mel-spectrogram
mel-spectrogram의 자세한 내용은 이 시리즈의 초반부에 자세히 설명했다. 내용은 전 글을 참고하자.
간단하게 말하자면 spectrogram이 우리가 딥러닝에 사용할 데이터인데 mel-spectrogram은 우리가 실제로 사용하는 화성학과 같은 음악이론을 물리적인 신호에 사용하기 위한 것이다. 자세한 건 전 시리즈의 글을 보자.
아무튼 mel-spectrogram은 mfcc와 함께 음악 딥러닝에 사용하는 데이터이며 최신 기술은 mel-spectrogram이 사용되고 있으니 librosa로 구해보자.
mel-filter bank
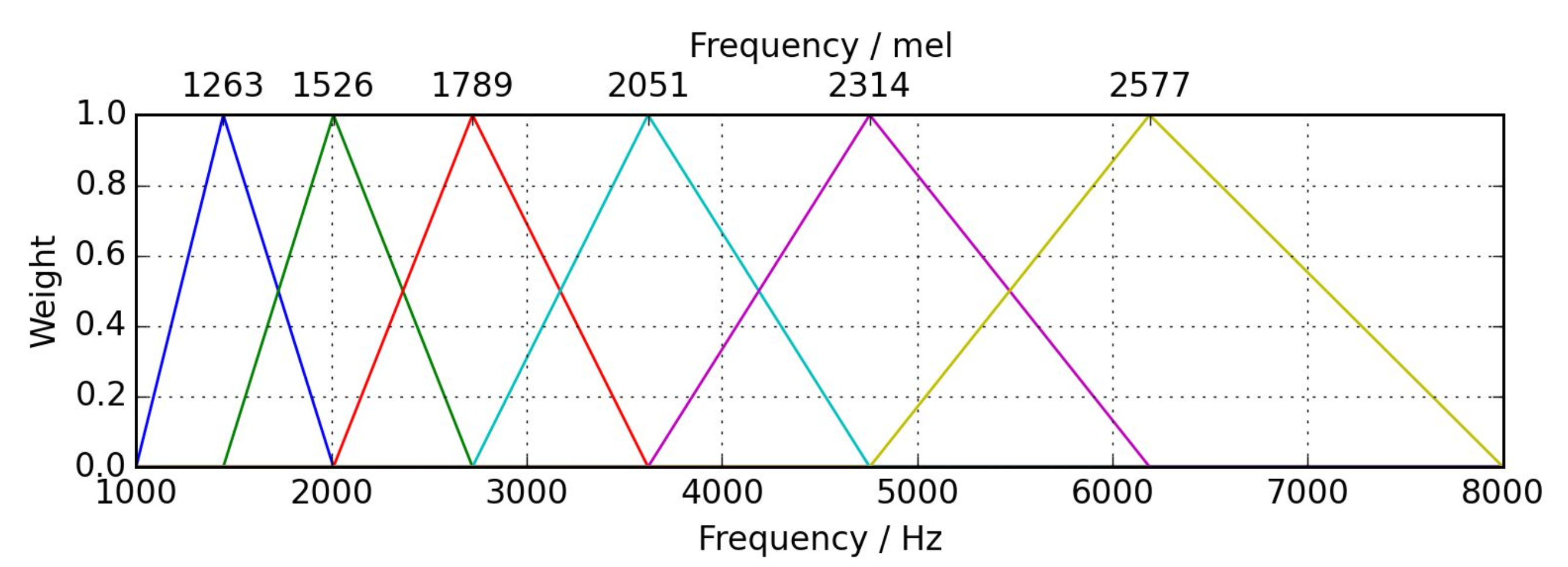
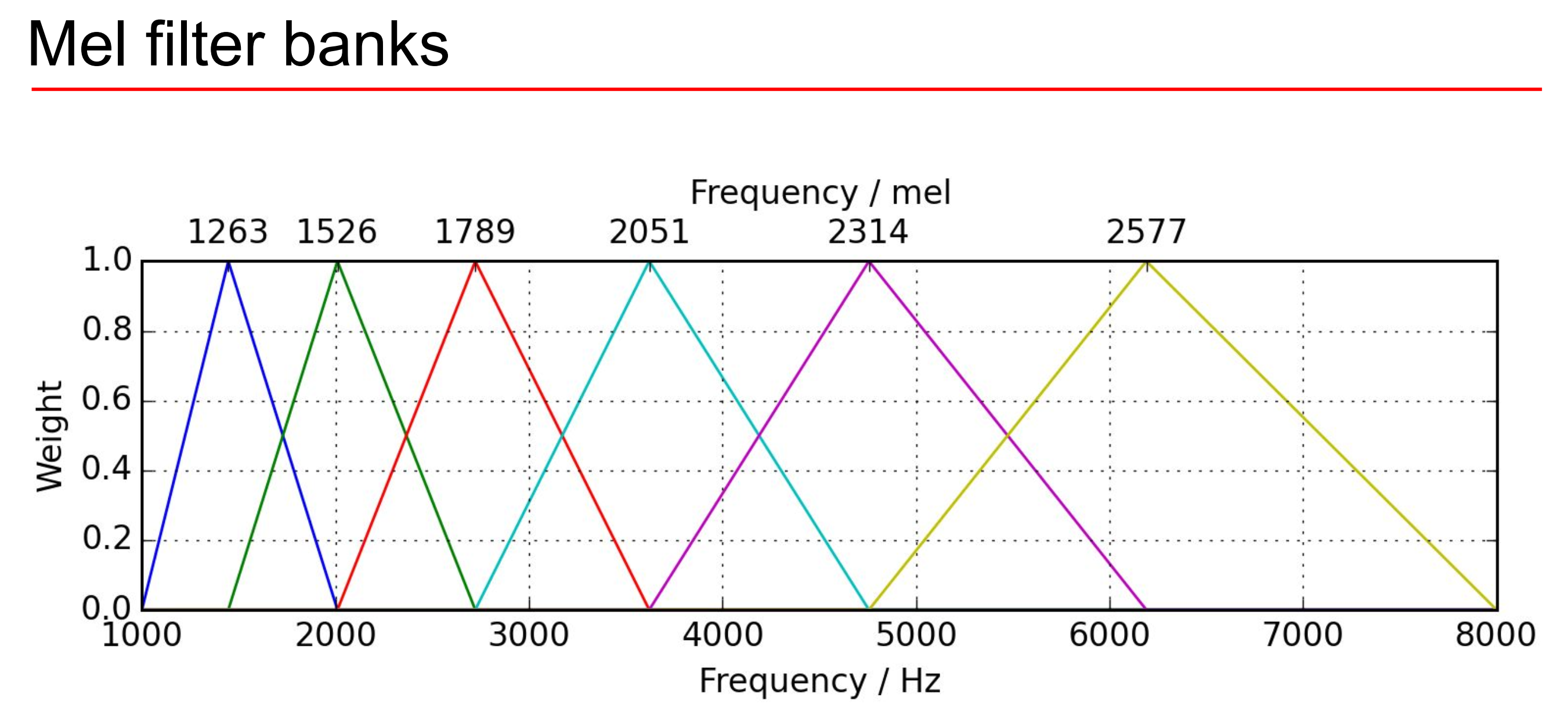
mel-scale은 지수적인 물리 신호를 음악 신호인 선형으로 바꾸기 위해 로그를 적용해주는 것이다.
mel-scale과 mel-filter bank는 이 주파수 신호의 영역을 로그적으로 나눠서 선형 신호로 바꾸는 작업이다.
주파수에 mel-filter bank를 적용해 mel-scale로 표현하면 그걸 mel-frequency라고 한다.
그냥 이름 앞에 mel 붙은건 원래 신호를 로그처리 해줬다고 보면된다. 로그 처리해주는 건 내 전 글을 보도록
librosa로 mel-spectrogram 구하기
import librosa
import librosa.display
import IPython.display as ipd
import matplotlib.pyplot as plt라이브러리 준비하고
lux = "/Users/seong-gyeongjun/Downloads/bugs_20230422165203/Lux Æterna_Metallica_72 Seasons.mp3"음원 객체를 로드해주자. 이때 음원은 wav파일로 하는 게 품질이 좋아서
웬만하면 wav 파일로 하자.
만약에 음원 파일을 구했다면 wav파일로 바꿔주자.
filter_bank = librosa.filters.mel(n_fft=2048, sr=22050, n_mels=10)librosa의 멜 필터를 사용해주자. 이때 n_mels는 필터 뱅크의 수다.
plt.figure(figsize=(25, 10))
librosa.display.specshow(filter_bank,
sr=sr,
x_axis="linear")
plt.colorbar(format="%+2.f")
plt.show()그림을 그려주자.
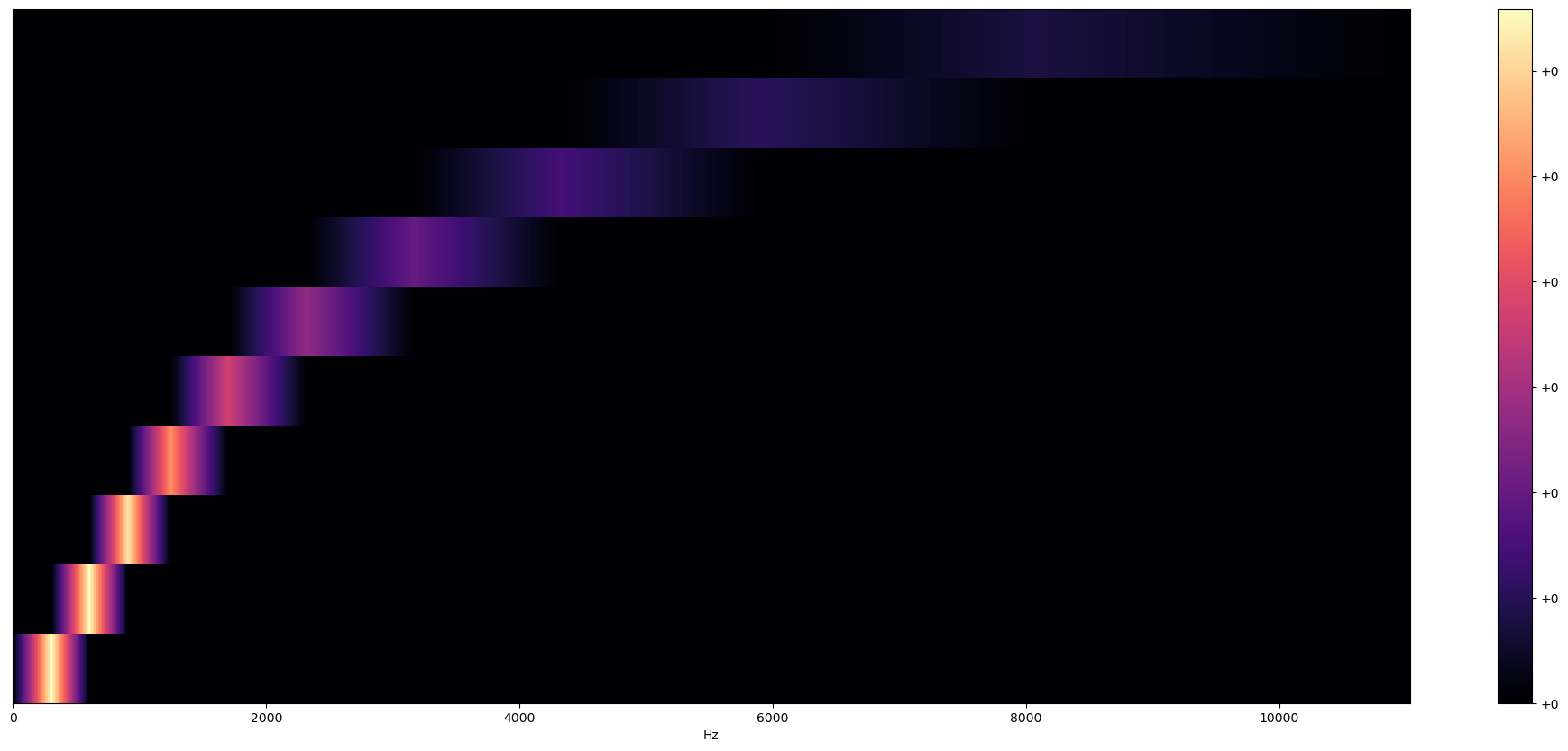
mel-filter bank의 모습을 볼 수 있다.
이번엔 mel-spectrogram을 구하자.
mel_spectrogram = librosa.feature.melspectrogram(y=lux, sr=sr, n_fft=2048, hop_length=512, n_mels=10)librosa.feature.melspectrogram(*, y=None, sr=22050, S=None, n_fft=2048, hop_length=512, win_length=None, window='hann', center=True, pad_mode='constant', power=2.0, **kwargs)y에 음원 librosa 로드한것 ,샘플링, 윈도우 길이인 n_fft 등을 설정해주자.
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)역시나 신호의 크기를 데시벨로 바꿔주자.
plt.figure(figsize=(25, 10))
librosa.display.specshow(log_mel_spectrogram,
x_axis="time",
y_axis="mel",
sr=sr)
plt.colorbar(format="%+2.f")
plt.show()그림을 그려서 대충 확인해주자.
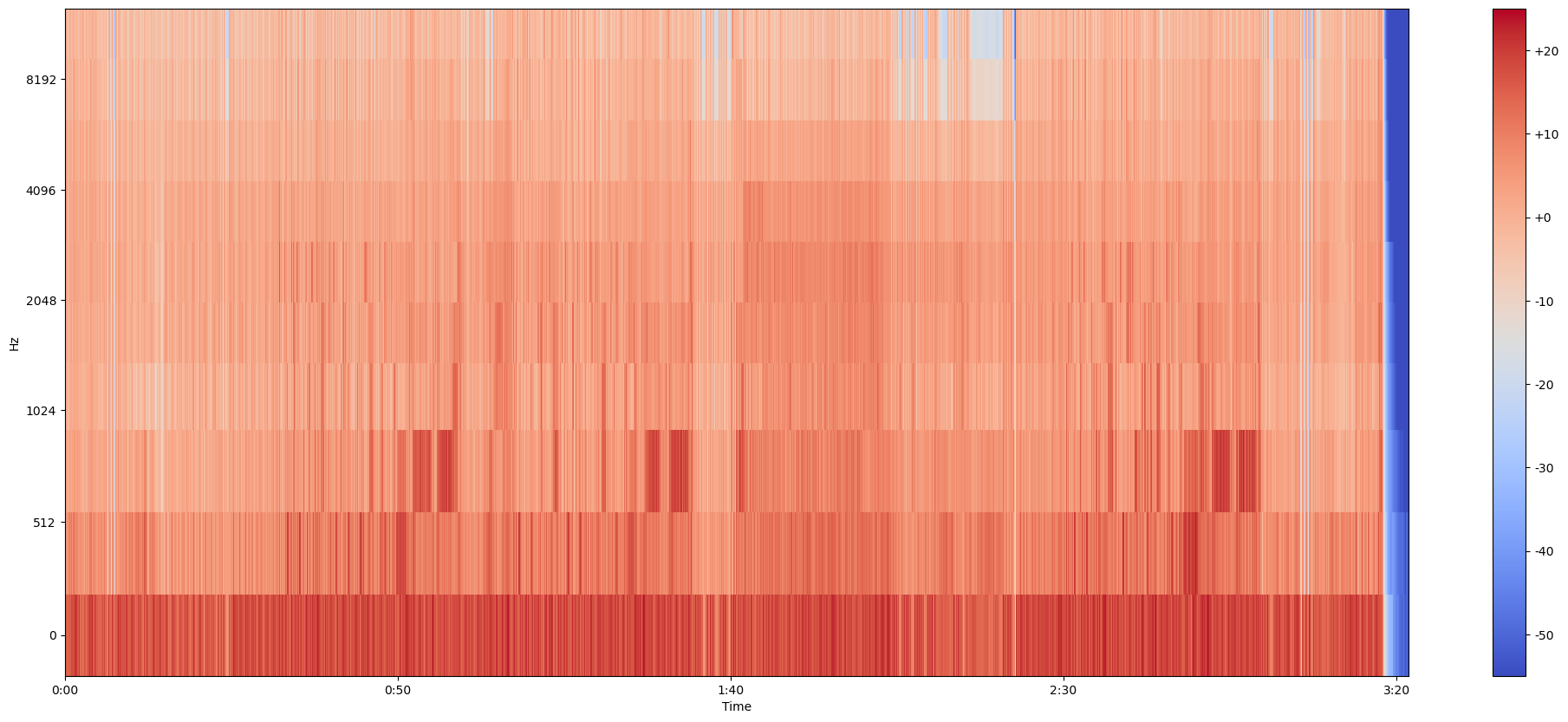
이것이 우리가 이용할 데이터인 mel-spectrogram이다.
보면 주파수, 주파수의 크기, 시간이 있어 음악 딥러닝에 사용할 수 있다.
