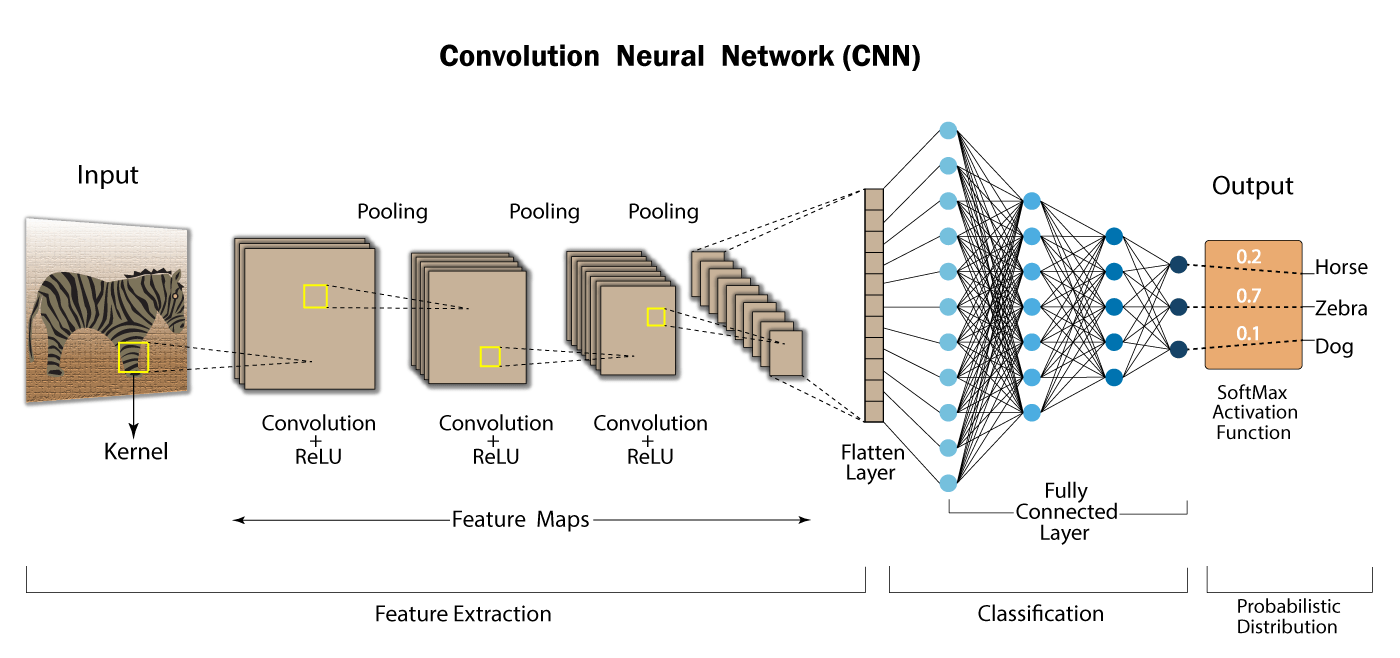
CNN이란?
CNN은 Convolution Neural Network의 줄임말이다. Convolution이란 합성곱이란 뜻으로, 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 구하는 수학 연산자 라고, 위키가 말했다. 무슨 소리일까.
쉽게 설명하면, 데이터에 마법의 도장을 찍어서 유용한 특성만 드러나게 하는 것이다.
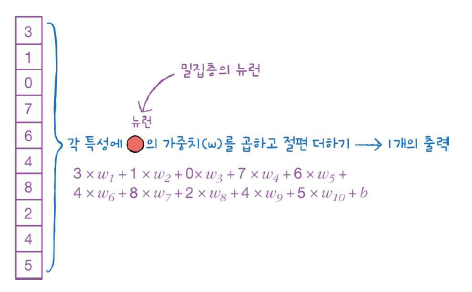
딥러닝의 밀집층에는 뉴런마다 입력 갯수만큼의 가중치가 있다. 즉, 모든 입력에 가중치를 곱한다.
인공 신경망은
- 가중치 w1~w10과 절편 b를 랜덤하게 초기화 한 다음,
- 에포크를 반복하면서 경사 하강법 알고리즘을 사용하여
- 손실이 낮아지도록 최적의 가중치와 절편을 찾아간다.
이것을 학습이라고 한다.
원래는 뉴런의 갯수만큼 출력이 있다. 입력 갯수에 상관없이,
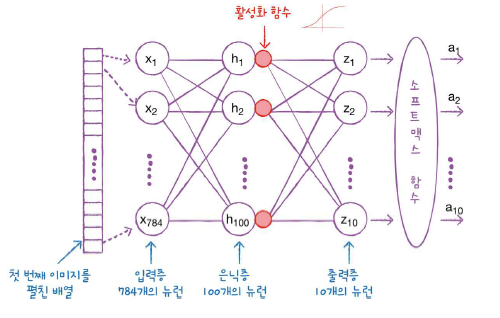
뉴런의 갯수가 100개면 출력도 100개가 된다.
하지만 합성곱은 다르다!
입력된 데이터 전체에 가중치를 적용하는 것이 아니라 일부에만 가중치를 곱한다.

가중치 w1~w3이 입력의 처음 3개 특성과 곱해져 1개의 출력을 만든다. 그런데 이 뉴런이 한 칸 아래로 이동해 두 번째부터 네 번째 특성과 곱해져 새로운 특성을 만든다.

그런데 중요한 건, 가중치와 절편은 똑같다. 똑같은 w1, w2, w3, b가 두 번째 합성곱에도 적용된다.
이런 식으로 한 칸씩 아래로 이동하면서 출력을 만드는 것이 합성곱이다. 여기는 뉴런의 가중치가 3개이기 때문에 8개의 출력이 만들어진다.
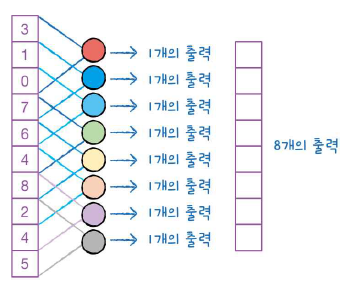
색은 다르지만 같은 뉴런이다. 같은 뉴런이라 함은, 같은 가중치와 절편을 가지고 있다는 뜻이다.
이렇듯 밀집층의 뉴런은 입력 갯수만큼 가중치를 가지고 1개의 출력을 만든다. 합성곱 층의 뉴런은 3개의 가중치를 가지고 8개의 출력을 만든다. 이는 마치 입력 데이터 위를 이동하면서 같은 도장(?)으로 하나씩 찍는 것처럼 이해해보면 쉽다. 도장을 찍을 때마다, 출력이 만들어지는 것이다.
합성곱 신경망은 뉴런을 필터 혹은 커널이라고 부른다.
합성곱의 장점은 1차원이 아니라 2차원에도 적용할 수 있다는 것이다.
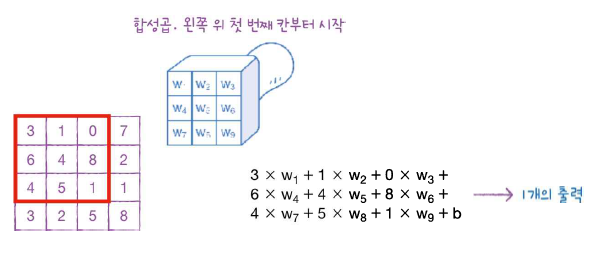
입력이 2차원이면 필터도 2차원이어야 한다. 필터의 크기는 하이퍼파라미터로, 우리가 조절할 수 있으니 (3,3)으로 가정하자.
왼쪽 위 모서리부터 합성곱을 시작한다.
입력의 9개 원소와 커널의 9개 가중치를 곱한 후 절편을 더한다. 1개의 출력이 만들어졌다.
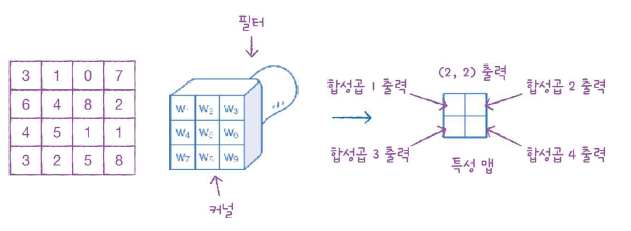
그리고 계속 순차적으로 진행해 나간다. 입력이 (4,4)였으므로 총 4번의 합성곱을 시행하게 된다. 이 때, 순서대로 입력에 놓인 위치에 맞게 2차원으로 출력을 배치한다.
마치 (4,4) 크기의 입력을 (2,2)로 축소한 것 같다.
합성곱 계산을 통해 얻은 출력을 특성 맵이라고 부른다.
합성곱 층도 물론 여러 필터를 사용할 수 있다.
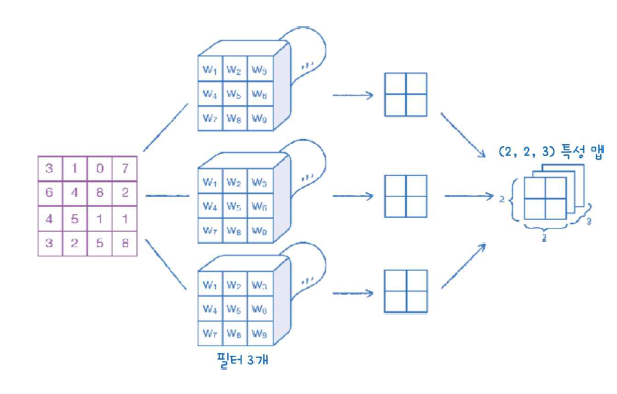
3번의 필터를 사용하면 다음과 같이 (2,2,3) 크기의 특성 맵을 사용할 수 있다.
다른 필터라면, 당연히 가중치와 절편 값도 다르다. 애초에 같은 가중치와 절편을 가진 필터를 여러개 사용할 필요는 없을 테니까!
이처럼 합성곱은 입력보다 훨씬 작은 크기의 커널(필터)을 사용하고 2차원 구조를 그대로 유지하기 때문에 이미지 처리에 유용하다.
케라스 합성곱 층
케라스의 층은 모두 keras.layer 패키지 아래 클래스로 구현되어 있다.
from tensorflow import keras
keras.layers.Conv2D(10, kernel_size=(3,3), activation='relu')저 첫 번째 변수 10은 필터의 개수다.
kernel_size 는 필터에 사용할 커널의 크기다.
그리고 활성화 함수의 종류를 지정해주면 된다.
특성 맵은 활성화 함수를 적용한 이후라고 생각하면 된다.
일반적으로 1개 이상의 합성곱 층을 사용한 인공 신경망을 합성곱 신경망이라고 부른다.
패딩
앞에서 우린 (4, 4)의 입력에 (3, 3)의 필터를 사용하여 (2, 2)의 출력을 얻었다.
그런데 만약 (3, 3)은 그대로 두고 출력의 크기를 입력과 동일하게 (4, 4)로 만들고 싶다면 어떻게 해야 할까?
그러려면 마치 더 큰 입력에 합성곱하는 척을 해야 한다.
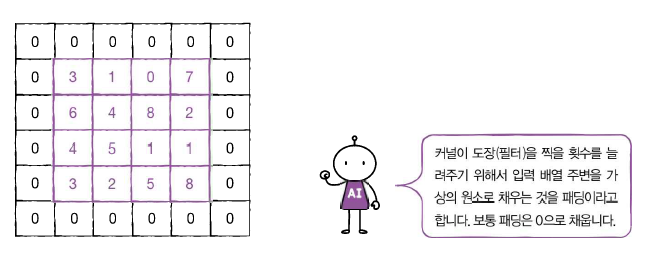
이렇게 말이다! 이 (6,6) 크기의 입력층을 (3, 3)의 커널(필터)로 찍어 보면 출력은 (4, 4)가 된다.
이렇게 입력 배열의 주위를 가상의 원소로 채우는 것을 패딩이라고 한다.
이건 그냥 커널이 도장을 찍을 횟수를 늘려 주는 역할만을 한다. 실제 값은 0으로 채워져 있기 때문에 계산에 영향을 미치지 않는다.
이렇게 입력과 특성 맵의 크기를 동일하게 만들기 위해 입력 주위를 0으로 패딩하는 것을 세임 패딩(same padding)이라고 한다.
이는 굉장히 많이 사용된다. 즉, 입력과 특성 맵의 크기를 동일하게 만드는 경우가 많다.
패딩 없이 순수한 입력 배열에서만 합성곱을 하여 특성 맵을 만드는 경우는 밸리드 패딩(Valid Padding) 이라고 한다. 이는 특성 맵의 크기가 줄어들 수밖에 없다.
패딩을 사용하는 이유는, 계산이 중복으로 되는 원소들과 그렇지 않은 원소들이 있기 때문이다. 그러면 모서리 쪽에 있는 중요할지도 모르는 정보가 특성 맵에 덜 전달될 것이다. 그리고 가운데에 있는 정보는 두드러지게 전달될 것이다.
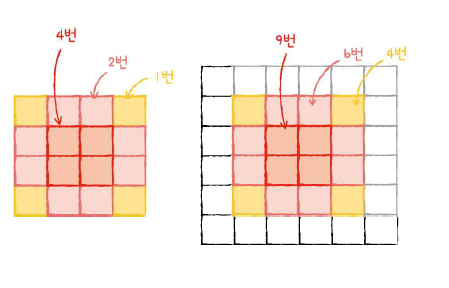
그림을 보면, 패딩을 하지 않을 경우 중앙 부분과 모서리 부분은 4배 차이가 나지만(4:1), 한 번 패딩을 하면 이 차이는 9:4로 줄어든다. 패딩을 한 픽셀 더 해주면 합성곱에 참여하는 비율이 동일해질 것이다.
고로, 적절한 패딩은 이미지 주변에 있는 정보를 잃어버리지 않도록 도와준다.
keras.layers.Conv2D(10,kernel_size=(3,3),activation='relu',padding='same',strides=1)케라스의 Conv2D는 Padding을 매개변수로 조절할 수 있다. 기본값은 valid이고, same으로 지정할 수 있다. 또, 몇 칸씩 건너뛸지도 정할 수 있다. 건너뛰는 칸이 커질수록 도장을 찍는 횟수는 줄어드므로 특성 맵의 크기는 작아질 것이다. 이런 이동의 크기를 스트라이드(stride)라 한다. 이 역시 하이퍼파라미터이며, 기본값은 1이고, 조절할 수 있다.
stride는 튜플로 값을 전달하여 오른쪽으로 이동하는 크기와 아래쪽으로 이동하는 크기를 다르게 지정할 수 있다. 그러나 그런 경우는 잘 없다. 그리고 보통 기본값을 사용한다.
풀링
풀링(pooling)은 합성곱 층에서 특성 맵의 가로세로 크기를 줄이는 역할을 수행한다. 그러나 특성 맵(필터)의 갯수를 줄이지는 않는다.
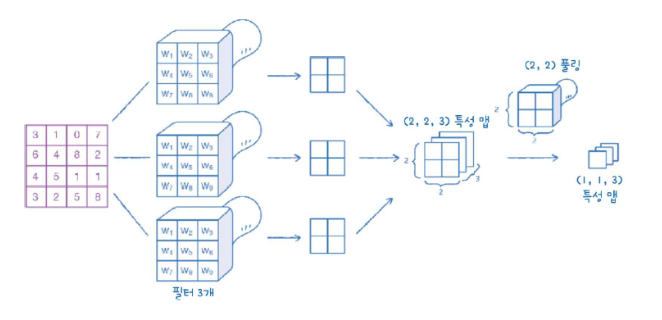
요롷게 말이다. 즉, (2, 2, 3)을 풀링하면 (1, 1, 3)이 된다.
풀링도 합성곱처럼 도장을 찍는다. 여기선 (2,2)로 풀링을 한다. 그러나 풀링에는 가중치가 없다. 도장을 찍은 영역에서 가장 큰 값을 고르거나 평균값을 계산한다.
이를 각각
최대 풀링 (max pooling)
평균 풀링 (average pooling)
이라 한다.
풀링은 합성곱 층과 뚜렷이 구분되기 때문에 풀링 층이라 부르자.
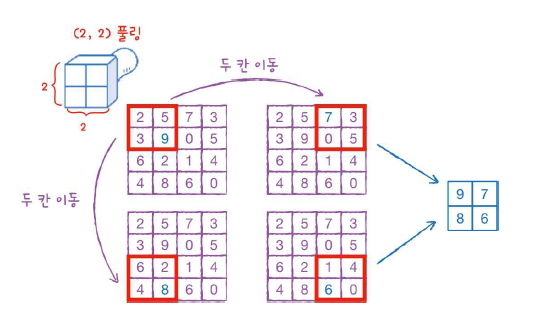
그림을 보면, 최대 풀링을 한 것이다. (2, 2) 풀링을 적용했다. 그랬더니 (4, 4) 입력이 (2, 2)로 크기가 줄어들었다.
특성 맵이 여러 개라면 동일한 작업을 반복한다. 즉, 10개의 특성 맵이 있다면 풀링을 거친 특성 맵도 10개가 될 것이다.
중요한 것은, 풀링 영역이 두 칸씩 이동했다는 것이다. 합성곱에서는 커널이 한 칸씩 이동했기 때문에 겹치는 영역이 있었다. 그러나 풀링에서는 겹치지 않고 이동한다. 따라서 풀링의 크기가 (2, 2)면 가로세로 두 칸씩 이동한다. 즉 스트라이드가 2다. (3, 3) 풀링이면 세 칸씩 이동한다.
keras.layers.MaxPooling2D(2)이렇게 적용해볼 수 있다.
대부분 풀링의 크기는 2로, 가로세로 절반씩으로 줄인다. 가로세로 방향의 풀링 크기를 다르게 할 수도 있지만, 그런 경우는 거의 없다.
strides와 padding 매개변수를 제공하지만, 바꾸지 않는다.
평균 풀링을 제공하는 클래스는
keras.layers.AveragePooling2D(2)로, 많은 경우 평균 풀링보다는 최대 풀링을 많이 사용한다. 평균 풀링은 특성 맵의 중요 정보를 평균하여 희석시킬 수 있기 때문이다.
합성곱 신경망의 전체 구조
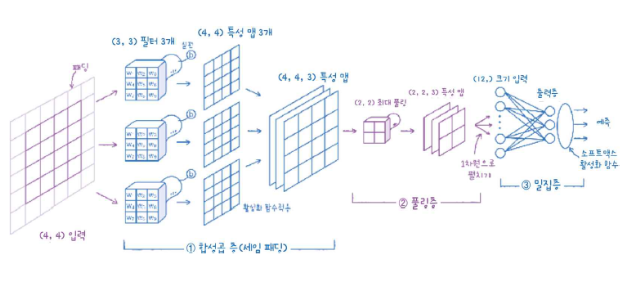
합성곱 층
합성곱 층(1)에서 사용할 커널의 크기는 (3, 3)으로 세임 패딩을 적용할 것이므로 주변에 1 픽셀이 추가되었다.
패딩이 추가된 입력에서 합성곱이 수행된다.
합성곱의 필터는 3개다. 각각 (3, 3) 가중치를 가지고 있다. 그리고 필터마다 가중치가 매달려 있다.
특성 맵의 크기는 (4, 4)(입력층과 같음), 3개의 필터가 합쳐져 (4, 4, 3)크기의 합성 맵이 만들어진다.
밀집층과 마찬가지로 합성곱 층에서도 활성화 함수를 적용한다. 렐루 함수를 많이 사용한다.
풀링 층
그 다음에 풀링 층(2)이다.
풀링 층은 합성곱 층에서 만든 특성 맵의 가로세로 크기를 줄인다. 보통은 (2, 2) 풀링을 사용해 절반으로 줄인다. 특성 맵의 갯수는 변하지 않으므로 (2, 2, 3)이 된다.
풀링을 사용하는 이유는 합성곱에서 스트라이드를 크게 하여 특성 맵을 줄이는 것보다 풀링 층에서 크기를 줄이는 것이 경험적으로 더 나은 성능을 내기 때문이다.
합성곱 층은 이렇게 합성곱 층에서 특성 맵을 생성하고 , 풀링에서 크기를 줄이는 구조가 쌍을 이룬다.
밀집 층
이제 밀집층에 이걸 전달하려면 3차원 배열을 1차원으로 펼쳐야 한다. flatten을 사용하여 펼치면 (12,1)이 된다. 이 배열은 출력층의 입력이 된다.
출력층에는 3개의 뉴런을 둔 것을 보니, 3개의 클래스를 분류하는 다중 분류 문제다. 출력층에서 계산된 값은 소프트맥스 활성화 함수를 통해 최종 예측 확률이 된다.
컬러 이미지를 사용한 합성곱
여태 우리는 입력을 2차원 배열이라고 가정했지만 흑백이 아닌 컬러 이미지는 RGB로 구성되기 때문에 3차원 배열로 표시하게 된다.
너비와 높이 차원에 깊이 차원(채널 차원)이 있는 것이다.
즉, 앞의 예의 경우 (4, 4, 3)이 되는 것이다. 이러면 합성곱이 수행 될까?
깊이가 있는 입력에서 합성곱을 수행하려면 도장도 깊이가 필요하다. 즉, 필터의 크기가 (3, 3)이 아니라 (3, 3, 3)이 된다. 커널 배열의 깊이는 항상 입력의 깊이와 같다.
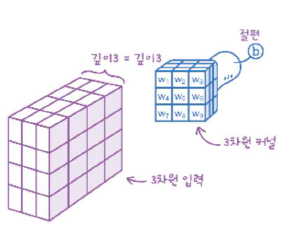
예를 들어, 이 합성곱의 계산은 (3, 3, 3)영역에 해당하는 27개의 원소에 27개의 가중치를 곱하고 절편을 더한다. 2차원 합성곱과 같지만 깊이만큼 쑥 들어가는 것이다.
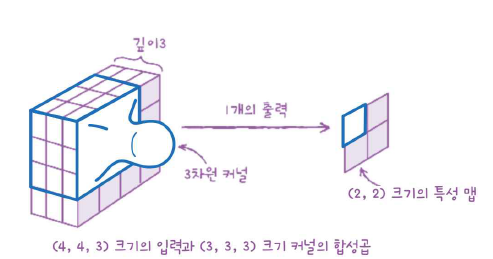
입력이나 필터의 차원이 몇 개인지 상관없이 출력은 항상 하나의 값이다. 즉, 특성 맵에 있는 한 원소가 채워진다.
사실 케라스의 디폴트 값은 3차원 입력이다. 흑백 이미지의 경우 (28, 28, 1)이런 식으로 차원을 맞춰 준다.
이와 비슷한 경우로는 합성곱 층 - 풀링 층 다음에 다시 또 합성곱 층이 올 때다.
예를 들어, 첫 번째 합성곱 층의 필터 갯수가 5개고, 첫 번째 풀링 층을 통과한 특성 맵의 크기가 (4, 4, 5)라고 가정해 보자.
그러면 두 번째 합성곱 층에서 필터의 너비와 높이가 각각 3이라면 이 필터의 커널 크기는 (3, 3, 5)가 된다.
왜? 입력의 깊이와 도장의 깊이는 같아야 하니까!
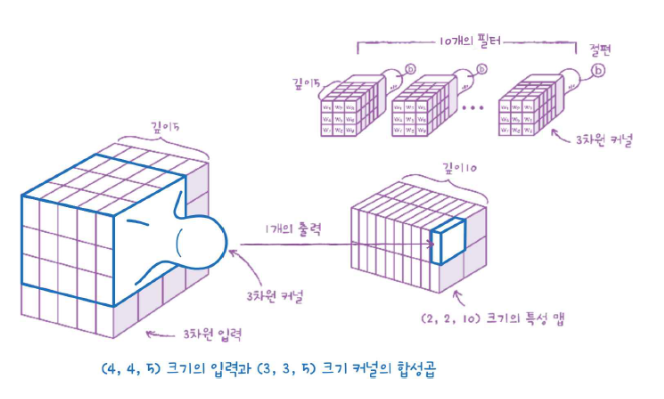
다음과 같이 3X3X5 = 45의 가중치를 곱하고 절편을 더한 이 합성곱의 결과는 1개의 출력을 만든다.
두 번째 합성곱 층의 필터 갯수가 10이라면 특성 맵의 크기는 (2, 2, 10)이 될 것이다. 이렇게 합성곱 신경망은 너비와 높이는 점점 줄어들고 깊이는 점점 깊어지는 것이 특징이다. 그리고 마지막에 쫙 펼쳐서 밀집층의 입력으로 사용한다.
합성곱 신경망에서 필터는 이미지의 특징을 찾는다고 보면 된다.
처음에는 간단하게 기본적인 특징(직선, 곡선)등을 찾고 층이 깊어질수록 다양하고 구체적인 특징을 감지할 수 있도록 필터의 갯수를 늘린다. 또 어떤 특징이 이미지의 어느 위치에 놓이더라도 쉽게 감지할 수 있도록 너비와 높이 차원을 줄여가는 것이다.
