개요
EC2 로 서버를 하나 만들었다고 가정해보자. 해당 서버의 Throughput(시간당 처리량) 과 Latency (처리 시간) 을 알려면 어떻게 해야될까? 해당 서버에 부하가 걸릴만큼의 매우 많은 메세지를 전달해보면 알 수 있을 것이다. K6 를 사용하면 강제로 서버에 원하는 만큼의 Dummy 메세지 를 전달할 수 있고 AWS 에서는 EC2 의 성능 등의 정보를 확인할 수 있는 모니터링 정보 (Metric) 를 제공하고 있으므로 이번 글에서는 K6 를 활용해 EC2 에 부하를 가해보고 이에 변동되는 EC2 의 모니터링 정보 (Metrics) 를 확인해보려 한다.
간단한 개념
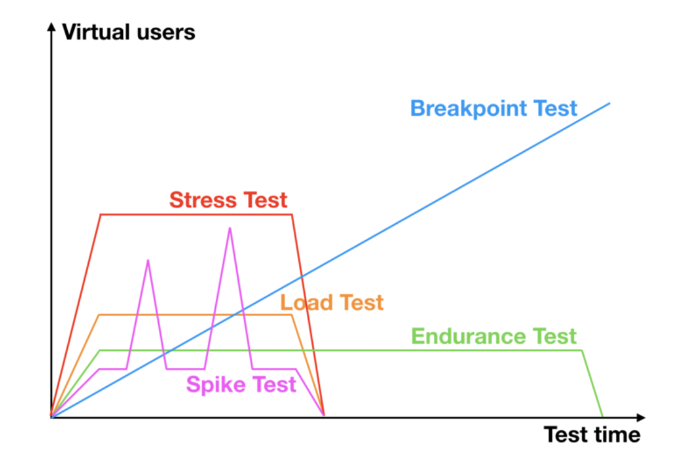
🔸 성능 테스트 종류
성능 테스트에는 몇가지 종류가 있다.
얼마만큼의 기간동안 , 얼마만큼의 부하를, 어느 시점 에 가했느냐에 따라 종류가 달라진다.
각각의 테스트를 통해 여러가지 원하는 성능 지표를 얻어낼 수 있을 것이다.

이미지 출처 : https://www.netsolutions.com/insights/performance-testing/
실습
EC2 서버 를 생성 및 실행시킨 뒤 K6 로 부하테스트 를 진행하는 순서로 진행하려 한다.
🔸 STEP 1: 서버 생성 및 실행
-
EC2 인스턴스 생성
t2.micro,ubuntu 20.04로 생성한다. -
SSH 접속
# ssh -i <key-pair> ubuntu@<인스턴스 퍼블릭 IP> $ ssh -i ~/.ssh/key.pem ubuntu@54.180.113.122 -
EC2 내 도커 설치
$ cat << EOF > install.sh #!/bin/sh #업데이트 및 HTTP 패키지 설치 sudo apt update sudo apt-get install -y ca-certificates \ curl \ software-properties-common \ apt-transport-https \ gnupg \ lsb-release # GPG 키 및 저장소 추가 sudo mkdir -p /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null # 도커엔진 설치 sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io EOF chmod 777 install.sh ./install.sh -
도커를 통한 서버 실행 및 접속 동작 확인
# 서버 이미지 실행 $ sudo docker run --name test -d -p 8080:80 httpd # 서버 동작 확인 $ curl http://localhost:8080 # 정상 결과 확인됨 <html><body><h1>It works!</h1></body></html>
🔸 STEP 2: K6 설치 및 실행
-
k6설치OS 별 설치 참조
주의 :EC2에 설치하면 정확한 모니터링 결과를 얻기는 힘들다. 각자 컴퓨터에서 설치하는 게 권장됨 관련 링크 이동# 우분투에 k6 설치 시 sudo apt update && \ sudo apt install snapd && \ sudo snap install k6 -
k6스크립트 실행# 스크립트 다운로드 git clone https://github.com/SangYunLeee/sprint_k6 cd sprint_k6 # 부하 테스트 진행 k6 run basic_test.js (laod test) k6 run spike_test.jsk6실행 시 아래와 같은k6실행 결과를 확인할 수 있다.

🔸 STEP 3: 테스트 결과 분석
-
Load 테스트 분석
10분간 초당 약 500건의 요청을 아래의 그림과 같이 보냈다.
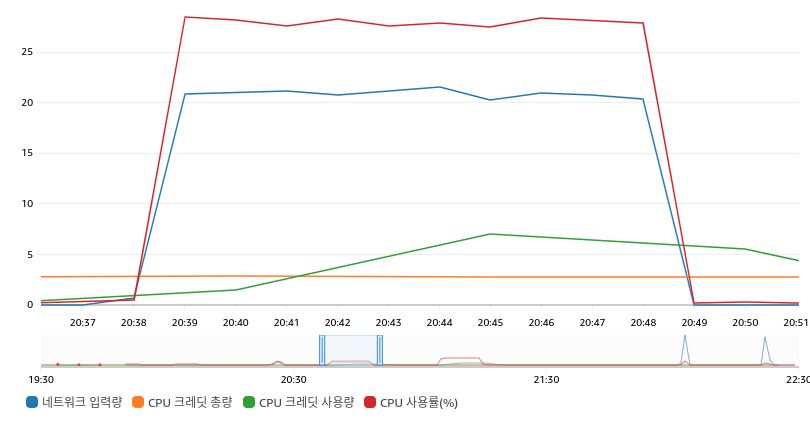
결과적으로, 네트워크 입력량에 따라 CPU 사용량이 비례하게 올라갔다.
또한 CPU 크레딧을 사용하여 CPU 버스팅을 하여 CPU 크레딧 사용량이 늘어난 것을 확인할 수 있었다. (CPU 버스팅 관련 참조) -
Spike 테스트 분석
6분간 초당 약 2000건의 요청을 보내 아래의 그림과 같은 결과나 나왔다.
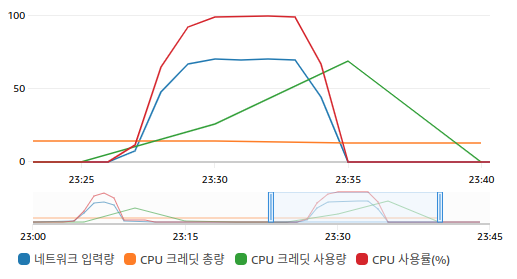
의도적으로 CPU 감당할 수 없을만큼의 요청을 보내어 요청이 처리되지 않는 것을 의도하였으나 결과적으로 초당 3000건으로 요청을 보내도 다 처리가 되었으며 CPU는 100% 를 유지했다. 다 처리가 된 정확한 이유는 아직 모르겠다. 추측으로는 요청들이 장기간 대기한 뒤 결과를 받지 않았을까 싶지만 보다 정확한 사유는 추후에 더 알아봐야겠다. 일단 CPU 가 40% 이상 올라가지 않도록 가용성을 유지하여야 하는 것에 중점을 둬서 공부하려 한다. 그 밖에도 CPU 크레딧을 상당량 소비하여 CPU 를 사용한 것을 확인할 수 있었다.
트러블 슈팅
🔸EC2 서버에서 K6을 실행시킬 시 문제 발생
결론부터 말하자면 EC2 서버 에서 k6 를 돌린 결과, 네트워크 입력량에 따른 CPU 증가량 을 확인할 수 없었으며 서버 자체의 처리 능력만을 측정하고 싶었으나 EC2 서버 가 k6 도 같이 실행시키고 있기에 k6 실행에 따른 부하도 같이 포함되어, EC2 서버 프로그램 만 실행했을 때보다 더 많은 CPU 자원을 사용하여 정확한 결과값을 얻을 수 없었다. 이와 같은 문제는 EC2 외부 에서 k6 을 실행함으로써 해결할 수 있었다.
아래는 EC2 외부 에서 k6 를 실행하여 EC2 서버 로 요청했을 때의 그래프이다.

1초당 약 500개의 요청을 스파크 트래픽 없이 10분간 고정적으로 보냈기에 네트워크 입력량이 일정하였고 CPU 또한 네트워크 입력량과 비례하게 증가하였다.
이번에는 반대로, EC2 서버 에서 k6 를 실행하여 자기 자신에게 요청했을 때의 그래프이다.
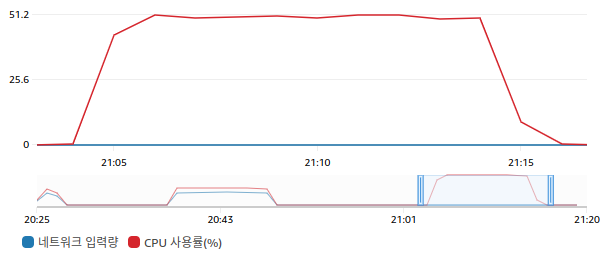
이전 테스트 결과와는 다르게 네트워크 입력량은 확인할 수 없고 CPU 사용량이 1.5배 이상 소모되었다.
따라서 정확한 결과를 위해서는 테스트 호출을 EC2 외부 에서 해야 되겠다는 결론이 나왔다.
부록
🔸 Load 테스트 k6 결과
$ k6 run basic_test.js
...
scenarios: (100.00%) 1 scenario, 100 max VUs, 10m30s max duration (incl. graceful stop):
* default: 100 looping VUs for 10m0s (gracefulStop: 30s)
data_received..................: 130 MB 217 kB/s
data_sent......................: 25 MB 41 kB/s
http_req_blocked...............: avg=19.75µs min=1.3µs med=6.36µs max=82.23ms p(90)=10.54µs p(95)=12.91µs
http_req_connecting............: avg=12.18µs min=0s med=0s max=82.08ms p(90)=0s p(95)=0s
http_req_duration..............: avg=6.51ms min=4.23ms med=6.36ms max=97.17ms p(90)=7.45ms p(95)=7.96ms
{ expected_response:true }...: avg=6.51ms min=4.23ms med=6.36ms max=97.17ms p(90)=7.45ms p(95)=7.96ms
http_req_failed................: 0.00% ✓ 0 ✗ 289502
http_req_receiving.............: avg=103.8µs min=15.82µs med=89.71µs max=13.26ms p(90)=156.13µs p(95)=188.98µs
http_req_sending...............: avg=33.22µs min=5.16µs med=28.02µs max=12.39ms p(90)=49.1µs p(95)=58.59µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=6.38ms min=4.15ms med=6.23ms max=96.8ms p(90)=7.3ms p(95)=7.8ms
http_reqs......................: 289502 482.340761/s
iteration_duration.............: avg=207.25ms min=204.52ms med=207.03ms max=353.05ms p(90)=208.35ms p(95)=209.05ms
iterations.....................: 289502 482.340761/s
vus............................: 100 min=100 max=100
vus_max........................: 100 min=100 max=100
running (10m00.2s), 000/100 VUs, 289502 complete and 0 interrupted iterations
default ✓ [======================================] 100 VUs 10m0s🔸 spike 테스트 k6 결과
$ k6 run spike_test.js
...
execution: local
script: spike_test.js
output: -
scenarios: (100.00%) 1 scenario, 3000 max VUs, 8m20s max duration (incl. graceful stop):
* default: Up to 3000 looping VUs for 7m50s over 7 stages (gracefulRampDown: 30s, gracefulStop: 30s)
✓ status was 200
checks.........................: 100.00% ✓ 641080 ✗ 0
data_received..................: 289 MB 613 kB/s
data_sent......................: 49 MB 105 kB/s
http_req_blocked...............: avg=55.31µs min=1.06µs med=5.16µs max=153.1ms p(90)=9.07µs p(95)=11.3µs
http_req_connecting............: avg=48.17µs min=0s med=0s max=152.93ms p(90)=0s p(95)=0s
http_req_duration..............: avg=268.84ms min=4.23ms med=189.08ms max=30.2s p(90)=635.27ms p(95)=670.05ms
{ expected_response:true }...: avg=268.84ms min=4.23ms med=189.08ms max=30.2s p(90)=635.27ms p(95)=670.05ms
http_req_failed................: 0.00% ✓ 0 ✗ 641080
http_req_receiving.............: avg=82.75µs min=15.87µs med=68.38µs max=43.02ms p(90)=122.34µs p(95)=151.93µs
http_req_sending...............: avg=28.14µs min=5.26µs med=21.42µs max=31.08ms p(90)=39.25µs p(95)=48.69µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=268.73ms min=4.19ms med=188.95ms max=30.2s p(90)=635.15ms p(95)=669.94ms
http_reqs......................: 641080 1361.487083/s
iteration_duration.............: avg=1.26s min=1s med=1.18s max=31.21s p(90)=1.63s p(95)=1.67s
iterations.....................: 641080 1361.487083/s
vus............................: 1 min=1 max=3000
vus_max........................: 3000 min=3000 max=3000
running (7m50.9s), 0000/3000 VUs, 641080 complete and 0 interrupted iterations
default ✓ [======================================] 0000/3000 VUs 7m50s🔸 CloudWatch Metrics 모니터링 소스
{
"metrics": [
[ { "expression": "m4 / 100 /30 /100", "label": "네트워크 입력량", "id": "q1", "region": "ap-northeast-2", "period": 300 } ],
[ { "expression": "mCPUCreditBalance / 4", "label": "CPU 크레딧 총량", "id": "e1", "region": "ap-northeast-2", "period": 300 } ],
[ { "expression": "m2 * 5 * 3", "label": "CPU 크레딧 사용량", "id": "e2", "region": "ap-northeast-2", "period": 300 } ],
[ "AWS/EC2", "CPUUtilization", "InstanceId", "i-091baff6c5a1f7979", { "label": "CPU 사용률(%)", "region": "ap-northeast-2", "id": "mCPUUtilization" } ],
[ "AWS/EC2", "CPUCreditUsage", "InstanceId", "i-091baff6c5a1f7979", { "region": "ap-northeast-2", "id": "m2", "label": "CPU 크레딧 사용량", "visible": false } ],
[ "AWS/EC2", "CPUCreditBalance", "InstanceId", "i-091baff6c5a1f7979", { "region": "ap-northeast-2", "id": "mCPUCreditBalance", "visible": false } ],
[ "AWS/EC2", "NetworkIn", "InstanceId", "i-091baff6c5a1f7979", { "region": "ap-northeast-2", "id": "m4", "visible": false } ]
],
"view": "timeSeries",
"stat": "Average",
"period": 60,
"stacked": false,
"yAxis": {
"left": {
"min": 0
}
},
"region": "ap-northeast-2",
"title": "CPU utilization (%)"
}참고 자료:

잘봤습니다!