frames
저번 시간에 음원 파일을 존나 나눈것을 샘플링이라고 했다. 그럼 우리가 분석을 할 때 샘플링 하나하나를 모두 분석을 할까? 샘플링은 음원을 존나 나눈것이라 작다. 아무래도 샘플 하나만을 분석하기엔 너무 작으니 샘플을 모아서 덩어리처럼 구간별로 다루는게 좋다. 샘플을 덩어리처럼 묶어논 것을 frame이라고 한다.
frame은 존나 중요하다.
우리가 음악 딥러닝에서 데이터의 단위가 바로 프레임이라고 생각하면 된다.
frame의 구성
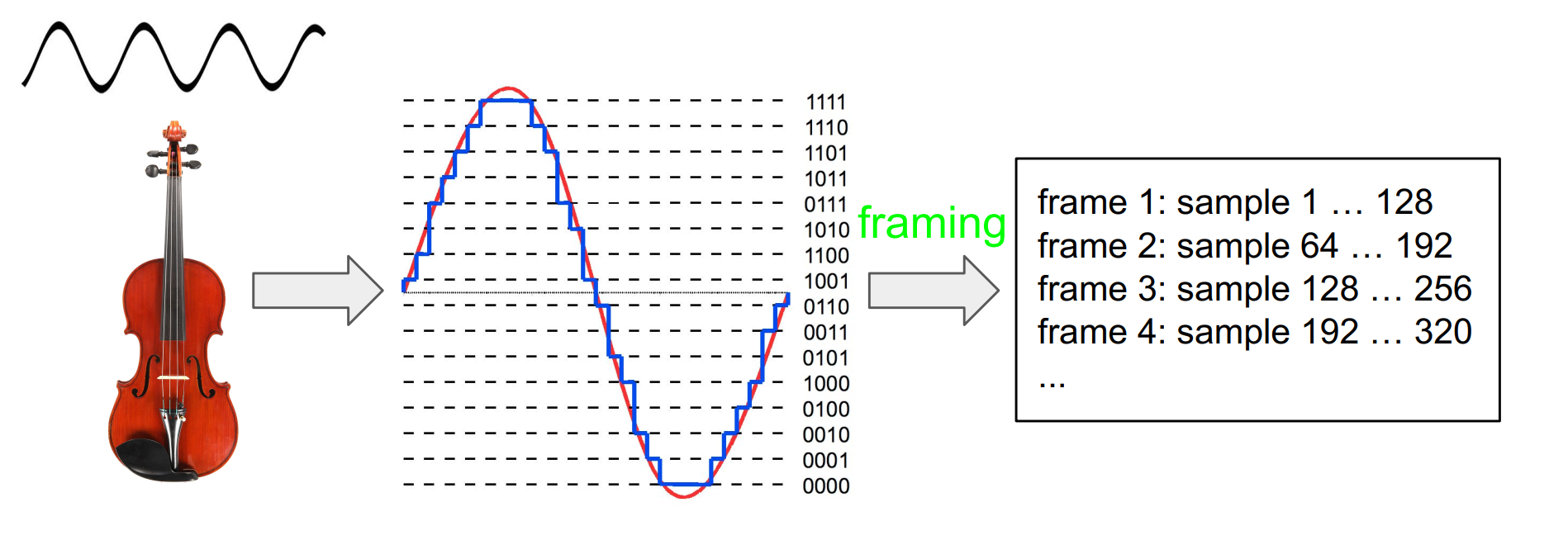
위 그림을 봐라
프레임1, 프레임2, ... 등 프레임이 샘플 1부터 128까지 64부터 192까지 프샘플링을 모아논 덩어리라는 것을 볼 수 있다.
프레임의 중요한 요소는 프레임 단위가 되어야 보통 우리가 음원을 들을 수 있다. 뭔 말이냐면 음원의 길이가 10ms이하면 우리는 그 소리를 못듣는다. 근데 샘플링을 할 때 보통 표준적으로 0.02ms 정도의 길이여서 당연히 샘플링으론 못 듣는다.
그래서 샘플링을 뭉쳐서 프레임을 만든 것이여.
하나의 프레임에 보통 2의 지수만큼의 샘플이 들어있다. 256, 512같은 거
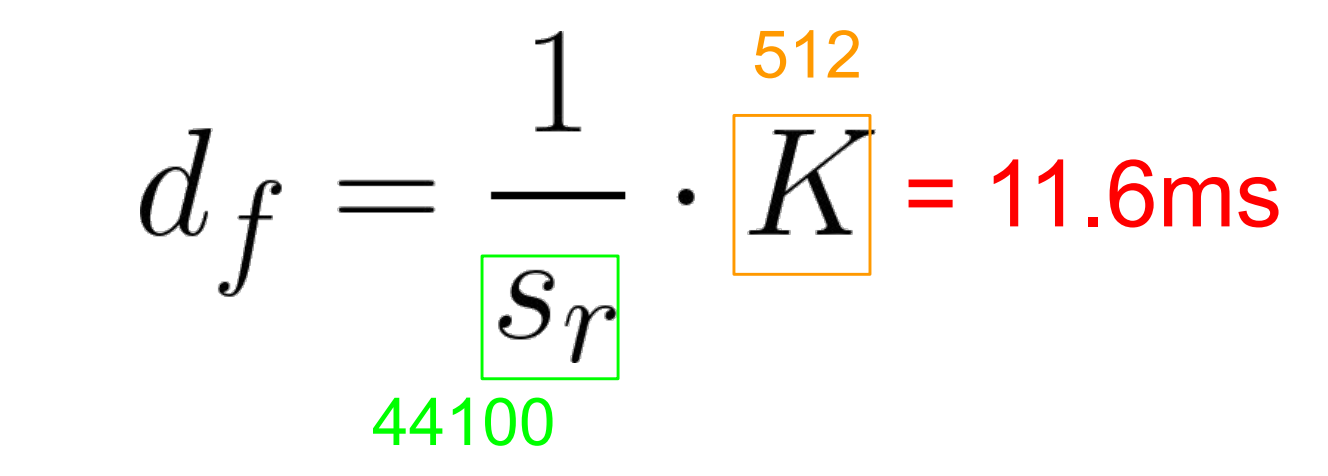
그래서 프레임의 길이를 계산해보면 샘플링의 역수는 샘플 하나의 시간길이고 K는 총 샘플의 개수이니 둘이 곱하면 11.6ms로 10ms 보다 길어서 들을 수 있는 데이터가 된다.
Spectral Leakage
아니 생각보다 내용 복잡하네? 이산 푸리에 변환과 고속 푸리에 변환과정에서 프레임들의 불연속적인 점을 이산적으로 처리하는 과정에서 생기는 이상한 주파수 배정이라고 생각하면 되는 데 생각보다 수학적으로 증명하기가 복잡하네. spectral leakage는 정리해서 나중에 따로 빼서 올리겠다.
