Lec 4-Free Memory Management
Basics
Dynamic allocation of pages
- Page table allows the OS to dynamically assign physical frames to process on-demand
- On Linux, processes use sbrk(), brk(), mmap() to request additional heap pages
- But, only allocates memory in multiples of 4KB pages
malloc & free
- Each process manages its own heap memory
- glibc implements malloc() and free(), manages objects on the heap
- JVM uses a garbage collector
- Explictly allocate and deallocate memory
- Programmers can malloc() any size of memory
- free() takes a pointer, but not a size
- How does free() know how many bytes to deallocate
- Pointers are returned to the programmer
- Code may modify these pointers
- Opposed to Java or C# where pointers are managed
Goals
- Keep track of memory usage
- Store the size of each allocation
- free() will work with just a pointer
- Minimize fragmentation
Heap fragmentation
- Variable size segments can lead to external fragmentation
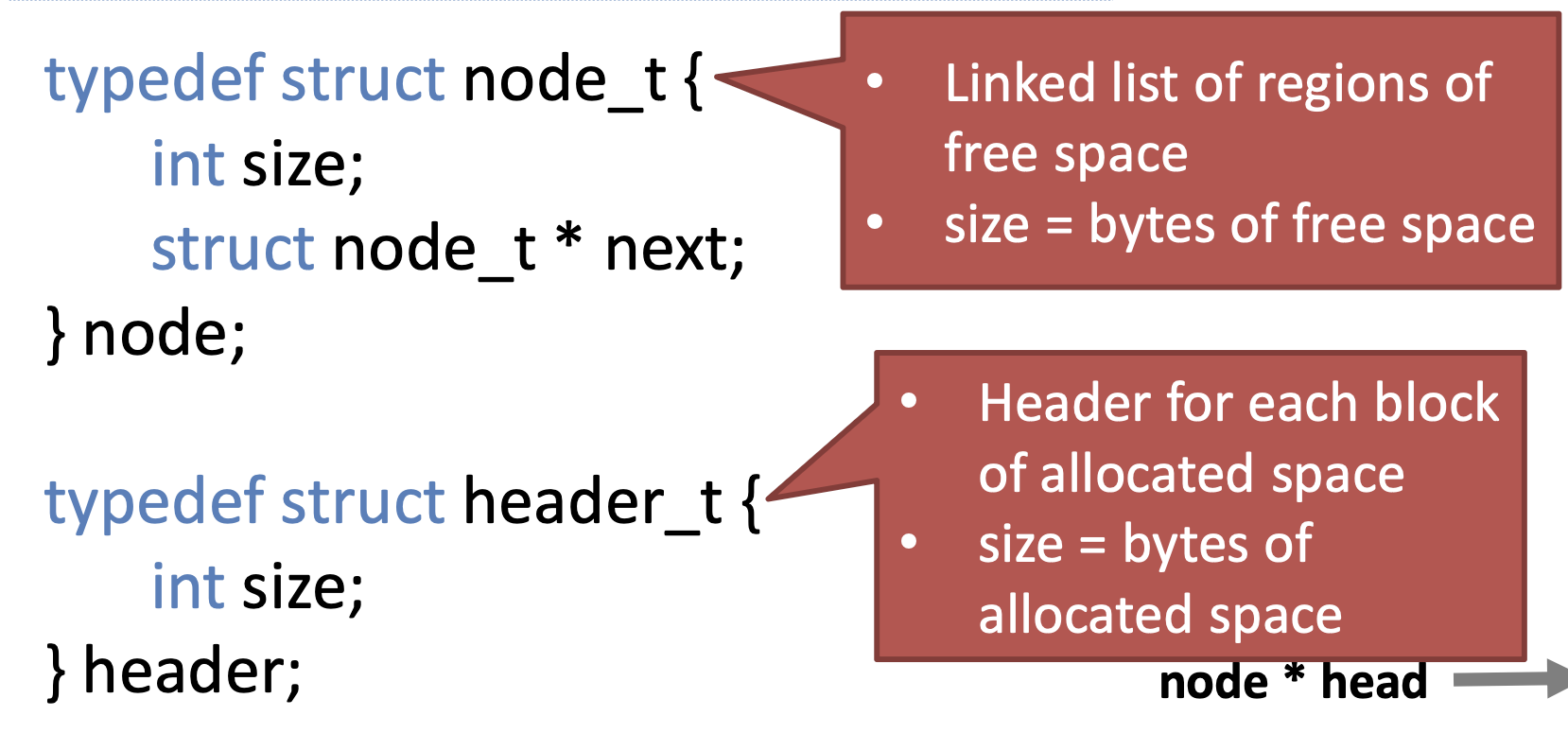
Free list
Data structure for managing heap memory
Key components
- A linked-list that records free regions of memory
- Free list is kept in sorted order by memory address
- Each allocated block of memory has a header that records the size of the block
- Algorithm that selects which free region of memory to use for each allocation request
Free list data structure
- Stored in heap memory
- For malloc(n)
- num_bytes = n + sizeof(header)
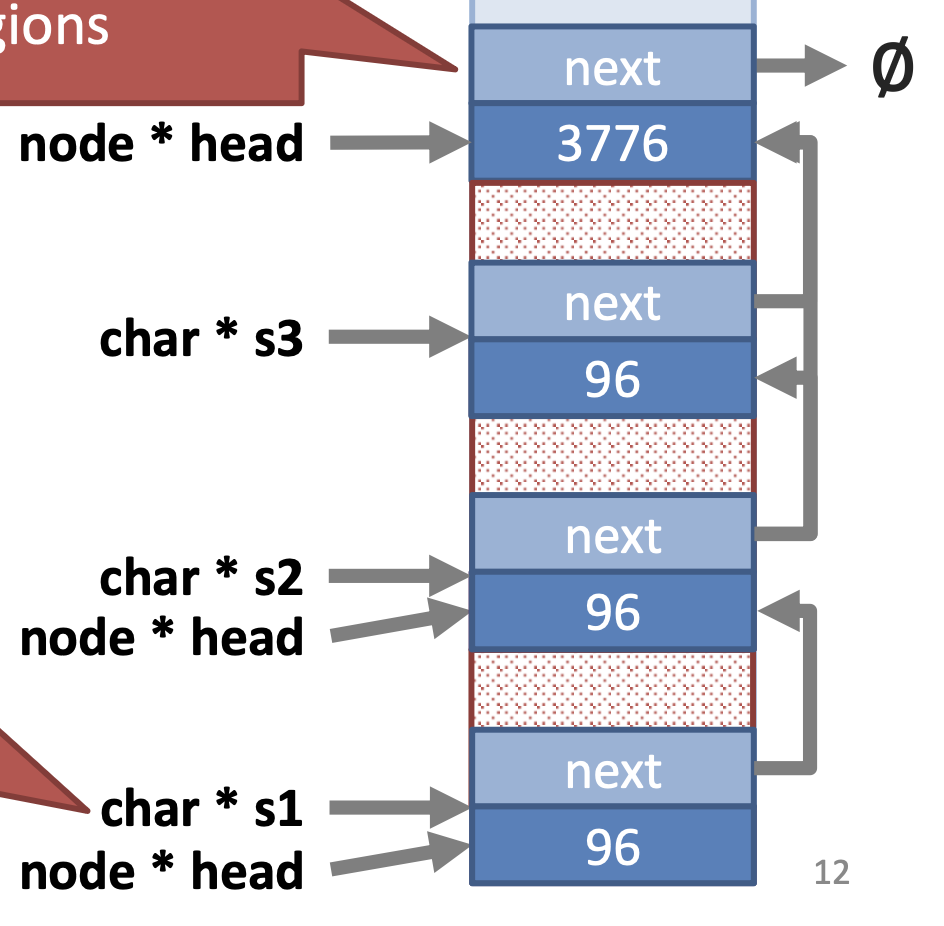
- Freeing memory
- All memory is free, but the free list divided into four regions
char * s1, s2, s3 are dangling
- They still point to heap memory, but invalid
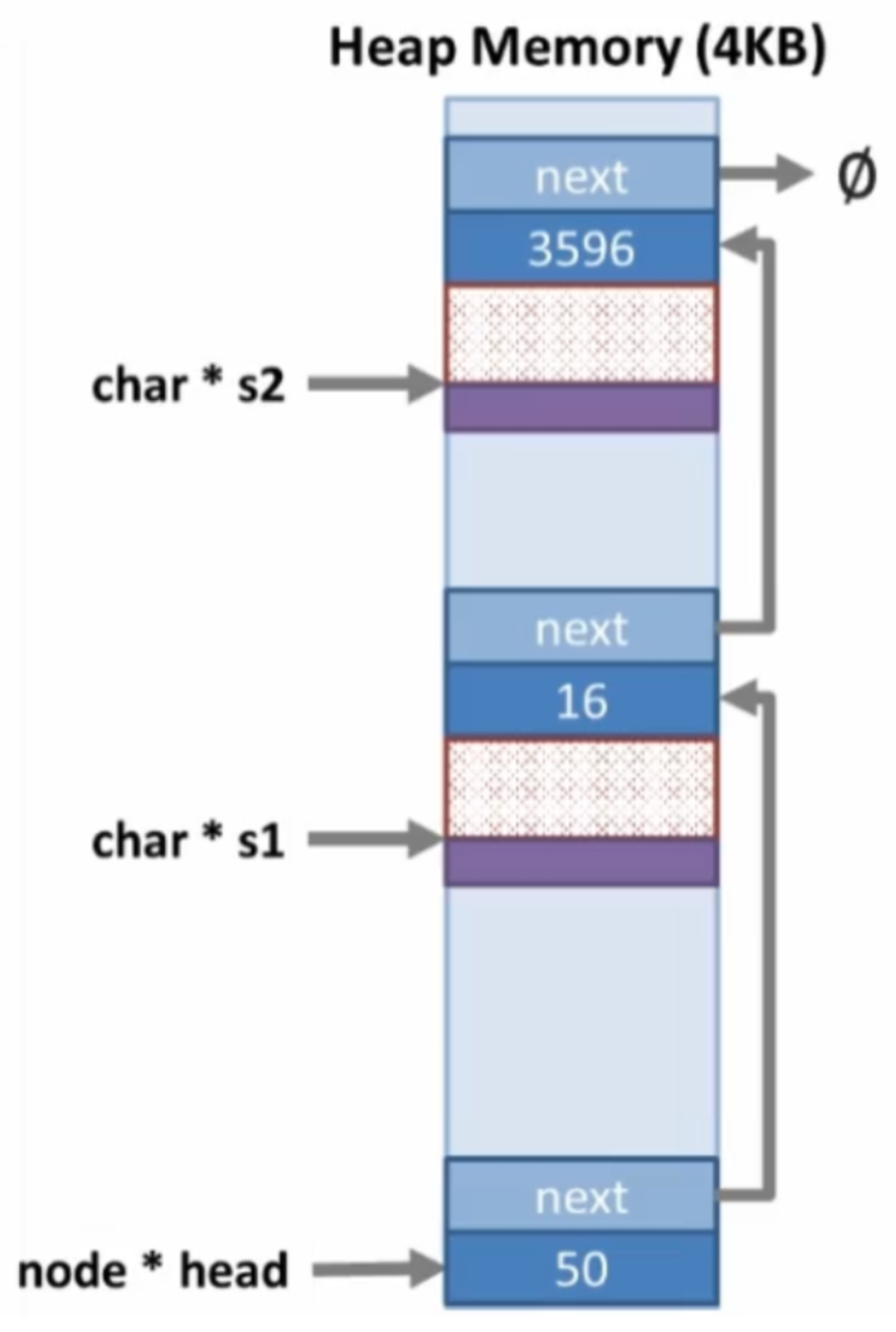
- Coalescing
- Free regions should be merged with their neighbors
- Helps to minimize fragmentation
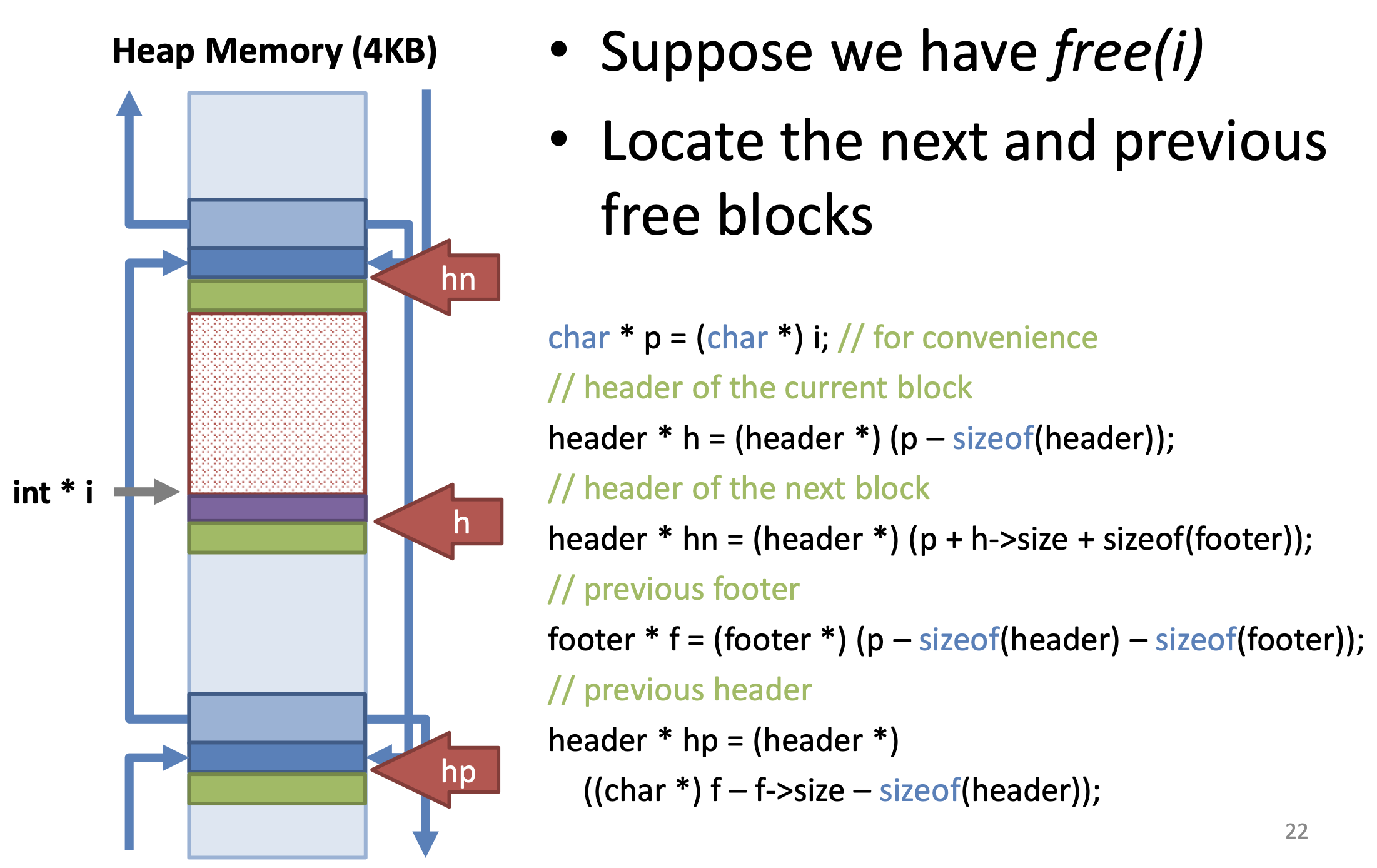
Choosing Free regions
int i[] = (int*) malloc(8); // 8 + 4 = 12 bytes
- Which free region should be chosen?
First Fit
- Split the first free region with >=8 bytes available (actually 12 bytes)
- Problems: Leads to external fragmentation
Best Fit
- Locate the free region with size closest to 8 bytes
- Less external fragmentation than First-Fit
- Problems: Requires O(n) time
Free List Review
- Linked free list
- List is kept in sorted order
- free() is O(n) operation
- Adjacent free regions are coalesced
- Stragies for selecting which free region to use for malloc(n)
- First-Fit
- Use the first free region with >= n bytes avail
- Worst-case is O(n), but much faster
- Lead to external fragmentation
- Best-Fit
- Use the region with size closest to n
- Less external fragmentation, but O(n) time
Improvements
1. Use a circular linked list and Next-Fit
- Use First-Fit, but move head after each split
- Next-Fit
- Helps spread allocations, probabilistically reduce fragmentation
- Faster than Best-Fit
- free() is O(n) because the free list must be kept in sorted order
- If we free memory, we must find adjacent free block by searching the free list
- Doubly linked list (Add footers to each block)
- Enables coalescing without sorting the free list (free() becomes O(1))
- Don't need to find adjacent free region by searching free list
- Example
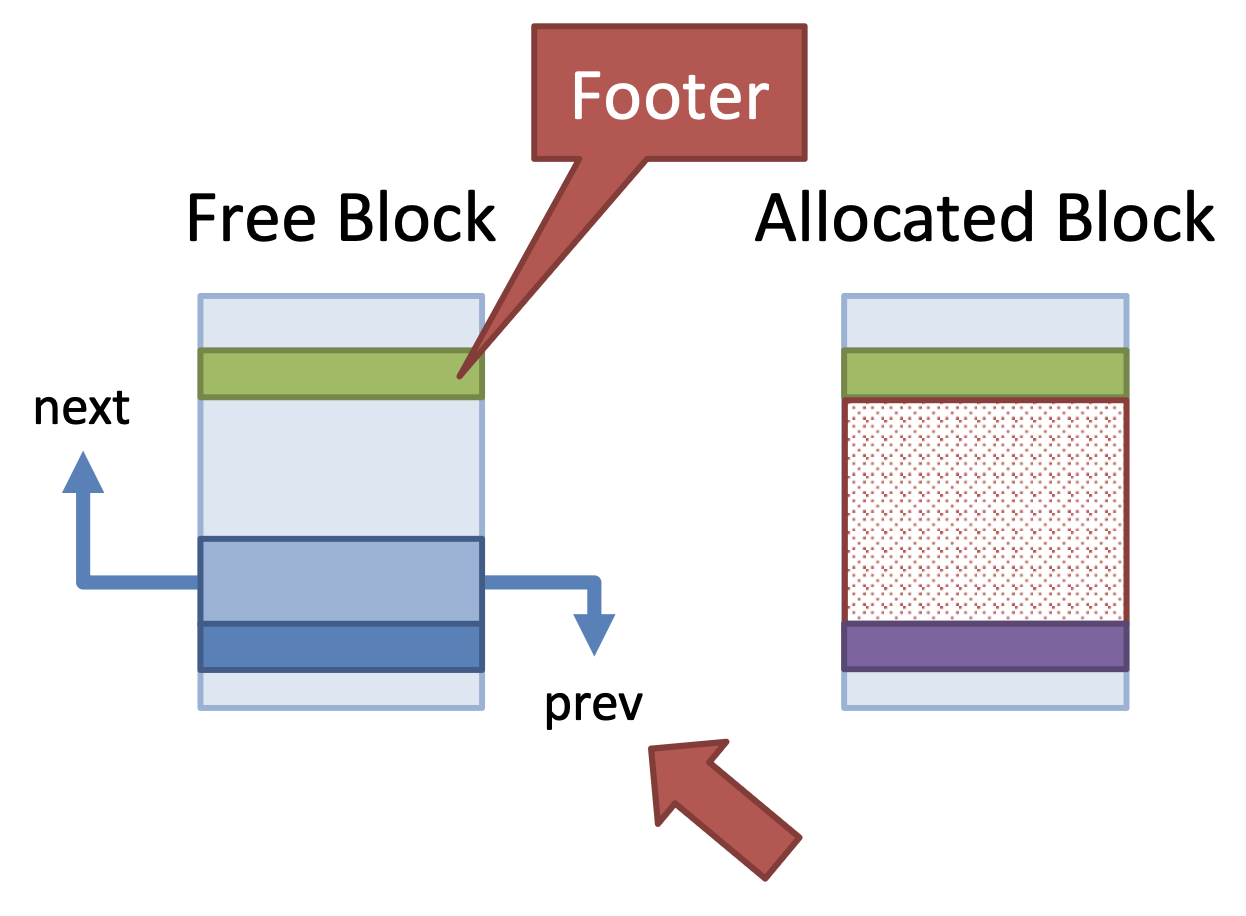
- Coalescing is O(1)
3. Use bins to quickly locate appropriately sized free regions
- But, malloc() still has problems
- Next-Fit: O(1) but more fragmentation
- Best-Fit: O(n) but less fragmentation
- Solution
- Round allocation request to powers of 2
- Less external fragmentation, some internal fragmentation
- 10 bytes request -> allocate 16 bytes
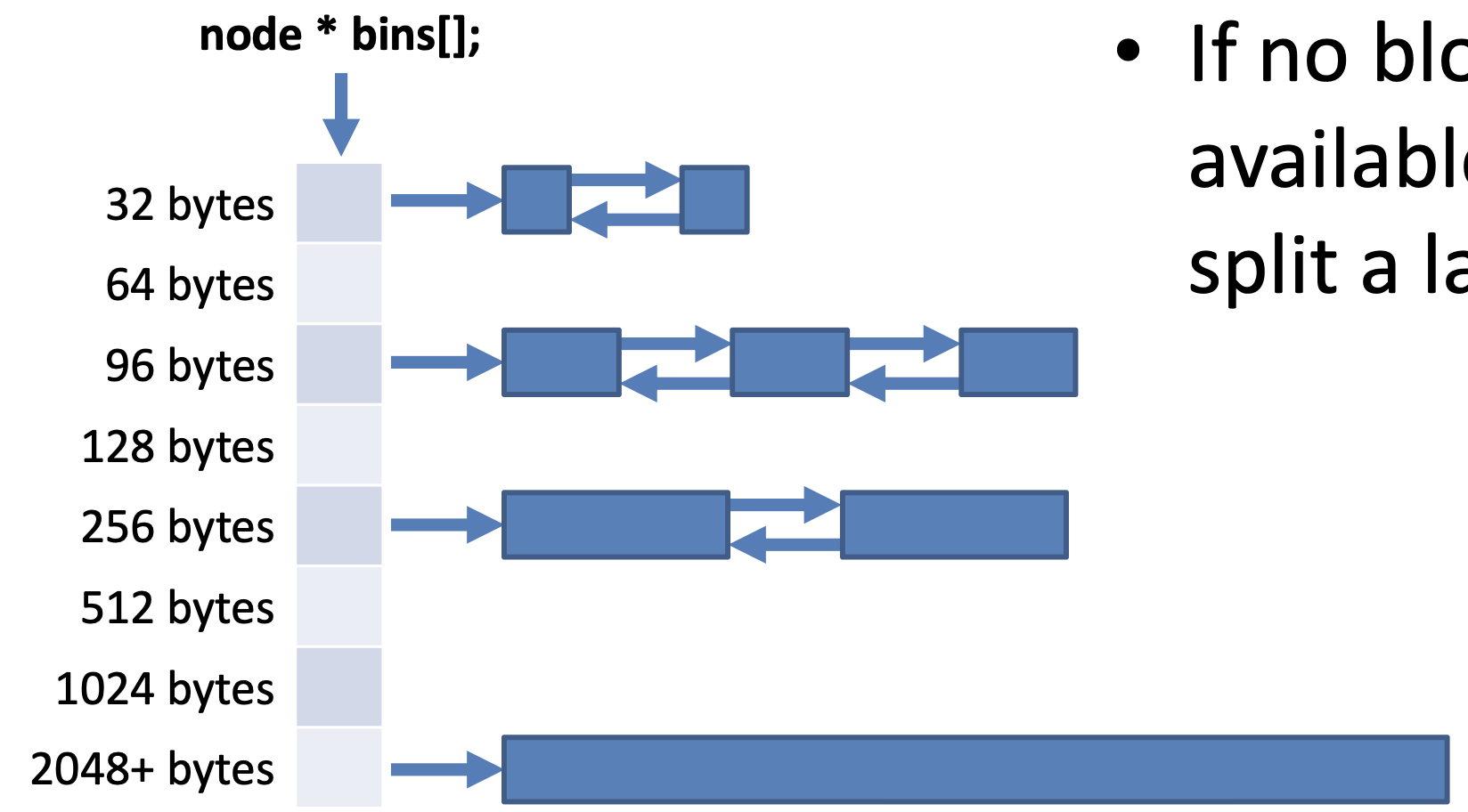
- Divide the free list into bins of similar size blocks
- Locating a free block of size round(x) will be O(1)
- 1. Rounding Allocations
- If size > 2048, size is multiple of 4KB (for large allocation, use full pages)
- elif size < 128, size is multiple of 32 (ensure the external fragmentation size is not smaller than 32 bytes)
- else size is round to next power of 2
- 2. Binning
- Divided the free list into bins of exact size blocks
- Most allocations is O(1) time by pulling a free block from the appropriate list
- If no block, locate and split a larger block
Parallelism
The free list is shared, it must be protected by a mutex
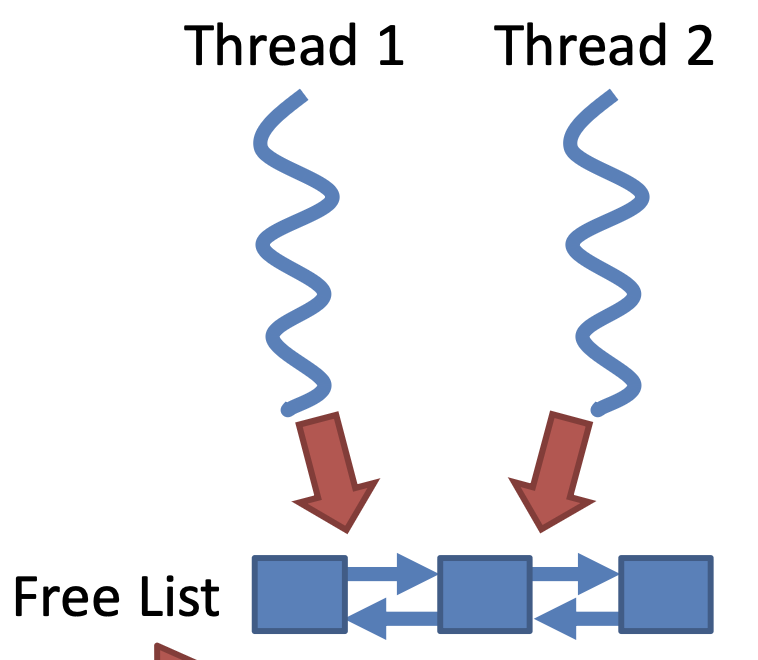
Objects for different threads may share the same cache line-> can cause contention between CPU cores
Per Thread Arenas
- To reduce lock and CPU cache contention, divide the heap into arenas
- Each arena has its own free list
- Each thread is assigned to several arenas
Speeding up code
Use an object cache + slab allocation
- Objects are allocated in bulk
- Less space wasted on headers and footers

Memory Management Bugs
1. Forget to free
- If this program run for a long time, exhaust all available virtual memory
2. Dangling pointer
- Even though we free a pointer, we still access the address
- Behavior is nondeterministic
- May print previous value or garbage
3. Double free
- Corrupt the free list
- The same address is entered twice in the free list
-> Two different malloc can be allocated the same address
