mobileNet v3 목표
mobileNet v2까지 경량화는 flops, parameter와 같은 실제적인 연산량을 줄이려고 노력했다면 mobileNet v3, v4를 비롯한 다른 최신 경량화 모델은 latency, memory의 병목 등을 신경쓰기 시작했다.
현재 4개월전 논문까지는 이런 트렌드를 유지하고 있고 당분간은 계속 될 것 같다.
아무튼 mobileNet v3 또한 latency를 주목하기 시작했다.
Network Search
NAS와 NetAdapt 알고리즘 사용
MNAS 참고
MnasNet이란 논문을 참고하자
내가 이 시리즈에서 맨날 하는 말이지만 mobileNet의 가장 큰 특징은 발표 전 논문 좋은거 있으면 흡수해서 합친다는 점이다.
NAS 알고리즘도 MNAS란 아키텍처에서 흡수해온 것이다. 웃긴게 MNAS 요약본에 mobileNetV2와 비교하며 MNAS가 훨씬 뛰어나다고 멕이고 있는데 mobileNetV3에선 
응~~ 흡수하면 그만이야 ㅋㅋ
mobileNetV3에선 자세히 설명하지 않으니 MNAS 논문을 읽고 오자.
목표는 다음을 최적값을 찾는 것
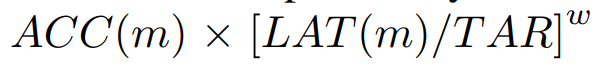
ACC: 정확도 (accuracy)
LAT: 지연시간 (latency)
TAR: 목표 지연시간 (Target Latency)
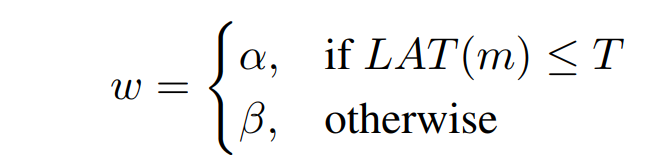
w는 2가지 케이스이고 저 값이 어떻게 나왔냐면 accuracy가 상대적인 비율로 5퍼센트가 올랐을 때 latency는 2배가 되었다는 관찰 결과로부터 나왔다.
Mnas는 α = β = −0.07 이렇게 설정했고
mobileNetV3는 작은 모델에서 latency와 accuracy의 관계가 급격하게 변하기 때문에 원래 설정했던 w = -0.07 보다 저 작은 값인 w = -0.15를 설정함
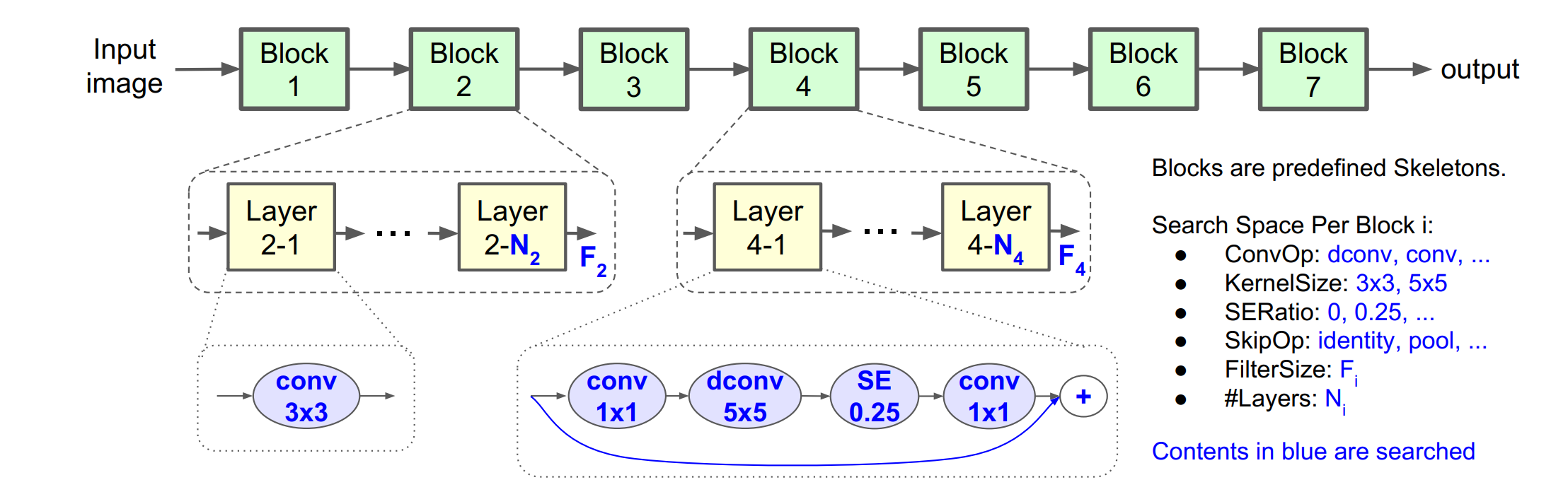
NAS가 뭐 특별한 게 있는게 아니다
위 그림은 Hierarchical Search Space라는 건데 말 그대로 latency와 accuracy가 균형을 이루는 block의 후보들을 정해놓고 최적의 아키텍처를 찾는 과정이다. 이전의 모델들이 하나의 아키텍처를 모든 블럭에 적용했다면 MNAS는 블럭마다 최적의 아키텍처를 개별로 적용한다

MNAS에선 위 중에서 하나를 적절하게 섞어서 선택한다
mobileNetV3에선 MNAS를 그대로 채택하여 RNN기반의 search space를 구성하고 거기에 NetAdapt란 과정을 더한다
NAS와는 달리 mobileNetV3는 전체적인 블럭을 한 번에 조정하지 않고 개별 블럭을 fine-tuning한다
즉 계층별로 fine-tuning을 해서 최적화를 진행한다.
NetAdapt
NetAdapt는 다른 NAS와 달리 하드웨어에서 직접적으로 측정한 metric을 사용한다. 예를 들어서 기존 NAS가 다양한 아키텍처 중 가장 최적의 아키텍처를 간접적인 metric을 이용해 찾는다면 NetAdapt는 기존 모델에서 점진적으로 자원 소모를 줄이는 방식으로 최적화를 진행한다
구체적인 최적화 과정
-
NAS과정을 통해 시작점인 seed network architecture를 설정한다
-
기존 아키텍처를 이것저것 수정해본 여러개의 아키텍처를 만든다
-
변형한 아키텍처가 지연 시간(latency)이 최소한 δ만큼 감소한것만 선택한다
-
이전 아키텍처에서 사용한 가중치를 새로운 아키텍처에 적용한다 이때 새로운 아키텍처에서 새로운 레이어가 추가된 부분이나 없어진 부분은 가중치를 잘라내거나 무작위로 초기화한다
-
각각 수정해본 아키텍처를 T 단계만큼 미세 조정(finetuning)한다. 여기서 T는 미세조정 횟수
-
가장 좋은 모델을 선택한다
-
목표로 하는 지연시간에 도달하기 전까지 위 과정을 반복한다
아키텍처 구조
기존 mobile 경량화 모델에서 cost가 많이 드는 layer가 있다. 마지막 layer와 첫 번째 layer인데 둘 다 mobileNetV3에선 개선한다.
일단 마지막 레이어에서 average pooling(7 x 7) 사용하는 대신 pointwise(1 x 1)을 사용한다. pointwise를 대신 사용하여 bottleneck구조를 쓸 필요가 없게 만든다.
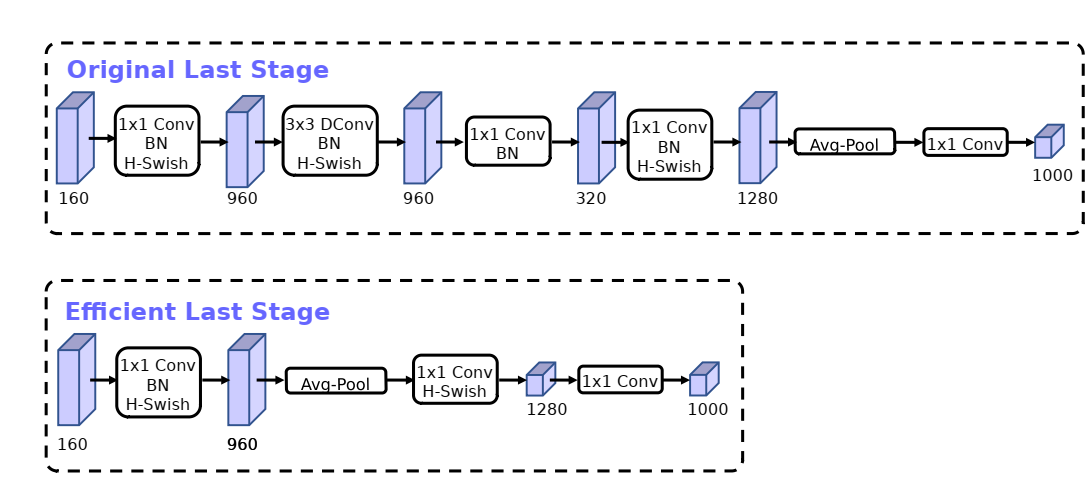
pointwise를 이용해 고차원을 저차원으로 줄이기 때문
그리고 첫 번째 단계에서 기존 아키텍처가 많은 수의 필터를 사용해서 mirror image가 많이 생겼다면 mobileNetV3에선 필터 수를 줄여 이런 중복 데이터를 줄이고 다른 비선형 함수를 이용해서 정확도를 높인다.
새로운 activation
기존 모바일 아키텍처는 nonlinear 함수로 swish를 사용해 개선을 했는데
mobileNetV3는 이것마저 개선해 새로운 h-swish를 이용한다.
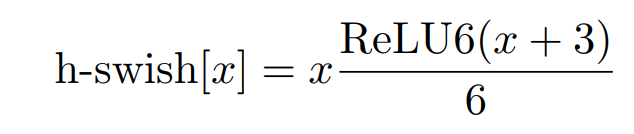
mobileNetV2를 읽었다면 알겠지만 부분적으로 선형으로 근사하는 함수인 relu를 저자들은 좋아한다. 이번 역시 swish에서 relu6 평행이동 함수로 교체해서 더 좋은 성능을 끌어 올렸다.
h-swish를 쓰면 3가지 장점은
-
많은 소프트웨어가 ReLU6의 최적화된 구현를 지원함
-
h-swish는 swish의 근사함수이기때문에 양자화 모드에서의 숫자 정밀도 손실 제거할 수 있다
-
h-swish는 본래 복잡한 함수이지만, 이를 조각 함수(piece-wise function)로 구현하면 계산량을 줄일 수 있다.
SE block 조절
mobileNetV3는 SE 알고리즘을 이용하는 데 기존에 bottleNeck이 convolution block의 크기와 비례해 정해졌다면 이번 아키텍처에선 1/4 channel expansion으로 고정했다 역시 accuracy와 latency에 좋았다
총평
mobileNetV3의 개선점은 크게 2가지가 있다.
-
NAS 알고리즘을 더함
-
기존 아키텍처의 구조를 실험을 통해 효율적으로 바꿔 개선함
개념상으론 어렵지 않으나 구현상으론 디테일한 점이 바뀌어서 특히 주의를 하며 구현해야 한다.
