문제 상황
개발하고 있었던 페이지는 게시글 종류의 데이터 목록을 보여주는 페이지였다.
해당 리스트 컴포넌트는 useInfiniteQuery로 데이터를 가져오고, 데이터가 undefined인 동안에는 스켈레톤을 대신 표시해주고 있었다.
import { useInfiniteQuery } from "@tanstack/react-query";
import { useMemo } from "react";
const Collections = ({ limit }: Props) => {
const { data } = useInfiniteQuery({
queryKey: ["collection-items", "public"],
queryFn: async ({ pageParam }) => {
// 데이터 fetch 로직
},
initialPageParam: 0,
getNextPageParam: (lastPage, _, lastPageParam) =>
lastPage.length < limit ? undefined : lastPageParam + limit,
staleTime: 1000 * 60 * 1,
});
const collectionItems = useMemo(() => data?.pages.flat(), [data]);
// if (collectionItems === undefined) 스켈레톤 리턴 코드 생략
return (
<>
<div>
{collectionItems.map((collectionItem) => (
<CollectionItem
key={collectionItem.collection.id}
collectionItem={collectionItem}
/>
))}
</div>
</>
);
};체감상 데이터가 표시되는 시간이 오래 걸렸고, 실제로 측정해보니 LCP(Largest Contentful Paint)와 TBT(Total Blocking Time)이 지연되는 문제가 있었다.
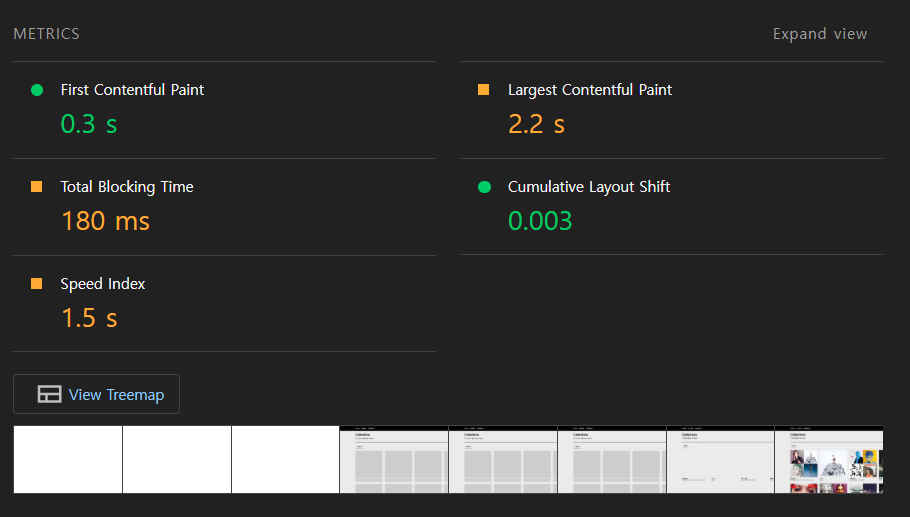
TBT의 경우 데이터를 가지고 오는 로직(queryFn)을 수정하여 개선할 수 있었다.
(Promise.All을 사용한 병렬 요청, spotify API의 /album 대신 /albums 사용하여 한 번에 여러 앨범 정보 가져오기 등...)
LCP를 조금 더 개선할 수 있는 것이 있을까 생각하다가, Next.js를 사용하고 있음에도 서버 환경을 충분히 활용하지 못하고 있다고 느꼈다.
그래서 SSR 환경에서 쿼리 데이터를 더 빠르게 가져와서 페이지의 성능을 개선할 수 있는 방법을 찾아보았다.
SSR 환경에서 Tanstack Query 사용하기
Tanstack Query에서는 두 가지 방법에 대해 소개하고 있었다.
1. initialData 주입
첫번째 방법은 서버에서 데이터를 미리 가져와서 쿼리 옵션 initialData 값에 넣어주는 것이다.
initialData은 훅이 처음 등록될 때, 즉 데이터가 없을 때 임시 초기값을 제공하기 위한 용도로 사용된다.
const result = useQuery({
queryKey: ['todos'],
queryFn: () => fetch('/todos'),
initialData: initialTodos,
})이미 같은 queryKey를 가지는 데이터가 있다면 무시된다. 즉, 캐시된 데이터가 없는 경우에만 초기값으로 세팅된다.
기본적으로 stale time은 0으로 설정되기 때문에 따로 staleTime을 명시하지 않는다면, 마운트 직후 fetch가 발생해 다시 최신 데이터를 가져오게 된다.
리팩토링
기존 데이터 목록 컴포넌트를 서버용과 클라이언트용으로 나누었다.
서버 컴포넌트 CollectionsServer
서버용 컴포넌트는 데이터를 불러오고, 해당 데이터를 클라이언트용 컴포넌트에 prop으로 전달하는 역할을 한다.
import CollectionsClient from "./CollectionsClient";
import { createClient } from "@/utils/supabase/server";
import { getPublicCollections } from "@/lib/supabase/fetchForCommon";
import { getCollectionItems } from "@/utils/collectionUtils";
interface CollectionsContentContainerProps {
limit: number;
}
const CollectionsServer = async ({
limit,
category,
}: CollectionsContentContainerProps) => {
const supabase = await createClient();
const publicCollections = await getPublicCollections(supabase, 0, limit - 1);
const collectionItems = await getCollectionItems(publicCollections, true);
return (
<CollectionsClient
limit={limit}
initialData={collectionItems}
/>
);
};클라이언트 컴포넌트 CollectionsClient
클라이언트 컴포넌트는 전달받은 initialData를 쿼리 옵션으로 넣어 초기값으로 설정한다.
"use client";
import { useMemo } from "react";
import CollectionItem from "./CollectionItem";
import { CollectionItemType } from "@/types/common";
import { useInfiniteQuery } from "@tanstack/react-query";
interface Props {
limit: number;
initialData: CollectionItemType[];
}
const CollectionsClient = ({ limit, initialData }: Props) => {
const { data, hasNextPage, fetchNextPage, isFetchingNextPage } = useInfiniteQuery({
queryKey: ["collection-items", "public"],
queryFn: async ({ pageParam }) => {
// 데이터 fetch 로직
},
initialPageParam: 0,
getNextPageParam: (lastPage, _, lastPageParam) =>
lastPage.length < limit ? undefined : lastPageParam + limit,
staleTime: 1000 * 60 * 1,
initialData: {
pageParams: [0],
pages: [initialData],
},
});
const collectionItems = useMemo(() => data?.pages.flat(), [data]);
return (
<>
<div>
{collectionItems.map((collectionItem) => (
<CollectionItem
key={collectionItem.collection.id}
collectionItem={collectionItem}
/>
))}
</div>
</>
);
};
export default CollectionsClient;
마지막으로 서버 컴포넌트를 Suspense로 감싸고, 서버 컴포넌트가 데이터를 가져오는 동안 보여줄 스켈레톤 UI를 fallback으로 설정해준다.
import CollectionsServer from "@/components/Collections/CollectionsServer";
import { Suspense } from "react";
const Page = async () => {
const limit = 8;
return (
<>
<h>Collections</h1>
<div>
<Suspense fallback={<CollectionsSkeleton />}>
<CollectionsServer category={currentCategory} limit={limit} />
</Suspense>
</div>
</>
);
};
export default Page;결과
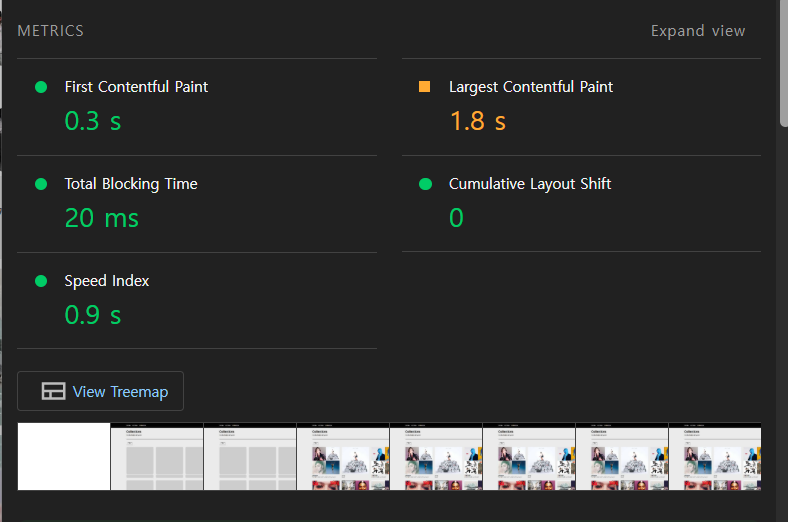
여러번 측정해본 결과 평균적으로 LCP가 1.6s로 나타나며, 0.2s 정도 개선되었다.
Speed Index는 비교적 증가했는데, 아마도 서버에서 데이터를 가져오는데 소요되는 시간 때문에 늘어난 것 같다.
initialData 방식의 트레이드오프
해당 방식은 간단하지만 단점이 있다.
-
쿼리를 호출하는 컴포넌트가 깊은 트리 구조 하위에 위치해 있는 경우,
initialData를 하위 컴포넌트에 직접 prop으로 전달해야 하므로 props drilling이 발생할 수 있다. -
여러 위치에서 같은 쿼리를 사용하더라도
initialData를 준 곳에만 데이터가 존재하게 되므로, 결국 여러 곳에initialData를 전달해야 한다. 컴포넌트를 이동하거나 삭제하면 캐싱 로직이 깨질 수 있어 관리가 어렵다. -
데이터가 언제 fetch되었는지(
dataUpdatedAt)가 브라우저가 로드된 시점이 된다. 실제 두 시점은 다르기 때문에, refetch 시점이 부정확해진다. -
이미 캐시된 데이터가 있다면,
initialData가 더 최신 정보이더라도 반영되지 않고 무시될 수 있다.
Tanstack Query는 이러한 initialData의 단점을 해결할 수 있는 방법으로 hydration API를 소개하고 있다.
2. prefetch + hydration
서버에서 미리 데이터를 가져와 쿼리 캐시를 미리 채우고, 캐시가 채워진 상태를 클라이언트에 전달하는 방식이다.
예제코드
예제 코드를 통해 사용법을 알아보자.
// app/posts/page.tsx
import {
dehydrate,
HydrationBoundary,
QueryClient,
} from '@tanstack/react-query'
import Posts from './posts'
export default async function PostsPage() {
const queryClient = new QueryClient()
await queryClient.prefetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return (
<HydrationBoundary state={dehydrate(queryClient)}>
<Posts />
</HydrationBoundary>
)// app/posts/posts.tsx
'use client'
export default function Posts() {
const { data } = useQuery({
queryKey: ['posts'],
queryFn: () => getPosts(),
})
// ...
}서버에서는 prefetchQuery(또는 prefetchInfiniteQuery)를 통해 캐시를 미리 채운다. 이때 서버에서는 항상 새로운 QueryClient 객체를 만들어 사용해야 한다.
캐시가 채워진 상태(state)를 클라이언트에 전달하기 위해 직렬화(dehydrate)하여 클라이언트 컴포넌트로 전달한다. 이때 HydrationBoundary는 내부적으로 역직렬화(hydrate)를 거쳐 복원하여, 클라이언트 측의 QueryClient(useQueryClient()가 리턴하는 QueryClient)에 캐시를 전달하는 역할을 한다.
클라이언트에서는 같은 queryKey, 같은 종류의 쿼리 훅(prefetchQuery - useQuery, prefetchInfiniteQuery - useInfiniteQuery)을 사용하여, 서버에서 미리 채운 캐시를 통해 빠르게 데이터를 사용할 수 있다.
리팩토링
서버/클라이언트 공통 쿼리 옵션
서버와 클라이언트가 쿼리 키, 리턴값 등 공통의 쿼리 옵션을 가지도록 보장하기 위해, 쿼리 옵션을 구하는 함수를 만들었다.
서버/클라이언트에 따라 queryFn이 달라져야해서 함수 파라미터로 forServer를 추가해주었다.
export type UseCollectionItemsQueryOptions = UseInfiniteQueryOptions<
CollectionItemType[],
Error,
InfiniteData<CollectionItemType[], number>,
CollectionItemType[],
string[],
number
>;
export type FetchCollectionsFunc = (
pageParam: number
) => Promise<Collection[]>;
// Collection Items 공통 쿼리 옵션
export function getUseCollectionItemsQueryOptions(
client: SupabaseClient,
limit: number,
fetchCollections: FetchCollectionsFunc,
queryKey: string[],
forServer?: boolean;
): UseCollectionItemsQueryOptions {
return {
queryKey: ["collection-items", ...queryKey],
queryFn: async ({ pageParam }) => {
const collections = await fetchCollections(client, pageParam);
// ...
return items;
},
initialPageParam: 0,
getNextPageParam: (lastPage, _, lastPageParam) =>
lastPage.length < limit ? undefined : lastPageParam + limit,
staleTime: 1000 * 60 * 1,
};
}
// public한 Collection Items을 가져오는 쿼리 옵션
export function getUsePublicCollectionItemsQueryOptions(
supabaseClient: SupabaseClient,
limit: number,
forServer?: boolean
) {
const fetchCollections = (client: SupabaseClient, pageParam: number) =>
getPublicCollections(client, pageParam, pageParam + limit - 1);
return getUseCollectionItemsQueryOptions(
supabaseClient,
limit,
fetchCollections,
["public"],
forServer
);
}서버 컴포넌트 CollectionsServer
import {
getUsePublicCollectionItemsQueryOptions
} from "@/hooks/queryOptions";
import { createClient } from "@/utils/supabase/server";
import {
dehydrate,
HydrationBoundary,
QueryClient,
} from "@tanstack/react-query";
import CollectionsClient from "./CollectionsClient";
interface CollectionsContentContainerProps {
limit: number;
}
const CollectionsServer = async ({ limit }: CollectionsContentContainerProps) => {
const supabase = await createClient();
const queryClient = new QueryClient();
// prefetch
const queryOptions = getUsePublicCollectionItemsQueryOptions(supabase, limit, true);
await queryClient.prefetchInfiniteQuery(queryOptions);
const state = dehydrate(queryClient);
// 서버 메모리 누수 방지 캐시 정리
queryClient.clear();
return (
<HydrationBoundary state={state}>
<CollectionsClient limit={limit} />
</HydrationBoundary>
);
};
export default CollectionsServer;
클라이언트 컴포넌트 CollectionsClient
"use client";
import { useMemo, useState } from "react";
import CollectionItem from "./CollectionItem";
import { createClient } from "@/utils/supabase/client";
import { useInfiniteQuery } from "@tanstack/react-query";
import { getUsePublicCollectionItemsQueryOptions } from "@/hooks/queryOptions";
interface Props {
limit: number;
}
const CollectionsClient = ({ limit }: Props) => {
const [client] = useState(() => createClient());
const { data, hasNextPage, fetchNextPage, isFetchingNextPage } = useInfiniteQuery(
getUsePublicCollectionItemsQueryOptions(client, limit) // 같은 쿼리 옵션
);
const collectionItems = useMemo(() => data?.pages.flat(), [data]);
return (
<>
<div className="collection_list_container">
{collectionItems.map((collectionItem) => (
<CollectionItem
key={collectionItem.collection.id}
collectionItem={collectionItem}
/>
))}
</div>
</>
);
};
export default CollectionsClient;
결과
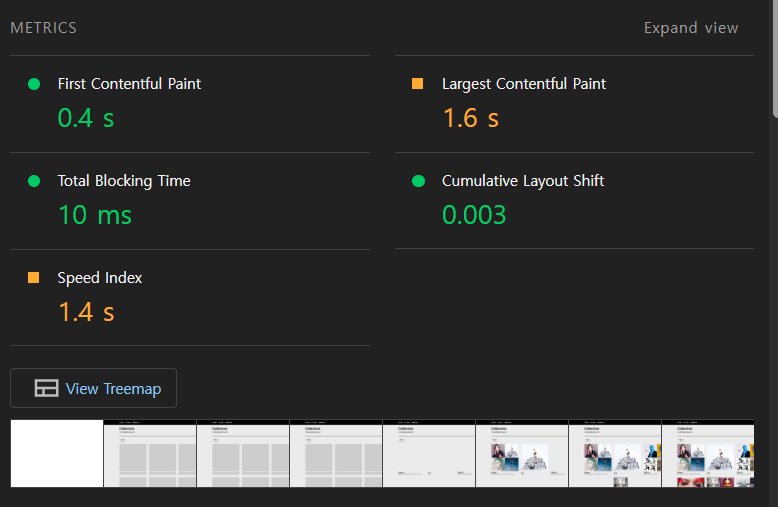
여러번 측정해본 결과 평균적으로 LCP가 1.5s 정도로, initialData와 비교해 0.1s 정도 개선되었다.
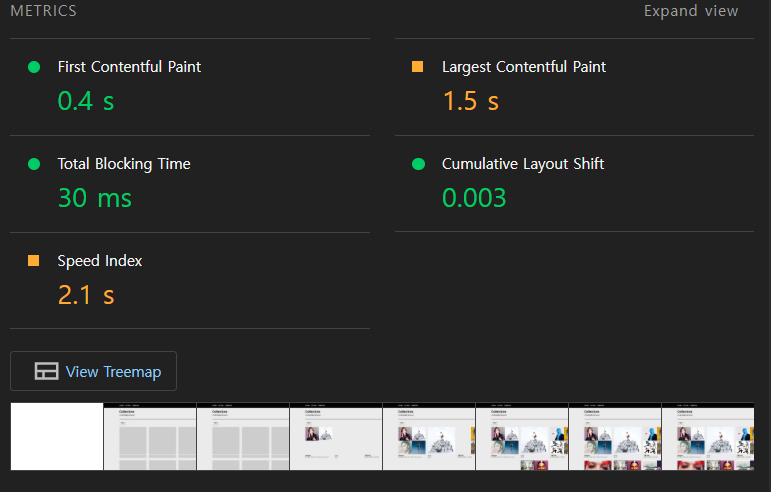
initialData와 prefetch 방식 비교
두 방식이 어느 부분에서 차이가 나는 것인지 비교해보았다.
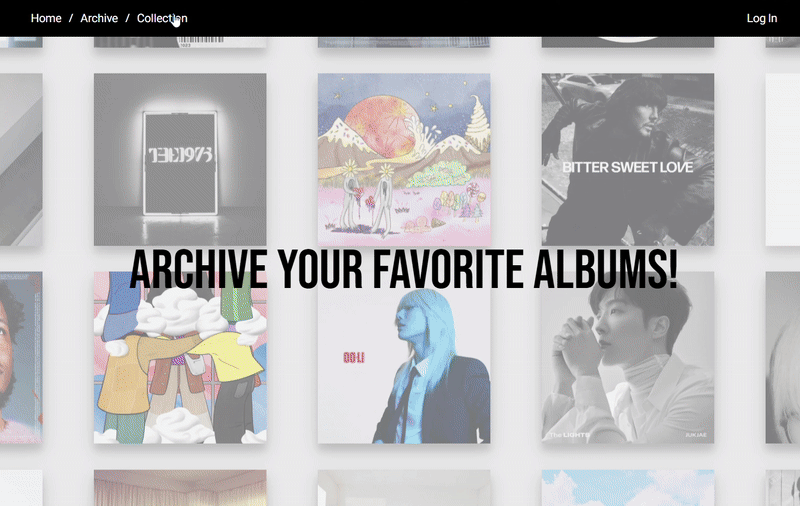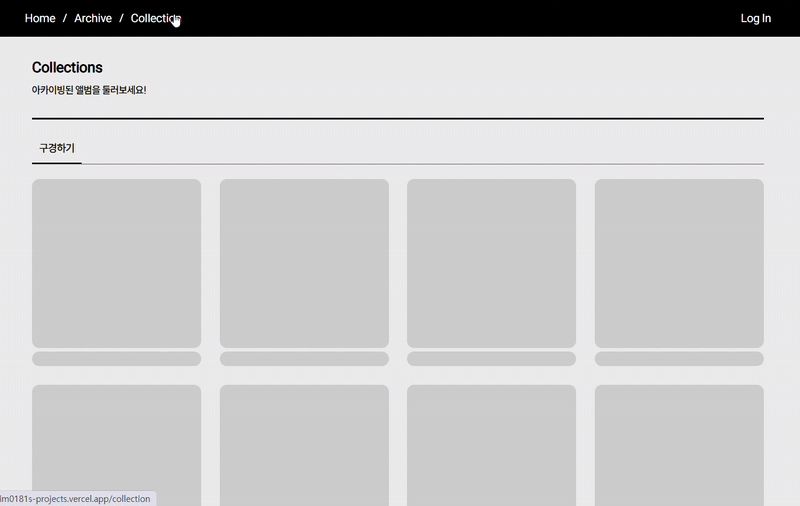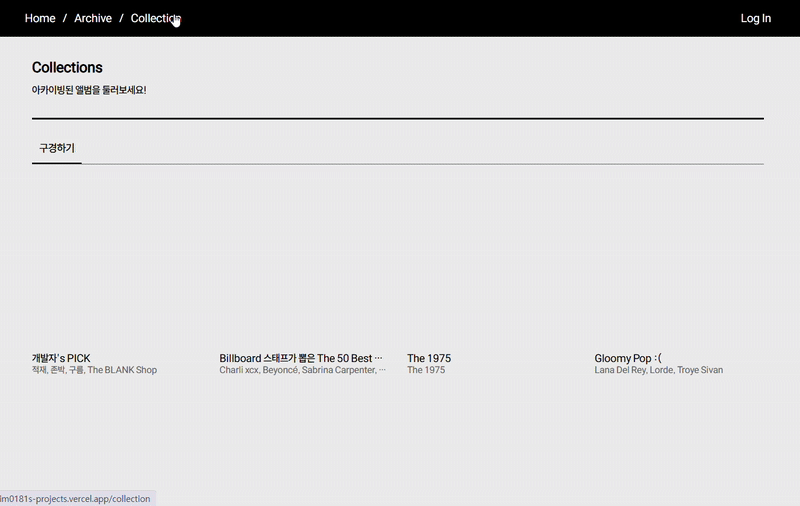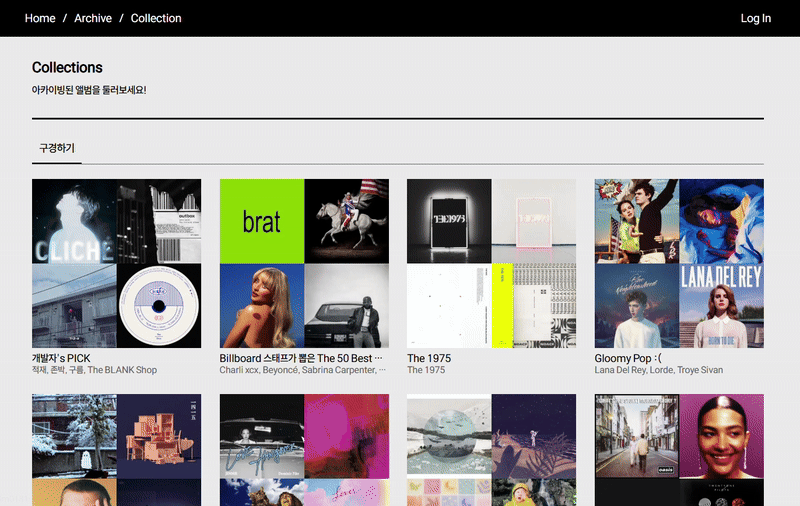
아래 스크린샷은 스켈레톤에서 데이터를 포함한 실제 엘리먼트로 전환되는 시점에 메인 스레드 Task를 확인해본 것으로, 왼쪽이 prefetch 그리고 오른쪽이 initialData 방식을 사용했을 때의 결과이다.
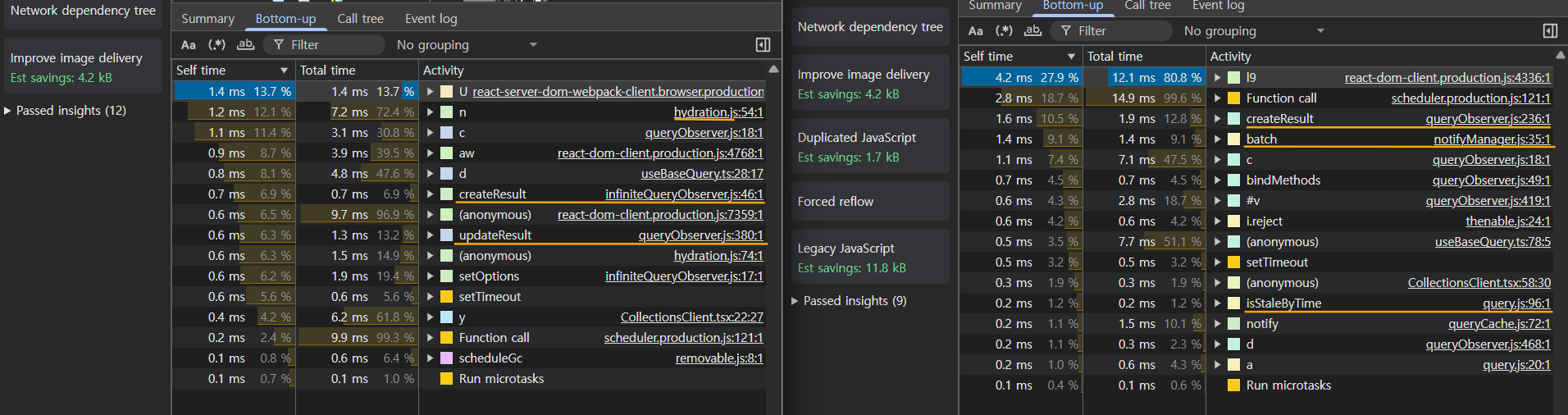
눈에 띄는 차이점은, 왼쪽 prefetch 스크린샷에서는 'hydration.js'이라는 파일에서 익명의 함수가 실행되었다는 것이다.
그리고 오른쪽 initialData 스크린샷에서는 notifyManager의 batch, isStaleByTime이 실행되었고, createResult에 소요되는 시간도 더 큰 것을 알 수 있다.
아마도 initialData의 stale 여부를 판정하고, 해당 데이터를 가지고 새 결과를 만들어내는 과정이 필요해져서 소요 시간이 더 늘어나게 된 것 같다.
정리
이번 개선 과정을 통해 TanStack Query에서 SSR을 활용하는 두 가지 방식(initialData vs prefetch + hydration)의 차이를 비교해 보았다.
initialData가 쉬운 방법으로 소개되었지만, 실제 적용해보니 hydration이 더 어렵다고도 느껴지지 않았다.
나의 경우 해당 데이터를 사용하는 곳이 페이지 한개 뿐이었지만, 만약 여러 곳에서 쓰이는 데이터라면 hydration의 효과를 확실히 체감할 수 있을 것 같다.
