1. Introduction
Optimize prompt by utilizing LLM as optimizers
Describe the optimization problem in natural language,
then instruct the LLM to iteratively generate new solutions
based on the problem description and the previously found solutions
Optimizing the prompt for accuracy on a small training set is sufficient to reach high performance on the test set
Meta-prompt
- Prompt to the LLM serves as a call to the optimizer
Two Core pieces
- Previously generated prompts with their corresponding training accuracies
- Optimization problem description
which includes several exemplars randomly selected from the training set
Each optimization step generates new prompts based on a trajectory of previously generated prompts
OPRO enables the LLM to gradually generate new prompts that improve the task accuracy, where the initial prompts have low task accuracies
2. OPRO
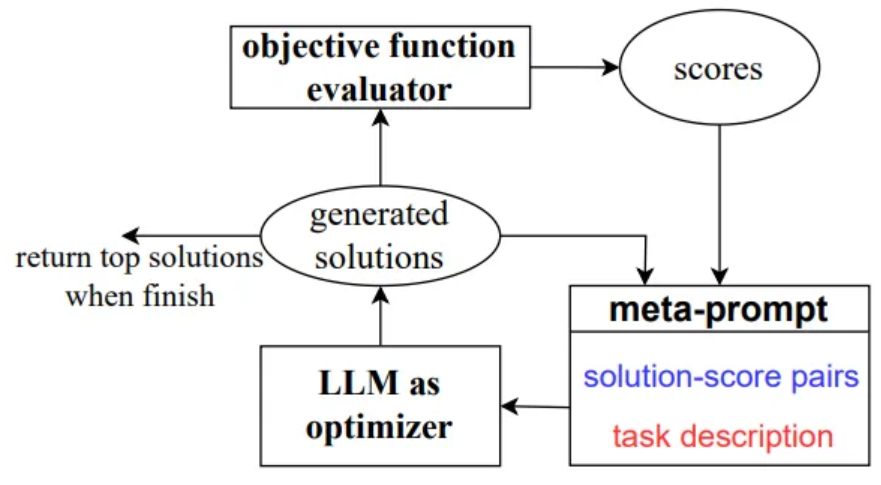
Each optimization step, LLM generates candidate solutions
New solutions are evaluated and added to the meta-prompt for the subsequent optimization process
Optimization process terminates when the LLM is unable to propose new solutions with better optimzation scores,
or a max number of optimzation steps
2.1. Desirables of Optimization
Task can be described with a high-level text summary
Trading off exploration and exploitation
- Exploit promising areas of the search space where good solutions are already found
- Also Exploring new regions of the search space so as to not miss potentially better solutions
2.2. Meta prompt Design
Optimization problem description
- Text description of the optimization problem, including the objective function and solution constraints
Optimization trajectory
- Optimization trajectory includes past solutions and their optimzation scores,
sorted in the ascending order - Allow the LLM to construct potentially better ones without the need of explicitly defining how the solution should be updated
2.3. Solution Generation
Optimization stability
- Not all solutions achieve high scores and monotonically improve over prior ones
- To improve stability, LLM generate multiple solutions at each optimization step,
allowing the LLM to simultaneously explore multiple possibilities and quickly discover
Exploration-exploitation trade off
- A lower temperature encourages the LLM to exploit the solution space
- While a high temperature allow the LLM to more aggressibely explore
4. Application : Prompt Optimization
4.1. Problem Setup
-
Both input and output are in the text format
-
Training set is used to calculate the training accuracy as the objective value during the optimzation process
-
Compute the test accuracy on the test set after the optimization finishes
-
Small number of fraction of training samples is sufficient
-
Scorer LLM
- LLM for objective function evaluation
-
Optimizer LLM
- LLM for optimization
- Output is an instruction
Example of the meta-prompt

- Blue : solution-score pairs
- Purple : optimization task and output format
- Orange : meta-instructions
4.2. Meta-prompt Design
Optimization problem examples
- Problem description includes a few examples taken from the training set
- Essential for the optimizer LLM to generate instructions of the same style
- Each optimization step, add several training examples to the meta-prompt
Optimization trajectory
- Inclues instructions generated from the past optimization steps, along with scores
- Sorted by the score in ascending order
- Only keep instructions with the highest scores
Meta-instructions
- Explain the optimization goal and instruct the model how to use the above information
5. Prompt Optimization Experiments
5.1. Evaluation Setup
Implementation details
- Temperature 0 when evaluating
- Default : 1.0 for optimizer LLM
- Each optimization step, generate 8 instructions
- Meta prompt contains best 20 instructions and 3 randomly picked exemplars from the training set
