ipynb 파일 하나 만들어주자.
1. 라이브러리 로드
import librosa
import librosa.display
import IPython.display as ipd
import matplotlib.pyplot as plt
import numpy as np필요한 라이브러리 가져오자. librosa.display는 matplotlib를 이용해서 내가 분석한 오디오 파일의 모습을 보여준다.
IPython은 파이썬에서 오디오 파일을 가져오게 해준다.
2. 파일 로드
music_file = "내 파일 경로"내가 분석하고 싶은 파일의 경로를 지정해서 객체를 만들어주자.
3. 파일 확인
ipd.Audio(music_file)위와 같이 코드를 짜주면 파이썬 스크립트에서 음악 파일을 직접 재생할 수 있다.
4. sample duration
myMusic, sr = librosa.load(music_file)내 음악 파일을 librosa에 로드해주자.
librosa.load(path, *, sr=22050, mono=True, offset=0.0, duration=None, dtype=<class 'numpy.float32'>, res_type='soxr_hq')librosa.load()의 매개변수는 위와 같다.
Returns:
y: np.ndarray [shape=(n,) or (…, n)]
audio time series. Multi-channel is supported.
sr: number > 0 [scalar]
sampling rate of y
리턴값은 위와 같다.
librosa.load()는 amplitude를 벡터처럼 배열로 만들어서 반환해준다. 여기서 기본적인 샘플링 레이트는 sr = 22050이고 원래 음원의 샘플링 레이트를 이용하고 싶다면 sr=none으로 매개변수를 처리해주면 된다.
myMusic, sr = librosa.load(music_file)위 코드는 amplitude와 sample rate을 추출하는 코드이다.
음원의 amplitude를 알고 싶으면 myMusic같이 내가 만든 객체만 치면된다.
음원의 크기 확인
내가 librosa.load()해서 음원의 크기를 알고 싶다면, 즉 amplitude 벡터의 개수를 알고 싶다면
myMusic.shape와 같이 shape을 붙여주면 된다.
내껀 (5615694,) 이렇게 나옴
음원 샘플의 길이 확인
sample rate가 뭐냐? 일종의 주파수다. 뭔 소리냐면 1초에 얼마나 쪼겠는지 나타내는것이라고 그럼 샘플 하나의 시간 크기를 알려면? sample rate에 역수를 취하면 되겠지?
sample rate = 샘플 개수 / 1(s)
그럼 역수를 취하면 1(s) / 샘플 개수
즉 샘플 하나의 시간 크기를 알 수 있다.
sample_rate = 1 / sr
print(sample_rate)내껀 4.5351473922902495e-05 이 값이 나왔다. 역시 음원을 존나 쪼개서 샘플들을 만들기 때문에 샘플 하나의 시간 크기가 상당히 작은 값이 나왔다.
tot_music = len(myMusic)
tot_music샘플 개수를 아는 다른 방법엔 위와 같은 것도 있다. 어느 언어에나 있는 len()를 활용하면 됨.
음원의 총 길이
그럼 위에서 추출한 거에서 음원의 크기를 구해서 확인해보자.
음원의 총 길이 = 샘플 한 개의 시간 크기 * 샘플의 개수
위처럼 하면 구할 수 있겠지?
duration = 1 / sr * tot_music
duration내껀 254.68(s)가 나왔다.
음원을 그래프로
plt.figure(figsize=(30, 10))
librosa.display.waveshow(myMusic, sr=sr, alpha=0.5, color='blue')
plt.ylim((-1.5, 1.5))
plt.title("myMusic")
plt.show()figsize로 (가로, 세로)길이를 조절 해주자.
waveshow의 alpha는 투명도를 의미한다. 현재
librosa 0.10.1
matplotlib 3.8.4 기준으로 컬러를 지정해주지 않으면 에러가 남으로 컬러를 지정해준다.
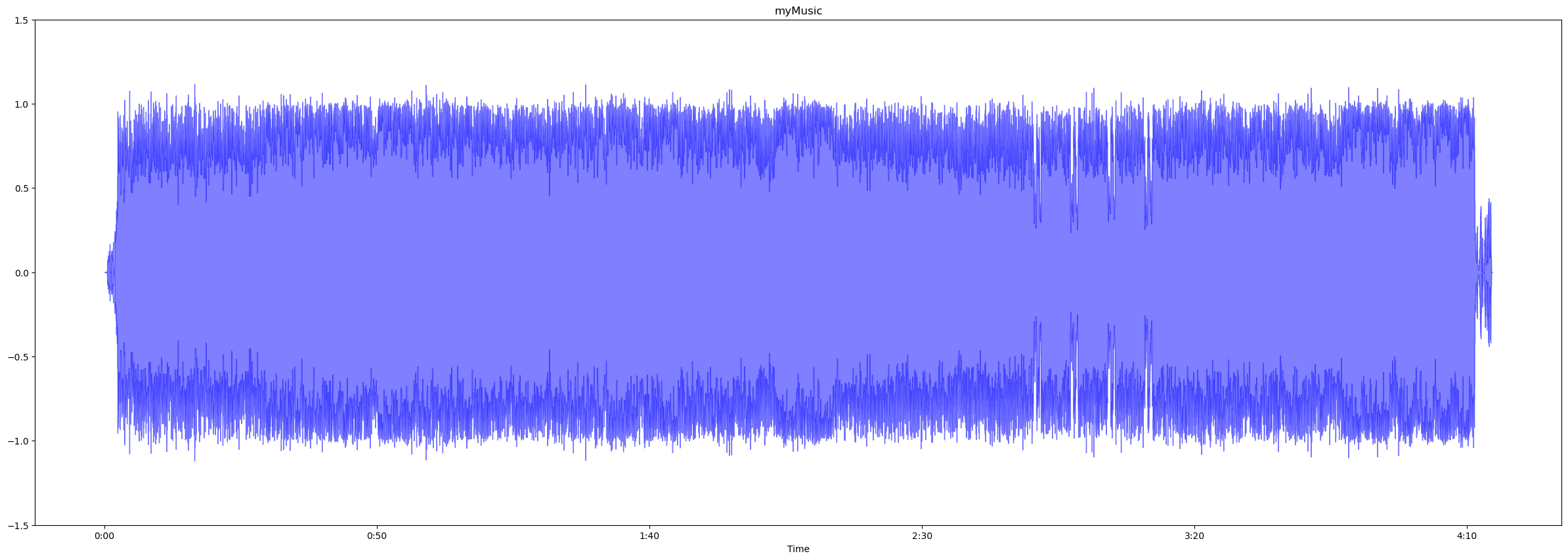
내 음원은 위와 같이 나왔다.
amplitude envelop 구하기
amplitude envelop은 프레임에서 가장 큰 amplitude를 구하는 것이라고 했다.
함수를 다음과 같이 만들어주자.
FRAME_SIZE = 4096
HOP_LENGTH = 2048
def amplitude_envelope(signal, frame_size, hop_length):
"""Calculate the amplitude envelope of a signal with a given frame size nad hop length."""
amplitude_envelope = []
# calculate amplitude envelope for each frame
for i in range(0, len(signal), hop_length):
amplitude_envelope_current_frame = max(signal[i:i+frame_size])
amplitude_envelope.append(amplitude_envelope_current_frame)
return np.array(amplitude_envelope)그리고 내 파일을 구해주면
ae_myMucis = amplitude_envelope(myMusic, FRAME_SIZE, HOP_LENGTH)
len(ae_myMucis)amplitude envelop 그래프
plt.figure(figsize=(15, 17))
ax = plt.subplot(3, 1, 1)
librosa.display.waveshow(myMusic, alpha=0.5, color='blue')
plt.plot(time, ae_myMucis, color="r")
plt.ylim((-2, 2))
plt.title("myMusic")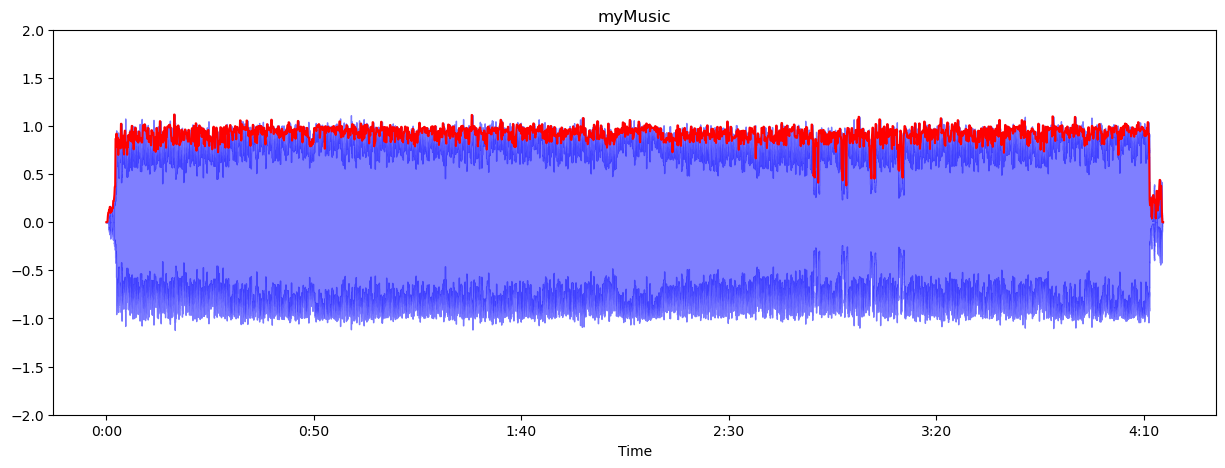
빨간색으로 표시된게 amplitude envelop다. 만약 그래프의 빨간색이 너무 못생기고 크게 나왔다면 frame_size와 HOP_LENGTH를 조절해주자. frame_size는 보통 2의 거듭제곱중에 하나로 선택을 하고 hop_length는 frame size의 절반정도로 해준다. 나는 이 그래프를 얻기 위해서 FRAME_SIZE = 4096
HOP_LENGTH = 2048로 설정해주었다.
frame_size를 크게 해준다는 것은 한 프레임에 좀 더 많은 수의 샘플을 포함해서 max값 하나를 찾는다는 말이다. 즉 대표값의 수가 적어져서 좀 더 대충 부드럽게 시각화 해준다는 말이다. frame_size를 작게 하는건 좀 더 세밀하게 amplitude envelop의 개수를 좀 더 늘려서 시각화 해준다는 말이다. 즉 구간이 많아지고 그 구간을 대표하는 대표값(max값)의 수가 많아진다는 소리다. frame_size를 늘려 대표값을 늘리는게 좋아보이지만 시각화 입장에서 너무 과하면 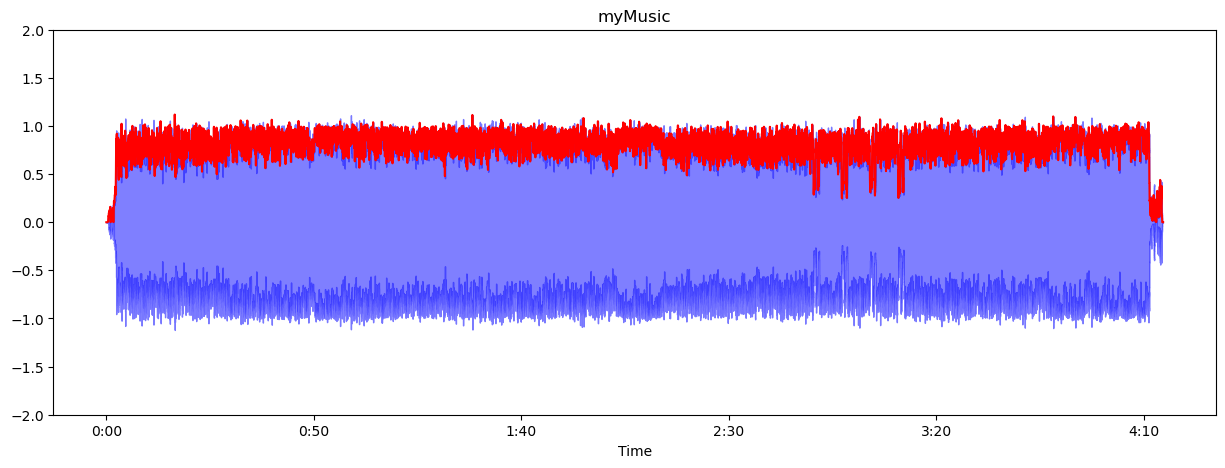
이따구로 되니까 적당히 조절하자.
