InvertedResidual
우선 mobileNetV2 경량화의 핵심은 bottleNeck과 residual의 개념을 합친 것이고 그 개념은 전 편에서 소개했었다. 이번엔 InvertedResidual를 모듈식으로 구현 해보자.
depthwise, pointwise 분리
저번에 v1을 구현할 때 depthwise와 pointwise를 섞어서 구현 했는데 그걸 이용하기 위해서 분리하겠다.
import torch.nn as nn
class DepthwiseConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DepthwiseConv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1,
groups=in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x이 것 들을
import torch.nn as nn
class DepthwiseConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DepthwiseConv, self).__init__()
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1,
groups=in_channels)
def forward(self, x):
x = self.depthwise(x)
return ximport torch.nn as nn
class PointwiseConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(PointwiseConv, self).__init__()
self.pointwise = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
def forward(self, x):
x = self.pointwise(x)
return x이렇게 분리하겠다.
relu6?
min(max(0, x), 6) 기존 relu의 상한선을 6으로 둔다.
논문에선 6을 상한선으로 둔 이유는 역시 경량화 측면에서 성능 최적화를 위해서이다.
상한선이 없을 때보다 있을 때 컴퓨터가 표현할 수 있는 bit가 작기 때문에 최적화가 되고 실제로 논문에서 relu6를 사용할 때 더 좋은 성능을 얻었다.
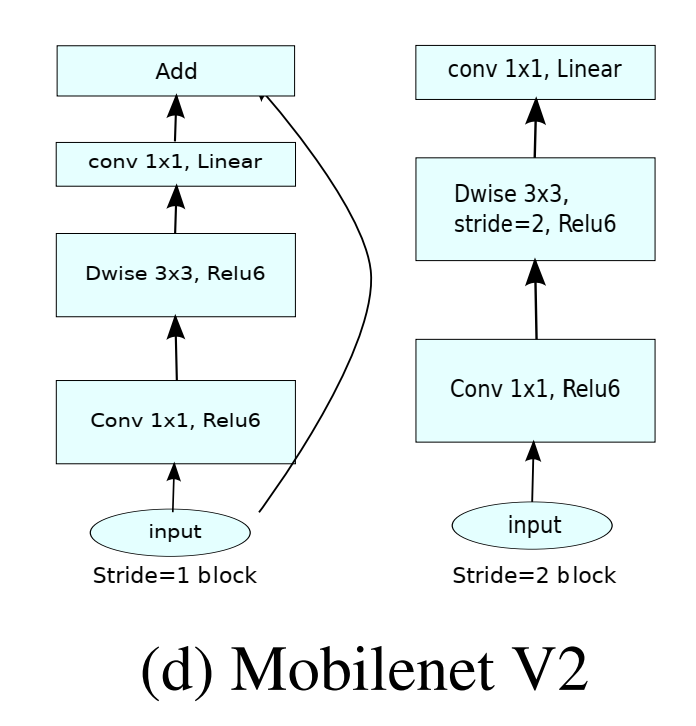
stride의 의미
Stride 1
입력과 출력의 크기가 동일합니다.
블록 내의 연산을 통해 특징을 추출하고, skip connection을 통해 입력을 출력에 더합니다.
예시: 블록 내에서 추가적인 특징 추출이 필요할 때.
Stride 2
입력의 공간적 크기를 줄여 다운샘플링합니다.
이 경우, skip connection을 사용할 수 없습니다.
예시: 네트워크의 깊이를 더하면서, 특징 맵의 크기를 줄여 다음 레벨의 특징 추출을 효율적으로 합니다.
2종류의 블럭 사용하는 이유
mobileNet V2에선 둘 중 하나의 블럭을 목적에 따라 선택하고 그런 블럭들을 CNN처럼 쌓아 올려서 깊게 모델을 만드는 과정이다.
이때 깊게 쌓는 과정 중에 residual을 이용해 채널 경량화 하면서 깊어져도 학습이 잘 되게 도와주는 과정
stride2는 공간 정보의 경량화(공간 정보를 절반으로) 줄이는 다운 샘플링으로 이것도 경량화라고 보면 된다.
InvertedResidual 구현
torch module을 활용 해주고 블럭에서 2가지 종류는 구별해야하니 조건문을 써주자.
import torch.nn as nn
from typing import Optional, Callable
from models import pointwise_conv
from models import depthwise_conv
class InvertedResidual(nn.Module):
"""
Inverted Residual Block for MobileNetV2 architecture.
This block implements the Inverted Residual structure introduced in MobileNetV2.
It consists of a series of layers including optional expansion, depthwise separable convolution, and projection.
Parameters:
- in_channels (int): Number of input channels.
- out_channels (int): Number of output channels.
- stride (int): Stride for the depthwise convolution. Must be either 1 or 2.
- expand_ratio (float): Ratio by which the input channels are expanded. If 1, no expansion is applied.
- norm_layer (Optional[Callable[..., nn.Module]]): A function or class that returns a normalization layer (e.g., nn.BatchNorm2d).
If `None`, no normalization layer is applied.
Attributes:
- use_res_connect (bool): Indicates whether to use the residual connection.
- conv (nn.Sequential): Sequential container of the layers used in the block.
"""
def __init__(self, in_channels, out_channels, stride, expand_ratio,
norm_layer: Optional[Callable[..., nn.Module]] = None):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2], "Stride must be either 1 or 2."
hidden_dim = int(round(in_channels * expand_ratio))
self.use_res_connect = self.stride == 1 and in_channels == out_channels
layers = []
pointwise = pointwise_conv.PointwiseConv
depthwise = depthwise_conv.DepthwiseConv
if expand_ratio != 1:
# Expansion phase
layers.append(pointwise(in_channels, hidden_dim))
if norm_layer is not None:
layers.append(norm_layer(hidden_dim))
layers.append(nn.ReLU6(inplace=True))
# Depthwise convolution phase
layers.append(depthwise(hidden_dim))
if norm_layer is not None:
layers.append(norm_layer(hidden_dim))
layers.append(nn.ReLU6(inplace=True))
# Projection phase
layers.append(pointwise(hidden_dim, out_channels))
if norm_layer is not None:
layers.append(norm_layer(out_channels))
self.conv = nn.Sequential(*layers)
def forward(self, x):
"""
Forward pass through the Inverted Residual Block.
Parameters:
- x (torch.Tensor): Input tensor with shape (N, C, H, W) where N is batch size, C is the number of channels,
H is height, and W is width.
Returns:
- torch.Tensor: Output tensor after passing through the block.
"""
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)블럭을 2가지 경우로 나눠서 위와 같이 구현 해주자.
