[Pandas] 10-11
1.그룹 연산
2.시계열 데이터
1. 그룹 연산
1-1.데이터 집계
데이터 집계하기- gropuby 메서드
- groupby 메서드로 평균값 구하기
year 열을 기준으로 데이터를 그룹화한 다음 lifeExp 열의 평균 구하기=> df.groupby('year').lifeExp.mean()도 같은 결과를 얻을 수 있다.
분할-반영-결합 과정 살펴보기- groupby 메서드
- 분할-반영-결합 과정 살펴보기
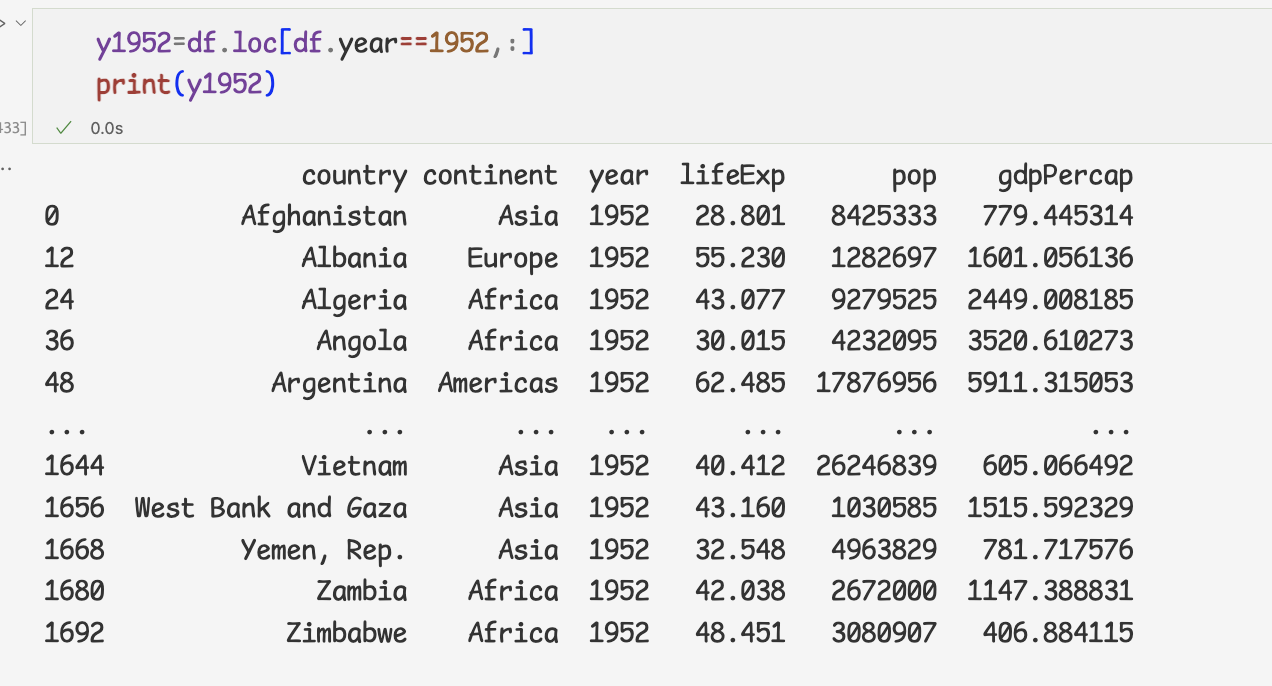
1 ) groupby 메서드에 열 이름을 전달하면 '분할'작업이 먼저 일어난다.(year 열의 데이터를 중복 없이 추출)
2 ) 연도별로 평균값을 구해야한다. 그러려면 각 연도별 데이터를 추출해야 한다.다음은 1952년의 데이터를 추출한 것. 이것을 '반영' 이라고 이해한다.
3 ) 1952년의 데이터에서 lifeExp 열의 평균값을 구해야한다.
이 과정도 '반영'의 한 부분이다.4 ) 과정 2-3을 반복하여 남은 연도의 평균값을 구하면 '반영'작업이 끝남
5 ) 마지막으로 연도별로 계산한 lifeExp 평균값을 합친다 .
이 과정이 '결합' 작업
groupby 메서드와 함께 사용하는 집계 메서드집계 메서드
- count:누락값을 제외한 데이터 수를 반환
- size:누락값을 포함한 데이터 수를 반환
- mean:평균값을 반환
- std:표준편차 반환
- min:최솟값 반환
- quatile(q=0.25):백분위수 25%
- quantile(q=0.50):백분위수 50%
- quantile(q=0.75): 백분위수 75%
- max:최댓값 반환
- sum:전체 합 반환
- var:분산 반환
- sem:평균의 표준편차 반환
- describe:데이터 수,평균,표준편차,최소값,백분위수,최댓값 모두 반환
- first:첫번째 행 반환
- last:마지막 행 반환
- nth:n번째 행 반환
agg 메서드로 사용자 함수와 groupby 메서드 조합하기
라이브러리에서 제공하는 집계메서드로 원하는 값을 계산할 수 없는 경우,
직접 사용자 함수 만들어야함
=>사용자 함수와 groupby메서드를 조합하려면 agg메서드 이용
- 평균값을 구하는 사용자 함수와 groupby 메서드
1 ) 입력받은 열의 평균값을 구하는 함수 만들기
2 ) 1의 함수를 groupby메서드와 조합하기 위해 agg메서드 사용
=>mean메서드를 사용하여 얻은 값과 동일하다
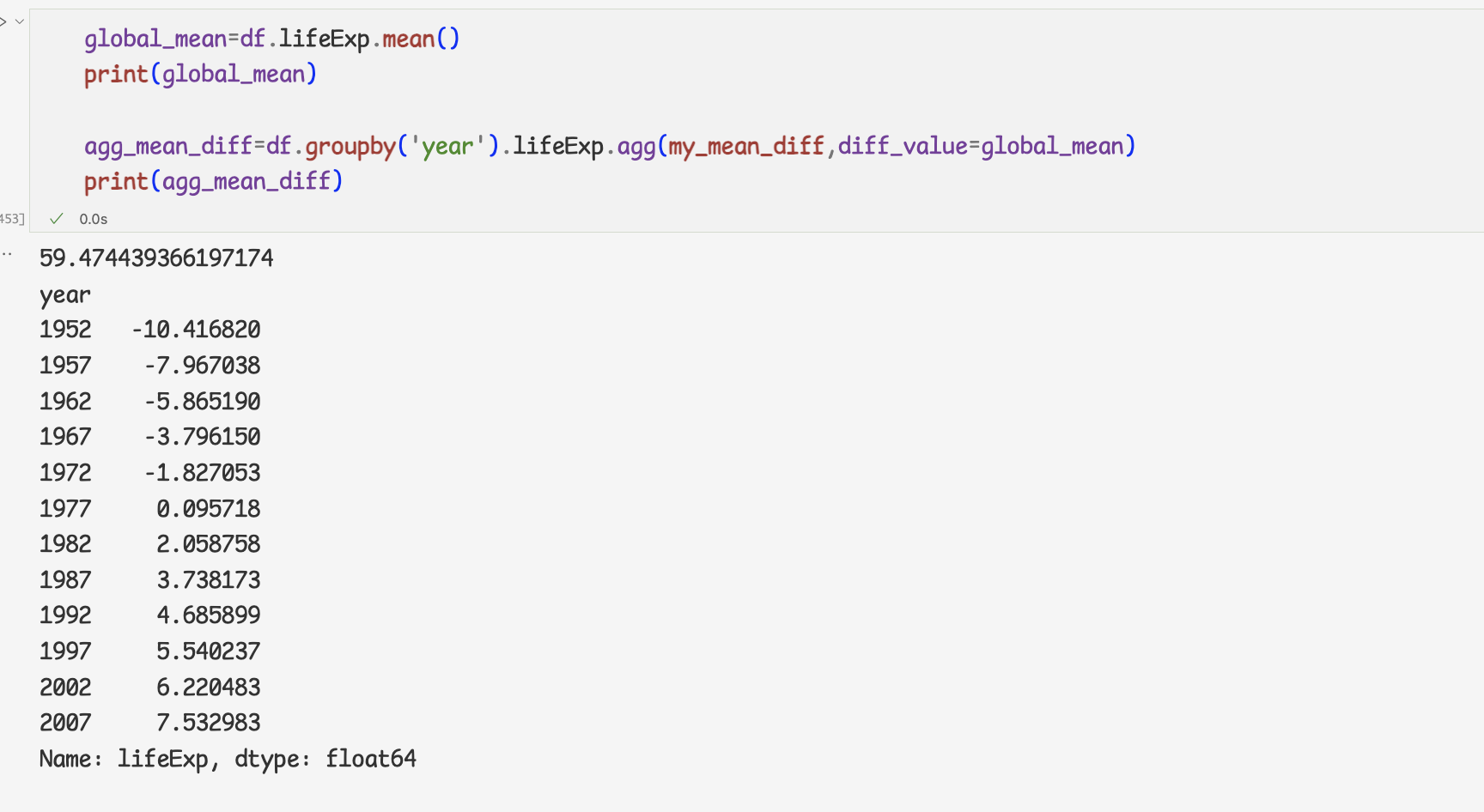
- 2개의 인잣값을 받아 처리하는 사용자 함수와 groupby 메서드
1 ) 2개의 인잣값을 받아 처리하는 사용자 정의 함수 만들기
=>첫번째 인자의 평균값을 구하여 두번째 인자와의 값 차이를 계산한 다음 반환
2 ) 연도별 평균 수명에서 전체 평균 수명을 뺀 값 구하기
여러 개의 집계 메서드 한 번에 사용하기
리스트나 딕셔너리에 담아 agg메서드에 전달하면 된다.
- 집계 메서드를 리스트,딕셔너리에 담아 전달하기
1 ) 연도별로 그룹화한 lifeExp열의 0이 아닌 값의 개수,평균,표준편차를 한번에 계산하여 출력
=>넘파이 메서드를 리스트에 담아 agg메서드에 전달
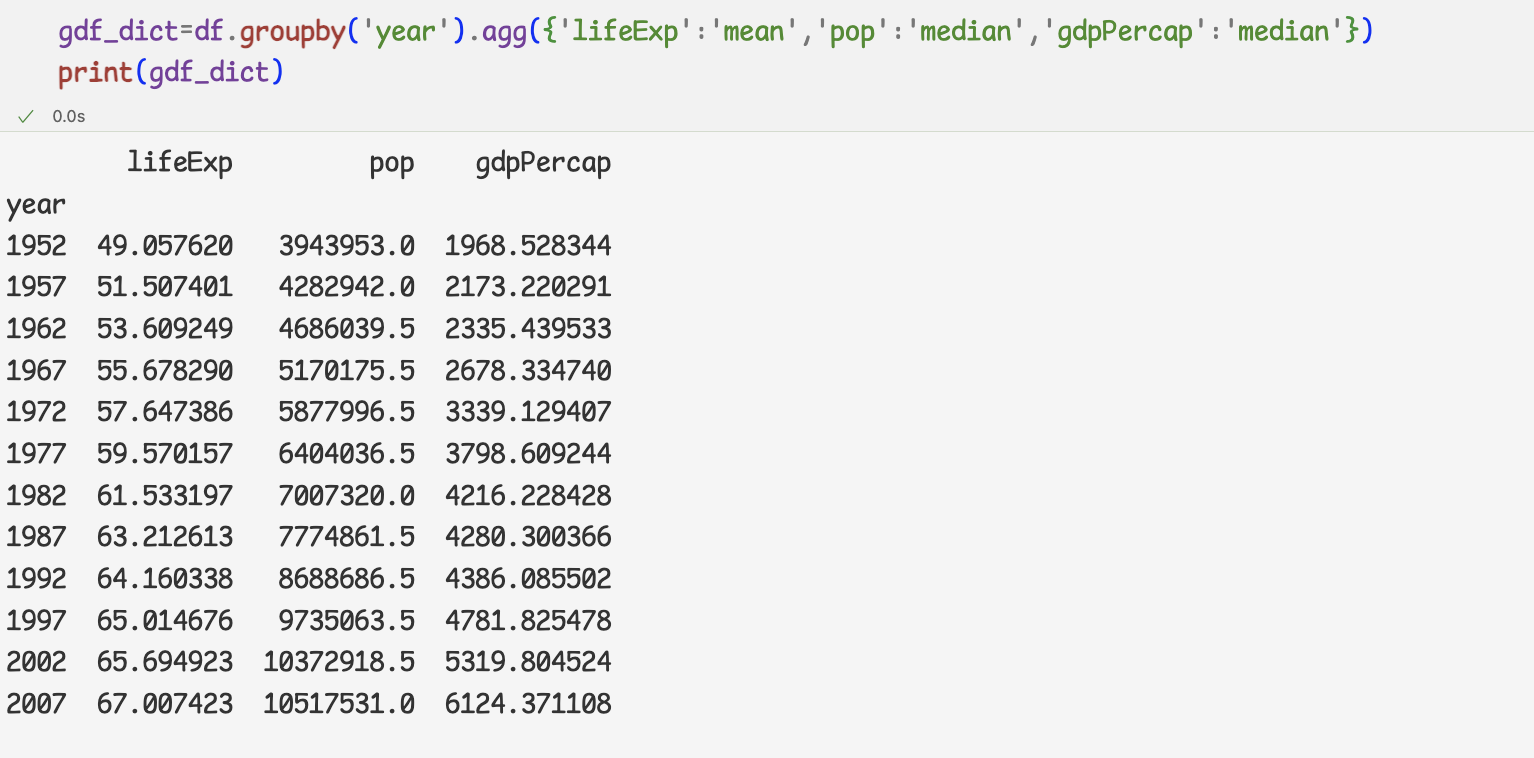
2 ) 집계 메서드를 딕셔너리에 담아 agg메서드에 전달하기
1-2.데이터 변환
데이터 변환 메서드는 데이터와 메서드를 일대일로 대응시켜 계산하므로,
데이터의 양이 줄어들지 않는다=>데이터를 변환하는 데 사용
표준점수 계산하기
표준점수 :데이터의 평균과 표준편차의 차이
표준점수를 구하면 평균값이0 표준편차 1이 됨
=>데이터가 표준화되어 서로 다른 데이터를 쉽게 비교할 수 있다.
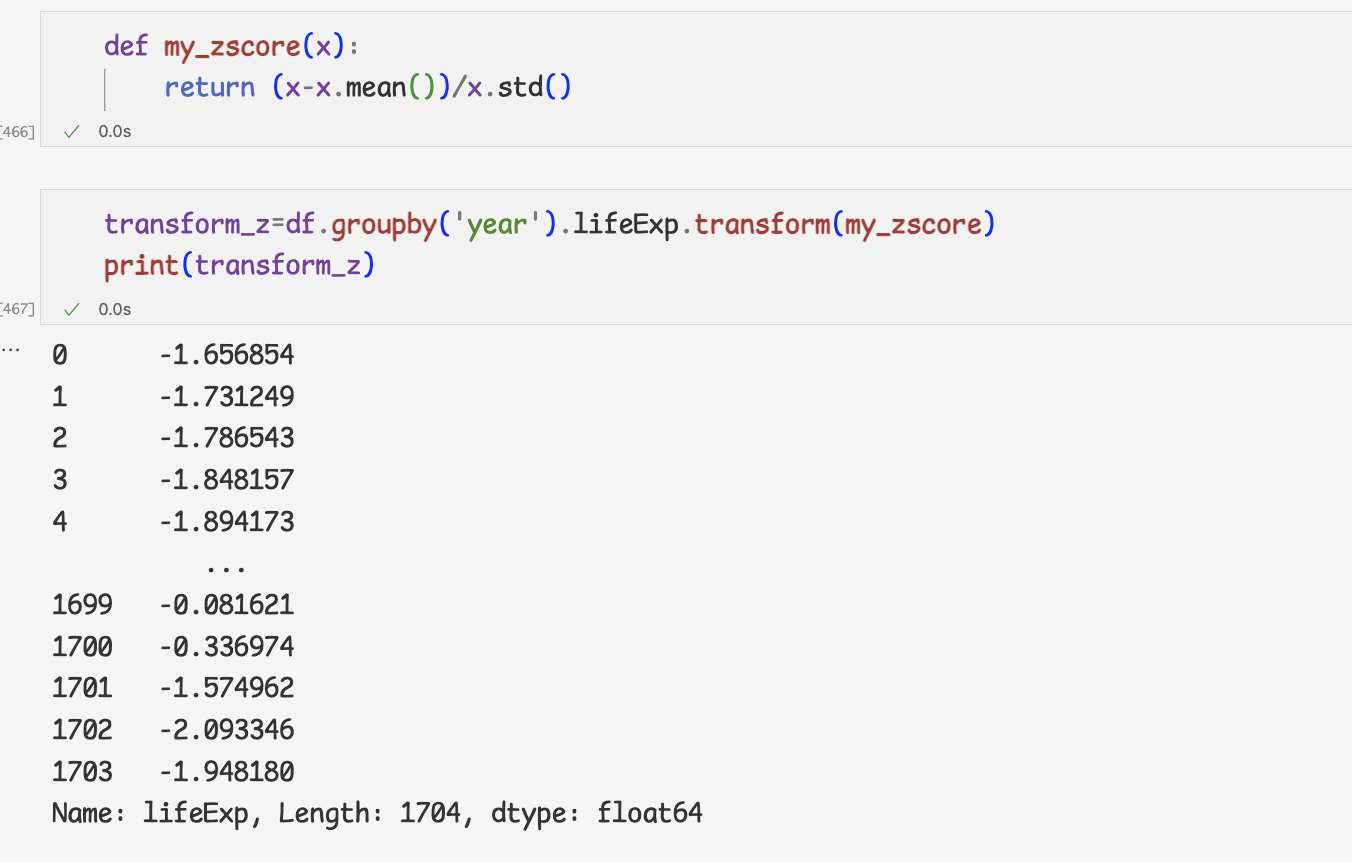
- 표준점수 계산하기
✳️ agg vs transform 비교
agg: sum,mean등 집계하는 함수 위주로 적용
transform:각 요소별로 적용되는데 적용
- my_zcore 함수는 데이터를 표준화할 뿐 집계는 하지 앟는다.
즉, 데이터의 양이 줄어들지 않는다
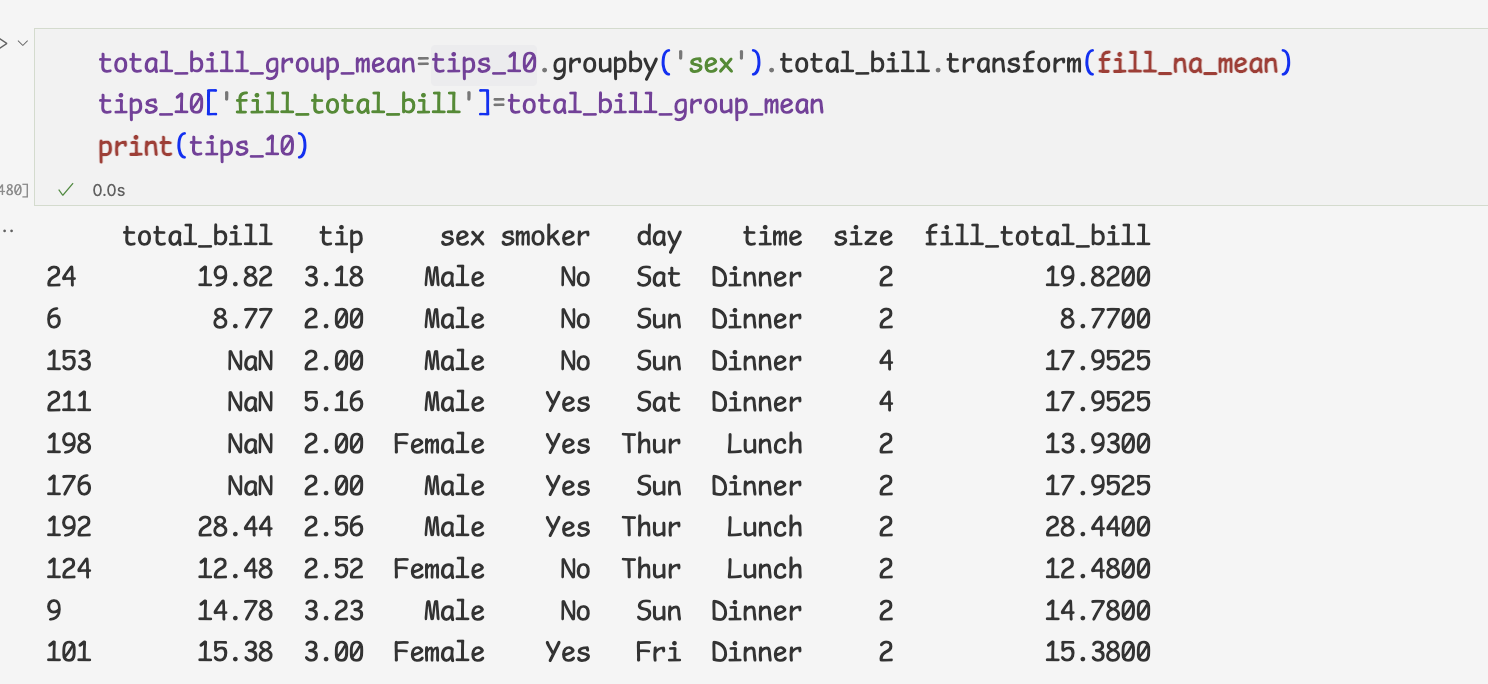
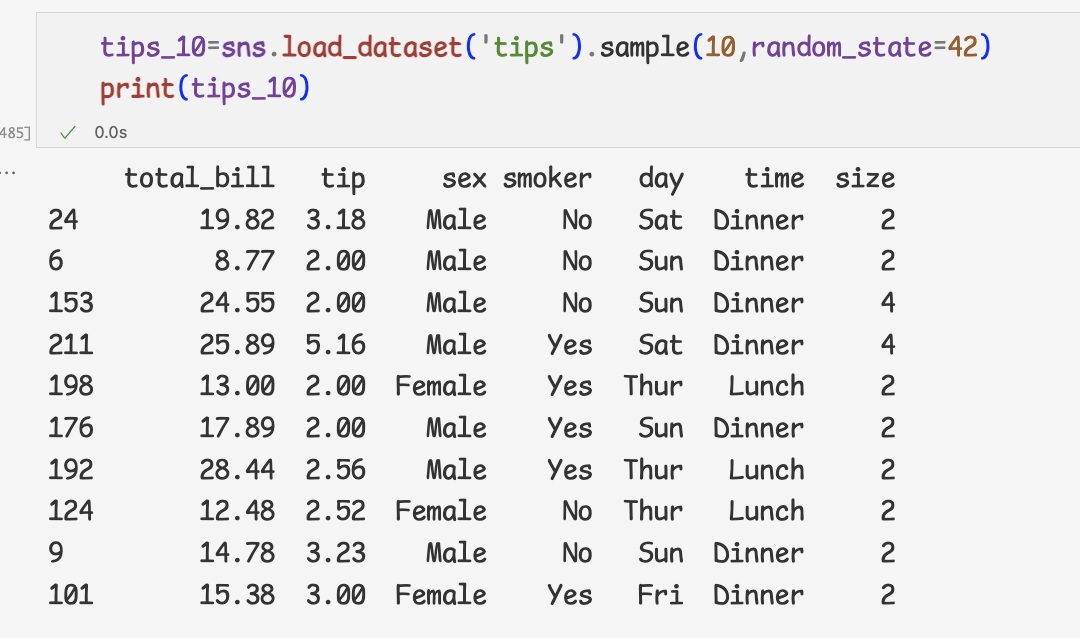
누락값을 평균값으로 처리하기
- 누락값을 평균값으로 처리하기
=>여성과 남성데이터가 불균형하기 때문에, 남성데이터의 영향을 받아 여성의 데이터가 훼손될 수 있다.
=>total_bill열을 살펴보면 남성의 누락값3개,여성의 누락값1개
다음은 성별을 구분하여 total_bill열의 데이터를 받아 평균값을 구하는 함수
남성과 여성의 누락값을 고려하여 계산한 평균값으로 추가
1-3.데이터 필터링
데이터 필터링 사용하기 - filter 메서드
=>1,5,6테이블의 주문이 매우 적다는 것을 알 수 있다.
=>30번 이상의 주문이 있는 테이블 그룹화하여 저장
=>1,5,6 테이블의 데이터가 제외되었다는 것을 알 수 있다.
1-4.그룹 오브젝트
그룹 오브젝트 살펴보기
- 그룹 오브젝트 저장하여 살펴보기
groupby 메서드의 결괏값을 출력하면 자료형이 그룹 오브젝트라는 것을
확인할 수 있다.그룹 오브젝트에 포함된 그룹을 보려면 groups 속성을 출력하면 된다.
=>sex 열로 그룹화한 데이터프레임의 인덱스를 확인할 수 있다.
=>이 그룹 오브젝트로 집계,변환,필터 작업을 수행한다.
한 번에 그룹 오브젝트 계산하기
- 그룹 오브젝트의 평균 구하기
그룹 오브젝트를 이용하여 평균을 구한다.
=>파이썬은 자동으로 계산할 수 있는 열을 골라주는 기능 제공
그룹 오브젝트 활용하기
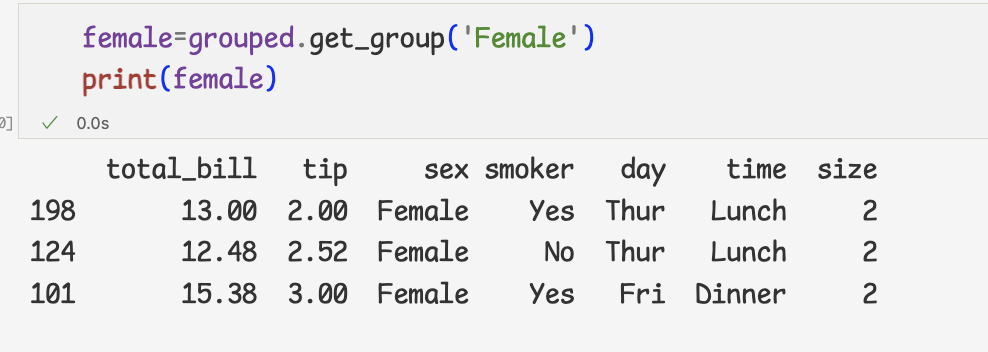
- 그룹 오브젝트에서 데이터 추출하고 반복하기
1 ) 그룹 오브젝트에서 특정 데이터만 추출하려면 get_group메서드 사용
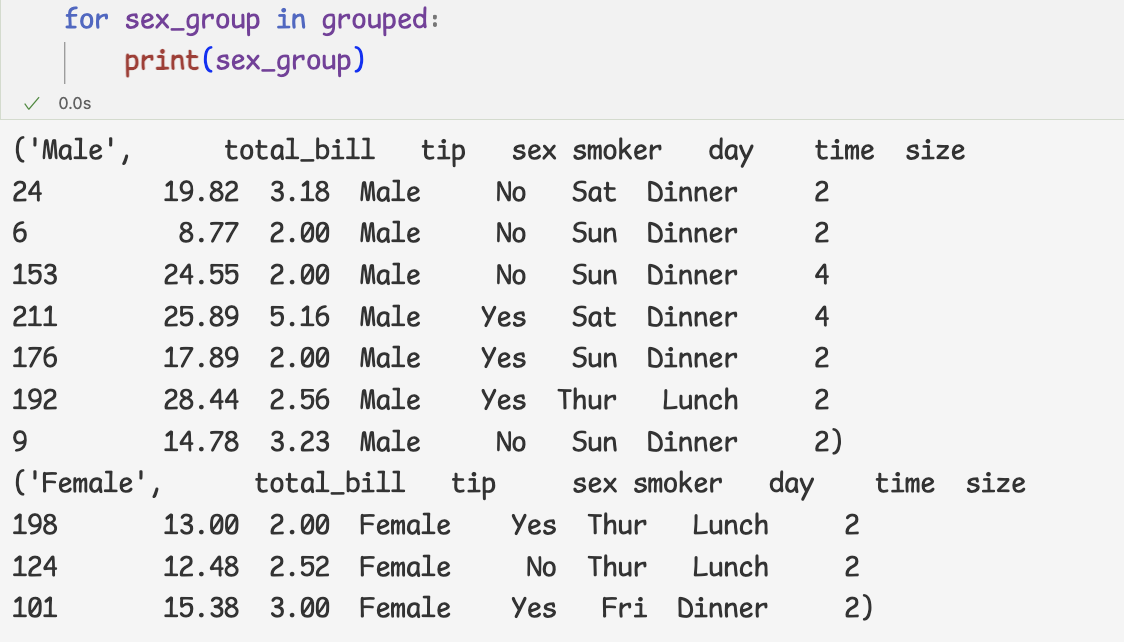
2 ) 그룹 오브젝트를 반복문에 사용
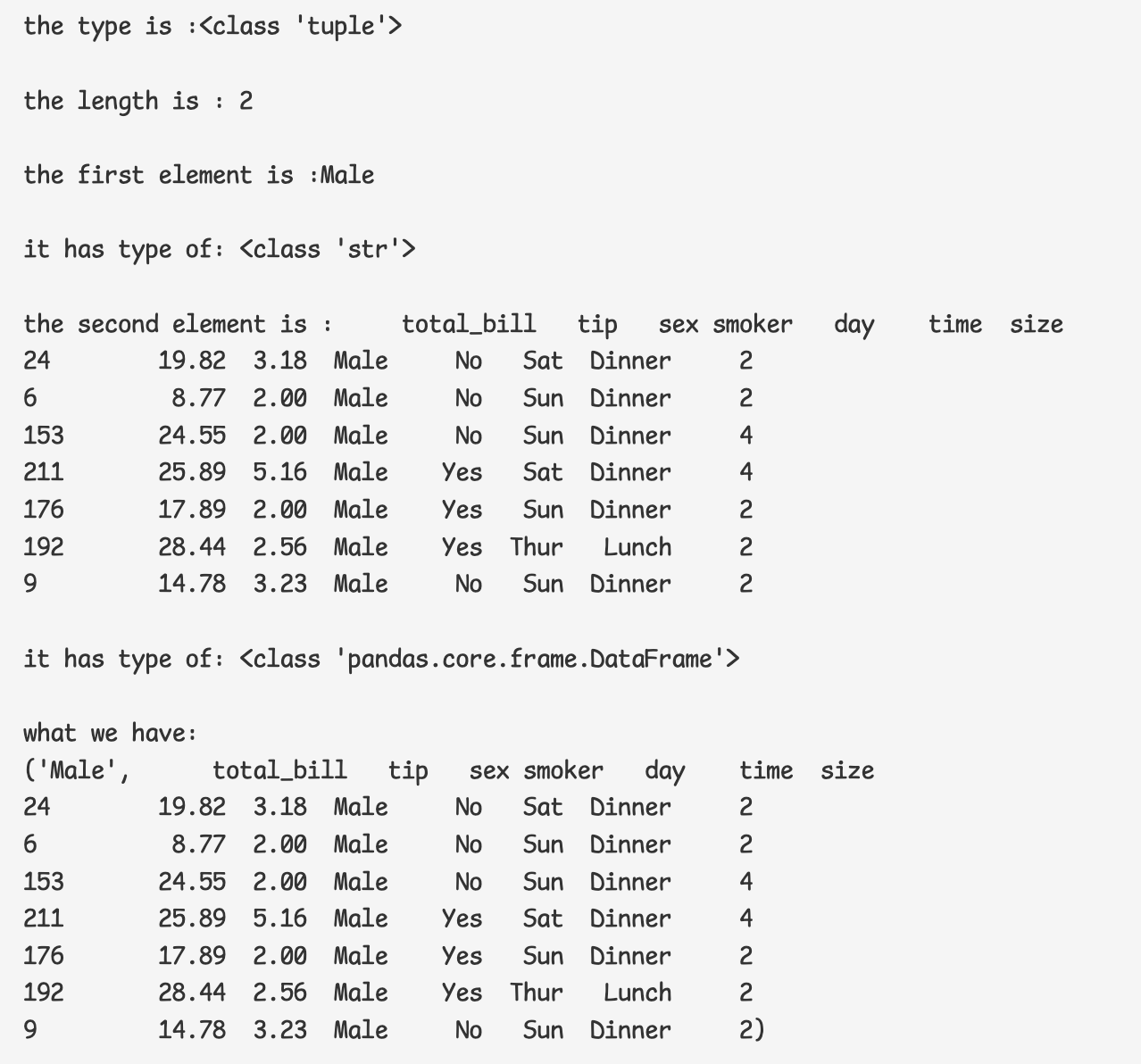
3 ) sex_group으로 넘어온 값이 튜플이라는 것을 알 수 있다.
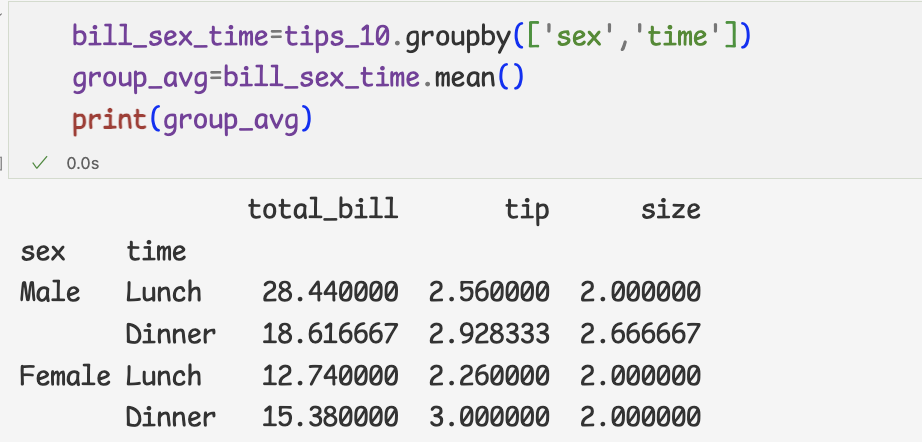
여러 열을 사용해 그룹 오브젝트 만들고 계산하기
- 그룹 오브젝트 계산하고 살펴보기
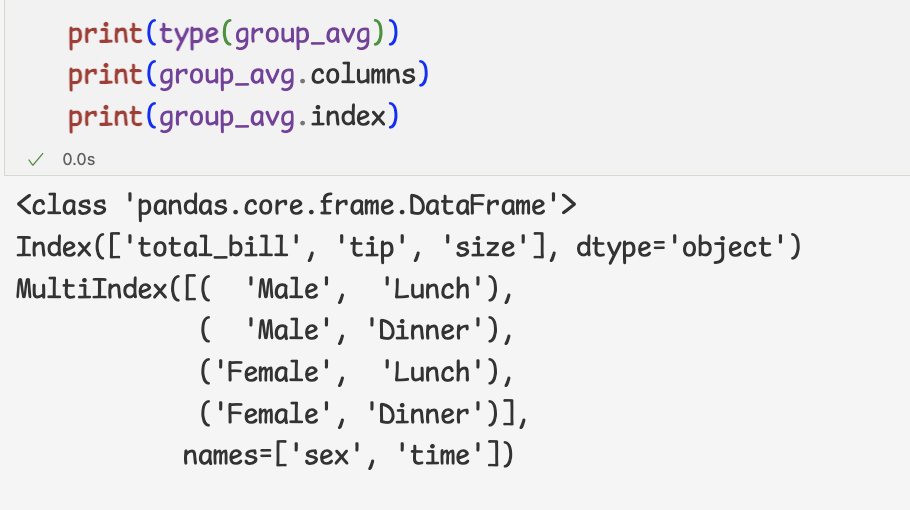
1 ) 여러 열을 사용하여 데이터 그룹화를 위해 열을 groupby메서드에 전달
2 ) 자료형 타입과 열,인덱스 구성 확인
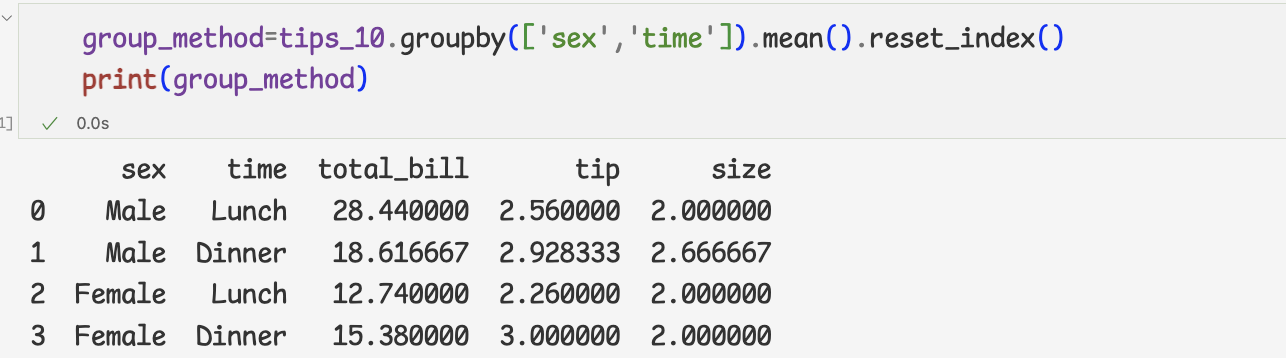
3 ) multidindex인 경우에는 reset_index메서드를 사용
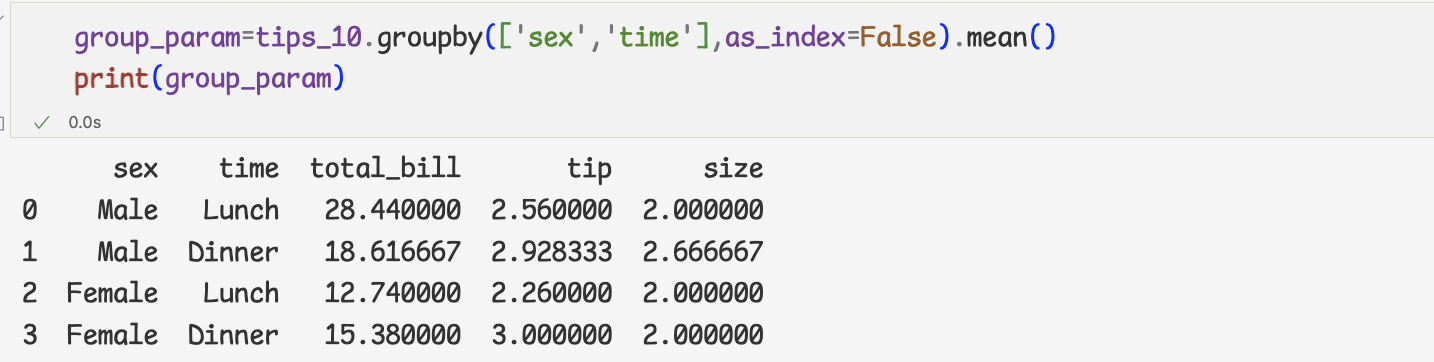
4 ) reset_index 메서드 대신 as_index인자를 False로 설정해도
3과 같은 결과를 얻을 수 있다.









2.시계열 데이터
2-1.datetime 오브젝트
datetime 라이브러리는 날짜와 시간을 처리하는 파이썬 라이브러리
date오브젝트 (날짜처리)
time오브젝트(시간처리
datetime오브젝트(날짜와 시간처리)
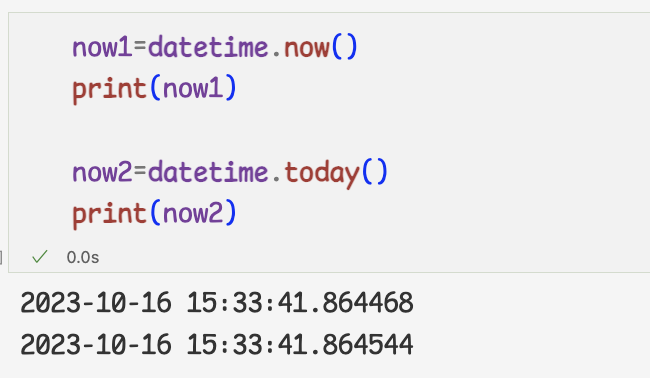
datetime 오브젝트 사용하기1 ) now,today메서드를 사용하면 현재 시간 출력 가능
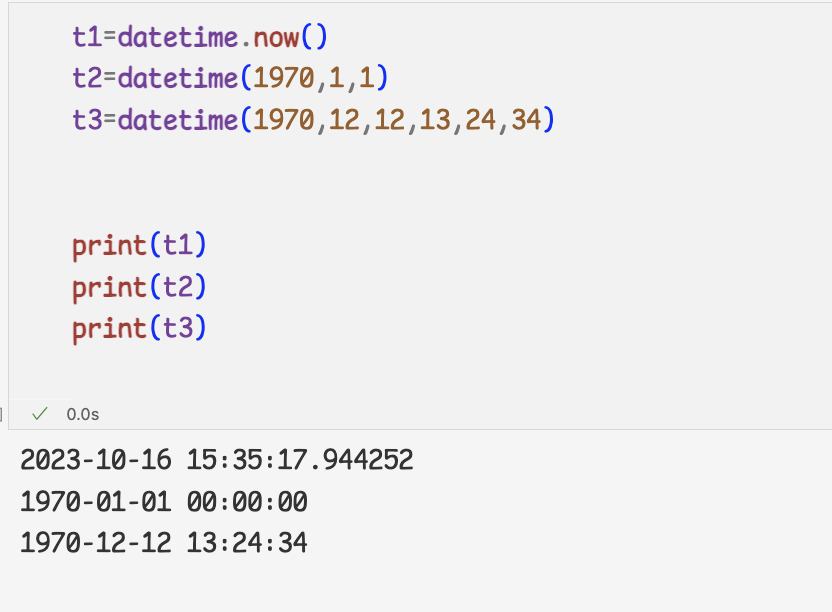
2 ) datetime 오브젝트를 생성할 때 시간을 직접 입력하여 인자로 전달
3 ) datetime 오브젝트를 사용하는 이유 중 하나는 시간 계산을 할 수 있다는점
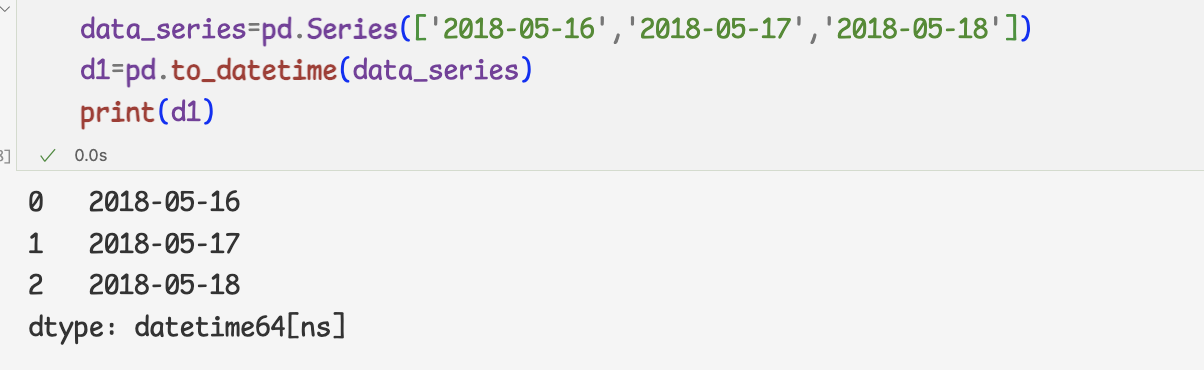
datetime 오브젝트로 변환하기- to_datetime메서드
경우에 따라서 시계열 데이터를 문자열로 저장해야 할 때도 있다.
하지만 문자열은 시간 계산을 할 수 없기 때문에 datetime오브젝트로 변환해 주어야 한다.=> to_datetime 메서드
- 문자열을 datetime 오브젝트로 변환하기
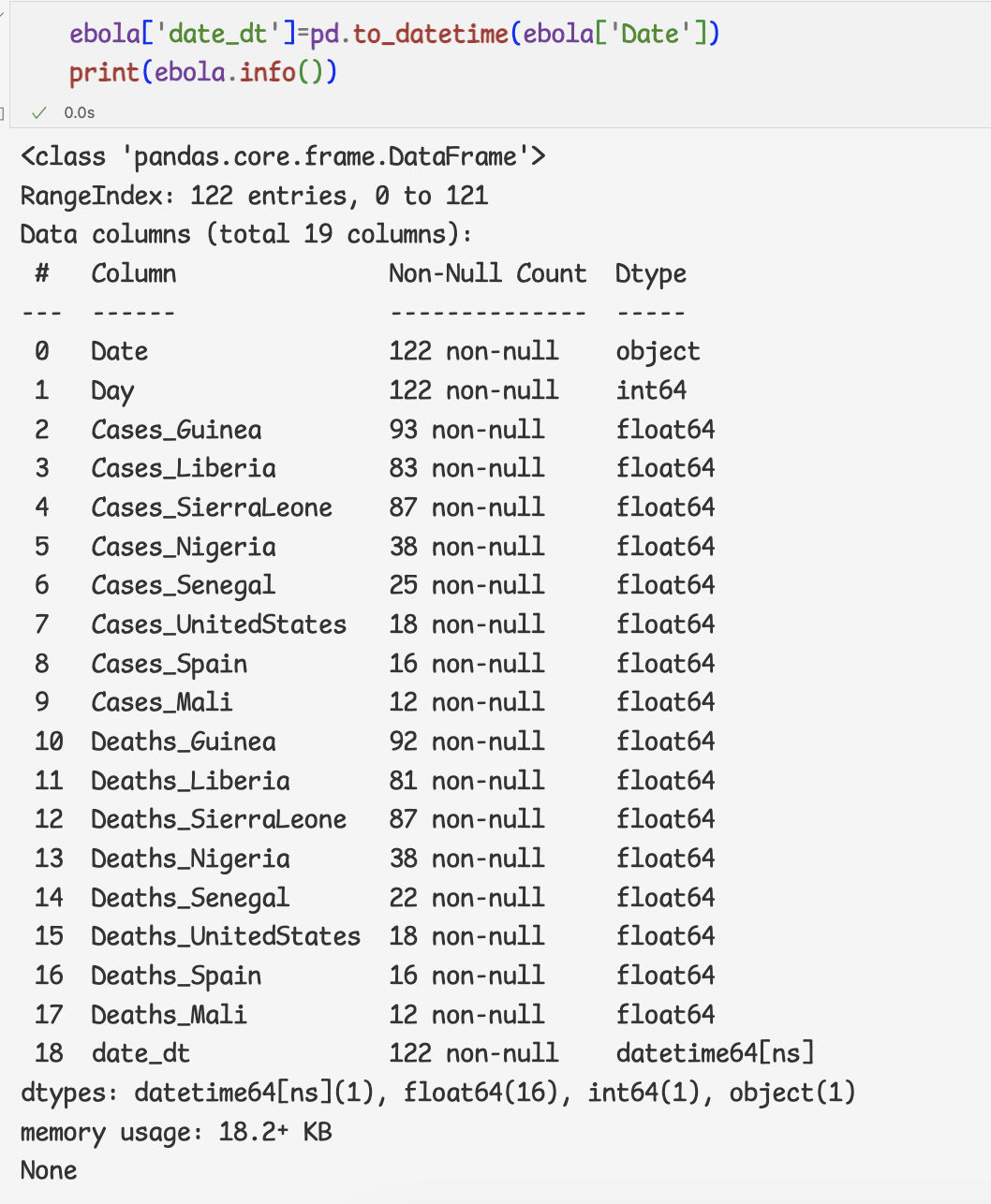
=> 문자열로 저장된 Date 열이 있는 것을 알 수 있다.
to_datetime 메서드를 사용하여 Date열의 자료형을 datetime오브젝트로 변환한 다음 새로운 열로 추가한다.
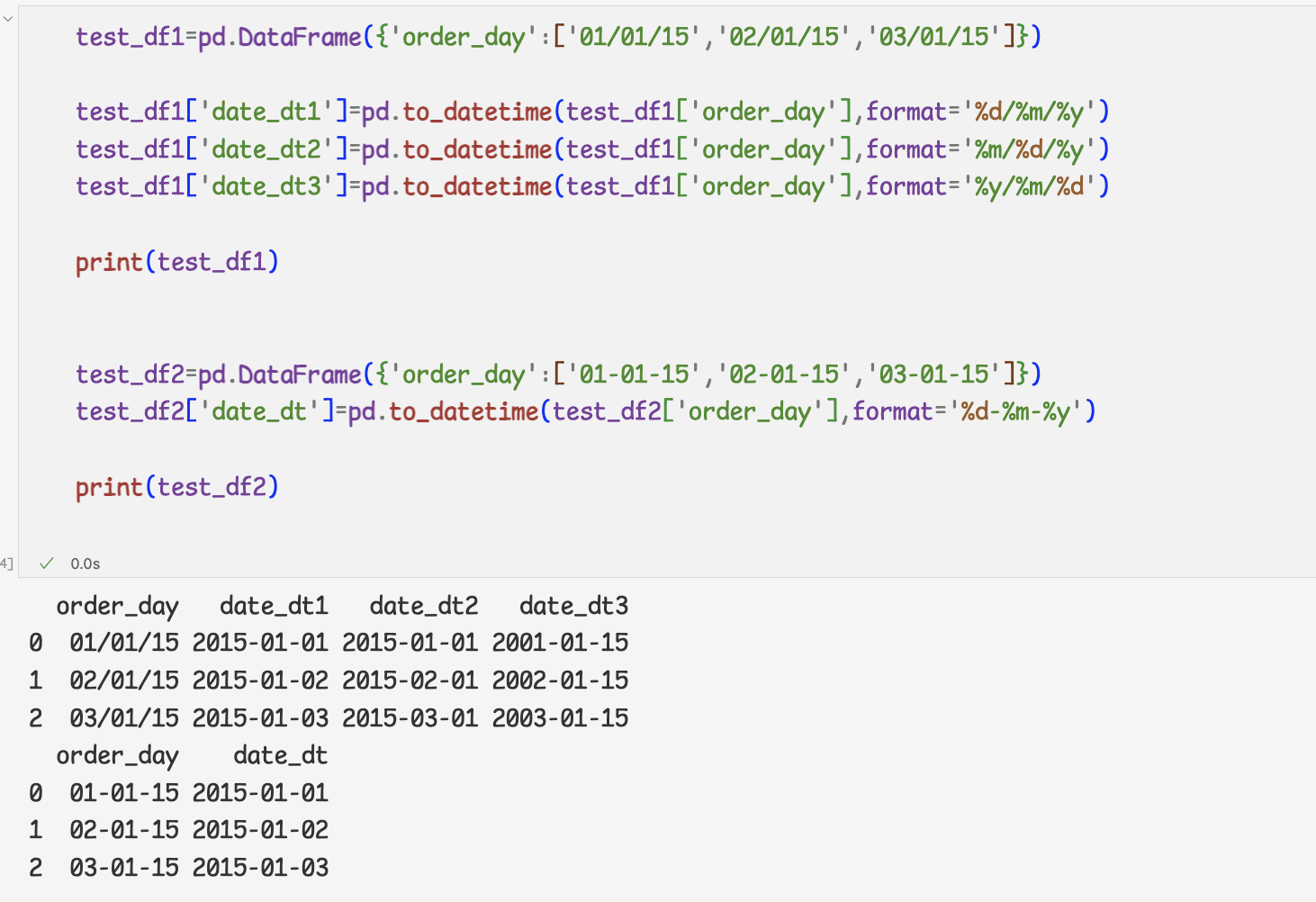
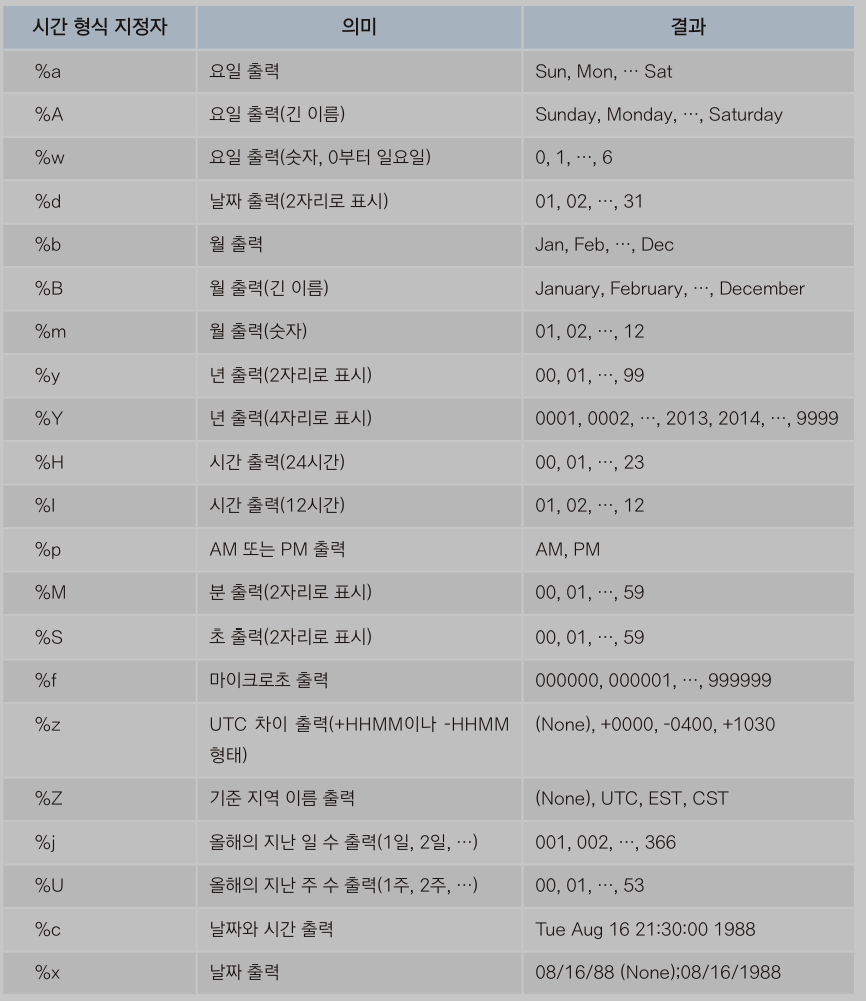
to_datetime메서드 ,format 인자
시간 형식 지정자
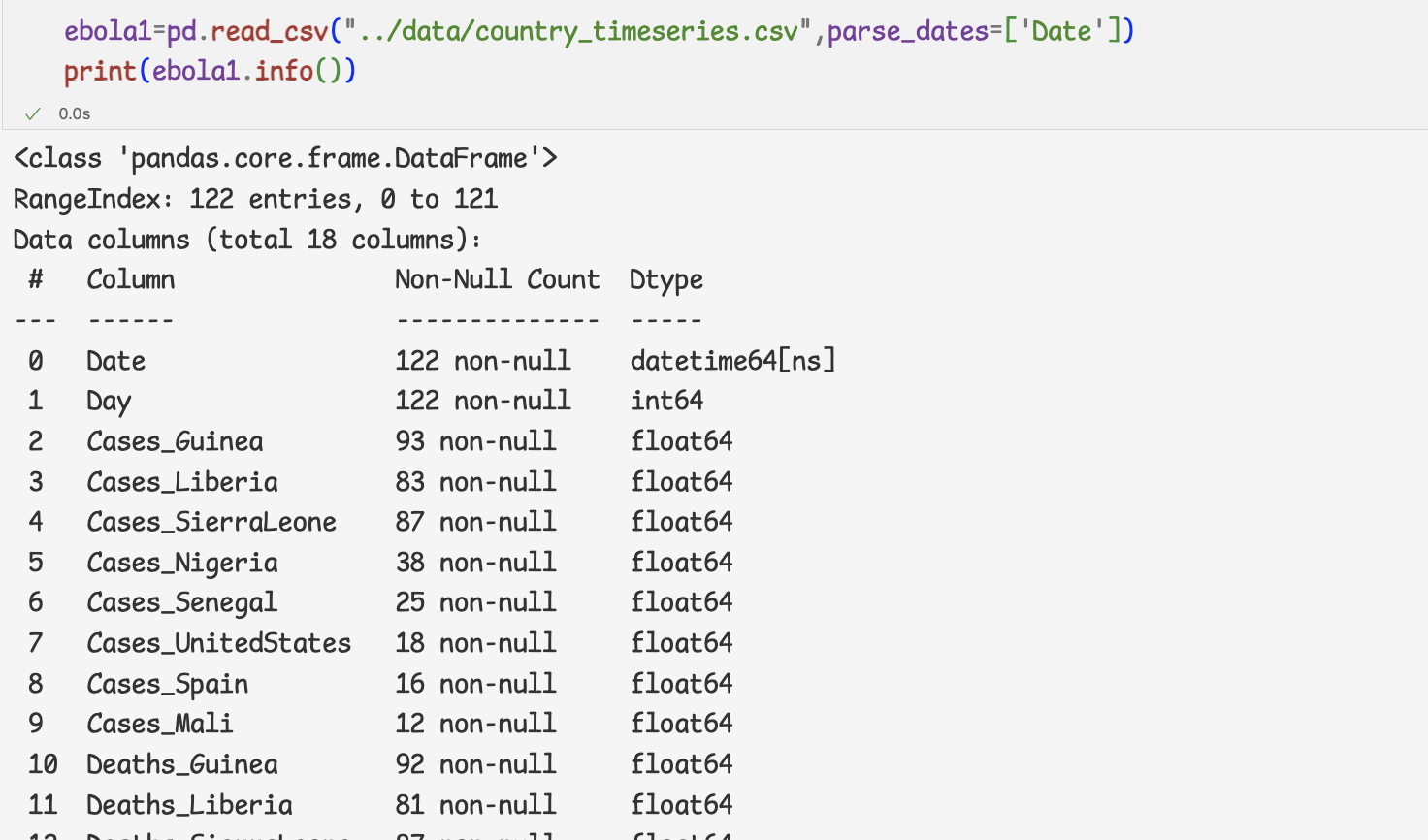
datetime 오브젝트 변환하기 -read_csv메서드
- datetime 오브젝트로 변환하려는 열을 지정하여 데이터 집합 불러오기
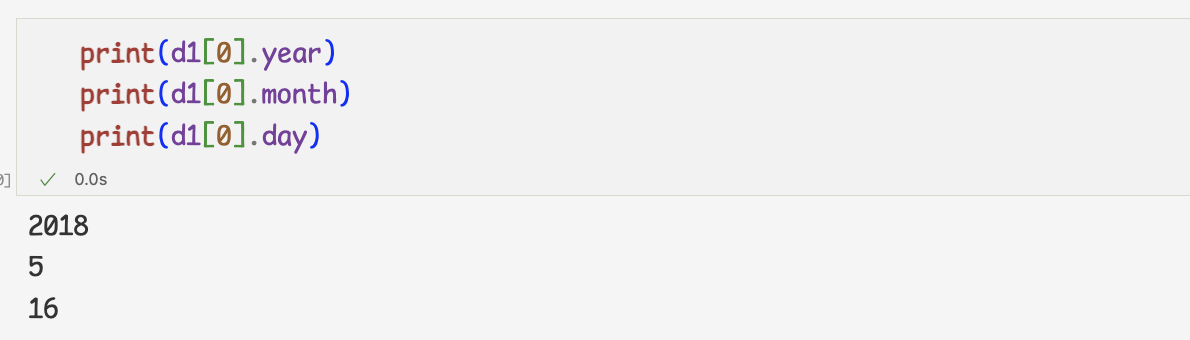
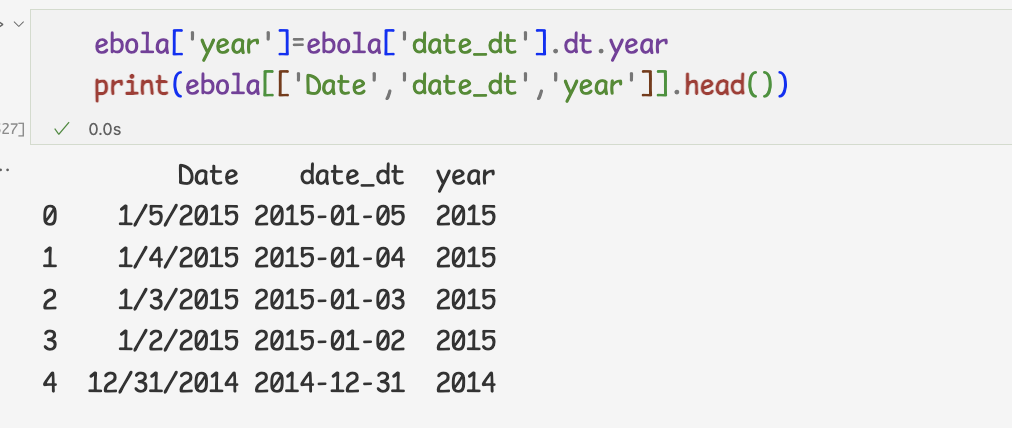
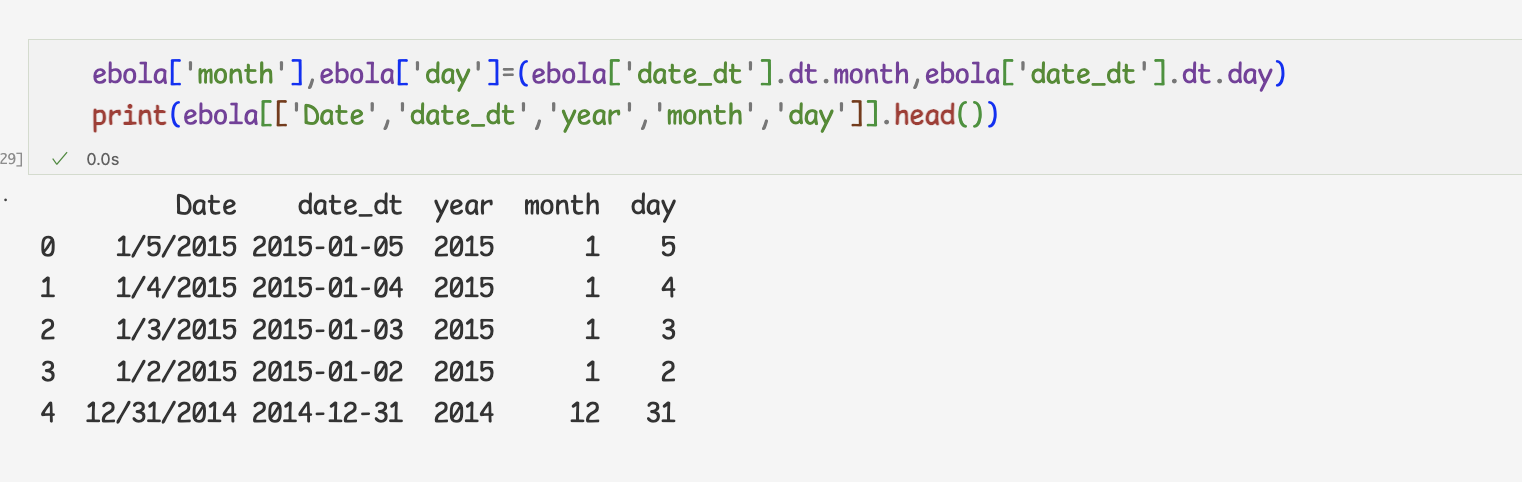
datetime 오브젝트에서 날짜 정보 추출하기1 ) 다음은 문자열로 저장된 날짜를 시리즈에 담아 datetime으로변환
2 ) datetime 오브젝트의 year,month,day 속성을 이용하면
년,월,일 정보를 바로 추출할 수 있다.
df 접근자 사용하기
문자열을 처리하려면 str 접근자를 사용한 다음 문자열 속성이나 메서드를 사용해야함
datetime 오브젝트도 dt 접근자를 사용하면 datetime속성,메서드를 사용하여 시계열 데이터를 처리할 수 있습니다.
- dt 접근자로 시계열 데이터 정리하기
=>dt접근자를 사용하지 않고 추출한 것
위의 과정을 응용하여, 새로운 열로 추가
2-2.사례별 시계열 데이터 계산하기
에볼라 최초 발병일 계산하기
Date 열에서 에볼라의 최초 방병일을 빼면 에볼라의 진행 정도를 알 수 있다.
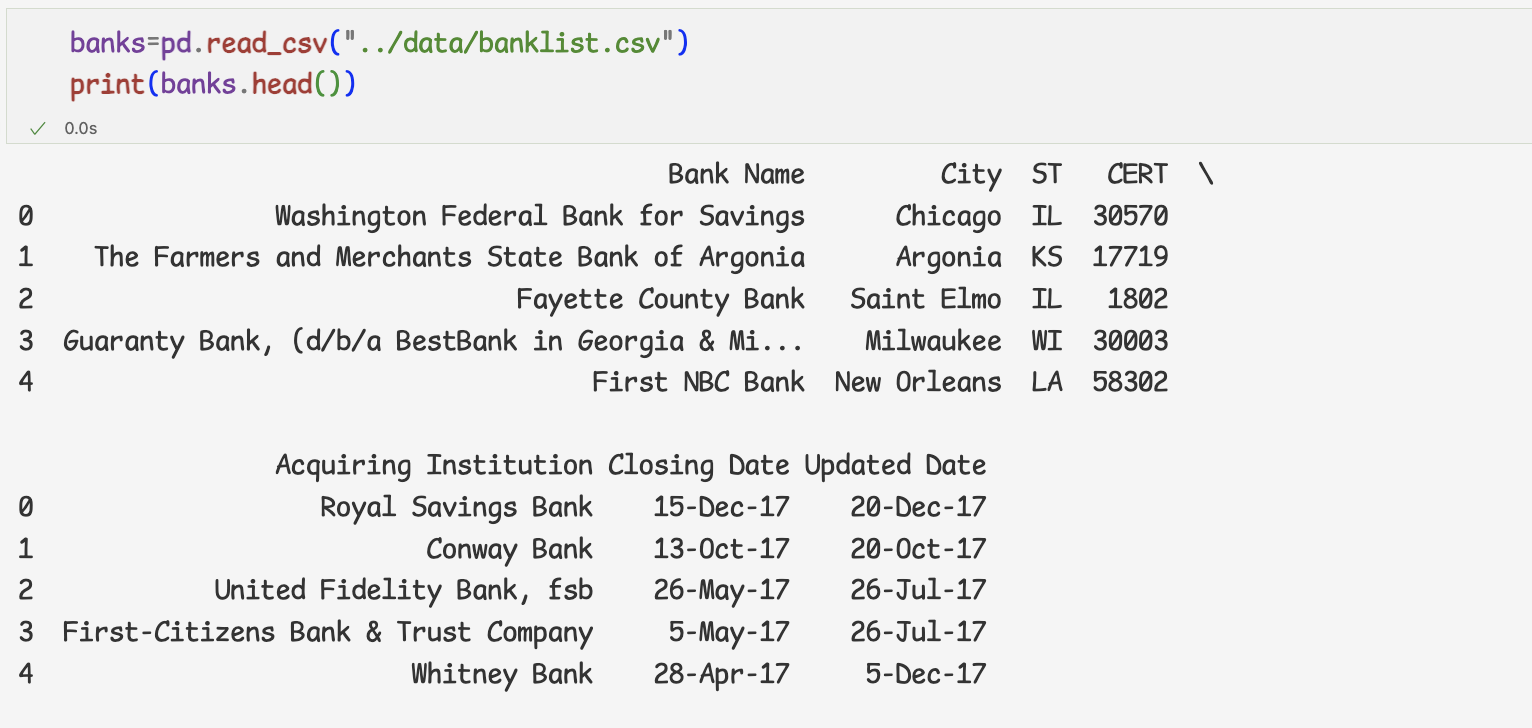
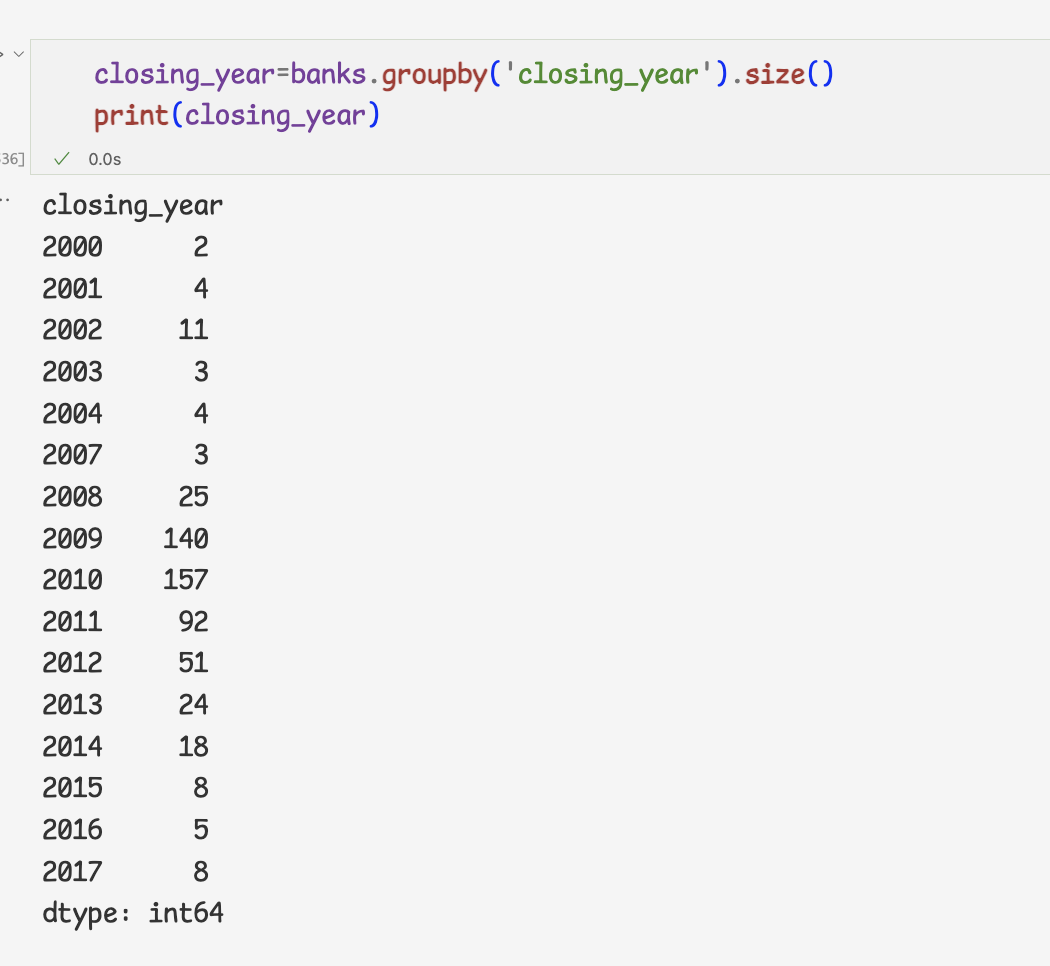
파산한 은행의 개수 계산하기
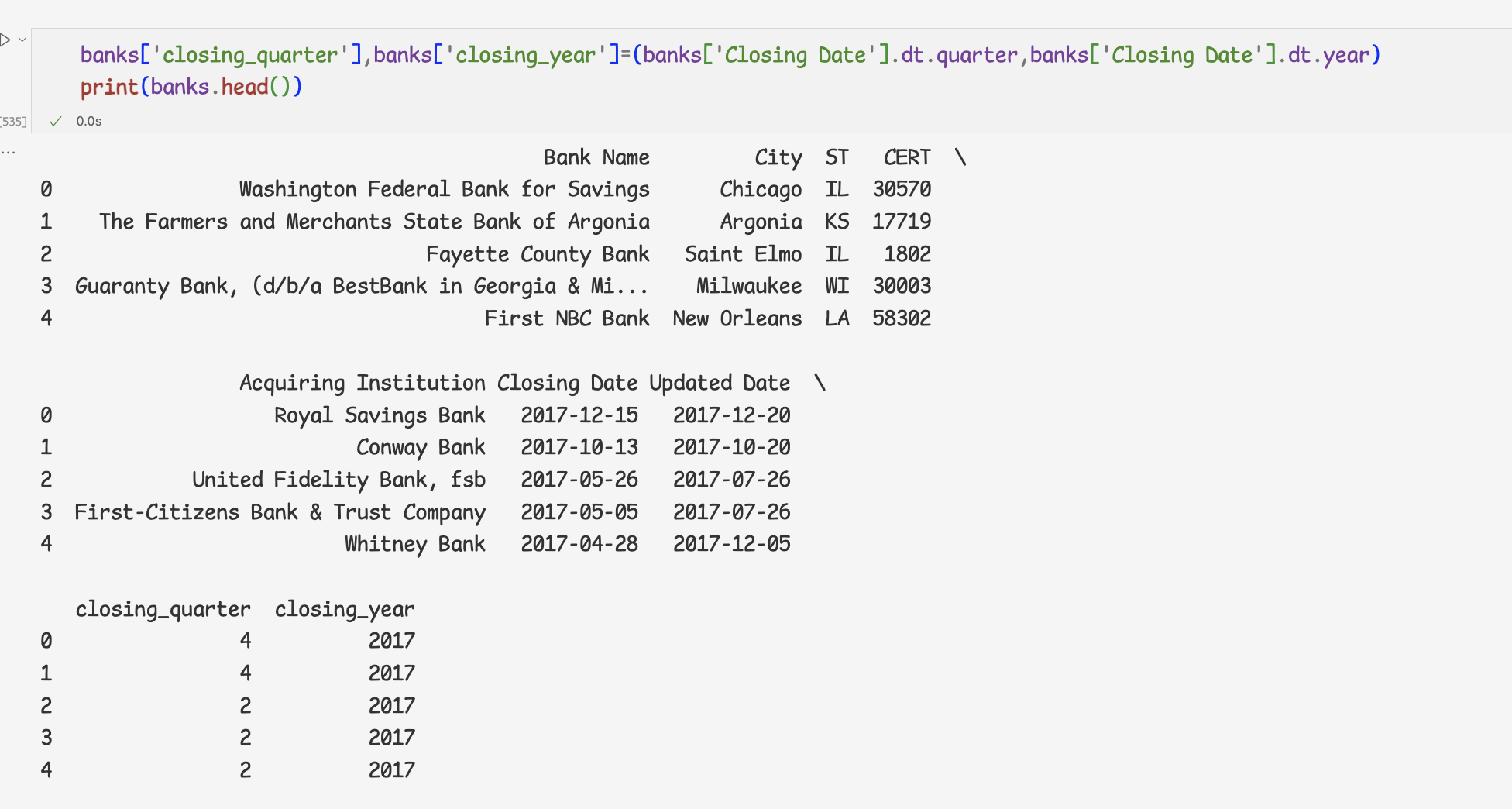
=> parse_dates 속성을 이용하여 문자열로 저장된 두열을 datetime오브젝트로 변환하여 불러온 것이다.
dt 접근자와 quarter 속성을 이용하면 파산 분기를 알 수 있다.
연도별로 파산한 은행의 갯수 구하기
연도별,분기별로 파산한 은행의 개수를 알아보자