Neural Style Transfer란?
content 이미지와 style 이미지가 주어졌을 때, content 이미지의 형태는 보존하면서 텍스쳐나 스타일을 style 이미지와 유사하게 바꾸는 것
Abstract
논문에서는 object recognition에 최적화된 CNN에서 파생된 높은 수준의 이미지 정보를 명시적으로 만드는 이미지 표현을 사용
이미지 콘텐츠와 이미지의 style을 분리하고 재결합할 수 있는 A Neural Algorithm of Artistic Style 을 제안
이 알고리즘은 임의의 사진의 콘텐츠와 수많은 잘 알려진 예술 작품의 모습을 결합한 높은 지각 품질의 이미지를 생성할 수 있게 함
CNN에서 학습한 심층 이미지 표현에 대한 새로운 통찰력을 제공하고, 높은 수준의 이미지 합성 및 조작의 가능성을 보여줌
방법론
CNN (VGG19)
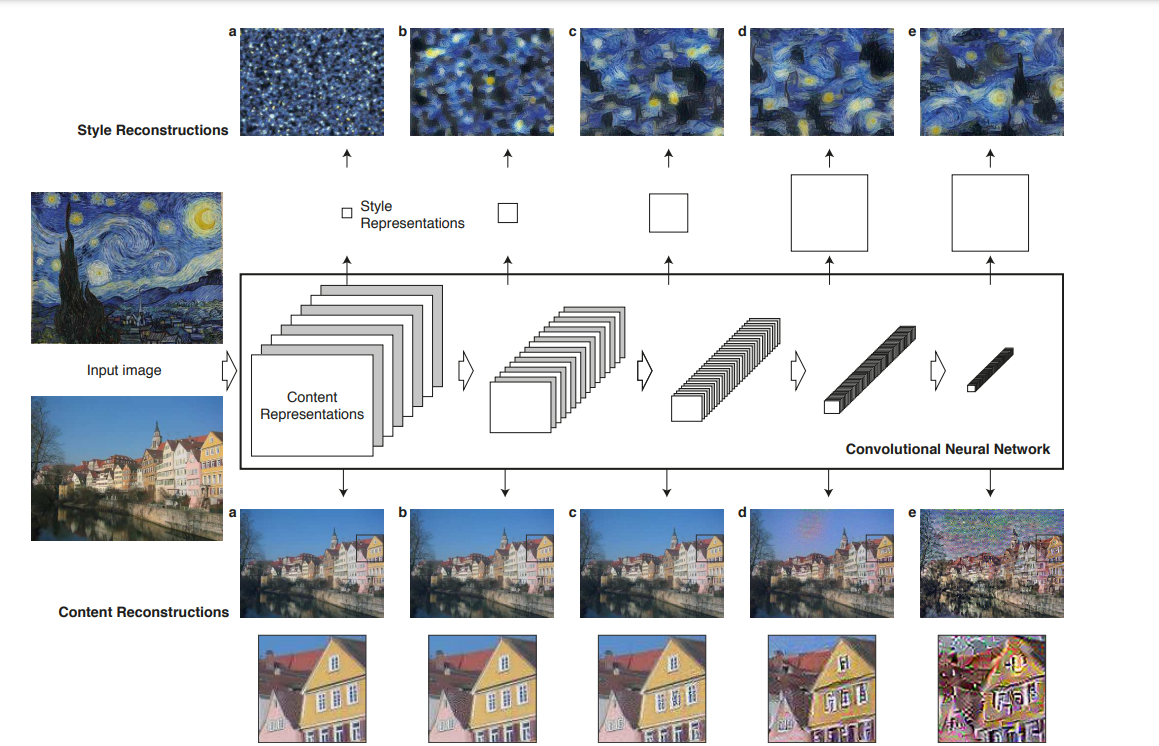
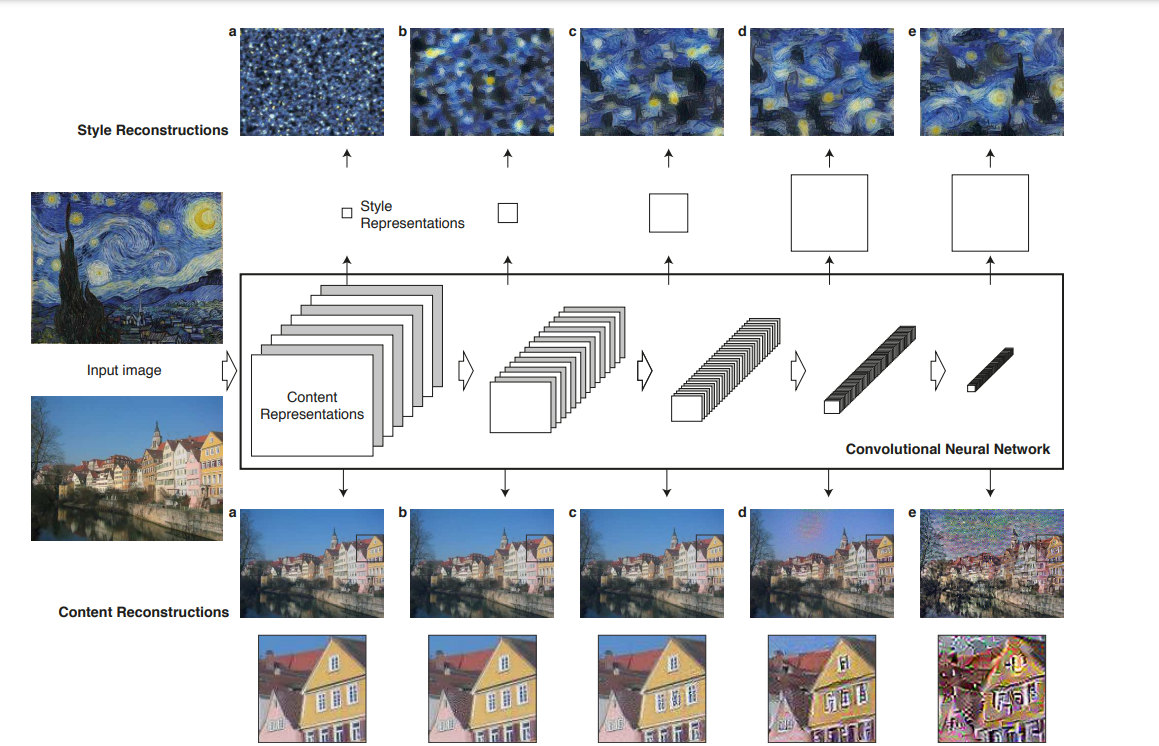
VGG-Network 사용(VGG-19)
기존의 max pooling보다는 average pooling을 사용하는 것이 더 좋은 결과가 나왔다고 한다.
CNN의 각 레이어: 특정 feature를 추출하는 이미지 필터이며, 계층적인 구조이다.
⇒ 각 레이어에서 생성된 feature map으로부터 이미지를 재구성한다!
Loss 함수
content loss와 style loss의 합을 최소화하는 방향으로 학습
[content loss]
주어진 이미지와 생성된 이미지의 feature representation 사이의 MSE loss
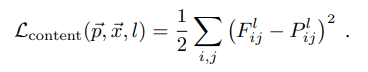
[style loss]
gram matrix를 사용하여 다른 필터 response에 대한 상관계수
gram matrix의 각 원소는 레이어 l에서의 벡터화된 feature map i, j 의 내적
feature correlation → global arrangement를 제외한 상태로 texture 정보를 얻을 수 있음
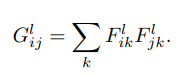
레이어 l에 대한 total loss는 다음 식과 같이 계산됨
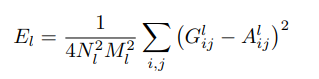
⇒ 생성된 이미지의 feature correlation과 주어진 이미지 사이의 MSE loss
그리고 total style loss의 식은 다음과 같음
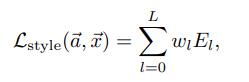
= 각 레이어에 대한 total loss에 각각 해당하는 가중치를 곱한 것
전체 loss는 content loss와 style loss에 각각 가중치를 줘서 합한 값!
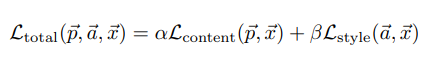
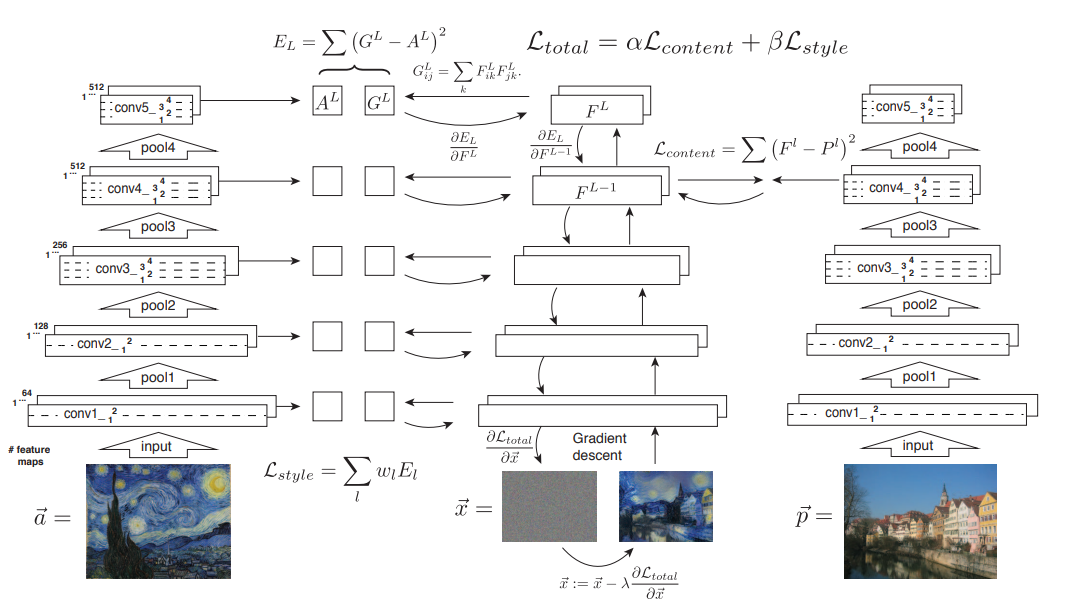
style representation에서는 [conv1_1, conv2_1, conv3_1, conv4_1, conv5_1]을 사용, 가중치는 각각 0.2씩 + 사용하지 않는 레이어는 0
content representation에서는 [conv4_2]를 사용
와 의 비율은 , , , 중 하나, 비율에 따라 stylize 정도를 조절할 수 있다.
content와 style 사이에는 trade-off 존재

Initialization of Gradient Descent
white noise로부터 이미지를 생성할 수 있지만 content image나 style image로부터 이미지를 생성할 수도 있음
noise로부터 시작하는 것이 임의의 수의 새로운 이미지 생성을 가능하게 하며, 고정된 이미지로 시작하는 것은 같은 결과를 낼 수 있음
하지만 content 이미지로 시작하는 것이 더 좋은 결과를 낸다고 함!
