TLB: Translation Lookaside Buffer
Problem : Page Table is slow
- Page tables are large, and they must go in RAM
- Each virtual memory access must be translated
- Each translation requires a table lookup in memory
- Memory overhead is doubled
Caching
- Cache page table entries in the CPU's MMU
- TLB stores recently used PTEs
- CPU cache is very fast
- Translations that hit the TLB don't need to be looked up in memory
TLB Entry

- Do not cache the entire page -> need the index (VPN)
- G : global page?
- ASID : address space ID
- D : dirty bit : written recently?
- V : valid bit : valid?
- C : cache coherency
TLB control flow
- TLB Miss
- Load the page table entry from the memory,
Add it to the TLB
Retry instruction
- Load the page table entry from the memory,
Comparison
- 10KB array of integers
- 4KB pages
- without TLB
- How many memory accesses are required?
- 10KB/4 = 2560 integers
- Each requires one page table lookup, one memory read
- 5120 reads
- How many memory accesses are required?
- with TLB
- TLB starts off cold (empty)
- 2560 to read the integers
- 3 page table lookups (3 pages will be cached)
- 2563 reads
Locality
- Spatial locality
- If you access address x, you will access x+1 soon
- Most of the time, x and x+1 are in the same page
- Temporal locality
- If you access address x, you will access x again soon
- The page containing x will still be in the TLB
Problems
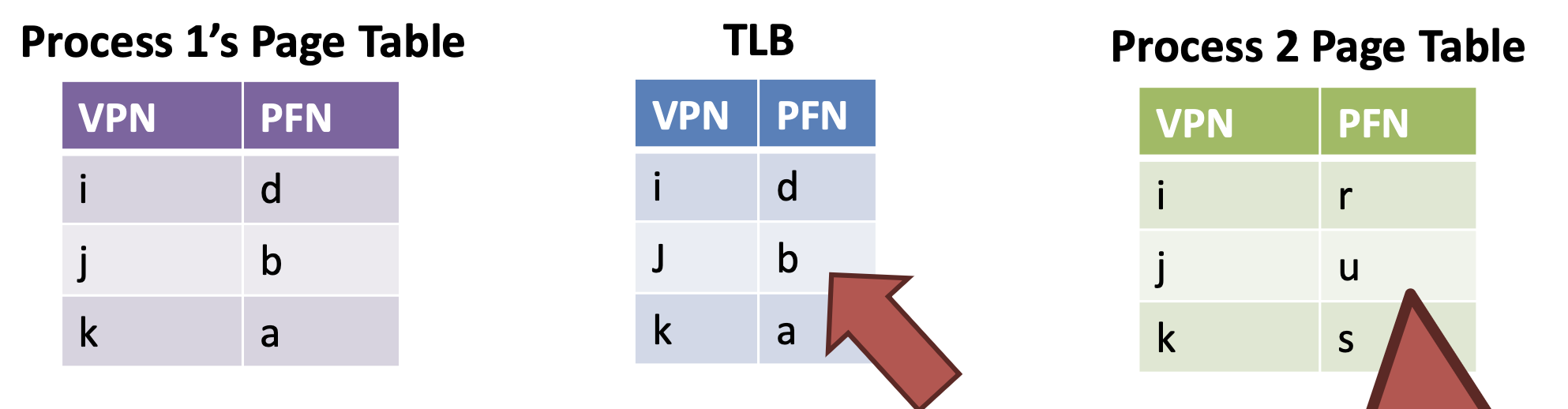
- TLB entries may not be valid after a context switch
- VPNs are the same, but PFN mappings have changed
Solutions
- Clear the TLB after each context switch
- Each process will start with a cold cache
- Associate an ASID with each process
- ASID is just like a PID in the kernel
- CPU can compare the ASID of the active process to the ASID stored in each TLB entry
- If don't match, TLB entry is invalid
- Why don't use PID?
- If different processes have same ASID, the memory are shared
Replacement Policies
- FIFO
- Random
- LRU: Least Recently Used
Hardware vs Software management
-
Hardware TLB
- Pros
- Easier to program = Less work for kernel developers,
CPU does a lot of work- CPU manages all TLB entries
- Easier to program = Less work for kernel developers,
- Cons
- Complex management is difficult
Limited ability to modify the TLB replacement policies
- Complex management is difficult
- Pros
-
Software TLB
- Pros
- Greater flexibility = No predefined data structure for the page table
- Free to implement TLB replacement policies
- Cons
- More work for kernel developers
- CPU don't
- Try to read the page table
- Add/remove entries from the TLB
- CPU don't
- More work for kernel developers
- TLB Miss
- CPU don't manage, occur Exception
- Then, OS handles the exception
- Insert the PTE into the TLB
- Tell the CPU to retry the previous instruction
- Pros
Advanced Page Tables
Problem: Page Table size
- Example
- 32-bit system with 4KB pages
- Each page table is 4MB
- Most entries are invalid
Solution 1: Bigger pages
- Increase the size of pages
- 32-bit system with 4MB pages
- 1024 * 4 bytes per page = 4KB page tables
- Problems
- Increased internal fragmentation
- Programs will have much less than 4MB
Solution 2: Alternate Data structures
- Hash table or Tree
- Why non-feasible?
- Can be done of the TLB is software managed
- If the TLB is hardware managed, OS must use the page table format specified by the CPU
Solution 3: Inverted Page Tables
Flip the table
- Map physical pages to virtual pages
- Pros
- Only one physical memory,
-> only need one inverted page table
- Only one physical memory,
- Cons
- Lookups are more expensive
- Table must be scanned to locate a given VPN
- What about shared memory?
- Implement VPN with a list
-> More time with searching
- Implement VPN with a list
- Lookups are more expensive
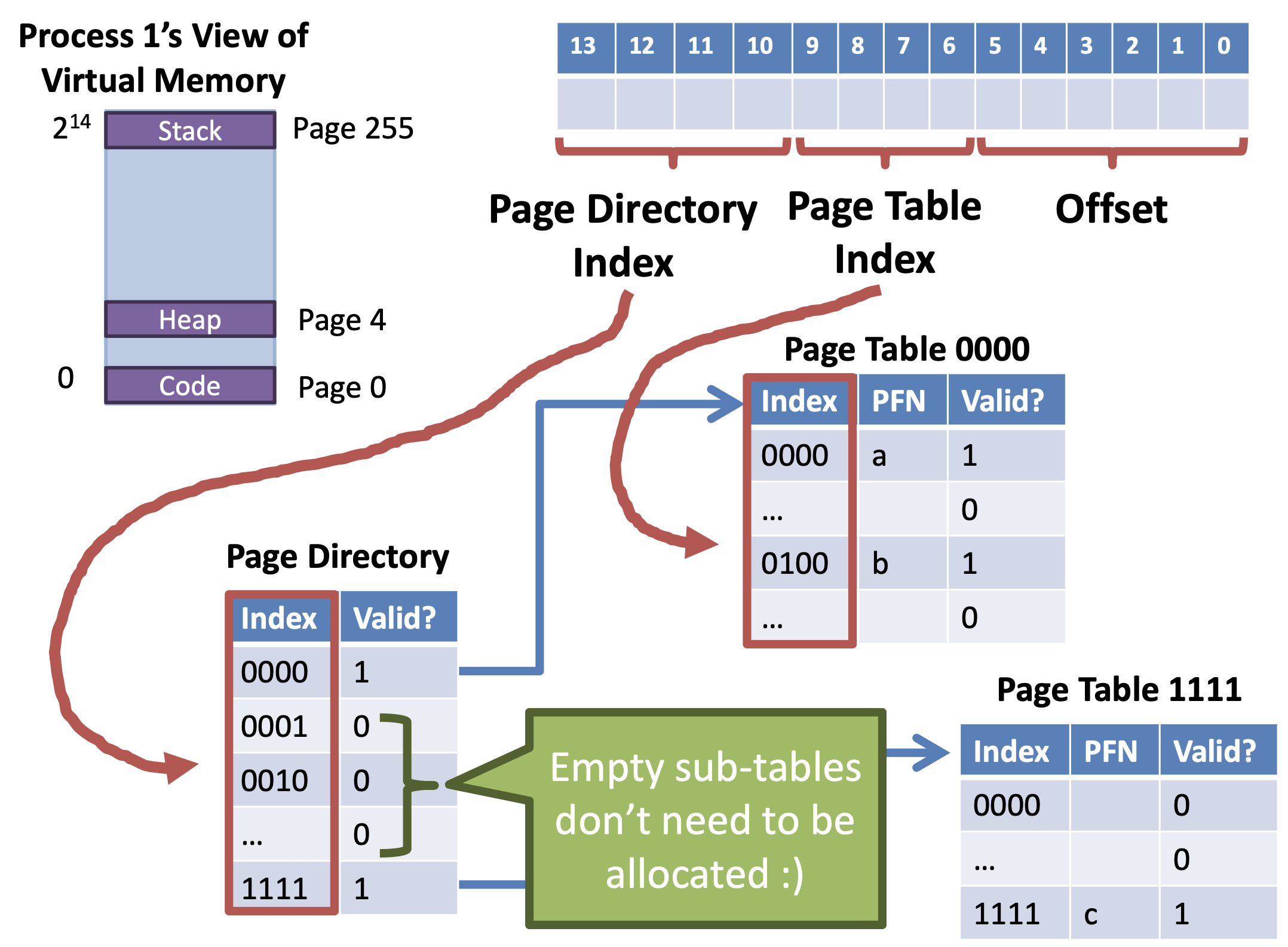
Solution 4: Multi-Level Page Tables
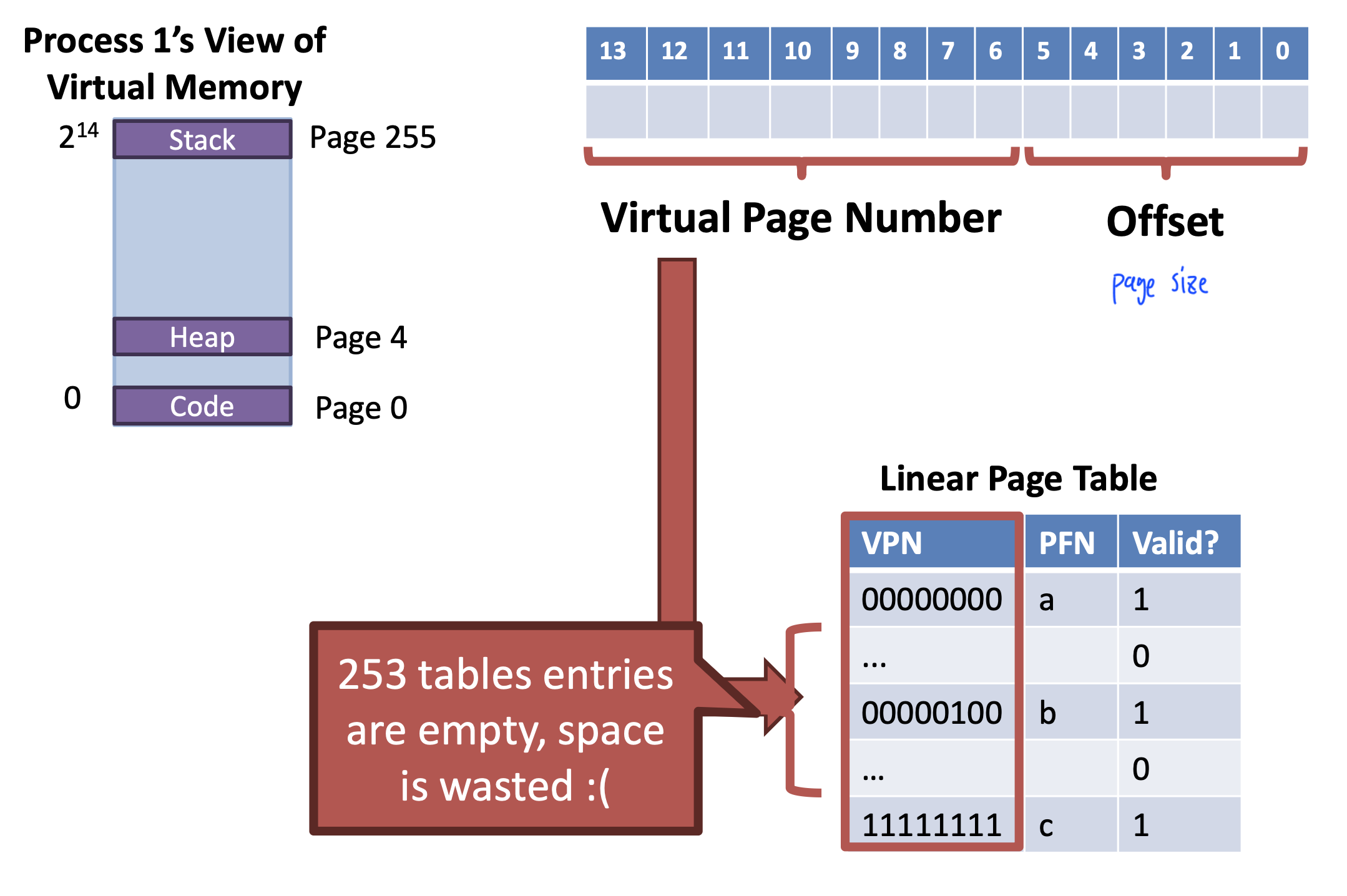
Split the linear page table into a tree of sub-tables
- Branches of the tree that are empty can be pruned
- Space / Time tradeoff
- Pruning reduces the size of the table (Save space)
- Tree must be traversed to translate virtual address (Increased access time)
Example
- 16KB address space
- 64 byte pages, 14-bit virtual address, 8-bit for the VPN, 6-bit for the offset
- How many entries?
- entries
- 256 entries, each is 4 bytes large
-> 1KB linear page tables - 1KB linear page table can be divided into 16 64-byte tables
- Each sub table holds 16 page table entries
- 32-bit x86 Two Level Page Table
- 64-bit x86 Four Level Page Table

Hybrid approach
- IA-32 architecture
- Both segmentation and segmentation with paging
- Each segment can be 4GB
- Up to 16K segments per process
- Divided into two partitions
- First partition of up to 8K segments are LDT (Local Descriptor Table)
- Second partition of up to 8K segments shared among all processes GDT (Global Descriptor Table)
- Both segmentation and segmentation with paging
-
CPU generates logical address (selector, offset)
-
Segmentation unit generates linear address (virtual address) using selector
-
MMU translates linear address into physical address
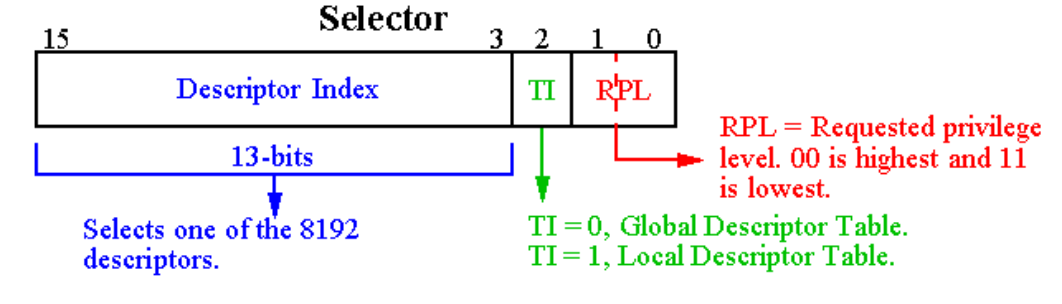
Descriptor Table
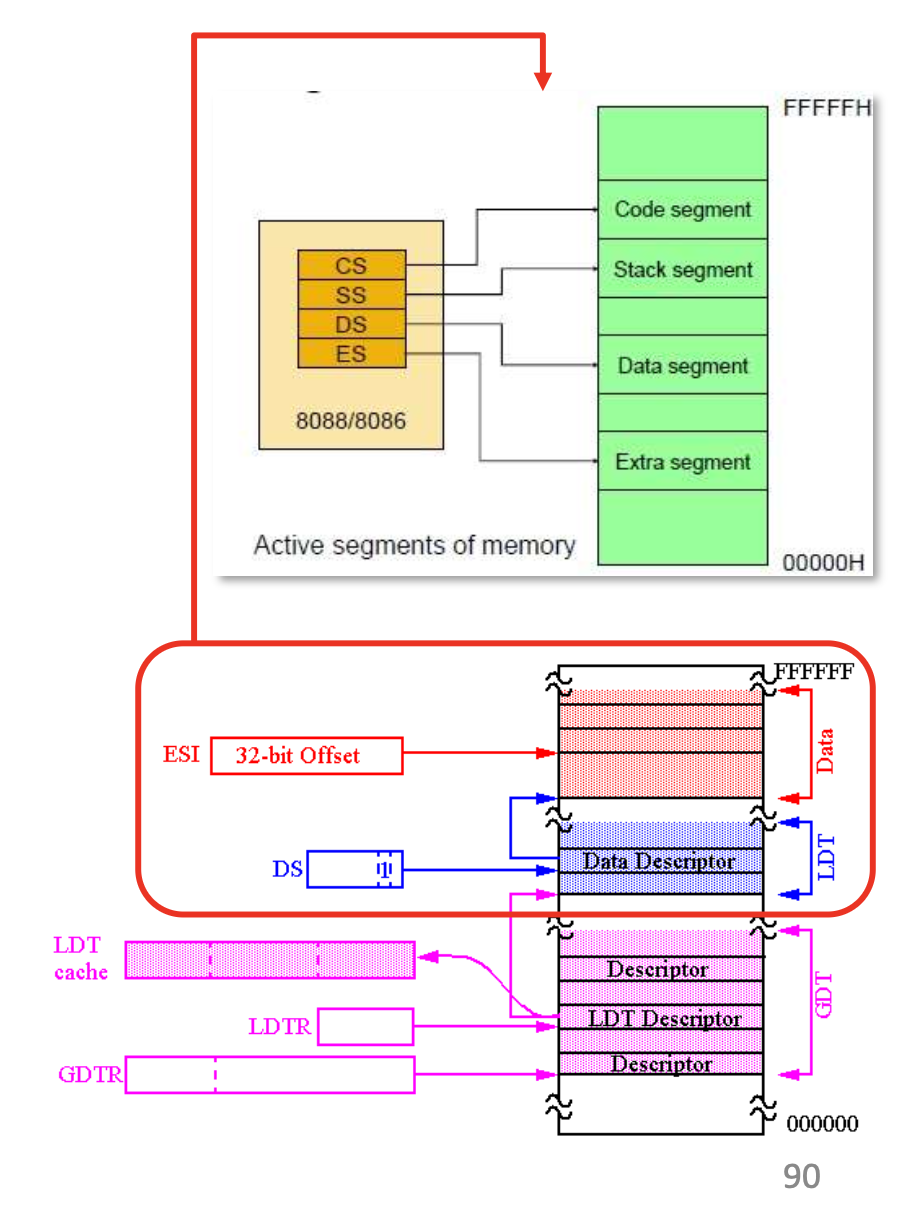
- GDTR points GDT
- Put LDT Descriptor value into LDTR, then LDTR points LDT
- Get the starting address of segment using selector
- Add offset and get linear address
