[Pandas] 4-6
1.데이터 연결하기
2.누락값 처리하기
3.깔끔한 데이터
1.데이터 연결하기
1-1.분석하기 좋은 데이터
깔끔한 데이터의 조건
- 데이터 분석 목적에 맞는 데이터를 모아 새로운 table을 만들어야 함
- 측정한 값은 행 (row)로 구성
- 변수는 열(column)로 구성
1-2. 데이터 연결 기초
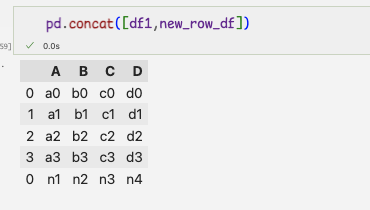
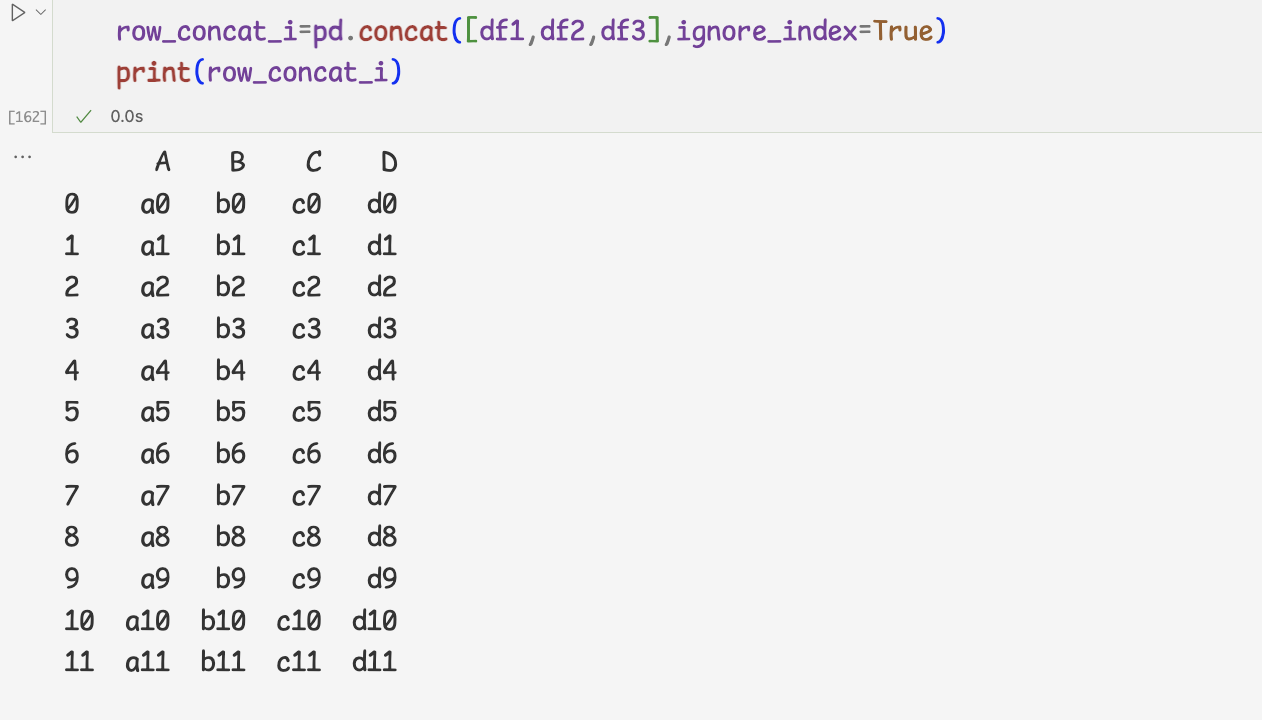
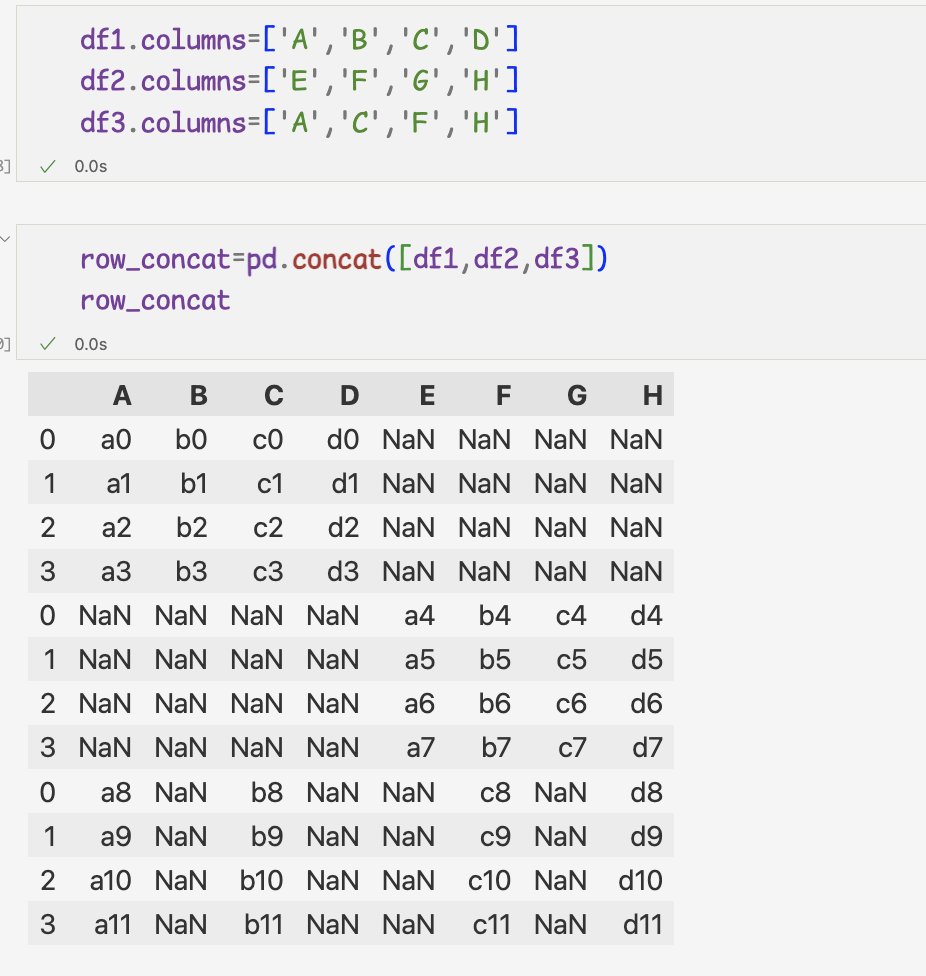
1.데이터 연결하기1) concat 메서드로 데이터 연결하기
- concat 메서드는 데이터프레임을 연결할 때 위에서 아래 방향으로 연결
- 연결할 데이터프레임 열의 이름이 모두같으면 그대로 유지
- 인덱스도 그대로 유지됨
row_concat=pd.concat([df1,df2,df3]) print(row_concat)2) 데이터프레임에 시리즈 연결하기
시리즈는 행이 아니라 새로운 열로 추가된다. nan누락값도 생김
=> 시리즈는 열이 없기 때문에
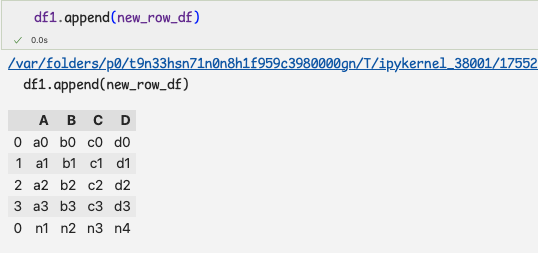
2.행 1개로 구성된 데이터프레임 생성하여 연결하기1 ) 1개의 행을 가지고 데이터프레임을 생성하여 df1에 연결
2 ) concat 메서드는 한 번에 2개 이상의 데이터프레임 연결
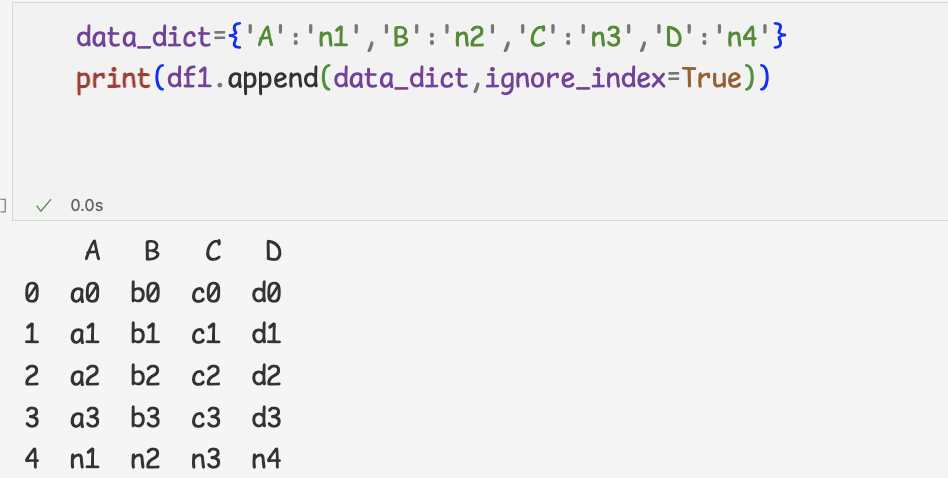
만약 1개라면 append메서드를 사용해도된다.3 ) append 메서드와 딕셔너리를 사용하면 간편히 행 연결
이때, ignore_index=True로 설정하면 데이터를 연결한 다음
데이터프레임의 인덱스를 0부터 다시 지정
3.다양한 방법으로 데이터 연결하기1 ) ignore_index 인자 사용하기
데이터를 연결한 다음 데이터프레임의 인덱스를 0부터 다시 지정
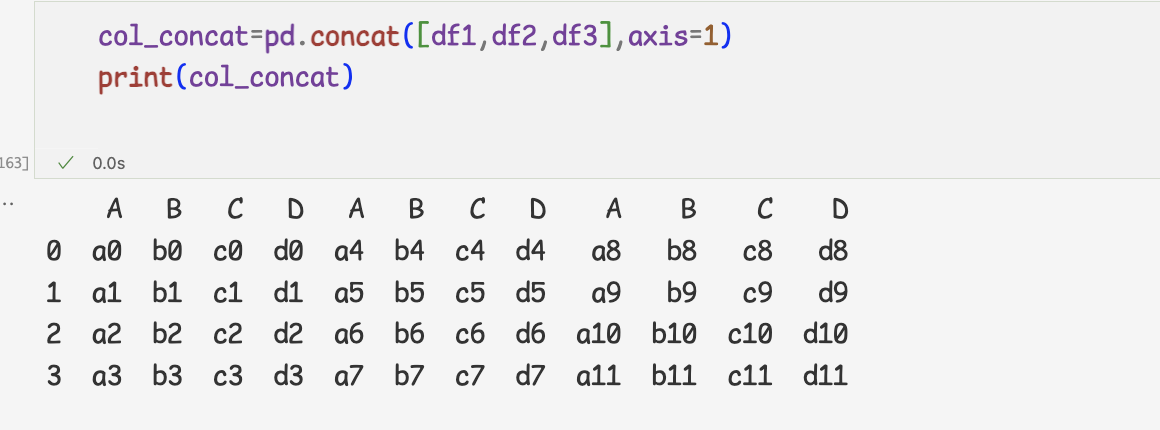
2 ) 열 방향으로 데이터 연결하기
concat 메서드의 axis=1로 지정
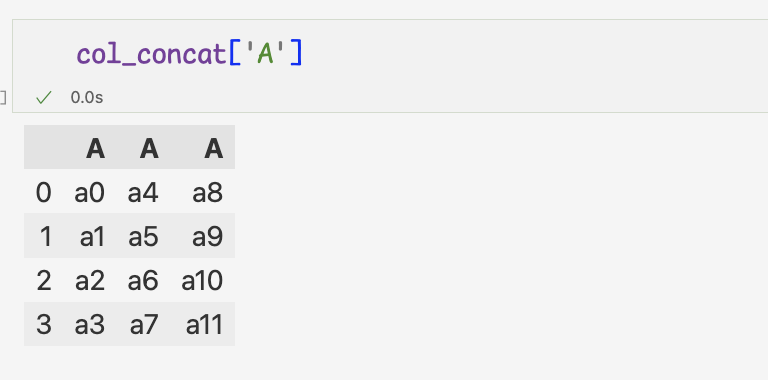
3 ) 만약 같은 열 이름이 있는 데이터에서 열 이름으로 데이터 추출 시,
해당 열 이름의 데이터를 모두 추출4 ) 새로운 열 추가
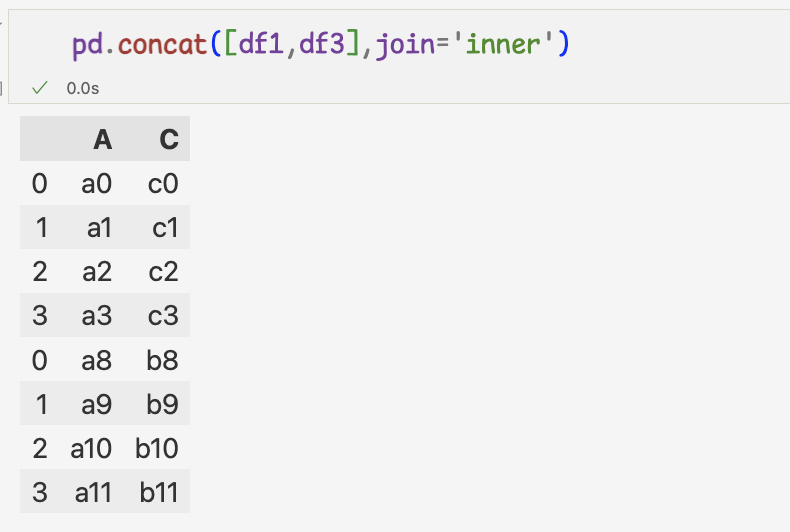
5 ) 공통 열과 공통 인덱스만 연결하기
=>서로 다른 열 이름으로 concat 연결했을때,
열이름이 정렬되며 연결,데이터프레임에 없는 열 이름의 데이터는
누락값으로 처리됨=> 누락값 없이 데이터를 연결하는 방법은?
6 ) 데이터프레임의 공통 열만 연결하면 누락값이 생기지 않음
=> join 인자를 inner로 지정해야 한다.7 ) 데이터프레임을 행 방향으로 연결하기
1-3. 데이터 연결 마무리
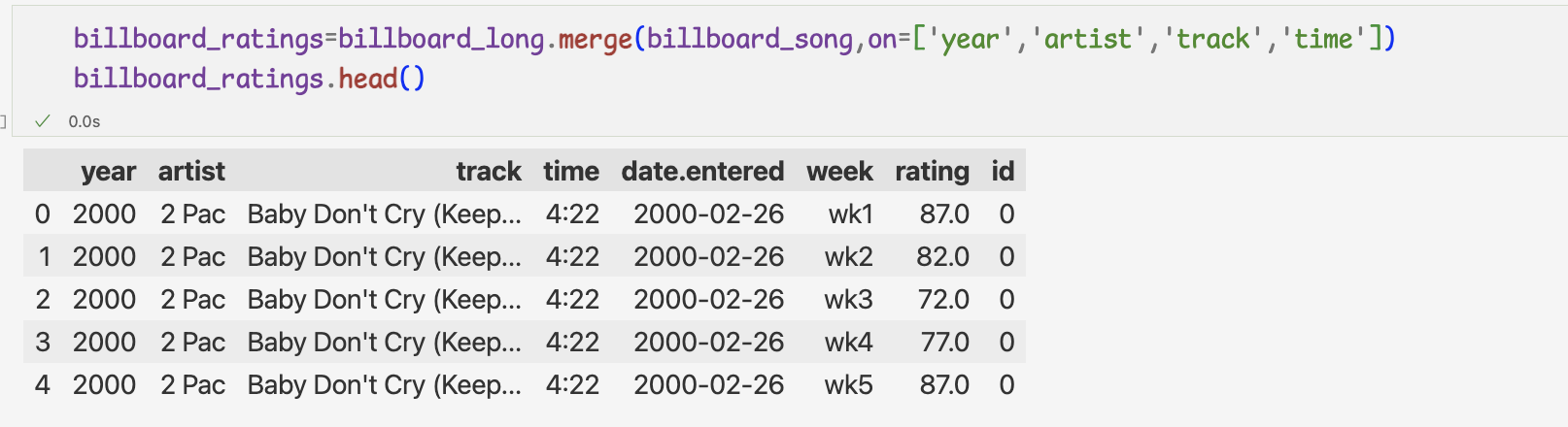
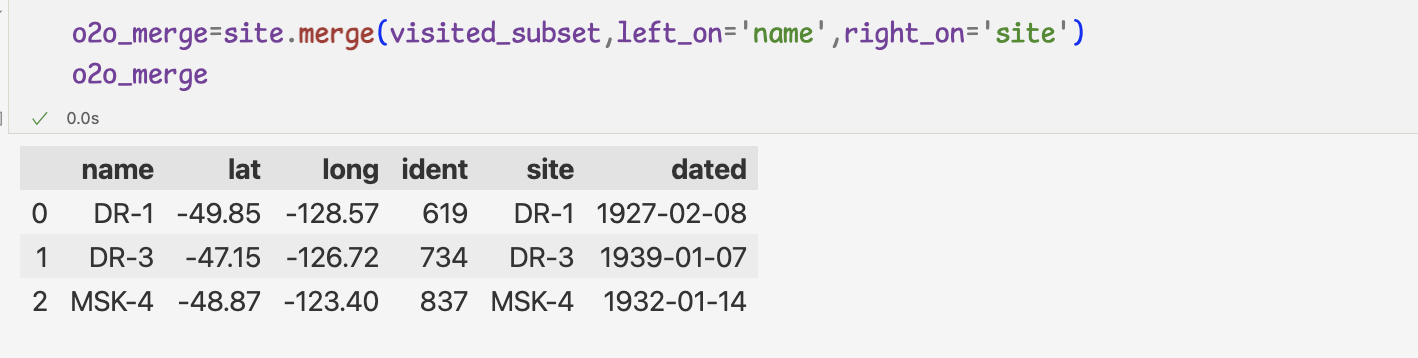
판다스는 데이터 연결 전용 메서드인 merge 제공
merge 메서드는 기본적으로 내부 조인 실행
left_on,right_on 인자는 값이 일치해야할 왼쪽,오른쪽 열을 지정
=>두개의 열의 값이 일치하면 왼쪽 데이터프레임 기준으로 연결
merge 메서드 사용하기
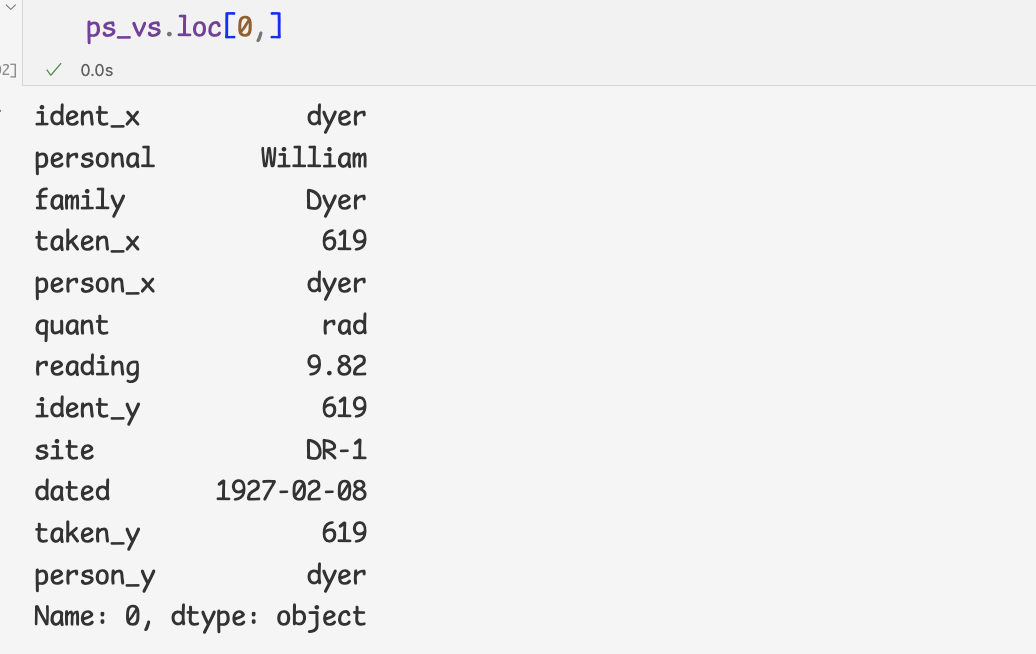
left_on,right_on에 전달하는 값은 여러 개도 상관이 없다.
중복된 열 이름에 접미사 _x,_y가 추가되어있으며
_x는 왼쪽 데이터프레임의 열의미,_y는 오른쪽 데이터프레임의 열 의미


2.누락값 처리하기
2-1.누락값이란?
1.누락값과 누락값 확인하기
누락값은 NaN,NAN,nan 과 같은 방법으로 표기할 수 있다.1 ) 누락값 확인하기
- 누락값은 0,' '와 같은 값과는 다른 개념
누락값: 데이터 자체가 없다는 의미
=>같다 라는 개념도 없다.
=>비교할 값 자체가 없으니 모두 False 출력
=> 자기 자신과 비교해도 False출력
누락값 확인 메서드 =>isnull
누락값이 아닌 경우 검사 메서드 => notnull
- 누락값이 생기는 이유
처음부터 누락값이 있는 데이터 불러오거나,
데이터를 연결,입력하는 과정에서 생길 수 있다.2 ) 누락값이 생기는 이유 알아보기
- 누락값이 있는 데이터 집합을 연결할 때 누락값이 생기는 경우
=>기존 데이터 집합에 처음부터 누락값이 있음
- 데이터를 입력할 때 누락값이 생기는 경우
누락값은 데이터를 잘못 입력하여 생길 수 있다.
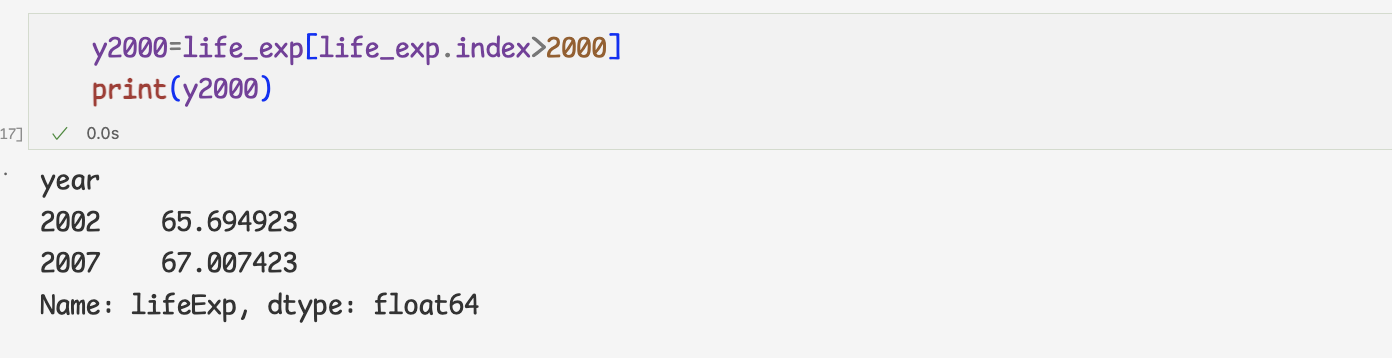
- 범위를 지정하여 데이터를 추출할 때 누락값이 생기는 경우
데이터프레임에 존재하지 않는 데이터를 추출하면 누락값이 생긴다.
=>처음부터 life_exp열에 없었던 연도가 포함되어 누락값 발생
=> 해당 문제 해결을 위해 , 불린 추출을 이용하여 데이터 추출
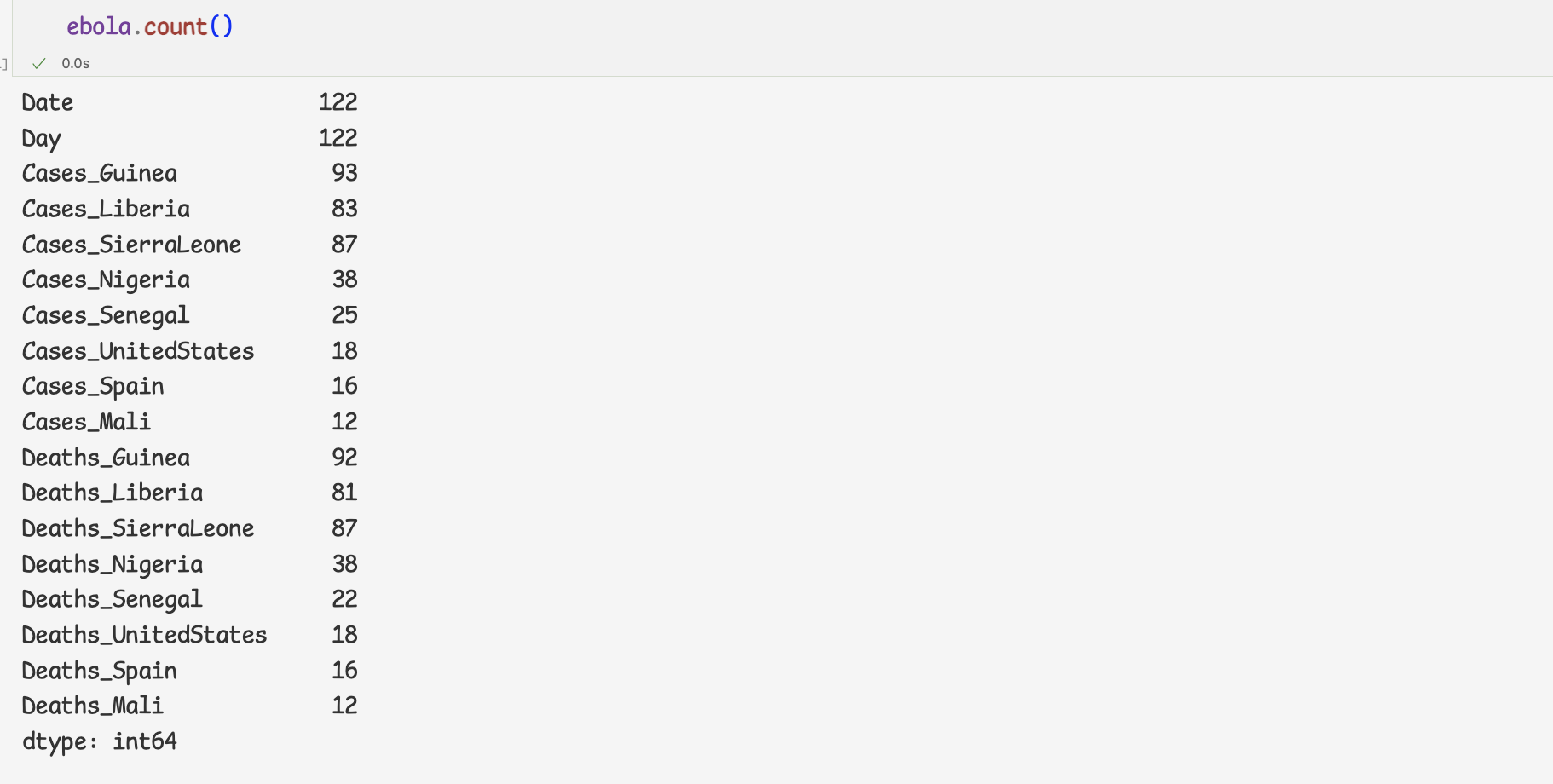
2.누락값의 개수
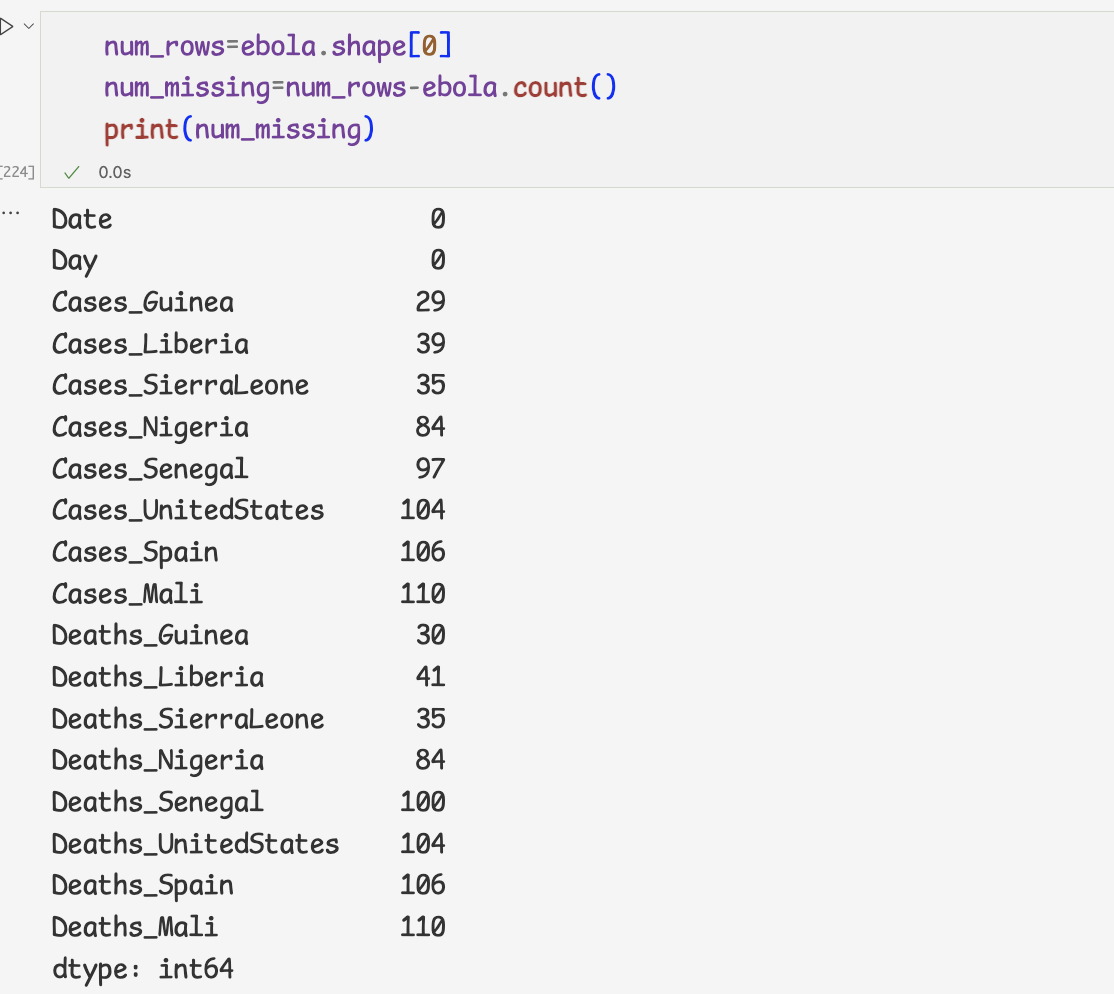
- 누락값의 개수 구하기
먼저 count 메서드로 누락값이 아닌 값의 개수를 구하기
shape메서드의 shape[0]에 전체 행의 데이터 개수 저장되어 있음을 이용
shape[0]-누락값이 아닌 값의 개수를 빼면 누락값의 개수를 구할 수 있다.count_nonzero,isnull 메서드를 조합해도 누락값의 개수를 구할 수 있다.
*count_nonzero 메서드는 배열에서 0이 아닌 값의 개수를 세는 메서드이다.
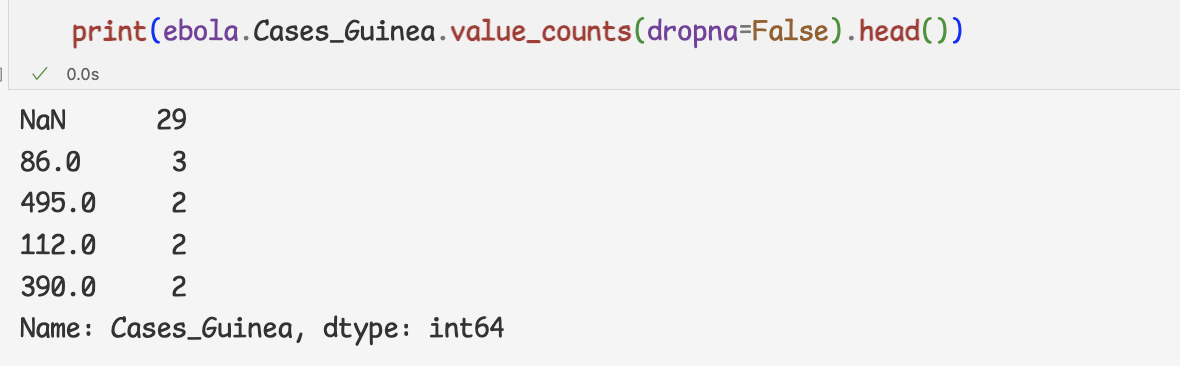
시리즈에 포함된 value_counts 메서드는 지정된 열의 빈도를 구하는 메서드
3.누락값 처리하기
누락값은 임의의 값으로 변경하거나 이미 있는 값으로 대신 채우는 방법등 으로
처리할 수 있다.
- 누락값 처리하기 - 변경, 삭제
1 ) 누락값 변경하기
fillna 메서드에 0을 대입하면 누락값 0으로 변경
fillna는 데이터프레임 크기가 매우 크고 메모리를 효율적으로 사용해야 하는 경우 자주 사용
2 ) fillna 메서드의 metho인잣값을 ffill로 지정하면
누락값이 나타나기 전의 값으로 변경된다.
=>6행의 경우 누락값이 나타나기 전 5행의 값사용,
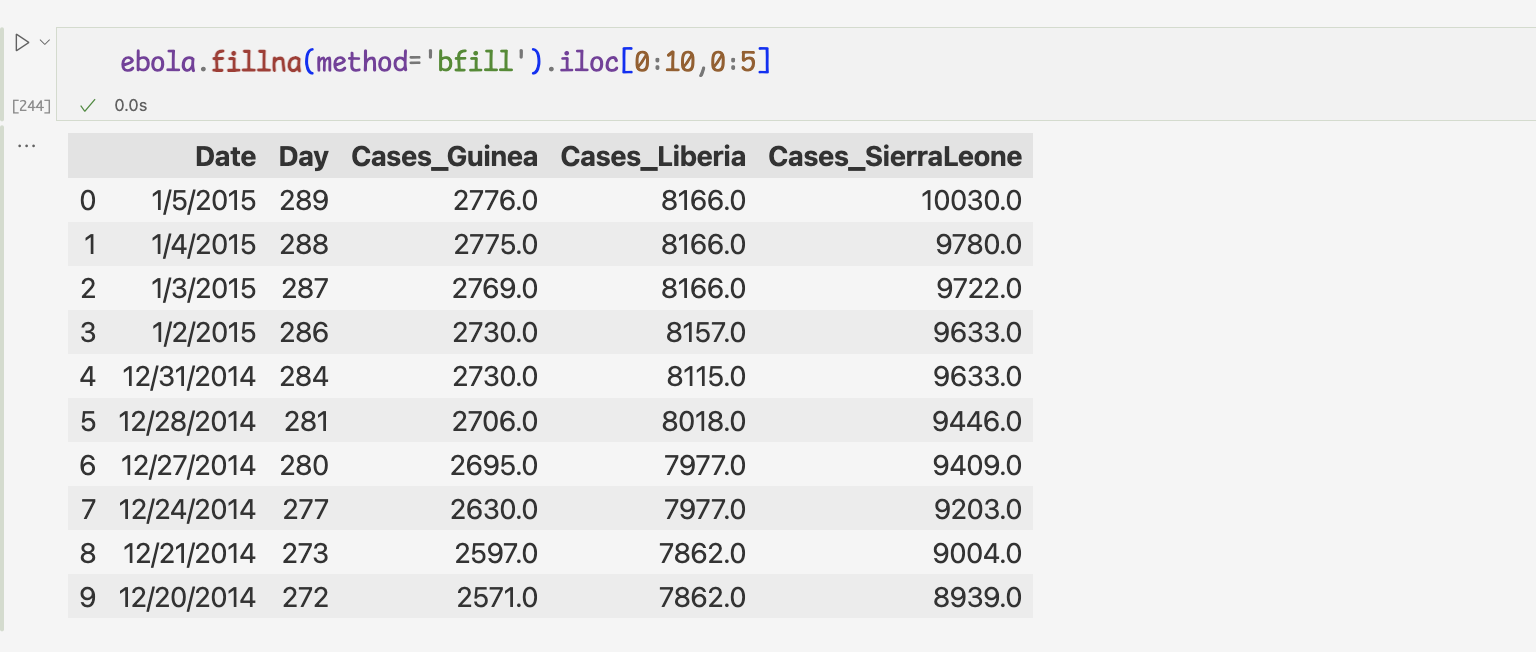
하지만 0,1행은 처음부터 누락값이기 때문에 그대로 남아있음3 ) method 인잣값을 bfill로 지정하면 누락값이 나타난 이후의 첫 번째 값으로 앞쪽의 누락값이 모두 변경된다.
하지만 이방법도 마지막 값이 누락값인 경우에 처리하지 못함
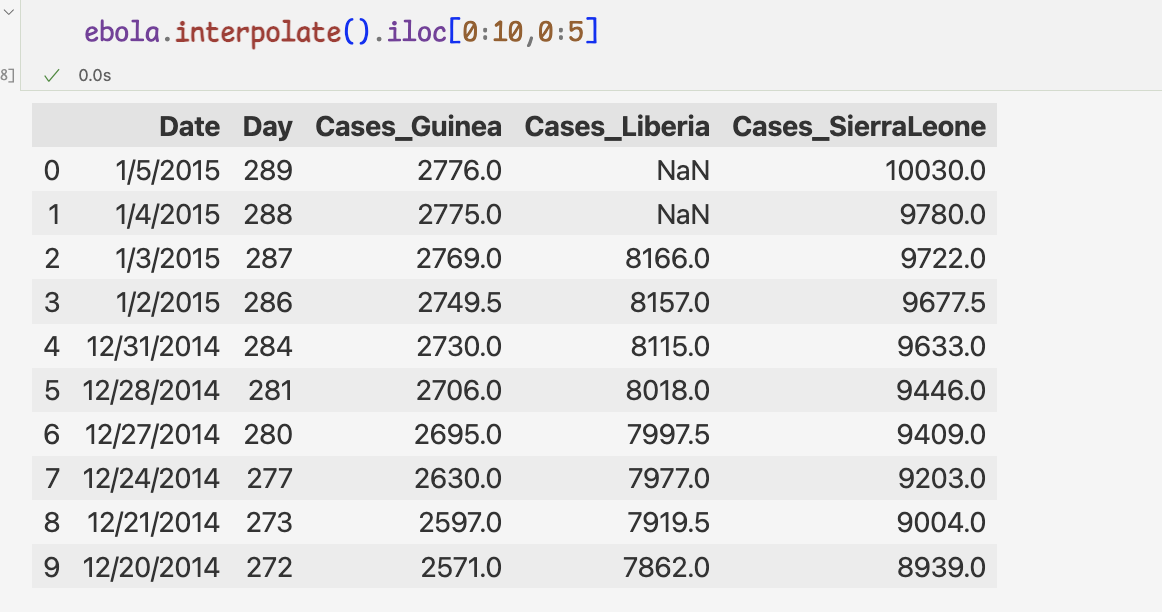
4 ) interpolate 메서드는 누락값 양쪽에 있는 값으로 중간값을 구한 뒤
누락값 처리 =>일정한 간격을 유지하고 있는 것처럼 수정할 수 있다.
5 ) 누락값 삭제하기 => dropna 메서드
누락값이 필요 없을 경우에는 삭제해도 된다.
무작정 삭제는 데이터가 편향되거나 개수가 너무 적어질 수도 있다.
4.누락값이 포함된 데이터 계산하기
- 누락값이 포함된 데이터 계산하기
=>누락값이 하나라도 있는 행은 계산 결과가 NaN이 됨
즉=> 계산 결과 누락값이 더많이 생김
- 누락값이 있을때 sum메서드를 사용하면 결괏값도 누락값이 된다
누락값을 무시한 채 계산하려면 skipna인값값을 True로 설정하면 됨





3.깔끔한 데이터
3-1.열과 피벗
넓은 데이터
데이터프레임의 열이 옆으로 길게 늘어선 형태를 '넓은 데이터'라고 한다.
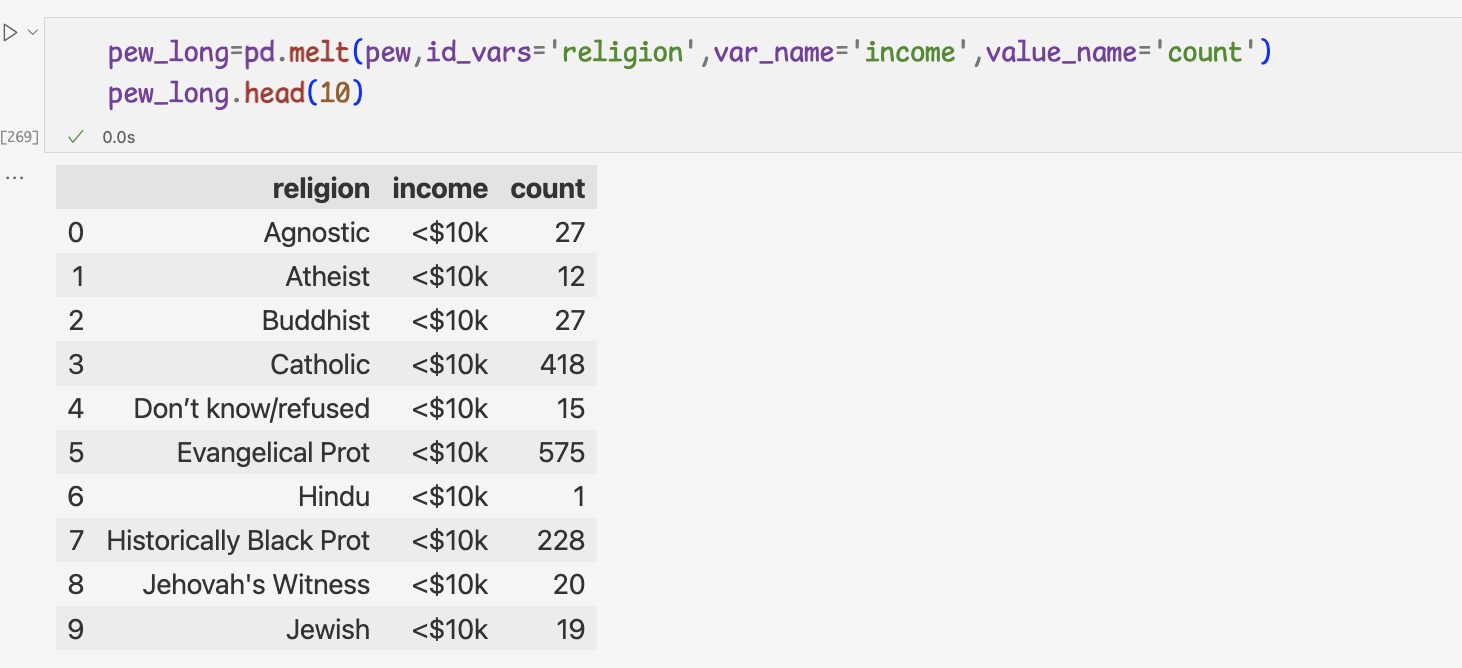
- melt 메서드
지정한 열의 데이터를 모두 행으로 정리해 준다.
- melt 메서드의 인자
id_vars:위치를 그대로 유지할 열의 이름을 지정
value_vars:행으로 위치를 변경할 열의 이름을 지정
var_name:val_vars로 위치를 변경한 열의 이름을 지정
value_name:var_name으로 위치를 변경한 열의 데이터를 저장한 열의 이름을 지정
- melt 메서드 사용하기
1 ) 1개의 열만 고정하고 나머지 열을 행으로 바꾸기
id_vars 인잣값으로 지정한 열을 제외한 나머지 열이 variable열로 정리되고
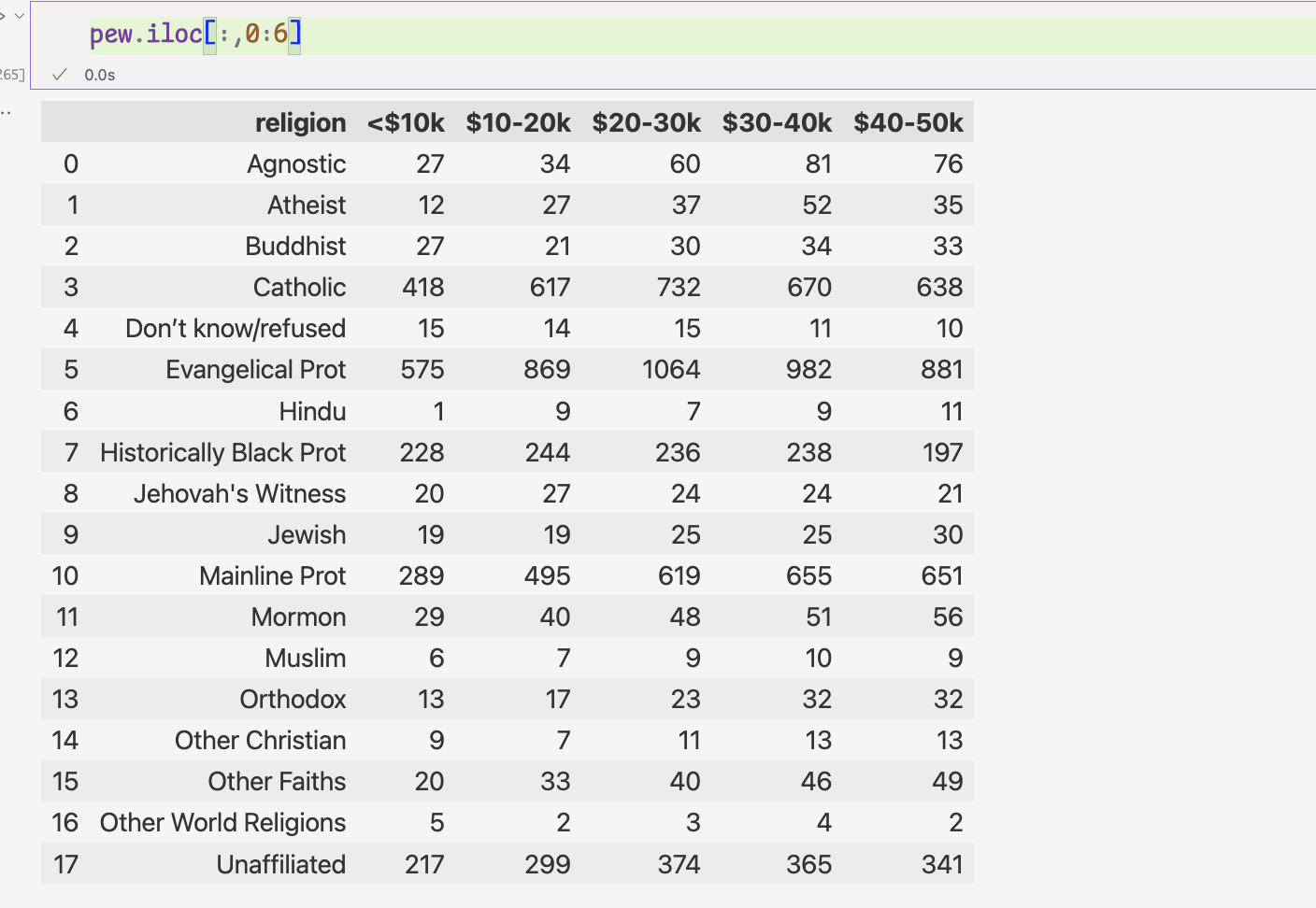
소득 정보 열의 행 데이터도 value열로 정리됨 =>이 과정을 religion열을 고정하여 피벗했다고 말한다.
variable,value열의 이름은 어떻게 바꿀까?
var_name,value_name 인잣값을 사용하면 된다.
2 ) 2개 이상의 열을 고정하고 나머지 열을 행으로 바꾸기
3-2.열 이름 관리하기
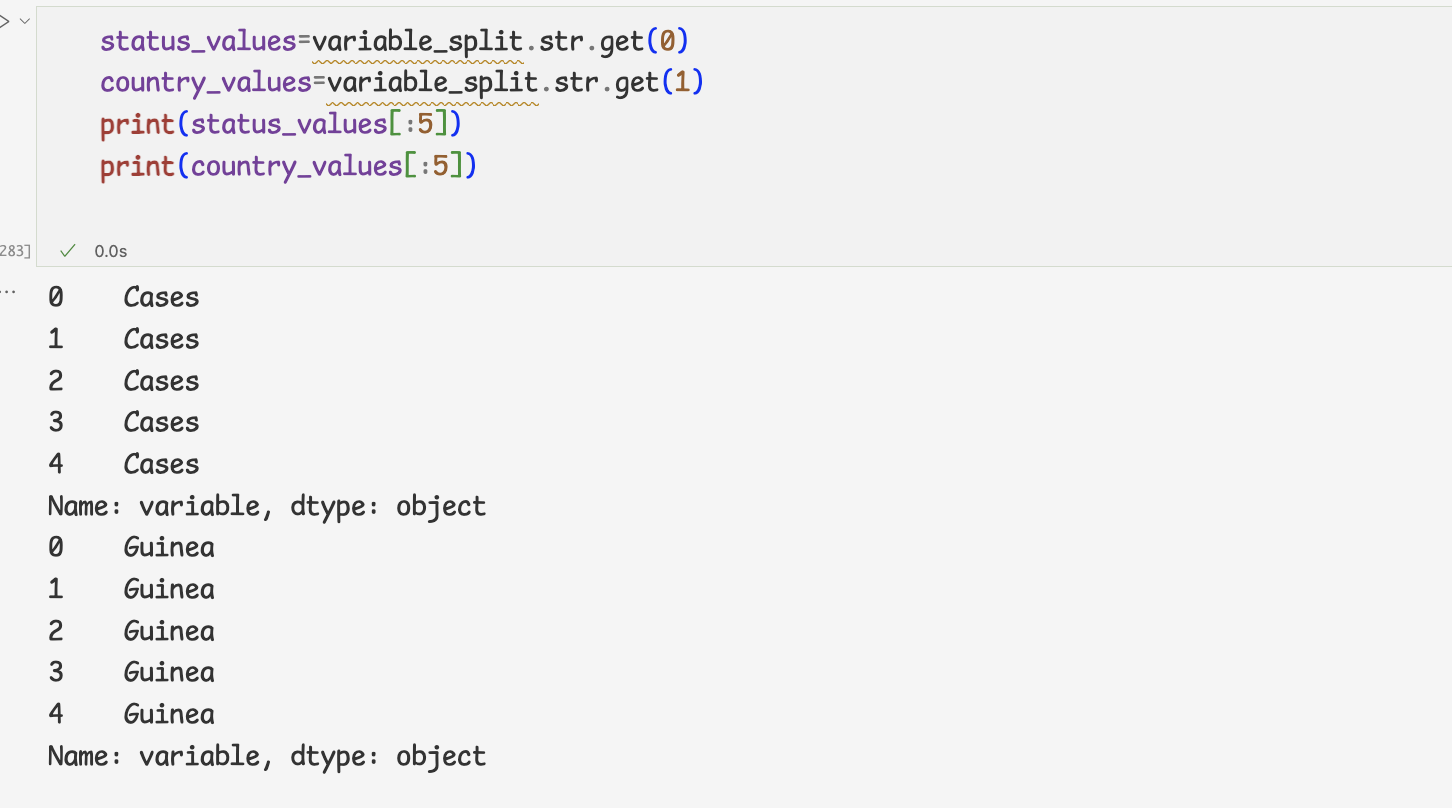
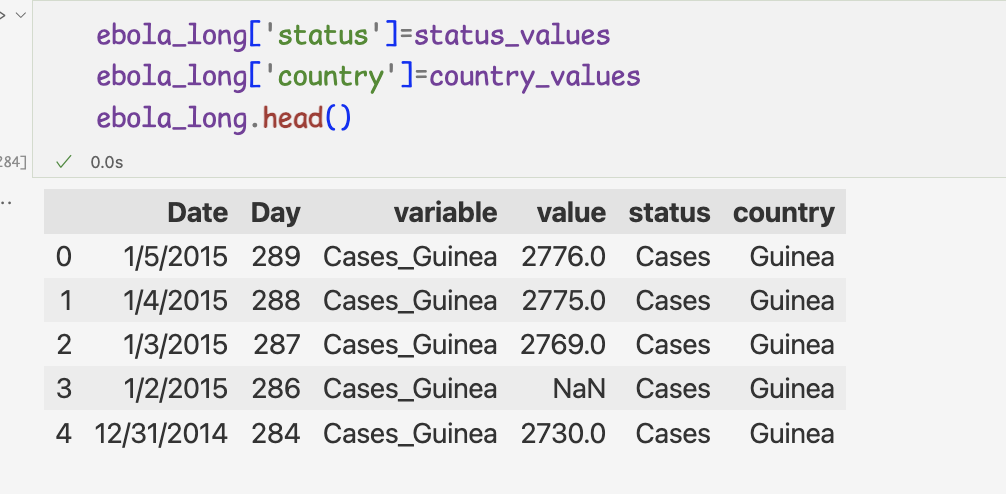
열 이름 분리하고 데이터프레임에 추가하기1 ) split 메서드로 열 이름 분리하기
2 ) get 메서드를 사용하여 0,1번째 인덱스의 데이터를 한 번에 추출
3 ) 2에서 분리한 문자열을 status,country라는 열이름으로 데이터프레임에 추가
3-3.여러 열을 하나로 정리하기
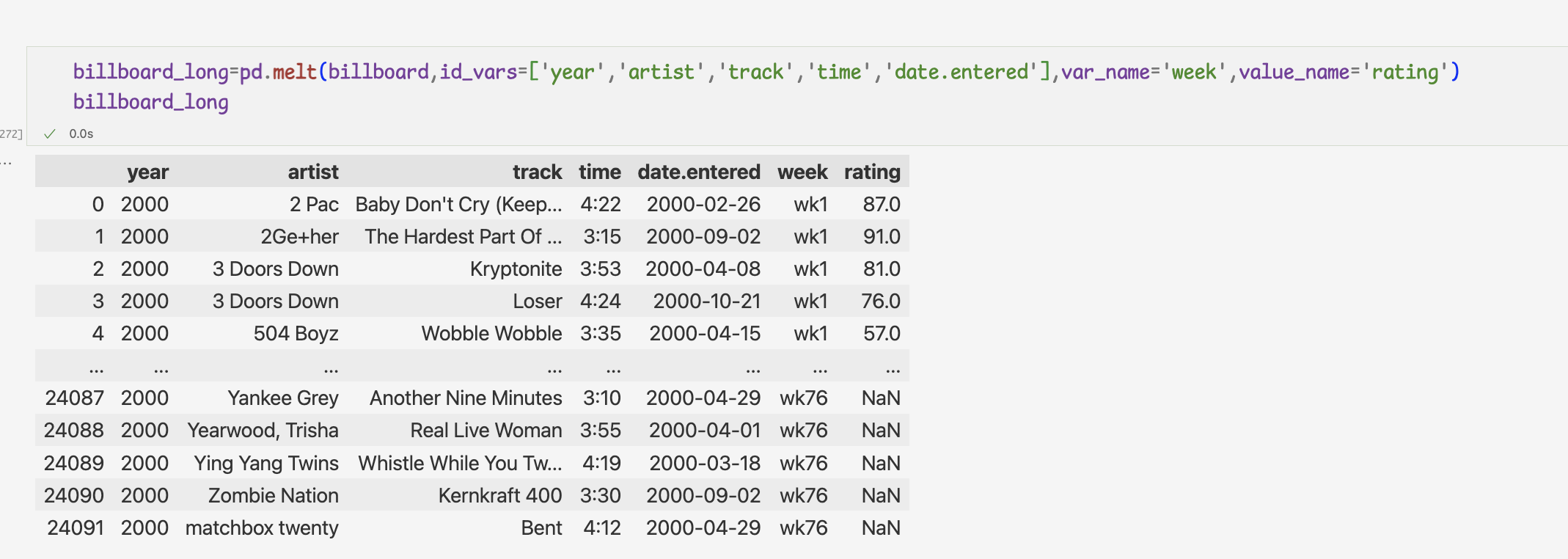
가상 데이터의 여러 열을 하나로 정리하기-melt,pivot_table
- melt 메서드로 일별 온도 측정값 피벗
- pivot_table 메서드
-행과 열의 위치를 다시 바꿔 정리해줌
-index 인자에는 위치를 그대로 유지할 열 이름 지정
-columns 인자에는 피벗할 열 이름을 지정
-values 인자에는 새로운 열의 데이터가 될 열 이름 지정
3-4.중복 데이터 처리하기
중복 데이터 처리하기
=>중복 데이터가 꽤 많다.
중복 데이터를 가지고 있는 열을 따로 모아 새로운 데이터프레임에 저장한다.
drop_duplicate 메서드로 중복 데이터 제거
중복을 제거한 데이터프레임에 아이디 추가
merge 메서드를 사용해 데이터 합치기