구현할 것
InvertedResidual
SE Block (Squeeze-and-Excitation Block)
H-Swish Activation
NetAdapt
h-swish
import torch.nn as nn
class HardSwish():
def forward(self, x):
return x * nn.functional.relu6(x + 3, inplace=True) / 6고민을 좀 했다. 이미 구현되어 있는게 nn에 있어서 근데 이번 시리즈는 학습을 위한 목적도 있어서 그냥 위와 같이 직접 구현했다.
inplace=True는 pytorch에서 메모리를 아끼기 위해 입력 텐서를 직접 수정하게 하는 기능이다.
SE Block
간단히 개념을 생각해보면 conv를 해주면 각 채널은 담당하는 정보만을 가지고 있다. 모델이 필요한 특징중에서 중요하게 있고 안 중요한게 있을건데 그런거 상관없이 필터의 정보를 취합하는 데 SE Block은 필터 채널이 담당하는 정보의 중요도를 따지는 거다.
어떻게 따지냐면 그냥 conv에선 필터가 본인의 정보만 가진 local이라면 필터들이 서로의 정보를 알게해 global하게 만들면 됨
그걸 해주는 게 global average pooling to generate channel-wise statistics임
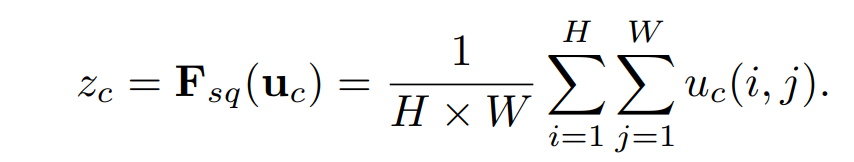
그게 뭐겠니 그럴 때 쓰는게 바로 정규화지 일단 위 식보면 흔한 비율 테크닉인게 느껴질꺼다.
비율로 바꾸는 테크닉을 왜 쓰냐? 스케일이 다른 경우를 비교 할려고 비율로 바꿔놓으면 결국엔 global한 필터 정보에서 각각의 객체가 얼마나 중요한지 비율로 알 수 있기 때문에 저런 고전적인 테크닉을 쓰는거다.
그 다음 excitaion은 다음과 같다.
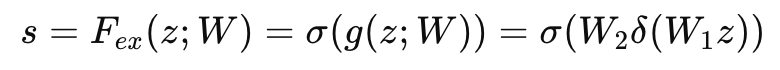
z: Squeeze 단계에서 얻은 채널 요약 정보 (벡터 형태)
w1, w2: FC 층의 가중치 매개변수
δ: ReLU 활성화 함수 (비선형성을 추가하기 위해 사용)
σ: Sigmoid 활성화 함수 (출력을 0과 1 사이로 제한)
간단하게 설명하면 w1은 차원 축소 -> δ 비선형으로 패턴 복잡하게 -> w2로 차원 복구 -> σ로 각 채널의 가중치로 이용함
이 구조 완전 bottleNeck 아니냐? 다만 bottleNeck구조에 마지막에 sigmoid를 둬서 비율로 나타낸 점만 추가 되었다.
bottleNeck으로 채널의 특징을 뽑아내서 가중치로 만들었으면 그걸 원래 채널에 곱해주면 SE Block 완성이다
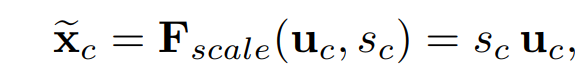
암튼 말이 길었는 데 이걸 구현해보자
import torch.nn as nn
class SqueezeExcitation(nn.Module):
"""
Squeeze-and-Excitation (SE) block implementation in PyTorch.
The SE block is designed to improve the representational power of a network
by enabling it to perform dynamic channel-wise feature recalibration.
It does so by modeling the interdependencies between channels and emphasizing
more informative features while suppressing less useful ones.
Args:
in_channels (int): Number of input channels.
reduction (int, optional): Reduction ratio for the channel dimension.
This parameter controls the size of the bottleneck. Default is 4.
Example:
se_block = SqueezeExcitation(in_channels=128, reduction=16)
output = se_block(input_tensor)
"""
def __init__(self, in_channels, reduction=4):
"""
Initializes the Squeeze-and-Excitation block.
Args:
in_channels (int): Number of input channels.
reduction (int): Reduction ratio for the intermediate channels.
"""
super(SqueezeExcitation, self).__init__()
self.in_channels = in_channels
self.reduction = reduction
# Sequentially define the operations in the SE block
self.sequential = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # Global Average Pooling to reduce spatial dimensions to 1x1
nn.Conv2d(in_channels, in_channels // reduction, kernel_size=1), # Bottleneck layer to reduce channel dimension
nn.ReLU(inplace=True), # ReLU activation for non-linearity
nn.Conv2d(in_channels // reduction, in_channels, kernel_size=1), # Restore the channel dimension
nn.Sigmoid() # Sigmoid activation to obtain a scaling factor for each channel
)
def forward(self, x):
"""
Forward pass through the SE block.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, in_channels, height, width).
Returns:
torch.Tensor: Output tensor of the same shape as the input,
with channel-wise scaling applied.
"""
scale = self.sequential(x) # Compute the scaling factors for each channel
return x * scale # Apply the computed scaling factors to the input tensor논문에서 주어진 순서대로 위와 같이 구현하면 된다.
여기서 주의할 점은 reduction이 mobileNetV3에선 4로 레시피가 정해져있다. 그래서 일단 mobileNetV3에서 사용할 거라 일단 기본값으로 4로 정해놓았다. 혹시 다른 구현에서 쓸거면 저기 4를 치우도록
다른거
는 다음시간에 구현하도록 하겠다. 겁나 길어서 ㄷㄷ
