Question
This is not sequence base model. Why does the authors expect the last token have summary representation of the entire sequence?
- (Decoder only) Model is trained to predict the next token in the sequence
- Even for Encoder only model, model is trained to predict the next sequence
- This means that the last token’s embedding is computed based on all previous tokens
- And we can expect the last token would have rich embedding
How reusing the last token embedding is justified?
- Each segment of time series data is converted into a prompt
- Example
- In real-time or online systems, once a model has been trained and a specific time series segment has been converted into a prompt, that prompt may not change frequently.
- Let’s say the time series describes hourly temperature data. If the prompt created from yesterday's temperature is the same as what is required for real-time analysis, storing the last token embedding means that the model can simply reuse that embedding instead of recalculating it every time.
Reduction in computational cost is mentioned because of using only the last token.
Storing the last token comes into play when the input prompt remains unchanged during inference.
Abstract
Background
- Existing MTSF methods suffer from limited parameterization and small scale training data
- Using LLM incurs heavy computational costs
Suggestion
- Dual-modality encoding module with two branches
- Time series encoding branch
- low quality yet pure embeddings
- LLM-empowered encoding branch
- wrap the same time series as prompts to obtain high quality yet entangled prompt embeddings via a Pre-trained LLM
time series → prompt (entangled)
- wrap the same time series as prompts to obtain high quality yet entangled prompt embeddings via a Pre-trained LLM
- Time series encoding branch
- Cross-modality alignment module
- To retrieve high quality and pure time series embeddings
- Last token embedding storage
- Encode sufficient temporal information into a last token
- Reduce computational costs
1. Introduction
Time series based LLM
- They replace LLM’s tokenizer with a randomly initiailized embedding layer
- Embedding layer is still trained with limited data(ts), and a domain gap exists between time series and language data
Prompt based LLM
- LLM wrap the original time series to achieve the data to text transformation
- Prompt based LLM can show better performance than time series based methods
Data entanglement issue
- Text prompt consists of some words and the numeric in the original time series
- It would be converted into tokens
- Word token embedding would be aggregated into time series tokens,
they might degrade the performance - In most existing prompt based LLM, univariate time series is calculated separately,
which prevents the methods from learning dependencies between multiple variables
Heavy computational burden of prompt based LLM
3. Preliminaries
Multivariate Time Series
- N : number of variables
- is a N-dimensonal vector
Prompt
- Convert the original time series into N prompts
- has S elements
Total trend value
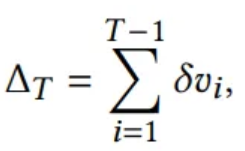
4. Methodology
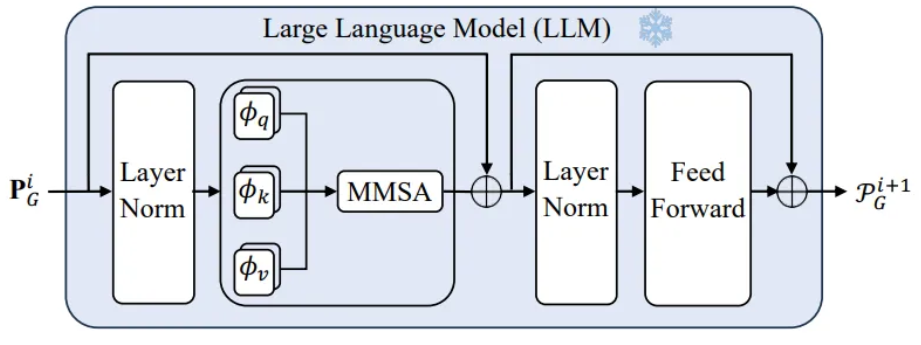
4.1. Framework
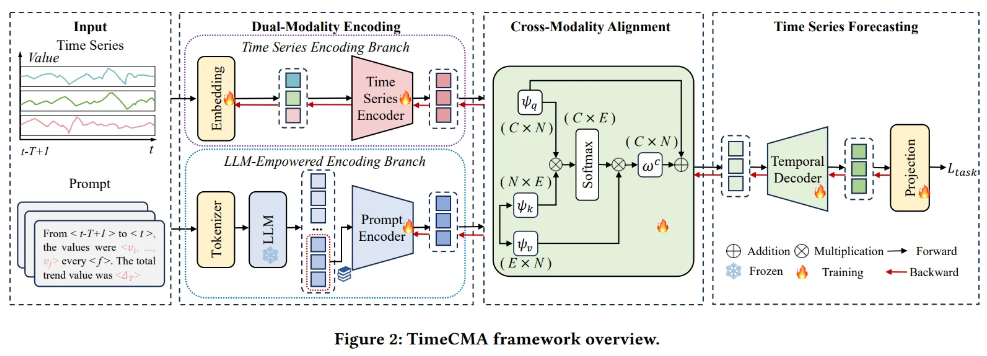
Dual-Modality Encoding
Time Series Encoding Branch
- Inverted embedding layer
- Embed the original time series into a single vector
- Time series encoder
LLM-Empowered Encoding Branch
- Pre-trained LLM
- Extract high quality prompt embeddings
- Prompt encoder
Cross-Modality Alignment
- Aggregate the learned time series and prompt embeddings
Purpose
- Retrieve high quality time series embeddings from prompt embeddings
Time Series Forecasting
- Decode the aligned time series embeddings
4.2. Dual-Modality Encoding
4.2.1 Time Series Encoding Branch
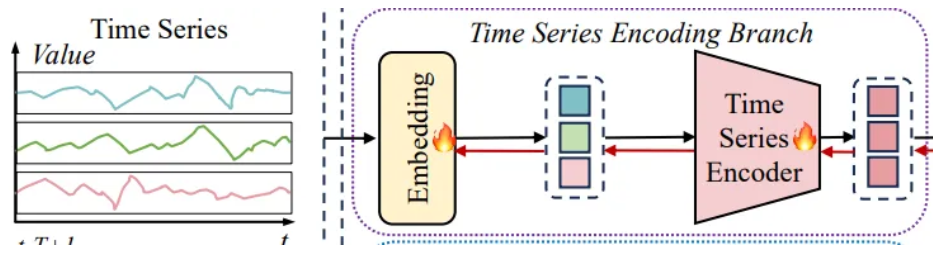
- Due to longer training time associated with channel independence,
unsuitable for time series data involving more variables - Channel independence overlooks the dependencies between multiple variables
Embedding
- RevIN
- Normalized is embedded by a linear layer
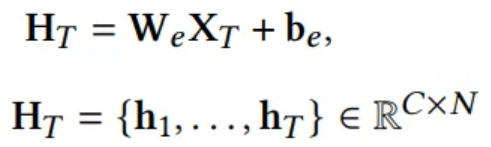
Time Series Encoder
- Layer Normalization
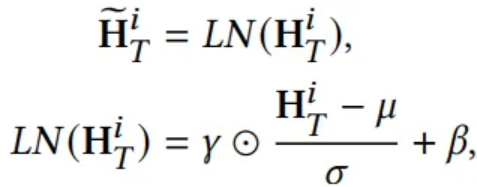
- Multi Head Self Attention
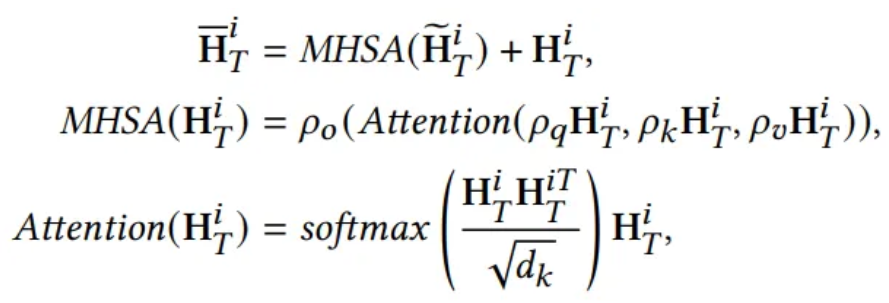
- Feed Forward Network
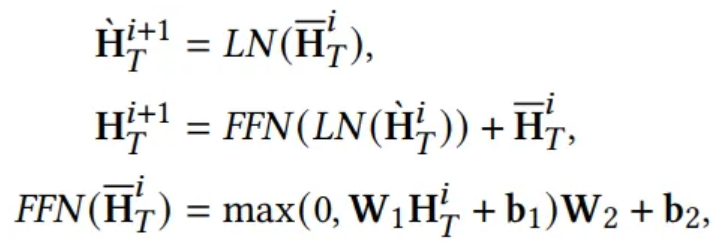
4.2.2 LLM-Empowered Encoding Branch
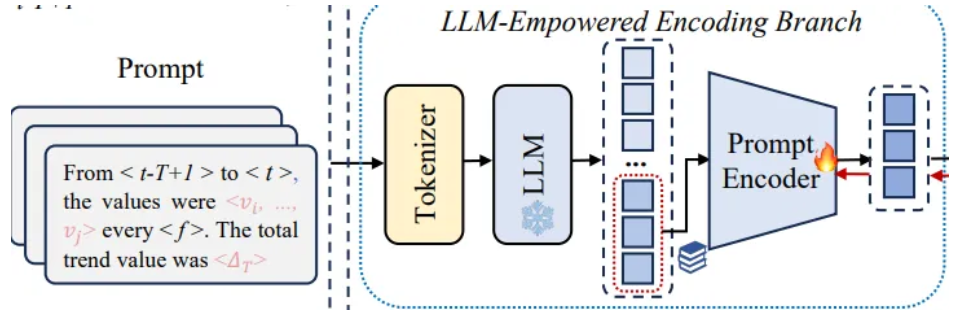
GPT2 tokenizer and GPT2 model
Pre-trained LLM
- Convert prompt input into a series of token IDs
- : the token ID number in a prompt
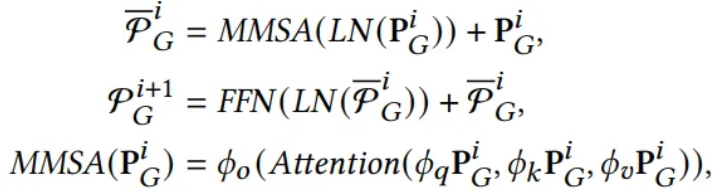
Last Token Embedding Storage
- Not all tokens are equaly important for language model training
- Last token in a prompt holds the most comprehensive knowledge
- Due to the masked multi self attention
- Last token at position is influenced by its previous tokens
- To maintain consistent embedding lengths under a variable,
append the last token as padding until the same length
4.3. Cross-Modality Alignment
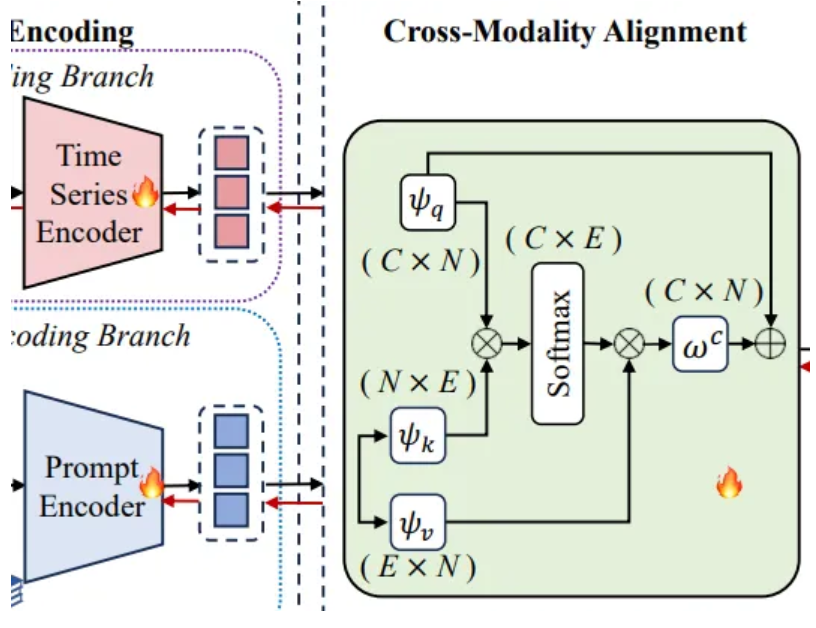
Goal : Retrieve high quality embedding
- To aggregate the dual modality features, should align time series and prompt embeddings
- Low quality time series embedding as query
- Prompt embedding as key, value
4.4. Time Series Forecasting
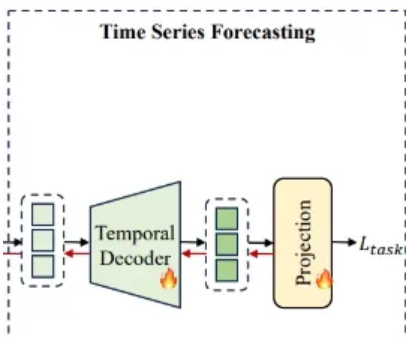
Temporal Decoder
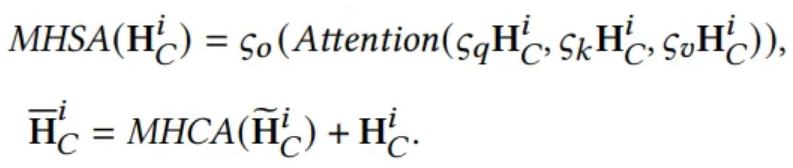
- Normalized embedding
- : Masked Multi-head Self Attention with residual connection
- Output :
Projection function
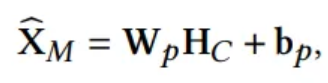
- Normalize the
4.5. Overall Objective Function
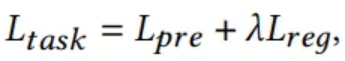
- : Prediciton loss (MSE)
- : Regularization loss (L2)
- : weight of trading off the prediction and regularization loss
5. Experiment
5.1. Experimental Setup
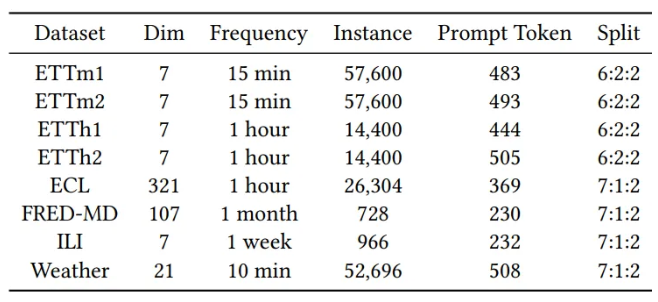
5.1.1. Dataset
- Average token number of a prompt for each dataset
5.1.3. Implementation
- LLM based methods use GPT-2 as the backbone
- Test batch size is set to 1
5.2. Main Results
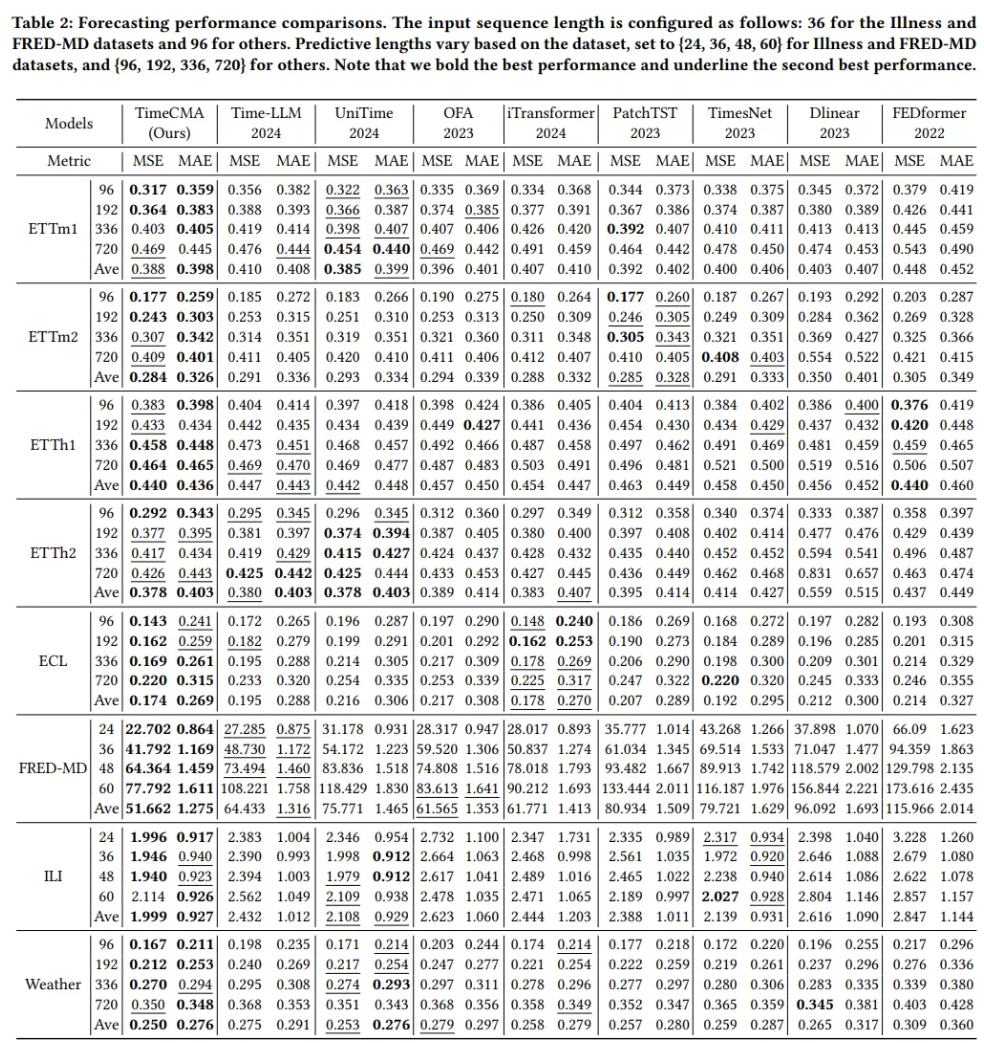
- LLM based methods perform better than traditional methods
- Prompt based LLM outperform time series based LLM
- Due to enhanced time series embeddings through prompt embeddings
- UniTime is trained on all datasets and tested a dataset
- TimeCMA is trained on a dataset and tested a dataset
5.3. Ablation Studies
5.3.2. Results of prompt design
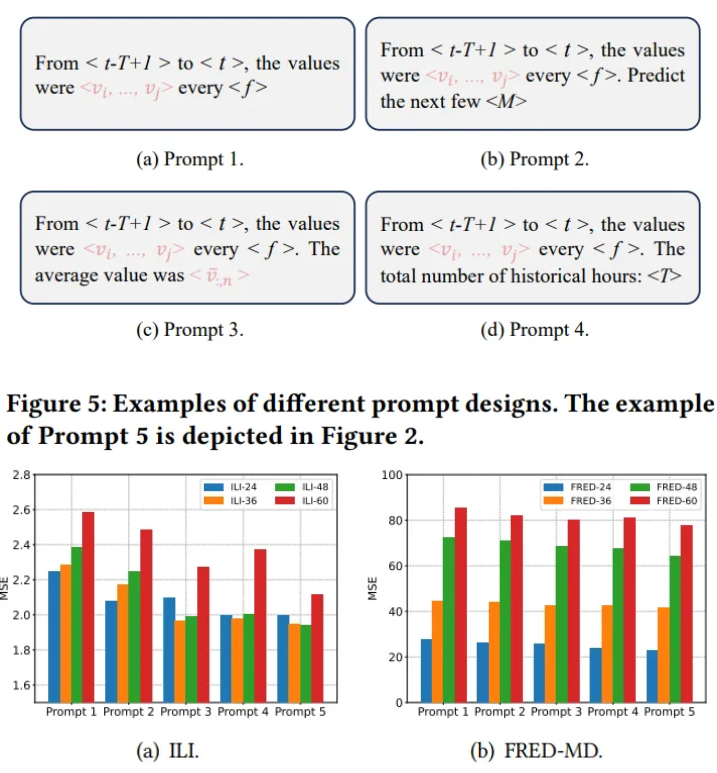
- Extract time and value information directly
- Forecasting guidance
- Summarize the average value
- Historical time information
- Calculate the trend value
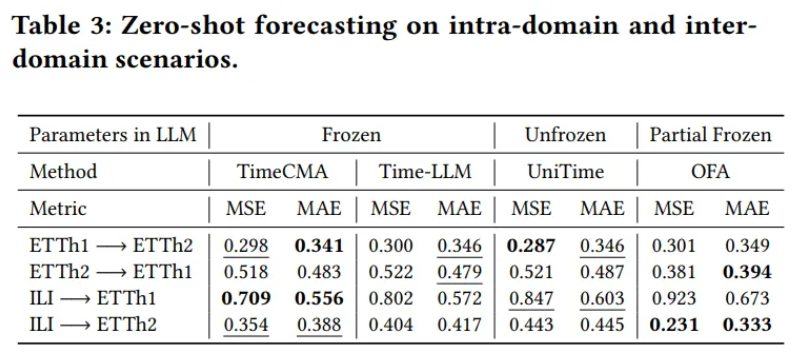
5.4. Zero shot
Train on ETTh1, ETTh2, ILI
5.5. Model Analysis
Last token attention analysis
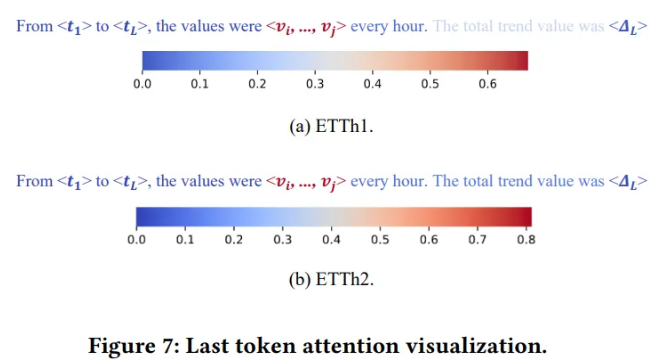
- Last token attention from the last layer of GPT2
- Segment the words and values in the prompt into nine segments
- Attention of the last segment to the previous eight segments
- Highest attention on the fifth segment corresponding to the values in prompt
- → Last token can save computing costs while maximizing value information
TSNE visualization
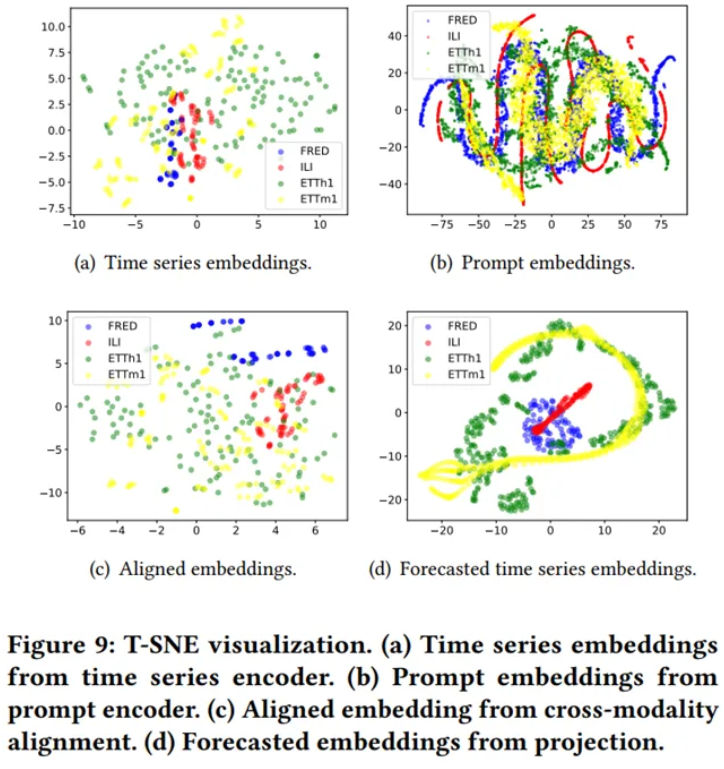
- Time series encoder can capture the distinct characteristics
- More complex inter-relation
- Similar types of data points closer together
- Forecasted time series embeddings form well separated clusters
