KLUE-STS 벤치마크를 사용할 일이 있어서,
약간의 공부와 함께 직접 다운로드 받아보고 구조를 살펴보는 시간을 가졌다
공부하기 앞서 아래 reference를 참고해 공부했음을 밝힙니다
STS task 외에도 KLUE 벤치마크 전부분을 쉽게 설명해주니 공부에 많은 도움이 될 것 같습니다
1. KLUE
KLUE(Korean Language Understanding Evaluation Benchmark)는
한국어 NLP를 위한 최초의 한국어 벤치마크로 아래 KLUE github 설명을 통해
프로젝트의 목적 및 제공하는 내용을 알 수 있다
The KLUE is introduced to make advances in Korean NLP. Korean pre-trained language models (PLMs) have appeared to solve Korean NLP problems since PLMs have brought significant performance gains in NLP problems in other languages. Despite the proliferation of Korean language models, however, none of the proper evaluation datasets has been opened yet. The lack of such benchmark dataset limits the fair comparison between the models and further progress on model architectures.
Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the PLMs, KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research.
<출처 : KLUE github readme>
Koerean NLP 에 대한 활발한 개발과 연구에 비해 이를 평가할 수 있는 한국어 벤치마크 부재라는 문제가 있었고, KLUE 프로젝트를 통해 공신력있는 벤치마크를 만들었다
뿐만 아니라 tasks 마다 적절한 평가산식이나 사전 학습 모델을 위한 fine-tuning 방법을 제공하고 있다.
앞서 제공한 reference 의 게시글의 말을 빌리면
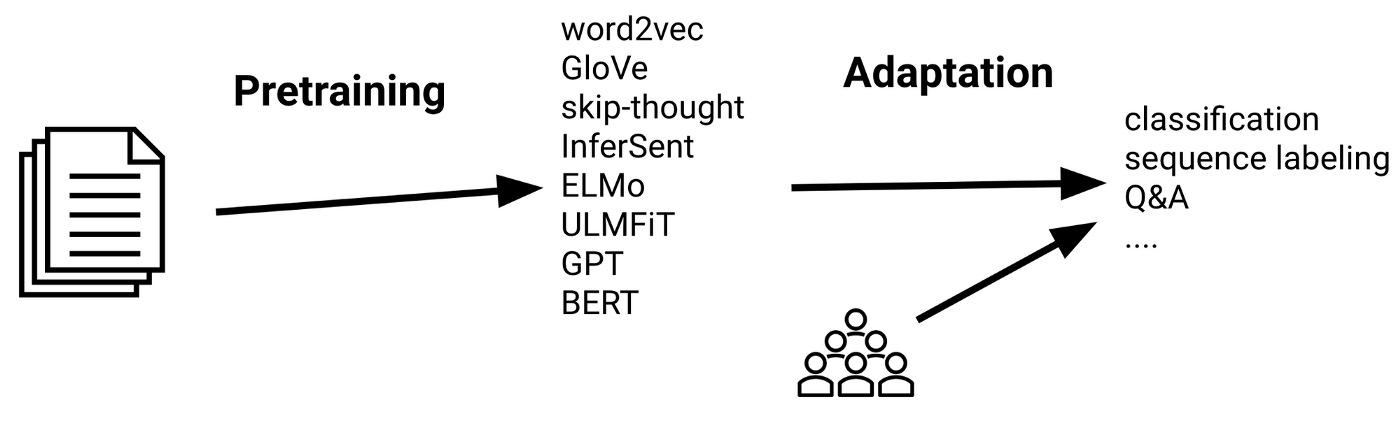
최근 NLP(Natural Language Processing) 모델의 핵심 키워드는 '전이학습'이라 볼 수 있으며
전이학습이란 사전 학습된 모델의 가중치로 초기화 된 모델을 가지고 구체적으로 풀고 싶은 문제에 맞게 추가 학습하는 방법이다
 출처 : 최상단 reference, AI Network 게시글
출처 : 최상단 reference, AI Network 게시글
전이 학습의 기본은 사전 학습 된 모델을 사용하는 것이므로 사전 학습 된 모델의 성능이 좋지 않으면 전이 학습의 효율성은 떨어질 것
이 때 사전 학습된 모델의 성능을 정량적으로 평가하는 방법이 벤치마크 데이터셋이다
실제로 사전 학습된 모델들(BERT, ELECTRA)이 빠른 속도로 발전하게 된 배경에는 GLUE(General Language Understanding Evaluation) 벤치마크가 있다고 한다.

위의 github 캡쳐를 통해 볼 수 있듯
KLUE는
- 토픽 분류 (TC)
- 의미 유사도 (STS)
- 자연어 추론 (NLI)
- 개체명 인식 (NER)
- 관계 추출 (RE)
- 의존 구문 분석 (DP)
- 기계 독해 (MRC)
- 대화 상태 추적 (DST)
로 총 8개의 Task에 대해 평가할 수 있다
또한 GLUE를 단순 번역한 것이 아닌 한국어 언어 모델이 구문론적, 의미론적 표상을 제대로 학습했는지 평가할 수 있는 과제를 포함하고, 학계뿐 아니라 산업계에서도 수요가 있는 과제를 포함했다는 점에서 의의를 가지고 있다
2. KLUE-STS
STS(Semantic Textual Similarity) 의 목표는 입력으로 주어진 두 문장간의 의미 동등성을 수치로 표현하는 것이다.
2.1 데이터 개요
KLUE-STS에서 사용된 데이터는 에어비앤비 리뷰, 정책 뉴스 브리핑 자료, 스마트 홈 기기를 위한 발화 데이터이다.
에어비앤비 리뷰, 정책 뉴스 브리핑 자료 같은 경우 문장간의 유사성을 추정하기 힘든 경우가 있었는데, 이때는 네이버 파파고를 사용하여 영어로 번역했다가 다시 한국어로 번역하여 유사한 문장 쌍을 생성했다고 한다. 이런 기법을 round-trip translation(RTT) 라고 부르는데 이렇게 함으로써 원래 문장의 핵심 의미를 유지하면서 어휘 표현이 살짝 다른 문장을 생성할 수 있었다.
2.2 평가방법
해당 Task를 평가할 때는 F1 score와 피어슨 상관 계수가 사용
-
F1 score 같은 경우, 유사도 3.0을 기준으로 유사하다, 유사하지 않다로 라벨링 후 F1 score를 구함
-
피어슨 상관 계수는 변수 X, Y가 있을 때 이 두 변수가 어떤 상관 관계를 가지는가를 수치로 나타낸 값으로, KLUE-STS에서는 사람이 직접 붙인 라벨값과 모델의 예측 라벨값 간의 선형 상관 관계를 측정
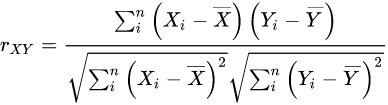
3. KLUE-STS Structure
앞으로 이어질 Hugging Face 사용법을 참고한 reference로
data load 뿐 아니라 fine-tuning 내용까지 참고했던 좋은 게시글입니다 😊
동일하게 colab을 사용해 작업을 수행했고,
저의 경우 transformers, datasets 모듈만 pip install 후 사용했습니다
3.1 download KLUE-STS
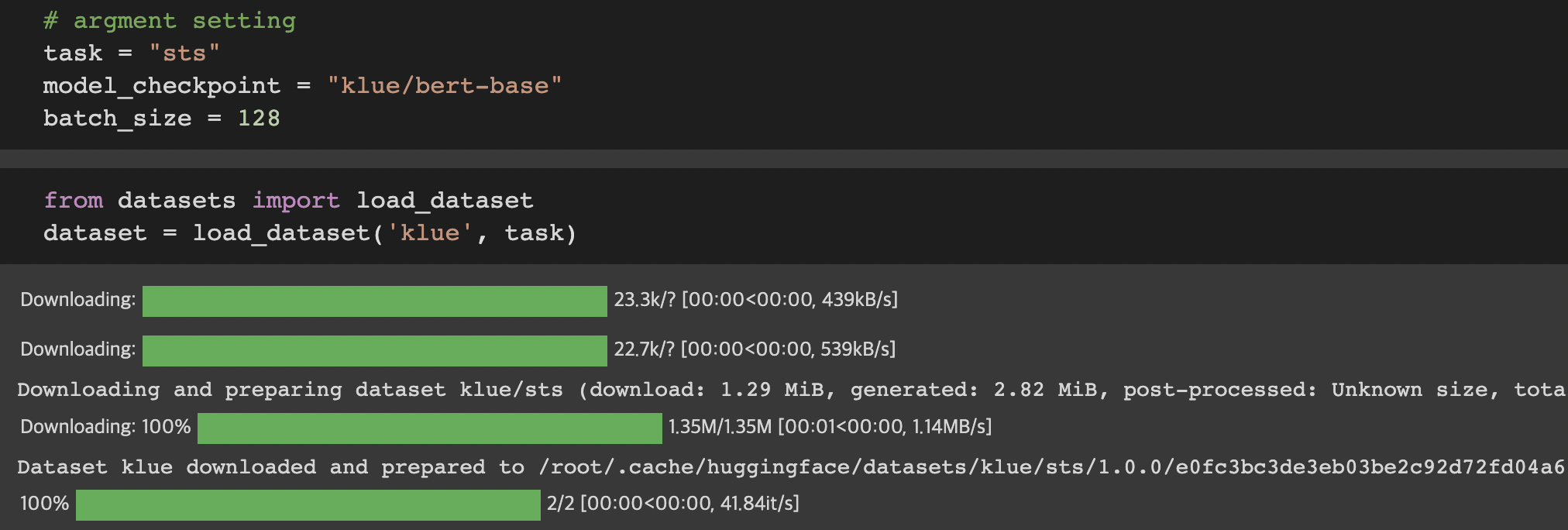
사용할 task 간 STS 이므로 task 변수에 "sts"를 저장해줍니다
사전학습 할 모델 이름 "klue/bert-base" 도 따로 저장해
뒤에서 두고두고 사용하게 됩니다
그 다음 셀에서는 datasets의 load_dataset을 이용해
KLUE-STS 를 다운로드 받아줍니다

dataset 에 다운 받은 데이터를 type 찍어보면
datasets dict 형식이라고 나옵니다
dict type 이니 당연히 key를 찍어보면 'train'과 'validation'이
나눠져 저장되어 있는 것을 알 수 있습니다

각각의 구조를 확인해줍니다
train은 11668 rows
validation은 519 rows
임을 볼 수 있습니다

이제 하나만 예시로 보겠습니다
labels가 하위에도 3개의 keys 로 나눠짐을 알 수 있습니다
즉 labels가 3가지 종류가 잇는 셈입니다
이진분류 label, 반올림or 버림된 label 값, 실제 label 값으로 보입니다
3.2 pre-trained Tokenizer
 출처: Hugging Face
출처: Hugging Face
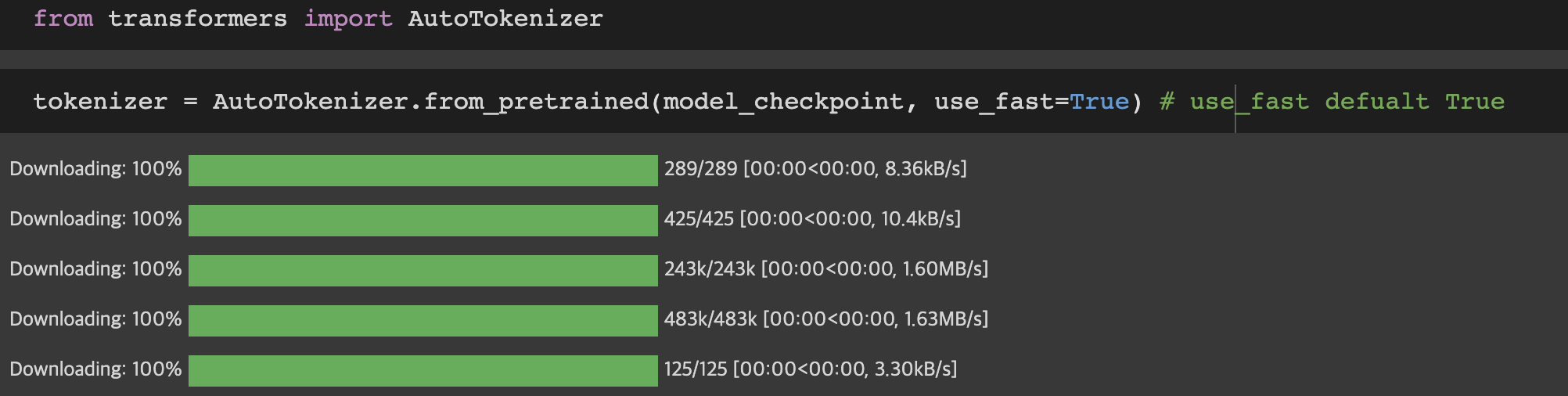
이제 Tokenizing에 필요한 Tokenizer가 필요한데
transformers 의 AutoTokenizer를 사용해 pre-trained 된 tokenizer를 다운로드 합니다
이렇게 하는 이유는
- 사용하는 모델이 입력받는 형식으로 토크나이징 하는 tokenizer 를 다운로드
- 특정 체크포인트를 pretraining할 때 사용된 vocabulary를 다운로드
하기 위해서 입니다
parameter use_fast 의 경우 AutoTokenizer 4버전 부터는 default 값이 True 이지만 reference를 따라 그냥 작성했습니다
3.2.1 token_type_ids

다운로드 받은 Tokenizer 를 사용해 아무 문장이나 tokenizing 해봅니다
최상단 셀의 출력은 우리가 다운로드 한 klue/bert-base 의 입력형식 되로 tokenizing 된 결과이며
아래 셀의 tokens() 출력 결과는 문장이 token이 된것을 보여줍니다
실제로 아래 출력된 token들이 input_ids의 index값으로 변환되어 저장된 것입니다.
token_type_ids 는 모두 0이고
attention_mask 는 모두 1로 출력되었는데 이것은 무엇을 의미할까요?
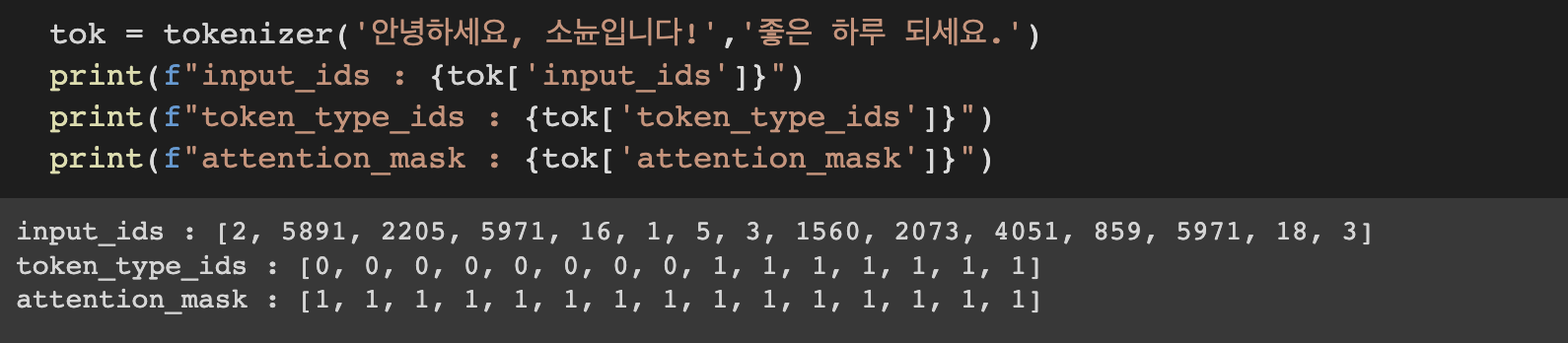
문장을 2개 입력해보면 token_type_ids 를 파악할 수 있습니다
바로 문장을 구분하는 ids 임을 알 수 있습니다
0과 1로 문장에 따라 token들에 값이 부여됩니다

문장 두개를 입력했을 때도 token은 똑같은 형태로 생성됩니다
3.3 prepare dataset

아까 위에서 살펴본 대로 labels 값이 3개로 나눠진 것을 flatten 취해줘야 합니다
결과를 출려해보면 왜 그렇게 하는지를 이해할 수 있습니다
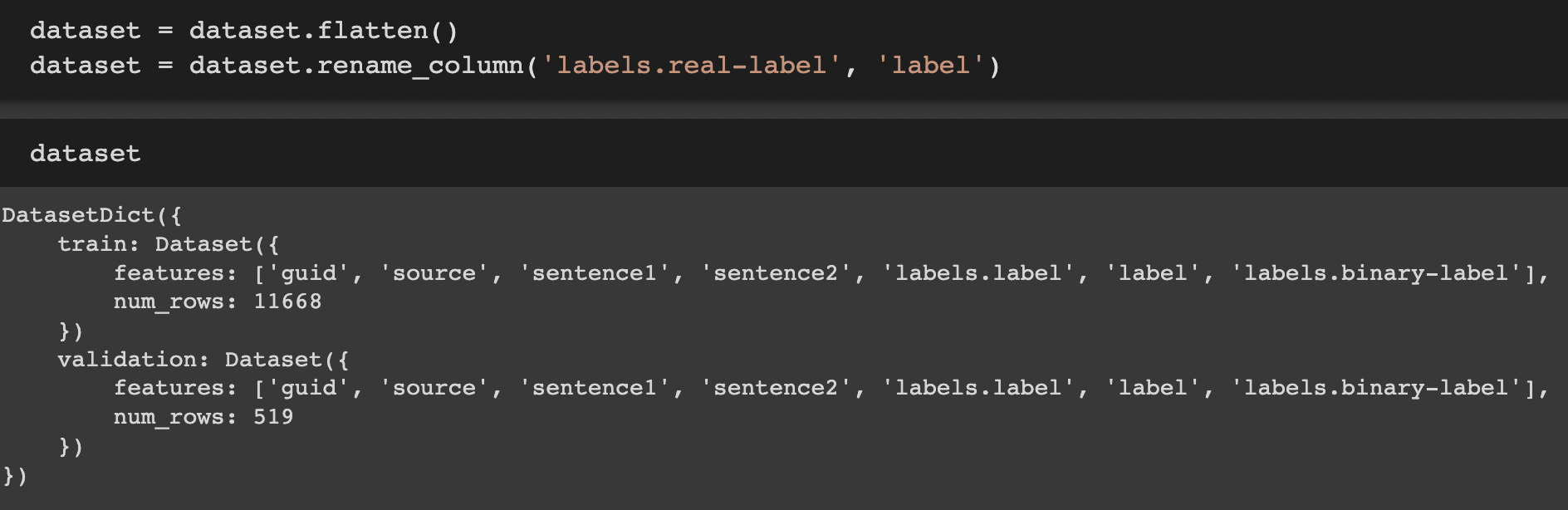
그럼 flatten() 취해 저장하고 real-label을 label이라 rename 해줍니다
이제 데이터셋을 만들어줬으니, truncation, padding 같은 전처리를 해줘야 합니다

이렇게 truncation과 padding을 적용해 tokenizing 하는 함수를 정의하고

전체 데이터셋에 적용하기 위해 datasets 객체의 map 메소드를 사용합니다
batched=True는 배치로 묶어서 텍스트를 인코딩 하는 것으로, 앞서 로드한 fast tokenizer의 이점을 활용합니다. fast tokenizer는 멀티 쓰레딩을 사용하여 텍스트를 배치 형태로 거의 동시에 처리하는 것이라 합니다.
3.3.1 attention_mask

마지막을 앞서 살펴보기로 한 attention_mask 의 의미를 보겠습니다
어텐션 마스크는 BERT가 어텐션 연산을 할 때, 불필요하게 패딩 토큰에 대해서 어텐션을 하지 않도록 실제 단어와 패딩 토큰을 구분할 수 있도록 알려주는 입력입니다. 이 값은 0과 1 두 가지 값을 가지는데, 숫자 1은 해당 토큰은 실제 단어이므로 마스킹을 하지 않는다라는 의미이고, 숫자 0은 해당 토큰은 패딩 토큰이므로 마스킹을 한다는 의미입니다 [발췌링크]
실제로 패딩을 적용한 encoded_dataset의 0번째 데이터에 대한
attention_mask 출력을 보면
쭉 1로 이어지던 값이 어느 순간 부터 0으로 바뀝니다
즉 보다 큰 문장에 맞춰 패딩된 뒷 토큰들을 0으로 기록해 모델이 attention 하지 않도록 도와줍니다
이로써 KLUE-STS 에 대한 공부와 구조 파악을 마쳤습니다
앞에서도 언급했지만 참고해 공부한 reference들을 다시 한번 참조합니다
STS 모델링을 이제 막 공부하시는 분들이라면 꼭 한 번씩 읽어보면 좋을 듯 합니다
Reference
