LLM DAY 6
- Test Set 구축 시 RAG 기반 청크 전략 및 검색 전략 고려 사항
Retrieval-Augmented Generation (RAG) 시스템에서 Test Set을 설계할 때, 단순히 문서를 청크하고 벡터화하는 것만으로는 충분하지 않다.
어떤 유형의 데이터로 어떤 목표 수준의 시스템을 구축할 것인지에 따라, 적절한 청크 전략(chunking strategy) 및 검색 전략(retrieval strategy)을 고려해야 한다.
특히, Test Set의 청크 방식은 RAG 시스템의 성능을 검증하는 데 중요한 요소로 작용한다. 청크의 크기와 구조는 문서의 맥락 유지, 검색 성능, 정답 포함률(Recall), 응답 생성 품질 등에 직접적인 영향을 미치기 때문이다. 따라서, Test Set 구축 시에는 다음과 같은 요소를 종합적으로 고려해야 한다.
- RAG 시스템의 목적: 질의 유형(예: Fact-based QA, 요약, 생성 등)에 맞는 최적의 청크 설계
- 데이터 유형: 구조화된 데이터(예: 표, 코드) vs. 비구조화 데이터(예: 논문, 기사)별 최적의 청크 크기 결정
- 검색 성능 최적화: 단순 벡터 인덱싱 외에 Hybrid Search (BM25+Embedding) 등의 검색 전략 적용
- 검증 수준 설정: 모델의 정확도(Precision) vs. 포괄성(Recall) 균형을 맞추기 위한 Test Set 청크 기준 설정
이러한 요소를 반영한 Test Set 청크 설계는 RAG 시스템의 평가 신뢰도를 높이고, 최적의 검색 및 응답 생성을 지원하는 핵심 요인이 된다.
- 청크(Chunk)란?
큰 내용을 작은 덩어리로 나누는 것! 더 쉽게 이해하고 처리하기 위해 필요 🚀
파일(data/ai.txt)을 읽어 Document 객체로 변환
세 가지 텍스트 분할기를 사용하여 청크를 생성
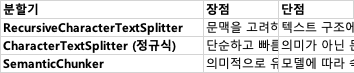
- RecursiveCharacterTextSplitter (문맥 유지에 최적화)
- CharacterTextSplitter (정규식 기반 단순 분할)
- SemanticChunker (의미 기반 분할)
각 분할기의 결과 비교 및 장단점 분석

- RecursiveCharacterTextSplitter → 가장 일반적인 청크 분할 방식, 검색 최적화에 적합
- CharacterTextSplitter → 정규식 기반으로 단순하지만, 문맥 손실 가능
- SemanticChunker → 의미를 보존하는 최적의 방법, 하지만 속도가 느릴 수 있음
💡 활용
RecursiveCharacterTextSplitter → 일반적인 검색 시스템 (RAG)
CharacterTextSplitter → 문장 기반 요약 모델
SemanticChunker → 의미 기반 검색 최적화
