오늘은 신경망이 어떻게 적용되는지 실제 사례를 살펴보고, 적용 과정을 차근차근 진행하면 어떻게 적용되는지를 알아보도록 하자.
1. 부동산 감정 평가
우선 '부동산 감정 평가'라는 사례를 통해 신경망이 어떻게 적용되는지부터 알아보자.
부동산의 매개변수를 받아 가치를 평가하는 신경망으로, '이미 훈련된 것처럼 보이는 신경망'을 사용해서 작업한다.
💡 아주 기본적인 형태의 신경망에는 은닉층 없이 입력층과 출력층만 존재한다.
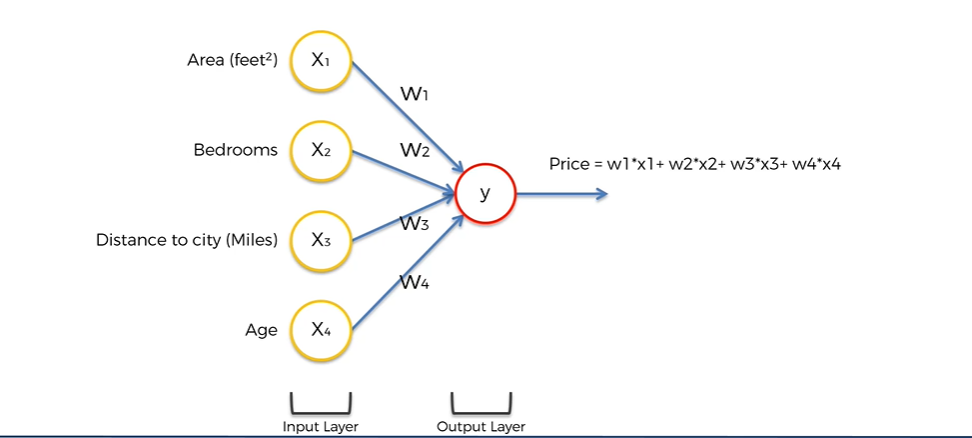
입력층 (입력 매개변수)
- 총 4개의 변수가 존재한다.
- X1, X2, X3, X4로 명명하며, 각각 Area, Bedrooms, Distance to city, Age를 의미한다.
- 시냅스에 의해 가중치가 부여되어 출력층이 계산된다.
각각의 가중치는 W1, W2, W3, W4로 명명한다.
신경망의 은닉층
신경망은 높은 유연성과, 많은 기능을 얻을 수 있다는 장점이 있다. 이 장점을 가능하게 하는 것이 은닉층인데, 은닉층을 거칠 수록 정확도가 올라가게 된다. 위 신경망에서 은닉층 (Hidden Layer)이 추가된 모습을 살펴보자.
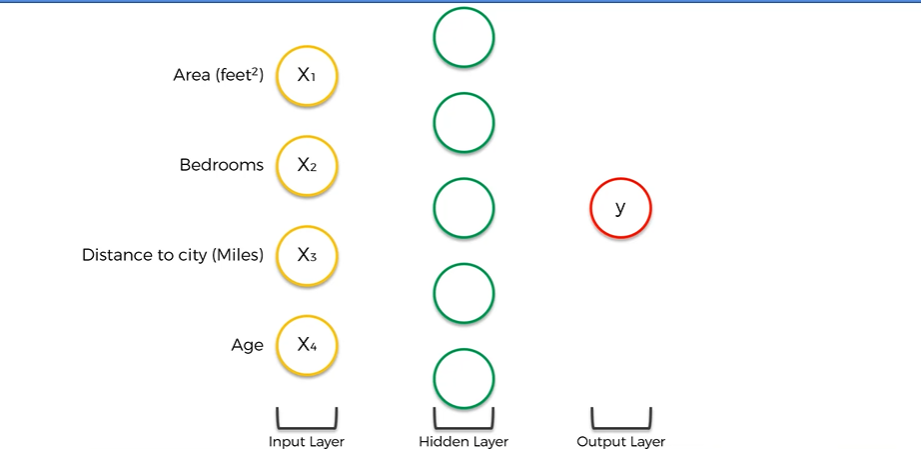
그렇다면, 신경망이 어떻게 입력 변수를 다루고 은닉층과 출력층을 계산하는지 단계별로 알아보도록 하자.
- 입력층의 모든 뉴런은 은닉층의 맨 위 뉴런에 연결하는 시냅스를 가지고 있다.
- 해당 시냅스는 가중치를 가지고 있다.
이때, 어떤 가중치는 0이 아니고, 어떤 가중치는 값이 0이다. 즉, 모든 입력 값이 유효한 값이 아닐 수도 있다는 의미이다.
왜? 모든 입력값이 모든 뉴런에 중요하게 작용하지 않기 때문이다.
아래 그림을 한 번 살펴보자.
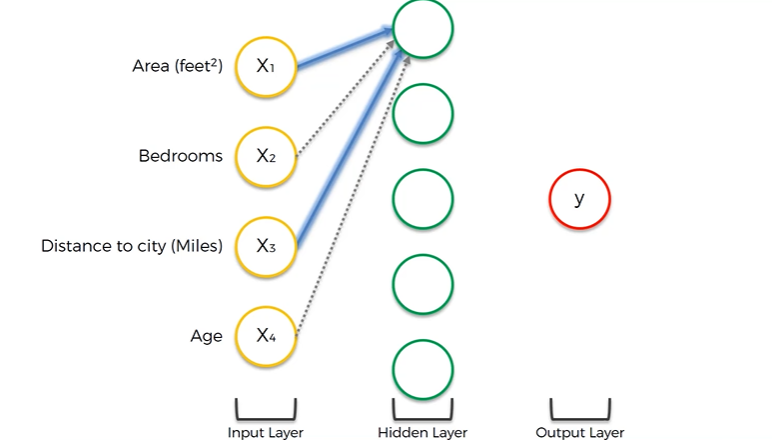
해당 사진에서 우리가 알 수 있는 건 어떤 매개 변수가 은닉층의 첫 번째 뉴런에 중요하게 여겨지고, 중요하게 여겨지지 않는지이다.
X2, 침실의 수와 X4, Age는 중요하지 않아 가중치가 0으로 조정되었고, x1, area와 x3, Distance to city는 중요하기 때문에 특정 가중치와 곱해져 뉴런에 영향을 주게 되었다.
이러한 결론은 우리가 이미 훈련된 모델을 사용한다고 가정했기 때문에 도출해 낼 수 있는 결론이다.
우리는 이미, 이 뉴런이 수천 개의 예시들을 통해 'Area', 'Age' 등 다양한 매개변수들의 조합의 중요성을 알아낸 걸 알고 있다. 그래서 특정 뉴런에 반응하는 매개변수의 조합이 정해져있는 것이다. → 뉴런이 그렇게 선택한 것
은닉층, Hidden Layer는 신경망의 유연성을 높여준다. 또한, 신경망이 아주 구체적인 내용을 찾을 수 있게 해준다. 각각의 뉴런들 자체로는 가격을 예측할 수 없지만, 여러 뉴런을 모아 제대로 훈련하고 가중치를 잘 설정하기만 하면 가격을 꽤 정확하게 예측할 수 있게 된다.
신경망은 어떻게 학습하는가
프로그램이 작업을 수행하게 하는 방법은 크게 두 가지로 분류할 수 있다.
1. 하드 코딩
- 프로그램에 구체적으로 규칙을 정해주고 원하는 결과를 알려준다. 즉, 전체 과정을 안내해주는 것
→ 프로그램이 처리해야 할 가능성이 있는 모든 옵션들을 설명해주는 것이다. - ex : 고양이와 개를 구분할 때 / 고양이의 귀는 이렇게 생겨야 하고 수염을 찾고, 어떤 식으로 생긴 코를 찾아야 하고, 어떤 형태의 얼굴을 찾고, 어떤 색상을 찾아야 한다고 프로그래밍 하기. 모든 부분을 묘사해야 한다.
2. 신경망
- 프로그램이 스스로 무슨 일을 하고 있는지 이해할 수 있는 기반을 만드는 것.
- 신경망을 만들어서 입력 정보를 제공하고 뭐가 출력값을 가지고 있는지 알려주고 나머지는 스스로 알아내도록 내버려 두는 것
- ex : 고양이와 개를 구분할 때 / 신경망을 코딩한다. 즉, 아키텍처를 코딩하는 것. 그리고 신경망에 이미 분류된 고양이와 개의 사진이 담긴 폴더를 알려준다. 신경망에게 고양이와 개의 사진들이 여기 있으니 고양이는 어떻게 생겼는지 학습하고 개는 어떻게 생겼는지 학습하여라~ 와 같은 식으로 알려주는 것이다.
→ 근본적으로 다른 두 가지 방법!
두 번째 방식인 신경망의 작동 원리에 대해 알아보자.
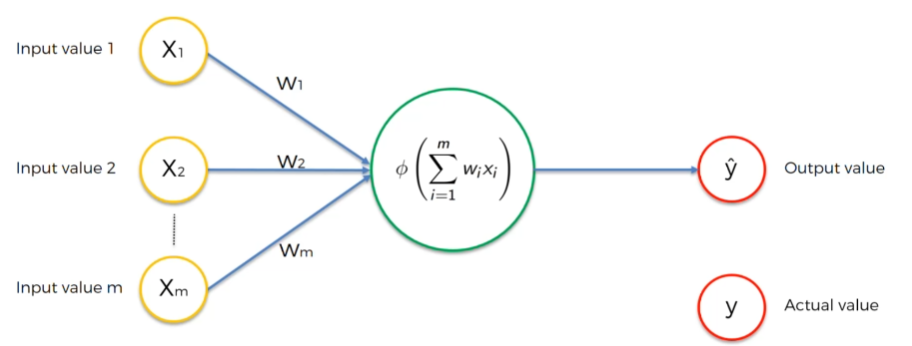
아주 기초적인 한 층짜리 신경망을 표현한 그림이다.
→ 이를 단층 피드포워드 신경망, 퍼셉트론 (Single Feed-forward Neural Network, Perceptron) 이라고 부른다.
- y는 실제로 보는 값, ŷ 즉 출력값은 신경망이 예측한 값이다.
비용 함수
비용함수는 실제값과 출력값 간 제곱 차이의 절반으로 계산된다.
사용할 수 있는 비용 함수에는 여러가지가 있는데, 이게 가장 흔하게 사용되는 비용함수이다.
비용 함수는 예측한 값에 오류가 있다는 걸 나타낸다. 그래서 우리의 목표는 비용 함수를 최소화 하는 것. 비용 함수가 작을 수록 ŷ와 y의 값이 비슷하다.
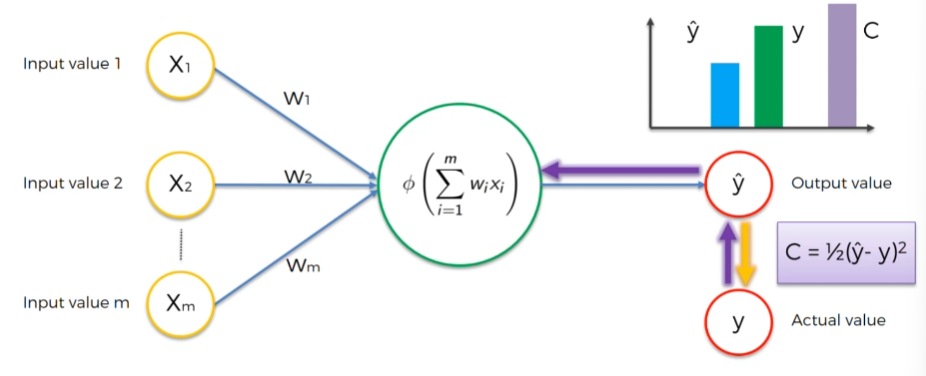
C가 비용함수의 값이라고 하자.
비교가 끝나면 이 정보를 다시 신경망에 주입한다!
신경망으로 정보가 되돌아가면, 가중치로 가서 가중치가 업데이트한다. 우리가 이 간단한 신경망에서 제어할 수 있는 건 가중치밖에 없다.
가중치를 업데이트하고 조금 조정해준다. 가중치를 업데이트 했다 치고, 진행해보자.
비용함수를 최소화하기 위해 위 과정을 계속 반복한다. 비용 함수의 최소치를 찾는 순간 최종 신경망을 완성한 것이다. 최적의 가중치를 찾았다는 뜻 !
CrossValidated의 '애플리케이션과 함께 신경망에서 사용되는 비용 함수 목록'
-> 비용 함수에 대해 더 알아보고 싶으면 한 번 읽어보면 좋다