시작
def _build_sampler(self):
with torch.no_grad():with와 no_grad()는 효율적인 메모리 관리를 위해 준 것, with는 컨텍스트 관리, no_grad()는 그래디언트를 사용하지 않는다. 샘플링은 역전파과정이 없어서 그래디언트 없어도 됨
변수 초기화
anchors = []
anchors_w_1 = []
arc_seq = []
entropys = []
log_probs = []
skip_count = []
skip_penalties = []anchors: 이전 레이어의 출력을 저장하는 리스트. 어텐션 계산 시 사용
arc_seq: 샘플링된 아키텍처 시퀀스를 저장
entropys, log_probs, skip_count, skip_penalties: 각각 샘플링 중에 발생하는 엔트로피, 로그 확률, 스킵 카운트, 스킵 패널티를 기록
LSTM 상태 초기화
prev_c = [torch.zeros(1, self.lstm_size) for _ in range(self.lstm_num_layers)]
prev_h = [torch.zeros(1, self.lstm_size) for _ in range(self.lstm_num_layers)]
inputs = self.g_emb
skip_targets = torch.tensor([1.0 - self.skip_target, self.skip_weight], dtype=torch.float32)prev_c, prev_h: LSTM의 초기 은닉 상태와 셀 상태를 0으로 초기화
inputs = self.g_emb: LSTM의 첫 번째 입력으로 사용할 임베딩 벡터
skip_targets: 스킵 연결 확률과 그 가중치를 정의, 스킵 연결에서의 선택 여부를 제어
각 레이어에서의 반복 (LSTM 스텝)
for layer_id in range(self.num_layers):
if self.search_whole_channels:layer_id: 현재 레이어의 인덱스
self.search_whole_channels: 채널 전체에서 탐색할지 여부를 제어
LSTM 계산 및 Softmax 샘플링
next_c, next_h = stack_lstm(inputs, prev_c, prev_h, self.w_lstm)
prev_c, prev_h = next_c, next_h
logit = torch.matmul(next_h[-1], self.w_soft)stack_lstm(): 현재 입력을 통해 다음 셀 상태(next_c)와 은닉 상태(next_h)를 계산
logit: LSTM의 마지막 은닉 상태에 self.w_soft 가중치를 곱해 나온 결과. 이는 소프트맥스 함수에 전달되어 확률을 계산하는 데 사용
if self.temperature is not None:
logit /= self.temperature
if self.tanh_constant is not None:
logit *= self.tanh_constant * torch.tanh(logit)temperature: 온도 조정 매개변수로, 값이 작을수록 예측 분포가 날카로워지고 값이 클수록 분포가 평탄해짐
tanh_constant: LSTM의 출력값을 제어하여, 더 부드러운 변화를 유도
branch 샘플링
if self.search_for == "macro" or self.search_for == "branch":
branch_id = torch.multinomial(F.softmax(logit, dim=-1), 1)
branch_id = branch_id.view(1)branch_id: 소프트맥스 함수를 적용한 logit 값을 바탕으로 확률적으로 branch를 선택
로그 확률과 엔트로피 계산
arc_seq.append(branch_id)
log_prob = F.cross_entropy(logit, branch_id)
log_probs.append(log_prob)
entropy = log_prob.detach() * torch.exp(-log_prob.detach())
entropys.append(entropy)
inputs = self.w_emb[branch_id]arc_seq: 선택된 branch를 저장.
log_prob: 선택된 branch에 대한 로그 확률을 계산하여 저장.
entropy: 선택의 불확실성을 나타내는 엔트로피를 계산하여 저장.
inputs: 다음 LSTM 레이어에 사용할 임베딩 벡터를 설정.
Skip Connection 로직
next_c, next_h = stack_lstm(inputs, prev_c, prev_h, self.w_lstm)
prev_c, prev_h = next_c, next_h
if layer_id > 0:
query = torch.cat(anchors_w_1, dim=0)
query = torch.tanh(query + torch.matmul(next_h[-1], self.w_attn_2))
query = torch.matmul(query, self.v_attn)query: 어텐션 계산을 위한 쿼리로, 이전 레이어 출력(anchors_w_1)과 현재 은닉 상태(next_h[-1])를 결합하여 어텐션 값(쿼리)를 계산.
logit = torch.cat([-query, query], dim=1)
skip = torch.multinomial(F.softmax(logit, dim=-1), 1)
arc_seq.append(skip)logit: 쿼리로부터 계산된 어텐션 값으로, 스킵 연결의 확률을 계산.
skip: 확률적으로 스킵 연결을 선택하고, 선택 결과를 arc_seq에 저장
KL Divergence와 Skip Penalties 계산
skip_prob = torch.sigmoid(logit)
kl = skip_prob * torch.log(skip_prob) / skip_targets
kl = torch.sum(kl)
skip_penalties.append(kl)skip_prob: 스킵 연결 확률을 시그모이드 함수로 계산.
KL divergence를 통해 스킵 연결의 페널티를 계산하고, 이는 샘플링 결과에 패널티를 부여하는 데 사용
결과 값 저장
arc_seq = torch.cat(arc_seq, dim=0)
self.sample_arc = arc_seq.view(-1)
entropys = torch.stack(entropys)
self.sample_entropy = entropys.sum()
log_probs = torch.stack(log_probs)
self.sample_log_probs = log_probs.sum()
skip_count = torch.stack(skip_count)
self.skip_count = skip_count.sum()
skip_penalties = torch.stack(skip_penalties)
self.skip_penalties = skip_penalties.mean()self.sample_arc: 샘플링된 아키텍처 시퀀스를 저장.
self.sample_entropy, self.sample_log_probs: 각 샘플에 대한 엔트로피와 로그 확률의 합계를 저장.
self.skip_count: 스킵 연결이 발생한 횟수를 저장.
self.skip_penalties: 스킵 연결에 대한 페널티의 평균을 저장.
전체적인 흐름
build_sampler()는 컨트롤러를 이용해 아키텍처를 만드는 과정이다
Enas의 macro search space는 전체적인 아키텍처를 한 번에 결정하는 방법이다. 이 전체적인 아키텍처를 만들어 최고의 아키텍처를 찾는 방법은 다음과 같다
Enas의 흐름
-
build_sampler()로 전체적인 아키텍처 하나를 만듬
-
하나의 아키텍처로 파라미터를 지속적으로 학습한다. (w-shared) 학습된 파라미터는 그 다음 아키텍처를 만들때 그대로 이용되서 논문에서 말하듯 굉장히 효율적인 탐색이 가능함(cifar 이미지를 이용해 cnn분류에서 약 50000배 시간 단축)
-
아키텍처를 이용해 최고의 아키텍처를 reward로 찾는 학습을 진행하고 최고의 아키텍처를 찾는다.
build_sampler()의 흐름
- lstm을 이용해 아키텍처의 순서를 만든다. prev_c, prev_h: LSTM의 이전 층의 상태를 나타내고 이전 상태와 현재 입력값을 바탕으로 다음 상태(next_c, next_h)를 계산하여 아키텍처의 다음 부분을 샘플링한다
inputs: 현재 샘플링한 아키텍처 부분을 다음 샘플링 과정의 입력으로 사용합니다. 초기 입력은 g_emb라는 임베딩이다.
- softmax를 이용해서 어떤 선택을 할지 결정한다. 이때 logit을 조정하는 데 logit이란 뉴럴 네트워크의 출력 층에서 최종 결과를 확률로 변환하기 전의 값으로 이걸 softmax를 적용해 최종적인 판단을 하게 확률로 만든다. build_sampler()에선 logit에 temperature란 기법을 적용한다. distilation에서 나온 기법으로
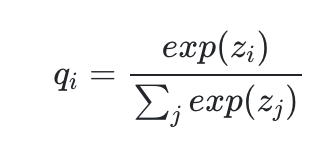
이게 평범한 logits에 softmax를 적용한 결과라면
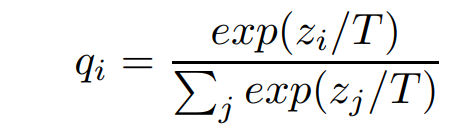
이건 logits에 T란 temperature를 역수로 취해줘서 softmax의 값들을 평탄하게 만든다
Nas 알고리즘에서 확률을 평탄하게 만드는 의미는 무엇일까? nas란 결국 다양한 아키텍처를 뽑는것인데 그 아키텍처를 뽑는 확률이 아주 뾰족하다고 생각해보자.
예를 들어서 a1, a2, a3, a4, ... 이런 아키텍처의 레이어 후보가 있는데 a1을 선택할 확률이 99%라면 거의 무조건 a1만 뽑아서 탐색하는 아키텍처를 만들것이다. 전체적인 레이어를 뽑을 확률이 이딴식이라면 다양한 아키텍처를 뽑는다는 nas의 의미가 퇴색되고 만다.
그래서 logits에 temperature를 적용해서 레이어들을 뽑을 확률을 일부러 평탄화 시키는 것이다.
그 결과 레이어를 뽑을 확률이 별 차이가 없으니 다양한 레이어들을 뽑을 수 있다.
결국 temperature란건 레이어의 다양성을 내가 임의로 조절하게 해주는 방법으로 Enas에선 초반에 temperature를 높게하여 레이어들을 다양하게 뽑고 후반에는 temperature를 낮춰서 레이어들을 고정시키는 방법이다
-
엔트로피를 이용하여 불확실성을 계산해준다. 엔트로피에 로그를 적용해서 나중에 보상함수로 쓰인다. 이건 내가 나중에 다양한 nas 알고리즘을 섞을 예정이라 바뀔수 있다.
-
어텐션을 이용해 skip을 정해준다. skip은 레이어들을 연결할건지 말건지 결정만 해서 구현할 수 있다.
실제로 구현에선 KL Divergence를 이용해서 모델이 예측한 skip 연결 확률 분포와, 우리가 기대하는 분포(목표 확률) 사이의 차이를 계산하고 패널티 항을 추가해서 skip을 구현한다
