[Pandas] 7-9
1.판다스 자료형
2.문자열 처리하기
3.apply 메서드 활용
1. 판다스 자료형
1-1.자료형 다루기
자료형 변환하기
- 자료형을 자유자재로 변환하기 - astype 메서드
여러 가지 자료형을 문자열로 변환하기
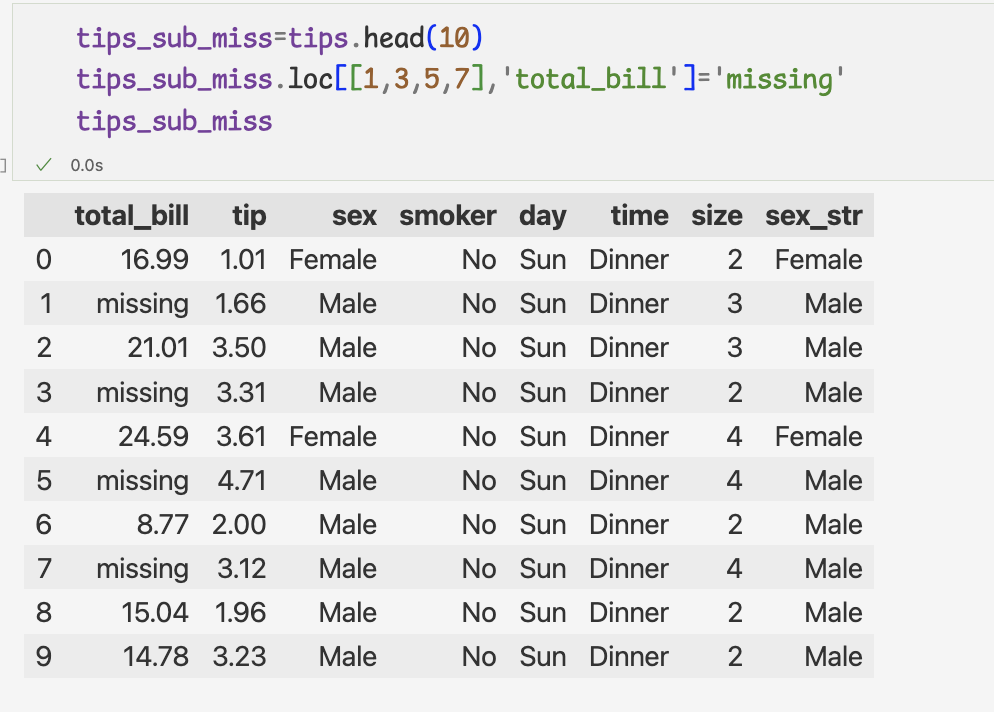
잘못 입력한 데이터 처리하기
- 잘못 입력한 문자열 처리하기 -to_numeric 메서드
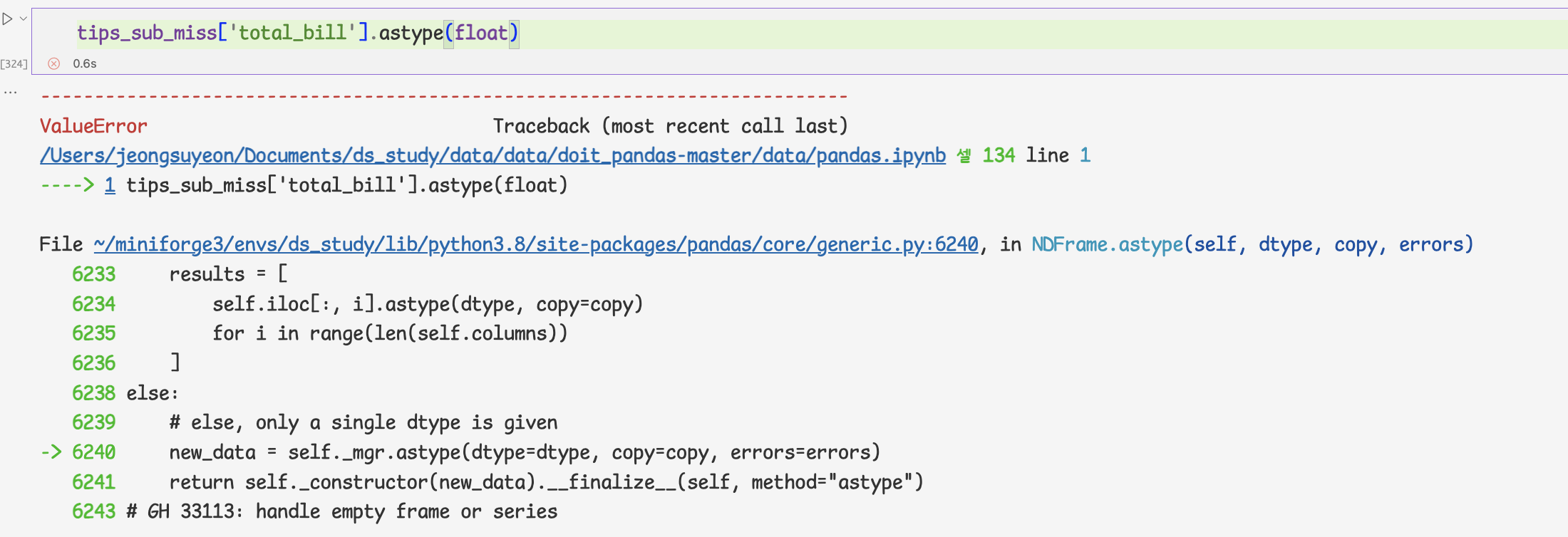
=> total_bill형이 실수가 아니라 문자열임을 알수 있다. 'missing'이라는 문자열 때문에 이런 문제 발생
- astype 메서드로 'total_bill'열의 데이터를 실수로 변환하면 오류 발생
=>판다스는 문자열을 실수로 변환하는 방법을 모르기때문
- to_numeric 메서드사용
=>비슷한 오류 발생
✳️ to_numeric 메서드를 사용해도 문자열을 실수로 변환할 수 없다.
to_numeric 메서드는 error인자에 raise,coere,ignore를 지정하여
오류를 어느 정도 제어할 수 있다.
errors 인자를 raise로 설정하면 숫자로 변환할 수 없는 값이 있을때만 오류 발생.✳️ errors 인자에 설정할 수 있는 값
-raise:숫자로 변환 할 수 없는 값이 있으므로 오류 발생
-coerce:숫자로 변환할 수 없는 값을 누락값으로 지정
-ignore:아무 작업도 하지 않음
- errors인자를 ignore로 설정하면 오류가 발생하지 않지만 자료형도
변하지 않는다. => 오류를 무시
=>여전히 문자열
- errors 인자를 coerec로 설정하면 누락값으로 바뀜
실수로 바뀜
- downcast 인자는 정수,실수와 같은 자료형을 더 작은 형태로 만들때 사용
downcast 인자에는 integer,signed,unsigned,float 등의 값으로 사용
=>float64에서 float32로 바뀜
만약 지정하는 실수의 예상 범위가 크지 않다면 다운캐스트하는 것이 좋다
1-2.카테고리 자료형
판다스 라이브러리는 카테고리라는 특수한 자료형이 있다.
- 카테고리: 유한한 범위의 값만을 가질 수 있는 자료형
ex)만약 10종류의 과일 이름을 저장할 열이 있다면, 문자열 자료형보다는
카테고리 자료형을 사용하는 것이 용량과 속도 면에서 효율적임
- 카테고리 자료형의 장점과 특징
-용량과 속도 면에서 매우 효율적
-주로 동일한 문자열이 반복되는 데이터를 구성하는 경우에 사용
문자열을 카테고리로 변환하기
=> 카테고리라는 자료형은 데이터의 크기가 커지면 커질수록 진가발휘
데이터프레임의 용량이 줄어듬

2.문자열 처리하기
2-1.문자열 다루기
파이썬과 문자열
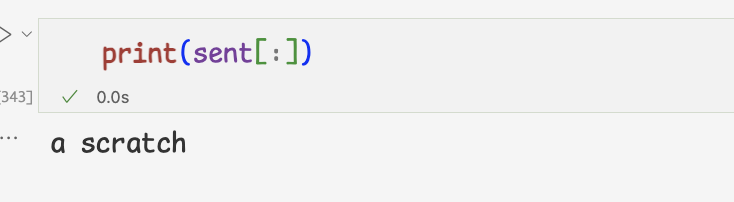
문자열은 작은따옴표나 큰따옴표로 감싸서 만든다.word='grail' sent='a scratch'
인덱스로 문자열 추출하기
문자열도 인덱스를 사용하여 추출할 수 있다.
문자열 추출하기1 ) 문자열의 첫 번째 문자 추출
2 ) 인덱스 슬라이싱을 사용하면 여러 개의 문자를 한번에 추출
3 ) 음수를 사용해도 문자열을 추출할 수 있다.
=>전체 문자열을 추출할때 음수를 사용하면 안됨.
전체 문자열 추출하기1 ) 왼쪽 범위를 비우고 문자열 추출
2 ) 오른쪽 범위를 비우면 문자열의 마지막 위치까지 문자열 추출
3 ) 양쪽 모두 비우면 전체 문자열 추출
4 ) 문자열을 일정한 간격으로 건너뛰며 추출 :콜론 추가
2-2.문자열 메서드
문자열 메서드
- capitalize :첫 문자를 대문자로 변환
- count:문자열의 개수를 반환
- starswith:문자열이 특정 문자로 시작하면 참이 된다
- endswith:문자열이 특정 문자로 끝나면 참이 된다
- find:찾을 문자열의 첫 번째 인덱스 반환 ,실패 시 -1 반환
- index:find메서드와 같은 역할을 수행하지만,실패 시 ValueError 반환
- isalpha:모든 문자가 알파벳이면 참
- isdecimal:모든 문자가 숫자면 참
- isalnum:모든 문자가 알파벳이거나 숫자면 참
- lower:모든 문자를 소문자로 변환
- upper:모든 문자를 대문자로 변환
- replace:문자열의 문자를 다른 문자로 교체
- strip:문자열의 맨 앞과 맨 뒤에 있는 빈 칸을 제거
- split:구분자를 지정하여 문자열을 나누고,나눈 값들의 리스트를 반환
- partition:split 메서드와 비슷한 역할을 수행하지만 구분자도 반환
- center:지정한 너비로 문자열을 늘이고 문자열을 가운데 정렬
- zfill :문자열의 빈 칸을 '0'으로 채운다.
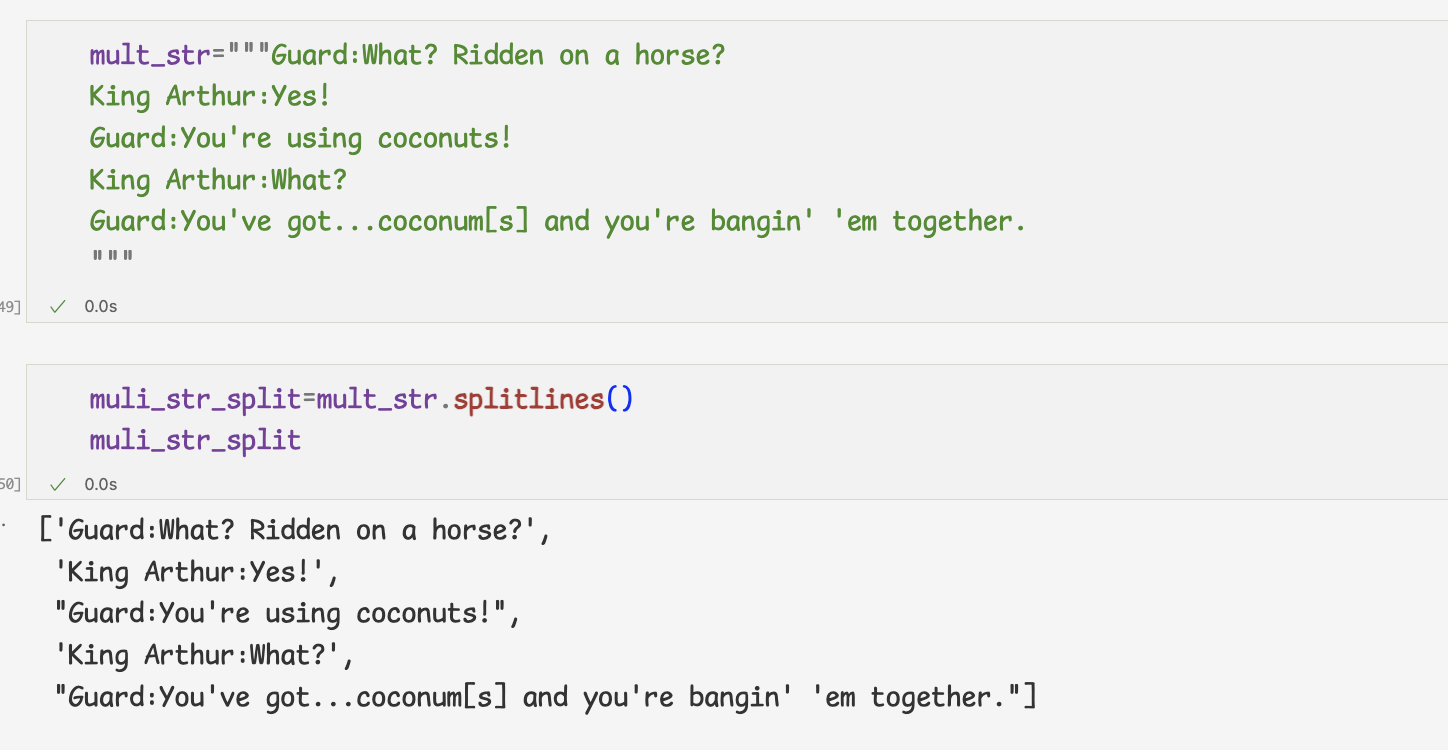
join,splitlines,replace메서드 실습하기1 ) join 메서드
문자열을 연결하여 새로운 문자열을 반환하는 메서드
2 ) splitlines 메서드
여러 행을 가진 문자열을 분리한 다음 리스트로 반환
3 ) 인덱스 슬라이싱을 응용하면 특정 문자열만 가져올 수 있다.
4 ) replace 메서드
2-3.문자열 포매팅
문자열 포매팅은 문자열을 편리하게 출력할 수 있게 해주는 기능
=>즉, 출력할 문자열의 형식을 지정하거나 변수를 조합하여 출력하는 방법
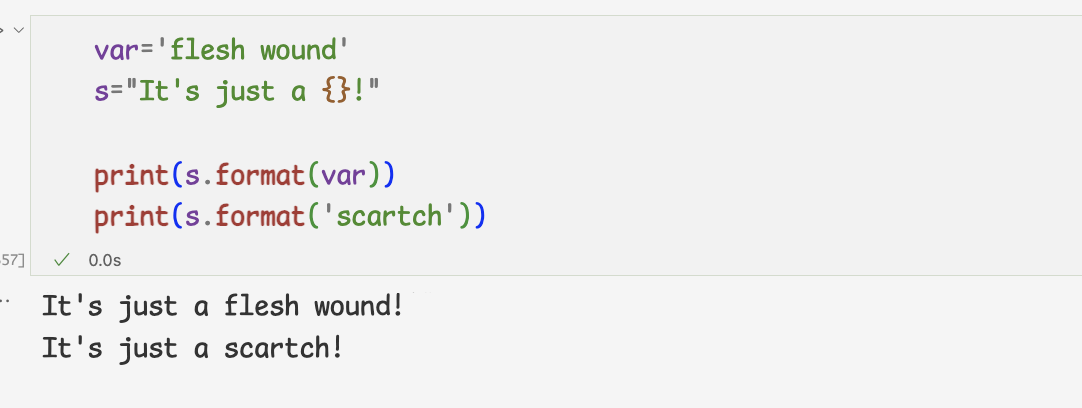
문자열 포매팅하기1 ) 단어를 삽입할 위치를 {}로 지정하고,format에 원하는 단어를 전달
{}를 플레이스 홀더라고한다.
2 ) 플레이스 홀더는 여러 번 사용해도 된다.
여러 단어를 전달할려면 인덱스 개념 응용
3 ) 플레이스 홀더에는 변수를 지정해도 된다.
단,format 메서드에 전달하는 문자열도 변수에 담아 전달해야 함
숫자 데이터 포매팅하기1 ) 숫자 데이터도 플레이스 홀더를 사용할 수 있다.
2 ) 플레이스 홀더에 ",를 넣으면 쉼표를 넣어 숫자를 표현할 수 있다
3 ) 소수는 다양한 방법으로 포매팅 할 수 있다.
4.format의 0번째 값을 5자리의 수로 표현하되 0으로 채워 출력
%연산자로 포매팅하기1 ) 삽입할 값이 10진수라면 값을 삽입할 위치에 %d라고 입력해야 한다.
그 다음 %연산자를 이용하여 삽입할 값을 지정하여 출력2 ) 삽입할 값이 문자열이라면 값을 삽입할 위치에 %s라고 입력해야한다.
2-4.정규식으로 문자열 처리에 날개 달기
정규식이란
- 정규식 표현 - 문법,특수 문자
1 ) 기본 정규식 문법
- . : 문자 앞에 문자 1개가 있는 패턴을 찾는다
- ^ :문자열의 처음부터 일치하는 패턴을 찾는다.
- $ :문자열의 끝 부분부터 일치하는 패턴을 찾는다.
- *:n이후 숫자가 0개 이상인 패턴을 찾는다
- :n이후 숫자가 1개 이상인 패턴을 찾는다.
- ? :?앞의 문자가 있거나 없는 패턴을 찾는다.
- {m} :n이후 숫자가 m개 인 패턴을 찾는다.
- {m,n} :n이후 숫자가 m개 이상, n개 이하인 패턴을 찾는다.
- \ :*,?,+와 같은 특수 문자를 검색할 때 이스케이프 문자를 사용
- [] : []중 1개를 포함하고 나머지 문자열이 []뒤 패턴을 찾는다.
- | :a이나 b중 하나만 있는 패턴을 찾는다
- (): ()에 지정한 패턴을 찾을 때 사용
.a ^I like on$ n\d* n\d+ apple? n\d{2} n\d{2,4} \*,\?,\+ [cfh]all apple | application (\d+)-(\d+)-(\d+)2 ) 정규식 특수 문자
- \d :숫자 1개를 의미한다 == [0-9]
- \D :숫자 이외의 문자 1개를 의미 ==[^0-9]
- \s:공백이나 탭 1개 의미
- \S: 공백 문자 이외의 문자 1개 의미
- \w:알파벳 1개를 의미
- \W:알파벳 이외의 문자 1개를 의미 (한글,중국어)
3 ) 정규식 표현 - 메서드
정규식 메서드는 정규식 패턴을 사용하지 않아도 메서드를 호출하는 방법
=> 원하는 패턴의 문자열을 찾을 수 있도록 해줌정규식 메서드
- search:첫번째로 찾은 패턴의 양 끝 인덱스를 반환
- match: 문자열의 처음부터 검색하여 찾아낸 패턴의 양 끝 인덱스 반환
- fullmatch:전체 문자열이 일치하는지 검사
- split: 지정한 패턴으로 잘라낸 문자열을 리스트로 반환
- findall : 지정한 패턴을 찾아 리스트로 반환
- finditer: findall메서드와 기능이 동일하지만 iterator를 반환
- sub: 첫 번째 인자로 전달한 값을 두번째 인자로 전달한 값으로 교체
정규식으로 전화번호 패턴 찾기
- match 메서드를 사용하여 길이가 10인 숫자를 확인하기
pattern 인자에는 10개의 숫자를 의미하는 10개의 \d를,
string에는 테스트용 문자열인 tele_num 전달
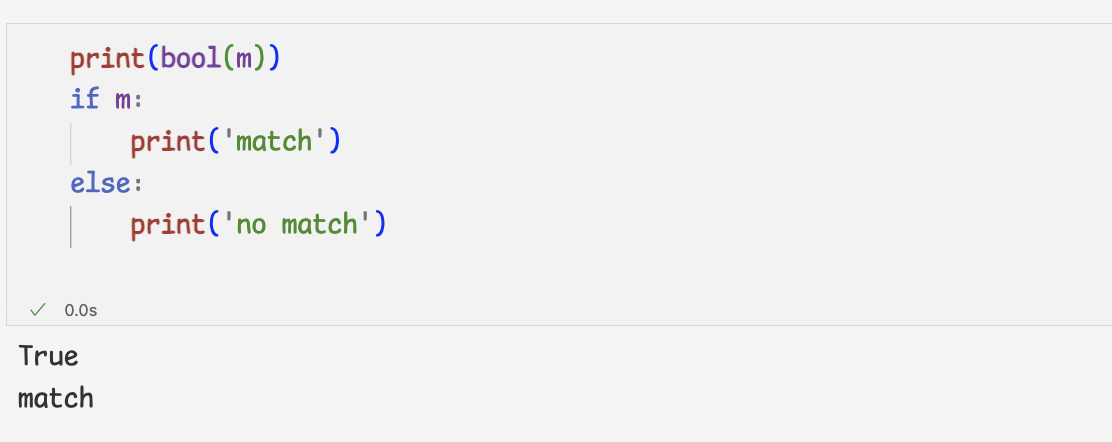
만약 패턴을 찾으면 Match 오브젝트 반환
Match오브젝트를 출력하면 span에는 찾은 패턴의 인덱스가,
match에는 찾은 패턴의 문자열이 있는 것을 확인
- bool 메서드에 m을 전달하면 True나 False얻을 수 있다.
즉, match메서드가 반환한 Match오브젝트는 bool메서드로 t/f 판단
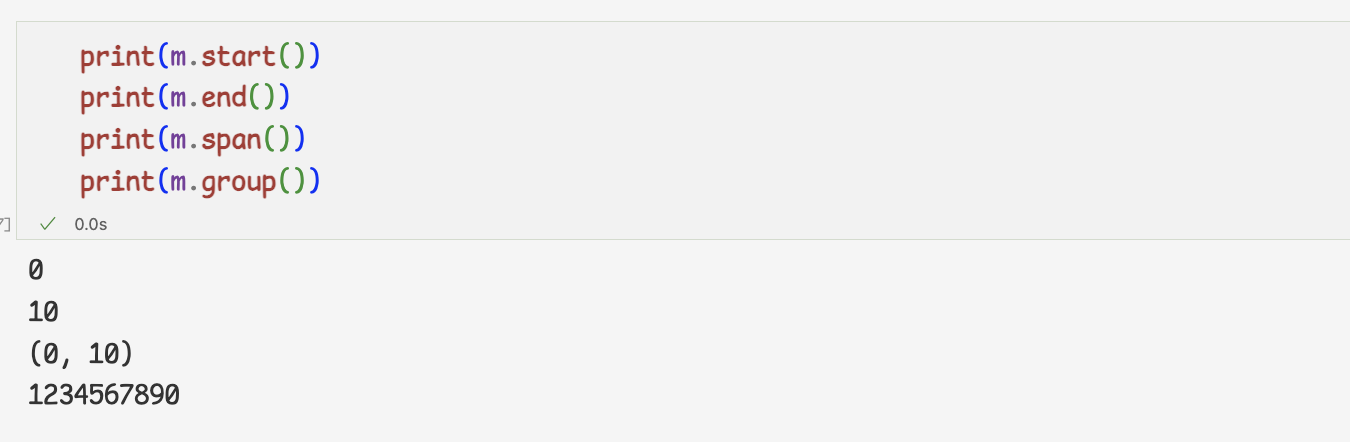
- Match 오브젝트에는 찾아낸 패턴의 정보를 확인할 수 있는 다양한 메서드o
start 와 end메서드: 첫번째와 마지막 인덱스 반환
span 메서드: 찾은 패턴의 첫번째와 마지막 인덱스를 한번에 반환
group메서드 : 찾아낸 패턴 반환
- 전화번호를 입력하는 방법은 1234567890아 아니라
123-456-7890 이나 123 456 789 같은 방법도 있다.
=>앞에서 사용한 패턴을 적용하면 None을 출력 (패턴 찾지 못함)
- 위의 문제를 해결하려면 정규식을 다시 작성해야 한다.
다음과 같이 빈 칸을 의미하는 정규식 \s를 넣어 패턴을 다시 만든다
- 지역 코드는 소괄호로 감싸고 나머지 번호는 반각 기호로 구분한 전화번호의 정규식은 다음과 같이 작성한다.
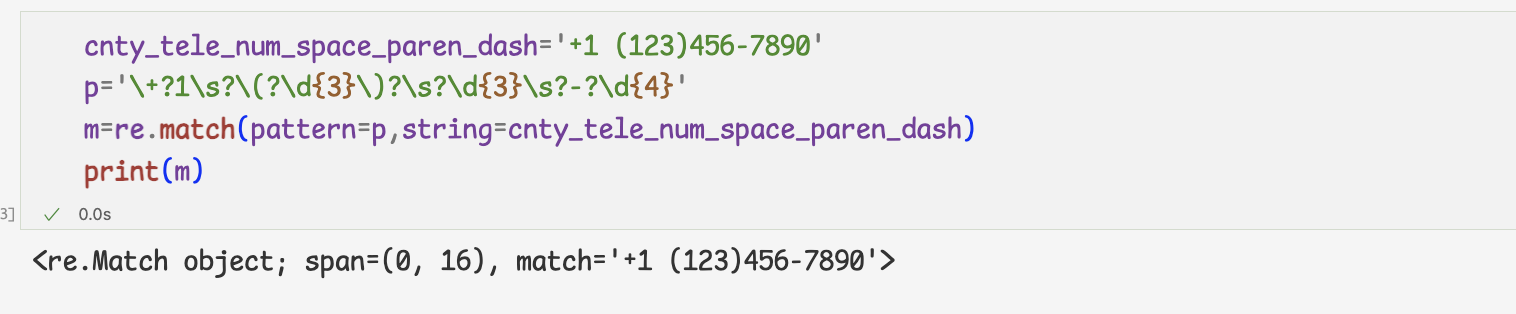
- 국가 코드까지 있는 전화번호의 정규식은 다음과 같이 작성한다.




















3.apply 메서드 활용
3-1.간단한 함수 만들기
제곱 함수와 n제곱 함수 만들기# 제곱함수 def my_sq(x): return x**2 # n 제곱 함수 my_exp def my_exp(x,n): return x**n print(my_sq(4)) 16 print(my_exp(2,4)) 16
3-2.apply메서드 사용하기 -기초
시리즈와 데이터프레임에 apply메서드 사용하기1 ) 시리즈와 apply 메서드
=>실습에 사용할 데이터프레임 준비
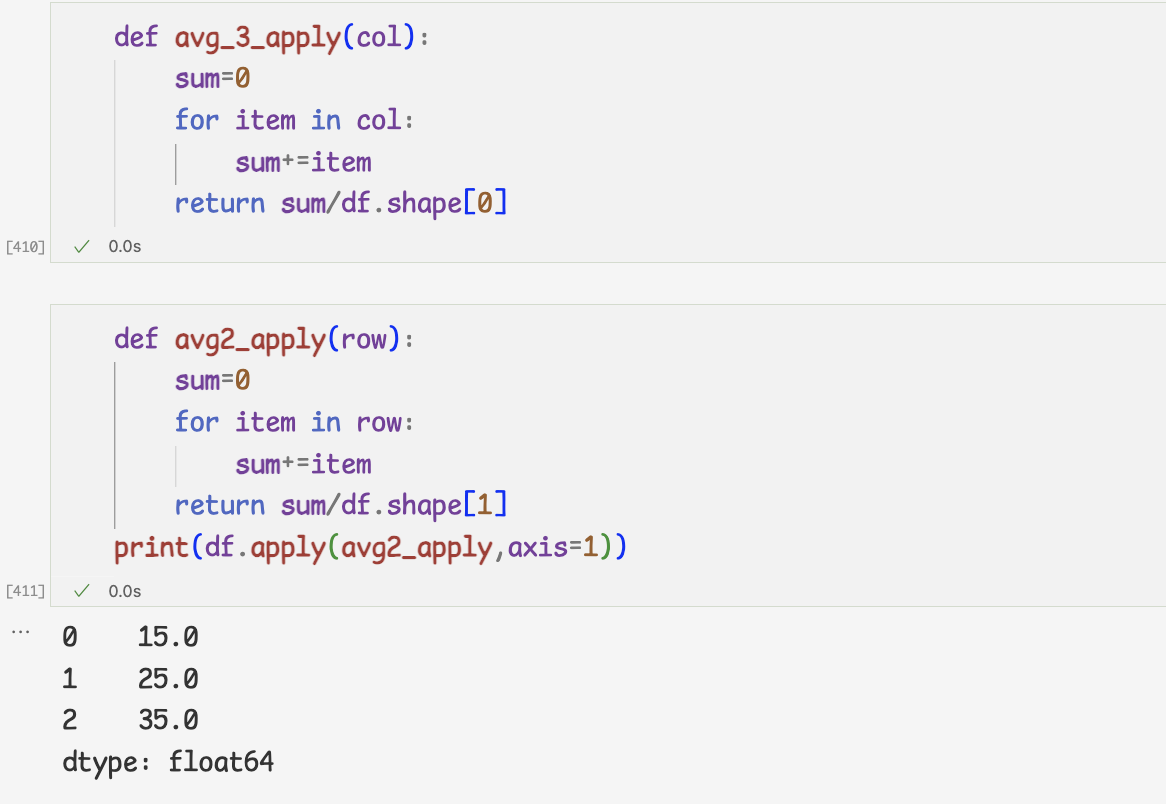
2 ) 'a'열을 제곱하여 얻는 결괏값과 apply메서드를 적용한 결괏값 비교
3) 2개의 인자를 전달받아야 하는 n 제곱 함수와 apply메서드를 함께 사용
apply메서드의 첫번째 인자에는 n제곱 함수의 이름을 전달하고
두번째 인자에는 n제곱 함수의 두번째 인자를 전달
=>df['a']의 값이 my_exp 함수의 첫번째 인자로 넘어간다.
4 ) 데이터프레임과 apply 메서드
=>데이터프레임 준비
=>1개의 값을 전달받아 출력하는 함수
=>데이터프레임에 함수를 적용해야 하기 때문에 axis값으로 열방향 혹은 행 방향으로 적용할지 정해야한다.
=>만약 axis값을 지정하지 않으면 열방향(0)으로 함수로 적용한다.
3개의 인자를 입력받아 평균을 계산하는 함수 사용
avg_3 함수를 apply메서드에 전달하면 3개의 인잣값을 필요로하는 함수인데 1개의 인잣값만 입력받았다는 오류 메세지 출력
=>avg_3 함수가 열 단위로 데이터를 처리할 수 있도록 수정해야 함
3-3.apply메서드 사용하기-고급
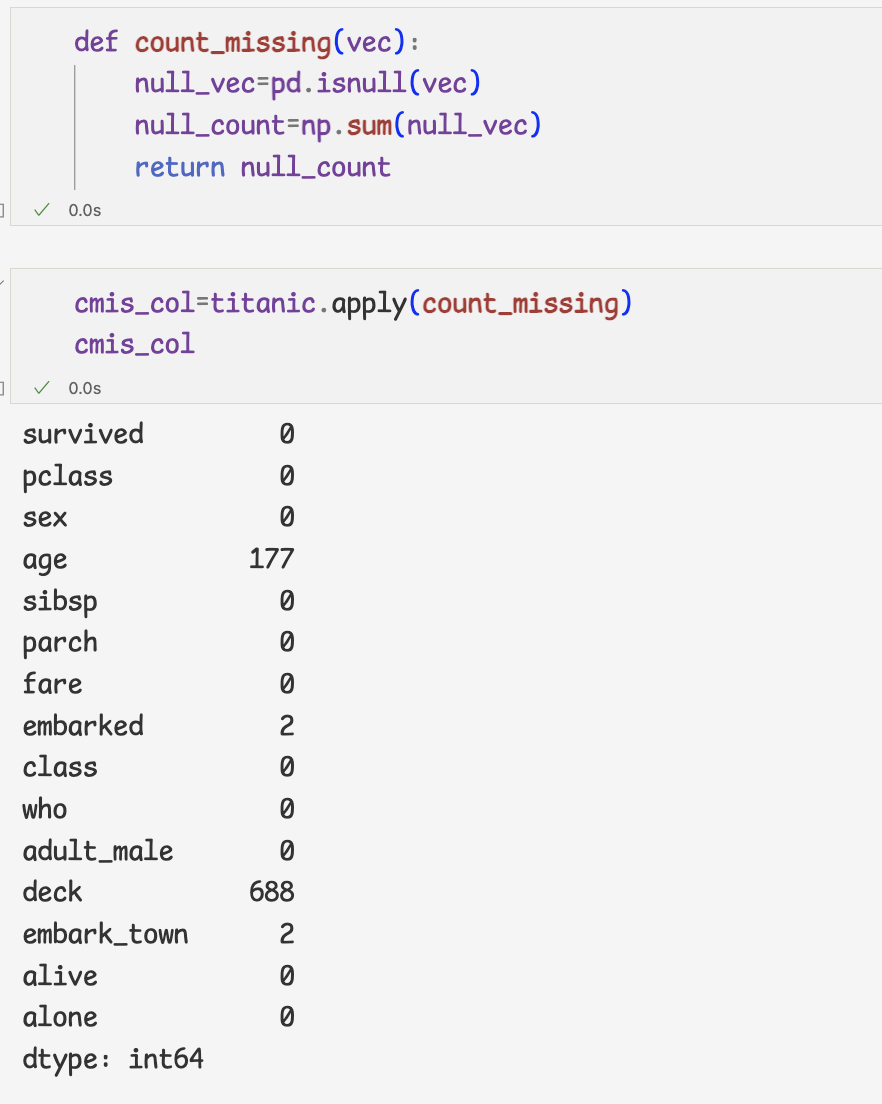
데이터프레임의 누락값을 처리한 다음 apply메서드 사용하기1 ) 데이터프레임의 누락값 처리하기 -열방향
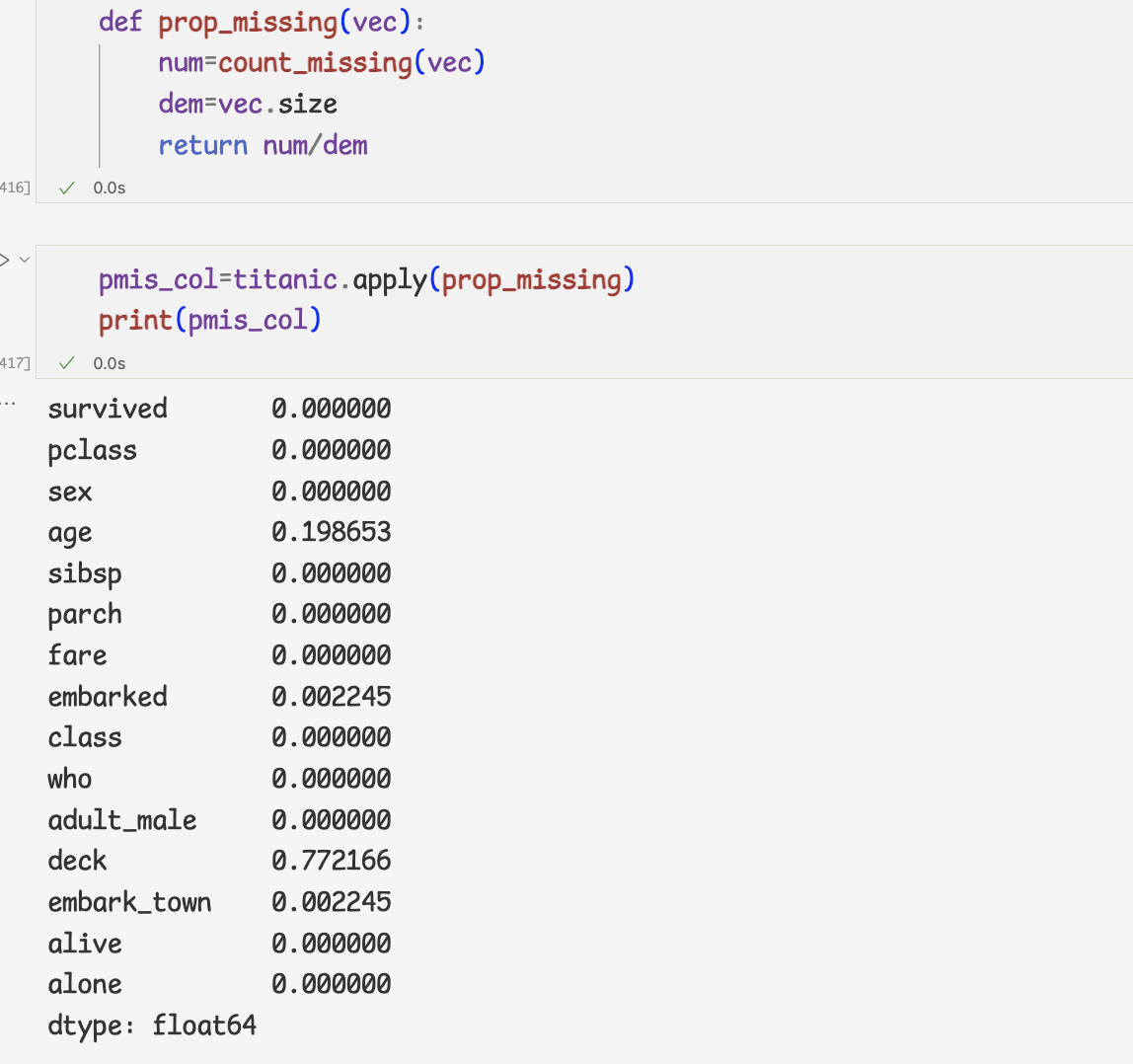
- 누락값의 비율을 계산하는 prop_missing 함수
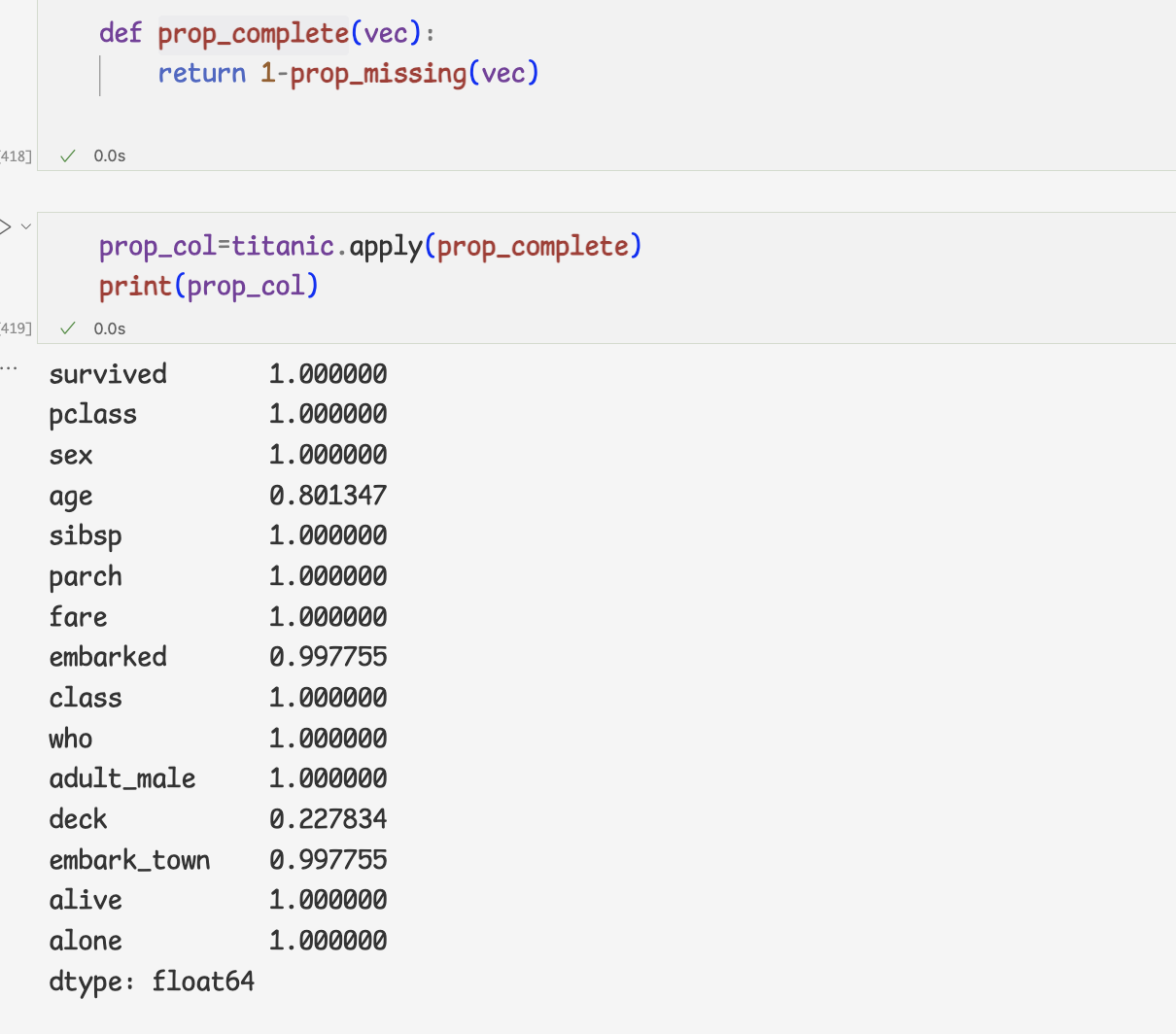
- 누락값이 아닌 데이터의 비율
데이터프레임의 누락값 처리하기 -행방향
누락값이 2개 이상인 데이터를 추출한 것