변수를 함께 사용하는 그래프boxplot=plt.figure() axes1=boxplot.add_subplot(1,1,1) axes1.boxplot([tips[tips['sex']=='Female']['tip'], tips[tips['sex']=='Male']['tip']], labels=['Female','Male']) axes1.set_xlabel('Sex') axes1.set_ylabel('Tip') axes1.set_title('Boxplot of Tips by Sex')
다변량 그래프 그리기
3개 이상의 변수를 사용하는 다변량 그래프는
적재적소에 맞는 그래프 요소 (크기,색상,투명도 조정) 추가1.산점도 그래프
scatter_plot=plt.figure() axes1=scatter_plot.add_subplot(1,1,1) axes1.scatter( x=tips['total_bill'], y=tips['tip'], s=tips['size']*10, # s는 점의 크기 c=tips['sex_color'], # c는 점의 색상 alpha=0.5) # alpha 인잣값은 투명도를 조절 axes1.set_title('Total Bill vs Tip Colored by Sex and Sized by Size') axes1.set_xlabel('Total Bill') axes1.set_ylabel('Tip')
3-3. seaborn 라이브러리 자유자재로 사용하기
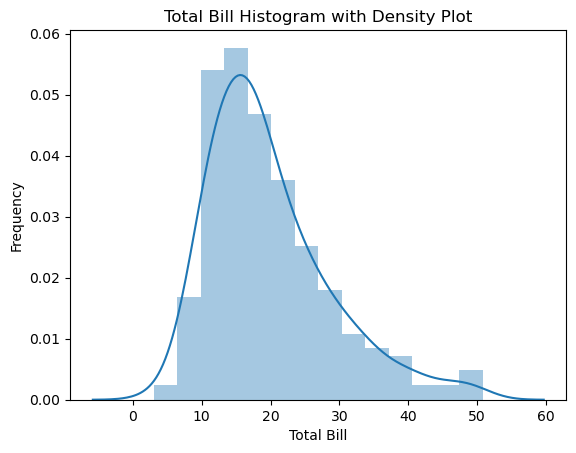
단변량 그래프 그리기 - 히스토그램
-subplots메서드로 기본 틀 만들고->distplot 메서드에서 total_bill열 데이터 전달하면 seaborn 라이브러리로 히스토그램 그릴 수 있다.ax=plt.subplots() ax=sns.distplot(tips['total_bill'],kde=False) ax.set_title('Total Bill Histogram with Density Plot') ax.set_xlabel('Total Bill') ax.set_ylabel('Frequency')
=> 밀집도 그래프를 제외하고 싶다면, kde=False로 설정한다.
=> 밀집도 그래프만 나타내려면 hist=False로 설정
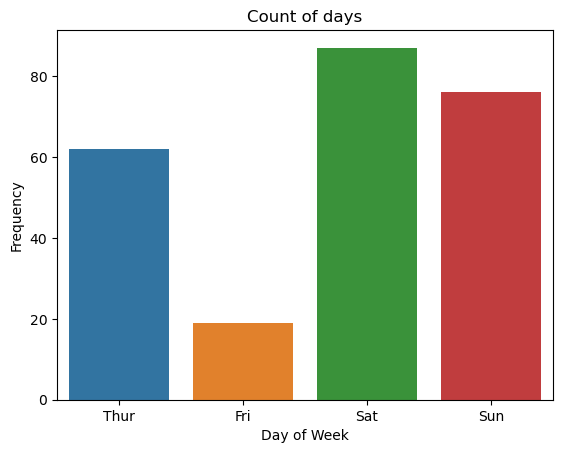
count 그래프
이산값을 나타낸 그래프.ax=plt.subplots() ax=sns.countplot(x='day',data=tips) ax.set_title('Count of days') ax.set_xlabel('Day of Week') ax.set_ylabel('Frequency')
다양한 종류의 이변량 그래프 그리기1.seaborn 라이브러리로 산점도 그래프 그리기
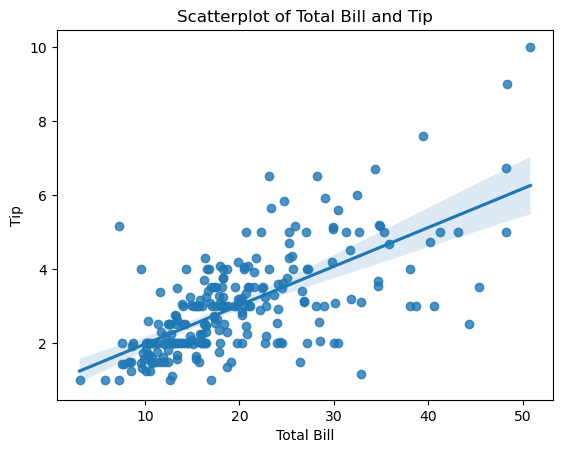
-seaborn 라이브러리의 regplot메서드를 사용해야 함
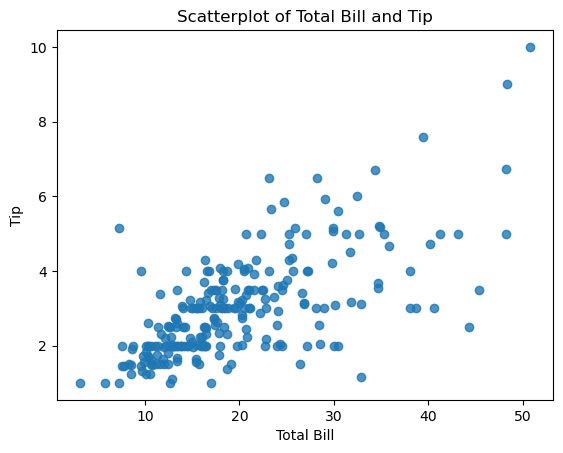
(산점도 그래프와 회귀선을 함께 그릴 수 있다,회귀선 제거는 fit_reg=False)ax=plt.subplots() ax=sns.regplot(x='total_bill',y='tip',data=tips) ax.set_title('Scatterplot of Total Bill and Tip') ax.set_xlabel('Total Bill') ax.set_ylabel('Tip') # 회귀선 제거 ax=plt.subplots() ax=sns.regplot(x='total_bill',y='tip',data=tips,fit_reg=False) ax.set_title('Scatterplot of Total Bill and Tip') ax.set_xlabel('Total Bill') ax.set_ylabel('Tip')
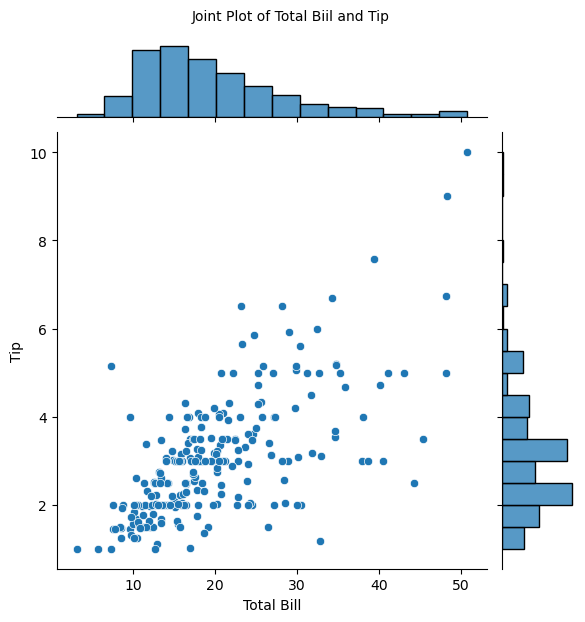
- jointplot (산점도 그래프와 히스토그램을 한번에 그려줌)
(x,y인자에 원하는 열 이름 지정, data 인잣값은 데이터프레임)joint=sns.jointplot(x='total_bill',y='tip',data=tips) joint.set_axis_labels(xlabel='Total Bill',ylabel='Tip') joint.fig.suptitle('Joint Plot of Total Biil and Tip',fontsize=10,y=1.03)
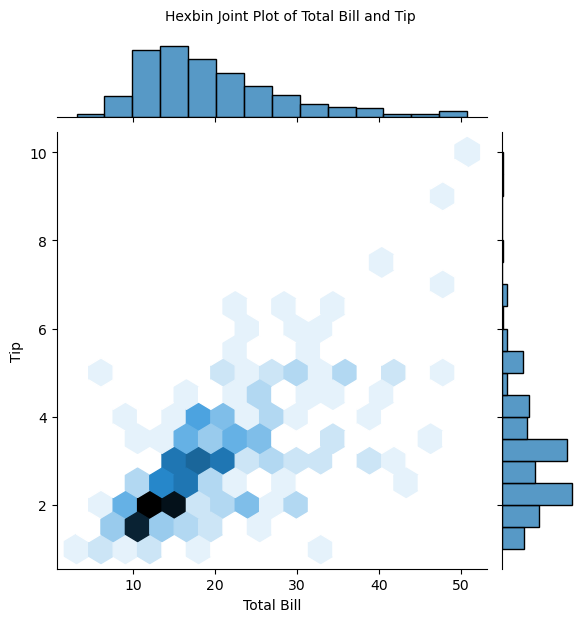
- 산점도 그래프의 데이터를 구분하기 쉽게 그리고 싶다면 육각 그래프 사용
(특정 데이터의 개수가 많아지면 점점 진한 색으로 표현된다.)
joinplot 메서드를 그래도 사용하며,kind인잣값을 hex로 지정함hexbin=sns.jointplot(x='total_bill',y='tip',data=tips,kind='hex') hexbin.set_axis_labels(xlabel='Total Bill',ylabel='Tip') hexbin.fig.suptitle('Hexbin Joint Plot of Total Bill and Tip',fontsize=10,y=1.03)
- 이차원 밀집도 그리기 (kdeplot)
(shade 인잣값을 True로 지정하면 음영 효과 줄 수 있다.)ax=plt.subplots() ax=sns.kdeplot(data=tips['total_bill'],data2=tips['tip'],shade=True) ax.set_title('Kernel Density Plot of Total Bill and Tip') ax.set_xlabel('Total Bill') ax.set_ylabel('Tip')5.바 그래프 그리기
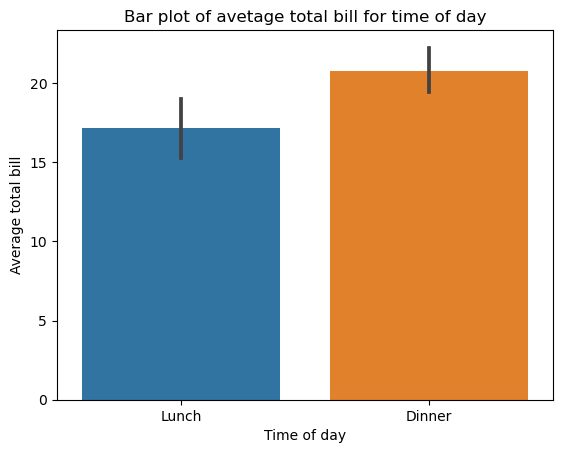
ax=plt.subplots() ax=sns.barplot(x='time',y='total_bill',data=tips) ax.set_title('Bar plot of avetage total bill for time of day') ax.set_xlabel('Time of day') ax.set_ylabel('Average total bill')
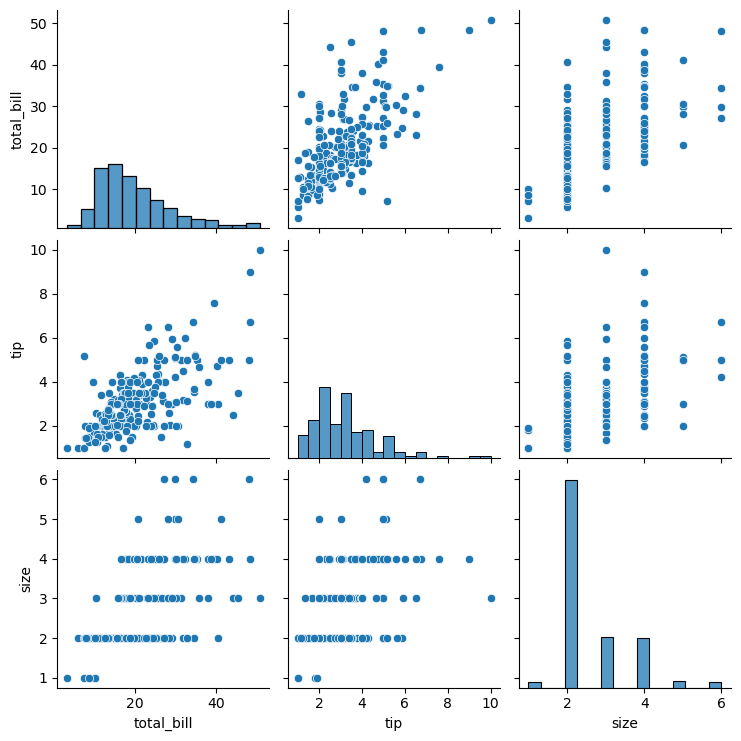
- 관계 그래프 그리기
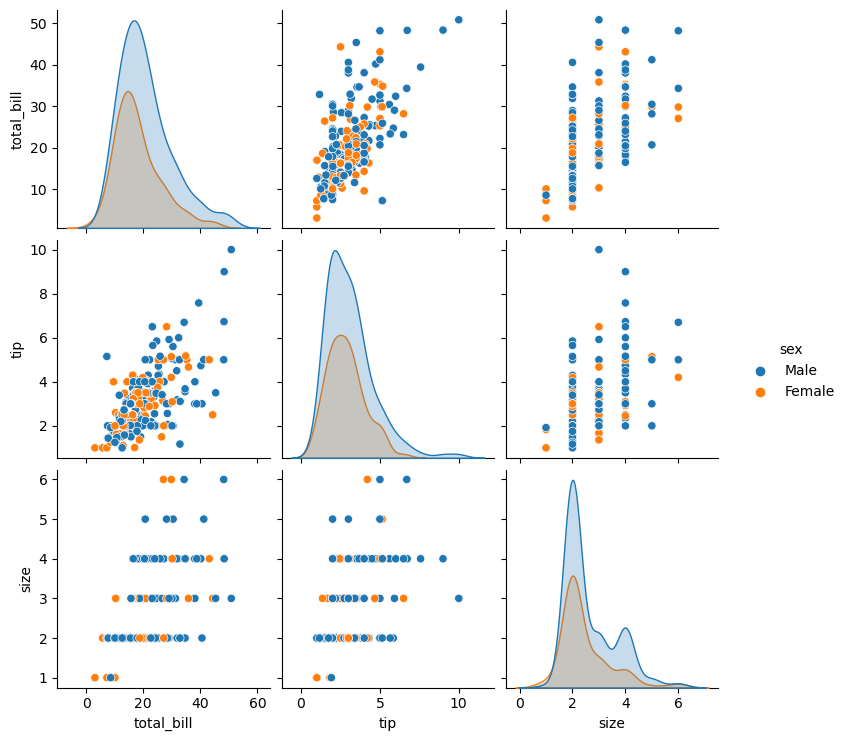
관계 그래프는 pairplot 메서드에 데이터프레임을 넣는 방법fig=sns.pairplot(tips)
다변량 그래프 그리기-seaborn
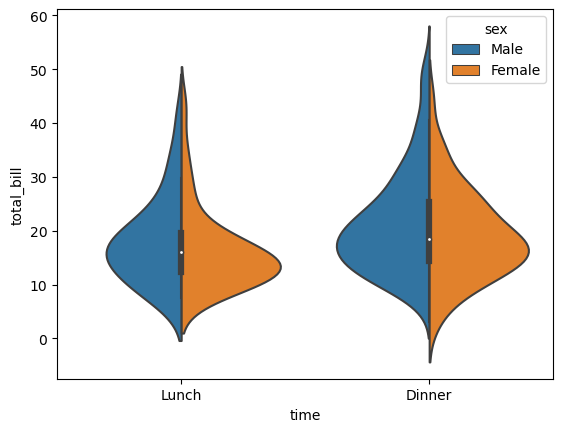
- seaborn 라이브러리로 바이올린 그래프 그리기 -색상 추가
-hue로 열이름 추가하면 색상 추가ax=plt.subplots() ax=sns.violinplot(x='time',y='total_bill',hue='sex',data=tips,split=True)
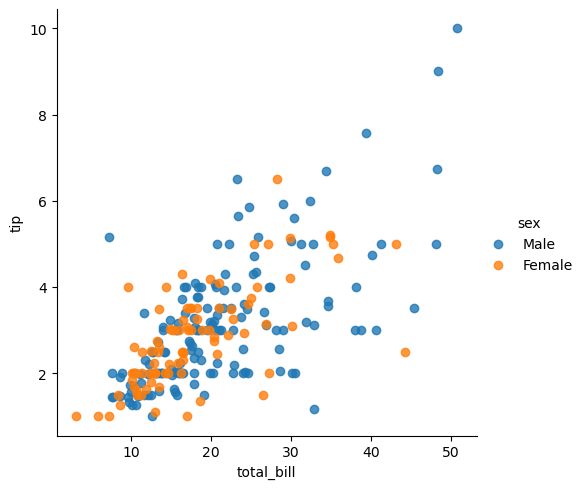
- 산점도, 관계 그래프 그리기- 색상 추가
scateer=sns.lmplot(x='total_bill',y='tip',data=tips,hue='sex',fit_reg=False) fig=sns.pairplot(tips,hue='sex')
3.산점도 그래프의 크기와 모양 조절하기
점 크기 조절: scatter_kws에 딕셔너리 형태로 인잣값 전달
크기 조절시, 's':tips['size'] 전달
4.산점도 그래프의 점을 다른 기호로 표현하고 싶다면
mrkers 인잣값에 표현하고자 하는 기호를 리스트에 담아 전달
markers=['o','x']
3-4. 데이터프레임과 시리즈로 그래프 그리기
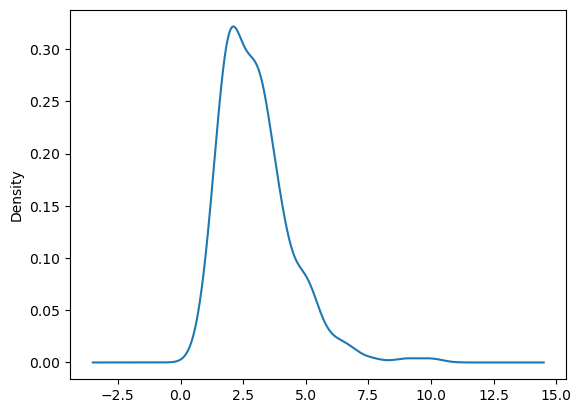
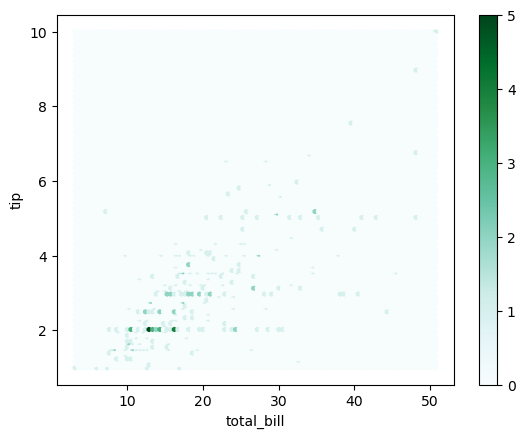
데이터프레임과 시리즈로 그래프 그리기# 밀집도 그래프 kde ax=plt.subplots() ax=tips['tip'].plot.kde() # 산점도 그래프 scatter fig,ax=plt.subplots() ax=tips.plot.scatter(x='total_bill',y='tip',ax=ax) # 육각 그래프 hexbin fig,ax=plt.subplots() ax=tips.plot.hexbin(x='total_bill',y='tip',ax=ax)