카메라 스티커앱
카메라앱을 만들기를 하면서 동영상 처리, 키포인트 추정, 추적, 카메라 원근의 기술을 다루는 것을 연습해보자
이미지는 png(Portable Network Graphics)파일을 사용한다
png파일
- 무손실 압축을 사용해 이미지 손실이 없고 고품질 이미지를 생성한다. 보통 이미지 편집에 많이 사용됨
- 배경이 투명해서 배경 이미지 위에 png 파일을 얹어 두 이미지를 자연스럽게 합성시킬 수 있다.
위 이미지를 확인하면 배경이 체커판 패턴으로 보이는데 이 부분이 투명한 부분이다.
위 사진을 활용해 머리에 왕관을 씌어보자
사진 준비하기
스티커를 적용하기 위해서는 눈,코,입,귀와 같은 얼굴 각각의 위치를 알아야한다. 이 위치들을 찾아내는 기술을 랜드마크(landmark) 또는 조정(alignment)이라고 한다.
대부분의 face landmark 데이터셋은 눈,코,입,턱을 포함하고 있다. 얼굴의 랜드마크를 찾으면 머리의 위치를 계산하기 쉽다. 눈 또는 코 위치에서 위로 떨어져 있는 거리를 데이터로부터 유추할 수 있다.
순서는
- 얼굴이 포함된 사진 준비
- 사진에서 얼굴 영역을 찾는다 (먼저 bounding box를 찾고 그 box를 사용해 landmark를 찾는다)
- 찾은 영역에 위치를 조정해 머리에 왕관 이미지를 붙인다
사진은 왕관이 어울리시는 유느님 사진으로 해보겠습니다.
import cv2
import matplotlib.pyplot as plt
import numpy as np
import dlib
image_path = "image.png"
img_bgr = cv2.imread(image_path) # openCV로 이미지를 불러온기
img_show = img_bgr.copy() # 출력용 이미지를 따로 저장하기
plt.imshow(img_bgr)
plt.show()
결과 값을 보면 얼굴 색이 파랗게 나온다. 이는 openCV의 특징 때문에 생기는 현상으로 대부분 이미지 채널을 RGB 순서로 사용하지만 openCV는 예외적으로 BGR을 사용한다 따라서 파란색이 빨간색으로 빨간색이 파란색으로 바뀌어 출력된다.
openCV에서 다룬 이미지를 다른 이미지 라이브러리를 활용하여 출력하려면 색깔 보정처리는 필수이다.
# plt.imshow 이전에 RGB 값을 설정해줘야 한다
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
사진이 색이 정상적으로 돌아왔다.

cvtColor()함수의 매개변수
- src : 입력이미지(부호 없는 8비트, 16비트)
- dst : src와 같은 크기와 깊이의 출력 이미지
- code : 색 공간 변환 코드 (COLOR_BGR2RGB, COLOR_RGB2GRAY ... 등)
- dstCn : 대상 이미지의 채널 수 (매개변수가 0이면 채널 수는 src 및 코드에서 자동으로 파생) defalt=0
cvtColor(입력영상, 출력영상, 변환형식)으로 일반적으로 사용한다.
얼굴 검출 face detection
Object detection 기술을 이용해서 얼굴의 위치를 찾아보자
dlib의 face detector는 HOG(Histogram of Oriented Gradients)와 SVM(Support Vector Machine)을 사용해서 얼굴을 찾는다.
HOG는 이미지에서 색상의 변화량을 나타낸 것이다. 색상 변화량을 계산해 이미지로부터 물체의 특징만 잘 잡아낸다.

[사진 출처 wikipedia]
HOG를 시각화한 이미지에서 사람형체가 잘 보인다
SVM은 선형 분류기로 한 이미지를 다차원 공간의 공간의 한 벡터라고 보면 여러 이미지는 여러 벡터가 된다. 이 벡터들을 구분짓는 방법이다. 지금은 얼굴이냐 아니냐를 구분한다.

얼굴의 위치는 sliding window를 사용한다. sliding window는 작은 영역(window)을 이동해가며 확인하는 방법을 말한다. 큰 이미지를 작은 영역으로 잘라서 얼굴이 있는지 확인, 다시 작은 영역을 옆으로 옮겨 얼굴이 있는지 확인을 반복하는 방식으로 작동한다. 하지만 이미지가 크면 오래걸리는 단점이 있다.
dlib 활용 hog detector 선언
detector_hog = dlib.get_frontal_face_detector()
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
dlib_rects = detector_hog(img_rgb, 1)dlib는 rgb이미지를 입력으로 받기 때문에 cvtColor() 활용 BGR -> RGB 변환
detector_hog의 두 번째 매개변수는 이미지 피라미드의 수이다. 이미지 피라미드는 동일한 이미지의 서로 다른 사이즈 세트를 말한다. 원본 이미지에 대한 다양한 사이즈에서 얼굴을 찾는다면 좀더 정확하고 확실한 이미지를 찾을 수 있다. Image Pyramids
이미지 피라미드인 이유
가장 아래에 가장 큰 해상도를 놓고 점점 줄여가면서 쌓아가는 형태이기 때문에
찾은 얼굴을 화면에 출력해보자
# 찾은 얼굴 영역 박스 리스트
# 여러 얼굴이 있을 수 있음
print(dlib_rects)
for dlib_rect in dlib_rects:
l = dlib_rect.left()
t = dlib_rect.top()
r = dlib_rect.right()
b = dlib_rect.bottom()
cv2.rectangle(img_show, (l,t), (r,b), (0,255,0), 2, lineType=cv2.LINE_AA)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()
정상적으로 얼굴을 인식했고 녹색 박스가 출력됐다.
dlib detector는 dlib.rectangles타입의 객체를 반환한다. dlib.rectangles는 dlib.rectangle객체의 배열 형태로 이루어져 있다.
cv2.rectangle
rectangle() 함수를 이용하여 사각형 그릴 수 있다. rectangle은 시작점(좌측 상단)과 종료점(우측 하단) 두 곳의 좌표만 기입하여 도형을 그린다.
cv2.rectangle(img, pt1, pt2, color, thickness, lineType, shift)
parameter 내용 img 이미지파일 pt1 시작점 좌표(x,y) pt2 종료점 좌표(x,y) color 색상(blue,green,red) 0~255 thickness 선 두께(default=1) lineType 선 종류 (default cv.Line_8) - LINE_8 : 8-connected line - LINE_4 : 4-connected line - LINE_AA : antialiased line shift factional bit(default 0)
얼굴 랜드마크 face landmark
스티커를 정확하게 붙이기 위해서 이목구비 위치를 먼저 찾아보자
이목구비의 위치는 face landmark localization를 이용해 추론할 수 있다. face landmark는 detection으로 만들어진 bounding box로 잘라낸(crop) 얼굴 이미지에 적용된다.
Object keypoint estimation 알고리즘
Face landmark와 같이 객체 내부의 점을 찾는 기술을 object keypoint estimation이라고 한다. keypoint를 찾는 알고리즘은 2가지로
- top-down : bounding box를 찾고 box 내부의 keypoint를 예측
- bottom-up : 이미지 전체의 keypoint를 먼저 찾고 point 관계를 이용해 군집화 해서 box 생성
첫 번째 방법을 사용할 예정
Dlib landmark localization
잘라진 얼굴 이미지에서 68개의 이목구비 위치를 찾는다

랜드마크 데이터셋 요약
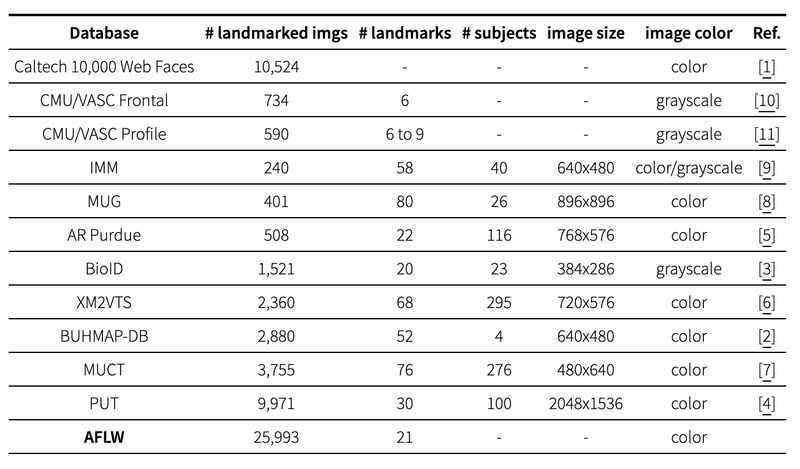
Dlib는 ibug 300-W 데이터셋으로 학습한 pretrained model을 제공한다. 학습 알고리즘은 regression tree의 앙상블 모델을 사용했다.
알고리즘 참조 : One Millisecond Face Alignment with an Ensemble of Regression Trees
Dlib의 제공되는 모델을 사용한다. 해당 모델 파일은 bz2 압축파일 형태로 제공되어 윈도우에선 7-zip을 사용해 풀어준다.
- http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
- 보통 프로그래밍을 하면 일반
.zip파일 보다 다양한 압축 파일들을 만나게 되는데 7-zip은 웬만한 압축 파일들에 사용할 수 있어 설치하는 것을 추천한다.
저장한 landmark 모델 불러오기
model_path = shape_predictor_68_face_landmarks.dat
landmark_predictor = dlib.shape_predictor(model_path)landmark_predictor는 RGB이미지와 dlib.rectangle을 입력받아 dlib.full_object_detection을 반환한다.
list_landmarks = []
# 얼굴 영역 박스 마다 face landmark를 찾아낸다
for dlib_rect in dlib_rects:
points = landmark_predictor(img_rgb, dlib_rect)
# face landmark 좌표를 저장
list_points = list(map(lambda p: (p.x, p.y), points.parts()))
list_landmarks.append(list_points)
print(len(list_landmarks[0]))parts()함수로points의 개별 위치에 접근해 (x,y)형태로 변환list_points는 tuple(x,y) 68개로 이루어진 리스트- 얼굴이 여러개라면 얼굴 개수만큼 반복한다.
list_landmark에 68(랜드마크) * n(얼굴 수) 만큼 저장된다
랜드마크 영상에 출력
for landmark in list_landmarks:
for point in landmark:
cv2.circle(img_show, point, 2, (255, 255, 255), -1)
img_show_rgb = cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB)
plt.imshow(img_show_rgb)
plt.show()점이 잘 보이지 않아 검은색으로 마크했다.

스티커 적용하기
이제 유느님 머리에 왕관을 씌어드릴 때가 됐다.
랜드마크를 기준으로 보면 얼굴 중앙에서 눈썹위로 적용하면 알맞아보인다.
스티커를 적용하는 방법은 다양하게 할 수 있다. 코를 기준으로 해도 되고 눈썹을 기준으로 해도 된다.
조심해야 할 점은 얼굴 위치, 카메라 거리에 따라 값이 다 다르기 때문에 비율로 계산을 해야한다.
스티커 위치와 스티커 크기를 생각해보자
스티커는 코를 기준으로 맞추기로 했다.
아래 x,y는 좌표이다.
왕관 위치
- x는 코를 기준으로 위로 올라갈 예정이라 그대로 사용한다.
- y는 박스 크기를 기준으로 박스의 반 정도 올릴 생각이라 박스 세로길이의 반을 빼준다(빼는 것은 위로 올라간다)
왕관 크기
- 스티커 크기는 박스의 세로길이에 맞춰 정사각형으로 맞춘다
좌표를 먼저 확인해보자
for dlib_rect, landmark in zip(dlib_rects, list_landmarks):
print(landmark[30])
x = landmark[30][0]
y = landmark[30][1] - dlib_rect.height()//2
w = h = dlib_rect.width()
print('(x,y) : (%d, %d)'%(x,y))
print('(w,h) : (%d, %d)'%(w,h))landmark[30]번은 코의 중앙이다.
유느님의 코의 좌표는 (443, 249)이고 (x,y)는 왕관의 위치 좌표 (443, 156), (w,h)는 왕관의 크기 (187, 187)이다.
이제 왕관 이미지를 불러온다.
sticker_path = 'king.png'
img_king = cv2.imread(sticker_path)
img_king = cv2.resize(img_king, (w,h))
print(img_king.shape)왕관 이미지를 읽고 위에서 계산한 크기로 resize한다
원본 이미지에 스티커 이미지를 추가하기 위해서 x,y 좌표를 조정한다. 이미지 시작점은 top-left 좌표이기 때문이다.
refined_x = x-w//2
refined_y = y-h
print('(x,y) : (%d,%d)'%(refined_x, refined_y))출력을 해보면 y값이 음수인 것을 확인할 수 있다.
왕관이미지의 시작점이 얼굴 사진의 영역을 벗어났을 경우에 음수로 표현된다. opencv 데이터는 numpy의 ndarray 형태의 데이터를 사용하는데 ndarray는 음수 인덱스에 접근할 수 없다. 따라서 음수인 값은 예외 처리 과정을 거쳐야 한다. (범위를 벗어난 부분을 제거한다.)
이번 경우에는 y 좌표 값만 음수로 나왔지만 x 좌표의 값도 음수가 될 수 있다.
if refined_x < 0:
img_king = img_king[:, -refined_x:]
refined_x = 0
if refined_y < 0:
img_king = img_king[-refined_y:, :]
refined_y = 0
print('(x,y) : (%d, %d)'%(refined_x, refined_y))-y 크기만큼 스티커를 crop하고, 벗어난 x,y좌표를 제외한 값을 입력한다.
# 너무 복잡해 보인다 하지만 단순한 img_show[from:to] 형식이다.
king_area = img_show[refined_y:refined_y+img_king.shape[0], refined_x:refined_x+img_king.shape[1]]
img_show[refined_y:refined_y+img_king.shape[0], refined_x:refined_x+img_king.shape[1]] = np.where(img_king==0,king_area,img_king).astype(np.uint8)king_area는 원본이미지에서 왕관을 적용할 위치를 crop한 이미지이다.
왕관 이미지는 배경이 없는 처리가 되어있기 때문에 배경을 없애고 자연스럽게 적용하기 위해 np.where을 사용해 img_king이 0인 부분은 king_area를 사용하고 0이 아닌 부분은 img_king을 사용하면 된다.
plt.imshow(cv2.cvtColor(img_show, cv2.COLOR_BGR2RGB))
plt.show()
bounding box와 landmark를 제거하고 최종 결과만 출력해보자. img_show 대신 img_bgr을 사용한다.
sticker_area = img_bgr[refined_y:refined_y +img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]]
img_bgr[refined_y:refined_y +img_sticker.shape[0], refined_x:refined_x+img_sticker.shape[1]] = np.where(img_sticker==0,sticker_area,img_sticker).astype(np.uint8)
plt.imshow(cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB))
plt.show()
이로서 완성됐다.
openCV 추가 설명
openCV 읽고 보고 쓰기
cv2.imread(), cv2.imshow(), cv2.imwrite()에 대해서 알아보자
cv2.imread()
openCV 모듈을 import 한다
import cv2이미지가 먼저 필요하기 때문에 cv2.imread()를 사용하여 이미지 파일을 읽는다. 이미지 파일의 경로는 절대/상대경로가 가능하다.
img = cv2.imread('lena.jpg', cv2.IMREAD_COLOR)cv2.imread(fileName, flag)
이미지 파일을 flag 값에 따라서 읽어들인다.
- Parameters : fileName(str) = 이미지파일의 경로, flag = 이미지 파일을 읽을 때의 Option
- Returns : image 객체 행렬
- Return type : numpy.ndarray
cv2.imread의 flag는 3가지가 있다.
cv2.IMREAD_COLOR: 이미지 파일을 Color로 읽어들인다. 투명한 부분은 무시되고 Default 값이다.cv2.IMREAD_GRAYSCALE: 이미지를 Grayscale로 읽어들인다. 실제 이미지 처리시 중간단계로 많이 사용한다.cv2.IMREAD_UNCHANGED: 이미지파일을 alpha channel까지 포함하여 읽어들인다.- 3개의 flag 대신에 1,0,-1을 사용해도 된다 (순서대로)
img.shape를 확인하면 (206, 207, 3) 3차원 행렬로 return이 된다. 행 = 206, 열 = 207, 행과 열이 만나는 지점의 값이 몇개의 원소 = 3
3은 색을 표현하는 BGR 값이다. 보통 RGB지만 위에서 설명한 것처럼 opencv는 BGR이다.
cv2.imshow()
cv2.imshow() 함수는 이미지를 사이즈에 맞게 보여준다.
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.imshow(title, image)
읽어들인 이미지 파일을 윈도우 창에 보여준다.
- Parameters : title(str) = 윈도우 창의 title, image(numpy.ndarray) =
cv2.imread()의 return 값
cv2.waitKey()는 keyboard 입력을 대기하는 함수로 0이면, key입력까지 무한대기이며 특정 시간동안 대기하려면 milisecond 값을 넣어주면 된다.
cv2.destroyAllWindows()는 화면에 나타난 윈도우를 종료한다.
일반적으로 위 3개는 같이 사용된다
샘플 코드
import cv2
fname = 'lena.jpg'
original = cv2.imread(fname, cv2.IMREAD_COLOR)
gray = cv2.imread(fname, cv2.IMREAD_GRAYSCALE)
unchange = cv2.imread(fname, cv2.IMREAD_UNCHANGED)
cv2.imshow('Original', original)
cv2.imshow('Gray', gray)
cv2.imshow('Unchange', unchange)
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.imwrite()
cv2.imwrite()함수를 이용하여 변환된 이미지나 동영상의 특정 프레임을 저장한다.
cv2.imwrite('lenagray.png', gray)cv2.imwrite(fileName, image)
image 파일을 저장한다.
- parameters : fileName(str) = 저장될 파일명, image = 저장할 이미지
샘플 코드
import cv2
img = cv2.imread('lena.jpg', cv2.IMREAD_GRAYSCALE)
cv2.imshow('image',img)
k = cv2.waitKey(0)
if k == 27: # esc key
cv2.destroyAllWindow()
elif k = ord('s'): # 's' key
cv2.imwrite('lenagray.png',img)
cv2.destroyAllWindow()이미지 피라미드(Image Pyramid)
이미지 피라미드의 종류는 Gaussian Pyramid, Laplacian Pyramid 두 가지가 있다.
Gaussian Pyramid
가우시안 피라미드는 High Level(낮은 해상도, Pyramid 상단)은 Lower level에서 row와 column을 연속적으로 제거하면서 생성된다. MxN 사이즈 이미지는 M/2 x N/2가 적용되면 1/4 사이즈로 줄어들게 된다.
import cv2
img = cv2.imread('images/lena.jpg')
lower_reso = cv2.pyrDown(img) # 원본 이미지의 1/4 사이즈
higher_reso = cv2.pyrUp(img) #원본 이미지의 4배 사이즈
cv2.imshow('img', img)
cv2.imshow('lower', lower_reso)
cv2.imshow('higher', higher_reso)
cv2.waitKey(0)
cv2.destroyAllWindows()
Laplacian Pyramid
라플라시안 피라미드는 가우시안 피라미드에서 만들어진다 cv2.pyrDown()과 cv2.pyrUp() 함수를 사용하여 축소, 확장을 하면 원본과 동일한 이미지를 얻을 수 없다.(계산하면서 약간의 차이 발생)
ex) 원본 이미지의 shape (225,400,3)을 cv2.pyrDown()을 적용하면 행과 열이 2배씩 줄게되고 소수점은 반올림되어 (113,200,3)이 된다. 다시 cv.pyrUp()을 하면 (226,400,3)이 되어 원본 이미지와 1row 차이가 발생한다. 이를 resize해 동일한 shape로 만든 후에 두 배열의 차이를 구하면 외곽선이 남게 된다.(짝수 해상도도 동일한 결과가 나온다)
>>> import cv2
>>> img = cv2.imread('lena.jpg')
>>> img.shape
(225, 400, 3)
>>> GAD = cv2.pyrDown(img)
>>> GAD.shape
(113, 200, 3)
>>> GAU = cv2.pyrUp(GAD)
>>> GAU.shape
(226, 400, 3)
>>> temp = cv2.resize(GAU, (400, 255))
>>> res = cv2.subtract(img, temp)
>>> cv2.imshow(res)
>>> cv2.waitKey(0)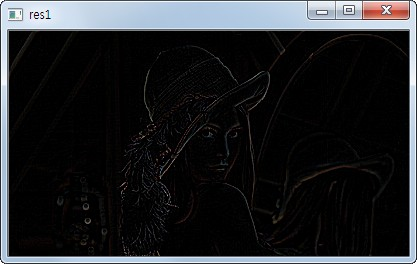
이러한 문제를 Pyramid를 이용하면 이미지 결합을 자연스럽게 처리할 수 있다. 작업 순서는 아래와 같다
- 2개의 이미지를 각각 load
- 각 이미지에 대해서 적당한 Gaussian Pyramid 생성
- Gaussian Pyramid를 이용 Laplacian Pyramid 생성
- 각 단계의 Laplacian Pyramid 이용해 각 이미지의 좌측과 우측을 결합
- 결합한 결과 중 가장 작은 이미지를 확대하면서 동일 사이즈의 결합 결과와 합쳐(add) 외곽선을 선명하게 처리
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 1단계
A = cv2.imread('images/apple.jpg')
B = cv2.imread('images/orange.jpg')
# 2단계
# A 이미지에 대한 Gaussian Pyramid를 생성
# 점점 작아지는 Pyramid
G = A.copy()
gpA = [G]
for i in xrange(6):
G = cv2.pyrDown(G)
gpA.append(G)
# B 이미지에 대한 Gaussian Pyramid 생성
# 점점 작아지는 Pyramid
G = B.copy()
gpB = [G]
for i in xrange(6):
G = cv2.pyrDown(G)
gpB.append(G)
# 3단계
# A 이미지에 대한 Laplacian Pyramid 생성
lpA = [gpA[5]] # n번째 추가된 Gaussian Image
for i in xrange(5,0,-1):
GE = cv2.pyrUp(gpA[i]) #n번째 추가된 Gaussian Image를 Up Scale함.
temp = cv2.resize(gpA[i-1], (GE.shape[:2][1], GE.shape[:2][0])) # 행렬의 크기를 동일하게 만듬.
L = cv2.subtract(temp,GE) # n-1번째 이미지에서 n번째 Up Sacle한 이미지 차이 -> Laplacian Pyramid
lpA.append(L)
# A 이미지와 동일하게 B 이미지도 Laplacian Pyramid 생성
lpB = [gpB[5]]
for i in xrange(5,0,-1):
GE = cv2.pyrUp(gpB[i])
temp = cv2.resize(gpB[i - 1], (GE.shape[:2][1], GE.shape[:2][0]))
L = cv2.subtract(temp, GE)
# L = cv2.subtract(gpB[i-1],GE)
lpB.append(L)
# 4단계
# Laplician Pyramid를 누적으로 좌측과 우측으로 재결함
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# 5단계
ls_ = LS[0] # 좌측과 우측이 결합된 가장 작은 이미지
for i in xrange(1,6):
ls_ = cv2.pyrUp(ls_) # Up Sacle
temp = cv2.resize(LS[i],(ls_.shape[:2][1], ls_.shape[:2][0])) # 외곽선만 있는 이미지
ls_ = cv2.add(ls_, temp) # UP Sacle된 이미지에 외곽선을 추가하여 선명한 이미지로 생성
# 원본 이미지를 그대로 붙인 경우
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv2.imshow('real', real)
cv2.imshow('blending', ls_)
cv2.destroyAllWindows()