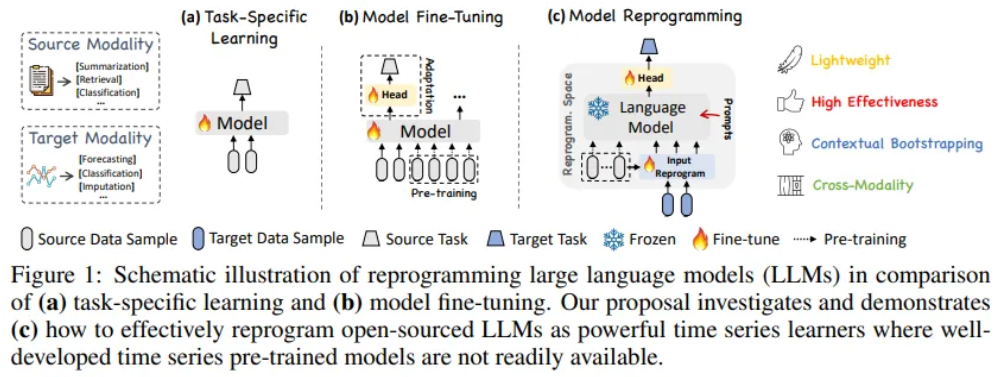
1. Introduction
Contribution
- Reprogramming large language models for time series forecasting without altering the backbone model
- Forecasting can be cast as yet another language task
- Reprogramming the input time series into text prototype representations
- Augmenting the input context with declarative prompts to guide LLM reasoning
- Unleashing LLM’s untapped potential for time series
2. Related Works
Task-specific Learning
In-modality Adaptation
- Pre-trained models can be fine-tuned for various downstream tasks
- TSPTM remains limited on smaller scales due to data sparsity
Cross-modality Adaptation
- Recent work has explored transferring knowledge from powerful pre-trained foundations models in NLP and CV to time-series
- From speech recognition to time series classification by editing time series into a format
- LLM4TS designs a two-stage fine-tuning process
- first supervised pre-training on time series
- task-specific fine-tuning
- We neither Edit the input time series directly nor Fine-tune the backbone LLM
- Propose reprogramming time series with the source data modality along with prompting to unleash the potential of LLMs
3. Methodology
Overview
1. Input transformation
2. Pre-trained frozen LLM
3. Output projection
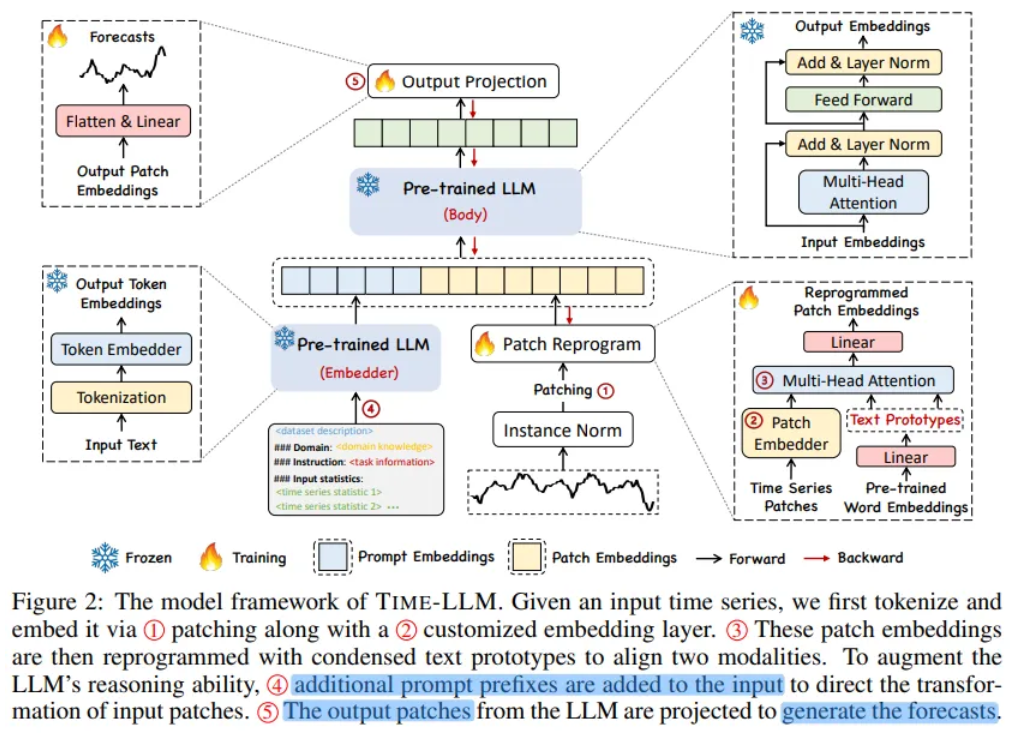
Without requiring any fine-tuning of the backbone model
- : different 1-dimensional variables
- : overall time steps
- : future time steps
- Overall objective : MSE
- A multivariate time series is partitioned into N univariate time series, which are subsequently processed independently
- Normalization, Patching and Embedding prior to being reprogrammed with learned text prototypes
- Prompting it together with reprogrammed patches to generate output representations
Only the parameters of input transformation and output projection are updated
Detail of Model Structure
Input Embedding
- Each input channel is individually normalized with RevIN
- Divide into patches with length
- Aggregating local information into each patch
- Forming a compact sequence of input tokens
- Given these patches embed them as adopting a simple linear layer to create dimensions
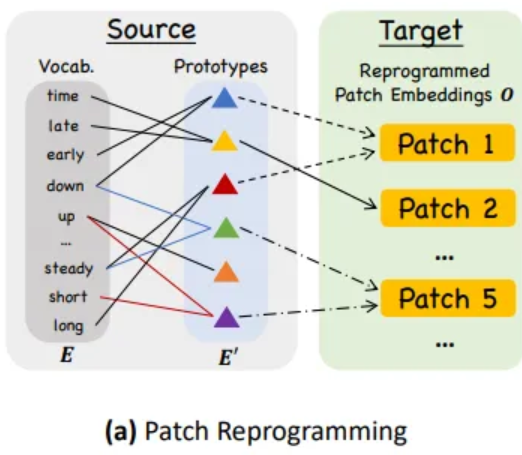
Patch Reprogramming
-
Reprogram patch embeddings to align the modalities of time series and natural language
-
Learning a form of noise allows the pre-trained source model to produce the desired target outputs
-
Feasible for bridging data modalities that are identical or similar
-
In past, learnable transformations between the source and target data allowing for the direct editing of input samples
-
Howerver, time series can neither be directly edited nor described losslessly in natural language
-
To close this gap, we propose reprogramming using pre-trained word embeddings
- : vocabulary size
-
No prior knowledge which source tokens are directly relevant
→ simply leveraging E result in large and potentially dense reprogramming space
-
Simple solution is to maintain a small collection of text prototypes by linearly probing
- which has less dimensions
-
Text prototypes learn connecting language cues which are combined to represent the local patch informaton (e.g. “short up then down steadily”)
-
without leaving the space where the language model is pre-trained
-
This approach allows for the adaptive selection of relevant source information
-
Employ multi-head cross-attention layer
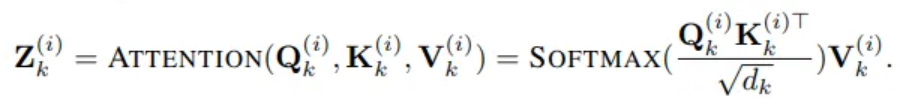
Prompt-as-Prefix
- Prompting is effective approach task-specific activation of LLM
- However, direct translation of time series into natural language presents challanges
- Other modality can be integrated as the prefixes of prompts
- Facilitating effective reasoning based on these inputs
- Prompts can act as prefixes to enrich the input context
- Prompts can guide the transformation of reprogrammed time series patches

Patch as Prefix and Prompt as Prefix
Constraints of Patch-as-Prefix
- Language models typically exhibit processing high-precision numerals without the aid of external tools
- Customized post-processing is required for different language models
- Forecasting represented in disparate natural language formats
- e.g) 0 . 6 1 and 0 . 61
Advantages of Prompt-as-Prefix
- Components for constructing effective prompts
- Dataset context
- Essential background information
- Task instruction
- Crucial guide for LLM in the transformaton of patch embeddings
- Input statistics
- Trends and lags of the input data
- Dataset context
Output Projection
- Discard the prefixal part and obtain the output
- Flatten and linear project output to derive the final forecasts
4. Main Results
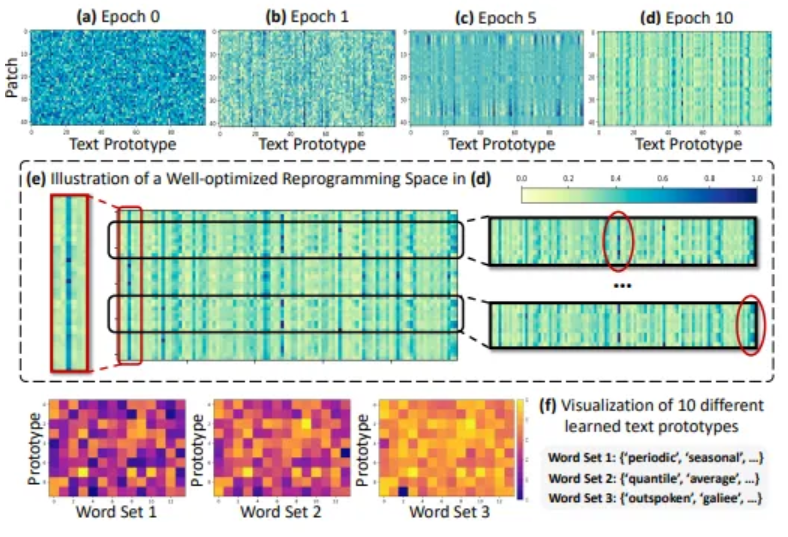
Reprogramming Interpretation
- 48 time series patches with 100 text prototypes
- Optimization of reprogramming space
- Text prototypes learn to summarize language cues
- Patches usually have different underlying semantics
- According to (f), prototypes are highly relevant to the words that describe time series properties (1, 2)
