개/고양이 이미지 분류기를 만들어 보려고 한다.
분류기를 만들어보는 연습을 하면서 각각의 이론과 코드를 공부해보자.
순서는 다음과 같다
데이터 준비(데이터 불러오기) -> 데이터 확인하기(불러온 데이터를 확인하고 수정한다) -> 모델 준비(모델 불러오기, 분류 레이어 스택 쌓기) -> 모델 학습(훈련 데이터셋으로 학습) -> 모델 검증
시작 전 참고 필요한 모듈
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds기본적으로 필요한 모듈이며 중간중간 모델을 만들거나 할때 추가적으로 불러와야 하는 모듈들이 있다.
데이터 준비
항상 모델 학습을 하기 위해서는 데이터가 필요하다.
텐서플로우에서 제공하는 데이터셋 모음집을 사용할 것이다. 텐서플로우 데이터셋 모음집은 tensorflow_datasets로 우리가 사용할려고 하는 강아지, 고양이 이미지 뿐만 아니라 방대한 종류의 데이터셋을 제공해준다.(이미지, 오디오, 텍스트, 비디오 등)
자세한 정보를 얻고 싶다면 tensorflow_datasets 세부 사항을 확인하자
(train_data, validation_data, test_data), metadata = tfds.load('cats_vs_dogs', split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'], with_info = True, as_supervised=True,)train[:80%], train[80%:90%], train[90%:]은 train_data, validation_data, test_data에 각각 전체 제이터셋의 80%, 10%, 10% 세 구간으로 나눠 사용한다는 의미
tfds.load 메소드는 데이터를 다운로드하여 캐시하고 tf.data.Dataset 오브젝트를 리턴한다.
print(train_data)
print(validation_data)
print(test_data)
출력값
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>
<PrefetchDataset shapes: ((None, None, 3), ()), types: (tf.uint8, tf.int64)>모든 데이터셋은 (image,label) 형태를 가진다. 위의 출력에서는 ((None, None, 3), ())이다. (None, None, 3) = image, () = label
(None, None, 3)는 3차원 데이터 (height, width, channel)의 형태이다.
height, width가 None인 이유는 이미지의 크기가 전부 다르기 때문에 None으로 나타냈다.
3은 RGB 세 가지의 색 조합을 나타낸다
데이터 확인
데이터를 불러왔으니 이젠 확인해볼 차례이다. 데이터를 확인하기 위해서는 matplotlib를 사용한다
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.figure(figsize=(10,5))
get_label_name = metadata.features['label'].int2str
for idx, (image, label) in enumerate(train_data.take(10)):
plt.subplot(2, 5, idx+1)
plt.imshow(image)
plt.title(f'label {label} : {get_label_name(label)}')
plt.axis('off')
figsize를 통해 출력할 표의 크기 설정
get_label_name은 metadata 안에 label 컬럼안에서 가져온다.
tf.data.Dataset의 take 함수를 사용해 데이터를 10개 가져온다.
이미지 포맷
사진 크기가 제각각이라 이미지 사이즈를 모두 통일해주는 작업을 해야한다. format_example() 함수를 만들어준다.
IMG_SIZE = 160
def format_example(image, label):
image = tf.cast(image, tf.float32)
image = (image/127.5) - 1 # 픽셀 scale 수정
image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE))
return image, labeltf.cast 함수는 새로운 형태로 캐스팅하는데 사용한다. Boolean 조건일 경우는 True = 1, False = 0을 반환하고, 부동소수점을 정수로 바꿀 경우는 소수점을 버린다.
(image/127.5) - 1 : 이미지의 각 픽셀값은 RGB를 나타낼 때 사용하는 0~255 사이의 정수값으로 표현되었다. 하지만 위의 코드로 픽셀을 수정해주었기 때문에 -1 ~ 1사이의 실수값이 된다.
이제 함수를 사용해보자
format_example() 함수를 사용해 각각의 train_data, validation_data, test_data를 train, validation, test 데이터셋으로 변환한다
map()함수를 사용한다. map 함수 설명 - 코딩도장
train = train_data.map(format_example)
validation = validation_data.map(format_example)
test = test_data.map(format_example)
print(train)
print(validation)
print(test)출력값은
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>
<MapDataset shapes: ((160, 160, 3), ()), types: (tf.float32, tf.int64)>모든 이미지가 (160,160,3)으로 변화된 것을 볼 수 있다.
plt.figure(figsize=(10, 5))
get_label_name = metadata.features['label'].int2str
for idx, (image, label) in enumerate(train.take(10)):
plt.subplot(2, 5, idx+1)
image = (image + 1) / 2
plt.imshow(image)
plt.title(f'label {label} : {get_label_name(label)}')
plt.axis('off')위에서 train_data => train로 바꿔주고, image = (image + 1) / 2를 추가해 주었다
image = (image + 1) / 2는 matplotlob로 이미지 시각화 할 때 모든 픽셀값이 양수여야 하기 때문에 픽셀값이 -1 ~ 1이던 것을 0 ~ 1 로 바꿔주었다
모델 준비
이미지 데이터는 준비가 완료 되었다. 이제 이 이미지들을 학습할 모델을 만들어보자
모델 생성에 필요한 함수들을 먼저 불러온다
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D위 함수들은 자주 사용되기 때문에 잘 기억해두는 것이 좋다.
models는 모델 그 자체를 구축하기 위한 함수들을 가지고 있다.layers는 모델의 구성 요소인 여러가지 layer(층) 함수들을 가지고 있다.Sequential은 순차적인, 연속적인 이라는 뜻으로 말그대로 순차적으로 모델을 쌓기 위한 함수이다.Sequential함수 안에 순차적으로 여러 가지 레이어들이 들어간다.
model = Sequential([
Conv2D(filters=16, kernel_size=3, padding='same', activation='relu', input_shape=(160, 160, 3)),
MaxPooling2D(),
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
MaxPooling2D(),
Flatten(),
Dense(units=512, activation='relu'),
Dense(units=2, activation='softmax')
])위 코드는 Conv2D, MaxPooling2D, Flatten, Dense는 레이어이고, 각 레이어들을 여러 층을 쌓은 형태라고 이해하면 된다
그럼 모델의 전체구조를 확인해보자 summary()함수를 사용한다. (summary는 요약이라는 뜻으로 모델의 전체구조를 보여준다)
model.summary()
출력된 표를 보면 처음 (160,160,3) 크기의 이미지가 모델에 입력된 이후 각 레이어를 지나며 이미지 사이즈가 변경되는 모습들을 잘 보여준다.
각 레이어를 지날때 Output Shape는 (None, height, width, channel) 4차원의 형태이다
None은 데이터의 개수를 나타낸다. 아직 정해지지 않았기 때문에 None으로 표시된다. 배치(batch) 사이즈에 따라 다른 수가 입력될 수 있다.
각 레이어를 지날 때 마다 height, width는 160 -> 80 -> 40 -> 20으로 줄어들고, channel의 개수는 16 -> 32 -> 64로 점점 늘어난다. 이후 flatten에서 25,600(=20x20x64) 하나의 수로 합쳐져, shape가 1차원으로 줄어든다
위 과정은 CNN(Convolutional Neural Net, 합성곱 신경망)이라는 이론을 이용한 딥러닝의 대표적인 알고리즘이다.
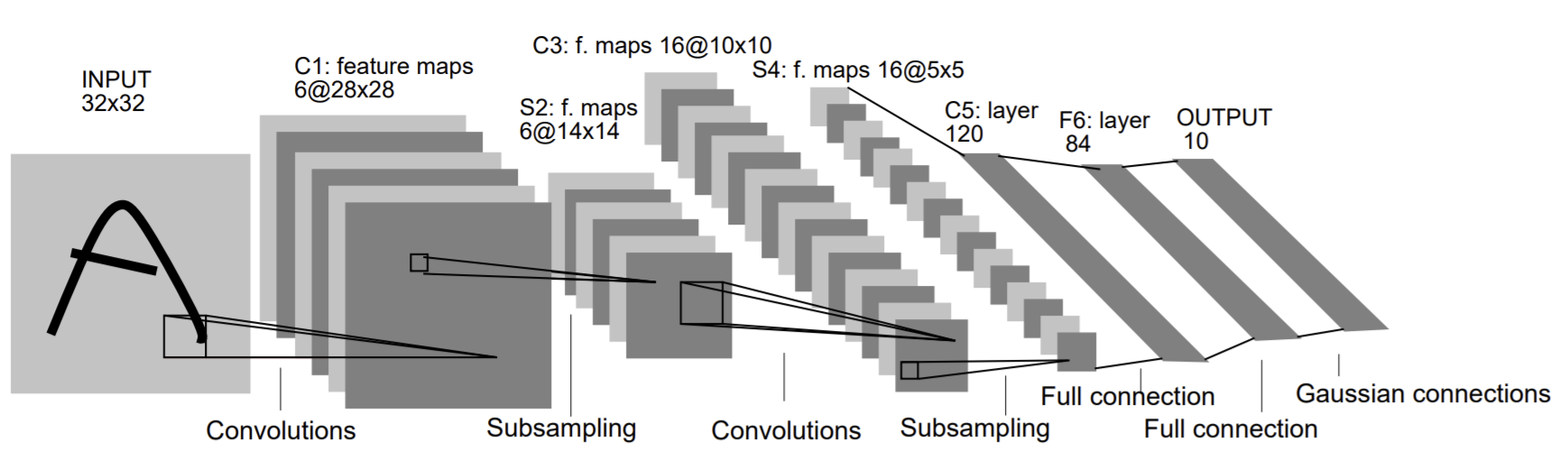 [출처 : Graduebt-Based Learning Applied to Document Recognition]
[출처 : Graduebt-Based Learning Applied to Document Recognition]
이미지 한장을 Convolutional(합성곱) 연산을 통해 크기는 작아지고, channel은 많아지다가 마지막에 flatten 함수를 통해 한줄로 펴지게 된다(3차원에서 1차원이 된다)
flatten의 간단한 예시
import numpy as np
image = np.array([[1, 2], [3, 4]])
print(image.shape)
image(2,2)의 배열인 2차원 이미지가 있을 때
image.flatten()flatten을 사용해 1차원으로 바꿔지게 된다.
위 예시와 같이 모델에서 flatten 레이어를 통과하면 숫자를 일렬로 늘어놓게 되고, Dense 레이어에서 512개의 노드로 축소 시킨 후 또 한번 Dense를 지나며 최종적으로 두 개의 숫자로 확률 분포를 출력하게 된다.
이 두 숫자는 강아지일 확률과 고양이일 확률이 된다.
모델 학습
이제 모델을 학습할 차례이다.
learning_rate(학습률)을 0.0001로 설정하고 compile()을 통해 학습할 수 있는 형태로 변환한다.
learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=learing_rate), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=['accuracy']compile에는 세 가지 파라미터가 필요하다. optimizer,loss,metrics 세 가지이다.
optimizer는최적화 함수로 어떻게 최적화시킬 것인지 결정한다. 쉽게말해 어떻게 학습을 시킬 것인지 선택한다.loss모델이 학습할 방향을 선택한다. 지금 해결하는 문제를 보면 입력받은 이미지가 강아지인지 고양이인지에 대한 확률분포로 했기 때문에, 고양이에 가까우면(label=0) 모델의 출력이 [1.0, 0.0]에 가깝도록, 강아지(label=1)일 경우 [0.0, 1.0]에 가깝도록 방향을 제시하는 것이다.metrics는 모델의 성능을 평가하는 척도이다. 분류 문제를 풀 때, 성능을 평가하는 지표는 정확도(accuracy), 정밀도(precision), 재현율(recall)등이 있다.
[참고 :숨니의 무작정 따라하기 - 분류성능평가지표]
compile을 완료하면 모델의 학습 준비는 완료되었다.
BATCH_SIZE = 32
SHUFFLE_BUFFER_SIZE = 1000
train_batches = train.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE)
validation_batches = validation.batch(BATCH_SIZE)
test_batches = test.batch(BATCH_SIZE)학습 데이터를 임의로 셔플하고 배치 크기를 정해 배치로 나눠준다
훈련하는 동안 32개의 데이터를 랜덤으로 사용할 train_batches, validation_batches, test_batches를 만들어 준다.
train_batches는 모델이 계속 학습하도록 전체 데이터에서 32개를 랜덤으로 뽑아준다.
batch size란
전체 훈련 데이터셋을 여러 작은 그룹으로 나누었을 때 하나의 소그룹에 속하는 데이터의 수를 의미한다. 우리 데이터를 예로 들면 80%로 나눈 훈련세트를 32개의 소그룹으로 나눈다.
전체 훈련 데이터셋을 나누는 이유는 훈련 데이터를 한번에 사용하면 리소스 사용이 비효율적이여서 학습 시간이 오래걸리기 때문이다. [참고 : 로스카츠의 AI 머신러닝 블로그]shuffle buffer size란
학습데이터를 적절히 섞어주기 위한 값이다. buffer size는 데이터와 같거나 그 이상으로 설정해 주어야 한다. buffer size가 작다면 제대로 섞이지 않기 때문에 [참고 : helloyjam's blog]
for image_batch, label_batch in train_batches.take(1):
pass
image_batch.shape, label_batch.shape결과값이 (TensorShape([32, 160, 160, 3]), TensorShape([32])) 나온다.
image_batch의 shape (32, 160, 160, 3)은 (160,160,3)인 데이터가 32개 존재한다는 뜻이고, label_batch의 shape가 32인 이유는 label은 0 또는 1 중 하나의 숫자로 총 32개라는 뜻이다.
모델 학습 전 테스트
모델을 학습하기 전에 초기 모델의 성능을 테스트하기 위해 validation(검증)을 위한 데이터셋 validation_batches를 이용해 20번 예측해보고, 평균 loss와 평균 accuracy를 확인해보자
validation_steps = 20
loss0, accuracy0 = model.evaluate(validation_batches, steps=validation_steps)
print("initial loss : {:.2f}".format(loss0))
print("initial accuracy : {:.2f}".format(accuracy0))
실행해보면 loss는 약 0.7, accuracy는 약 0.53 정도가 나왔다.
loss는 말 그대로 손실, 모델이 얼마나 틀렸는지에 대한 수치이고, accuracy는 정확도가 얼마인지를 보여주는 수치이다. (loss는 낮을 수록 좋고, accuracy는 높을 수록 좋다)
위의 값을 보면 약 50% 정도로 의미가 없는 수준이다.
그럼 이번엔 epoch를 사용해 10번 정도 학습시켜서 정확도가 바뀌는지 확인해보자.
epoch는 전체 학습세트가 신경망을 통과한 횟수를 의미한다. 쉽게말해 몇번 반복할지를 정한다고 생각하면 된다.
EPOCHS = 10
history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)결과 = loss: 0.0825 - accuracy: 0.9749 - val_loss: 0.7001 - val_accuracy: 0.7807
학습하는데 시간이 많이 소모되긴 했지만 대충 살펴봐도 정확도가 많이 올라간 것을 알 수 있다.
accuracy는 약 97% 정도고 val_accuracy는 약 78%정도의 수치가 나온다.
결과에 accuracy가 2개가 있는 것을 볼 수 있는데
accuracy는 훈련 데이터셋에 대한 정확도이다. 10번을 반복 학습한 데이터에 대한 정확도val_accuracy는 검증 데이터셋에 대한 정확도이다. 학습하지 않은, 10번을 반복 학습할때 보지 않은 데이터에 대한 정확도
훈련 데이터셋은 같은 연습 문제를 계속해서 풀어보는 것이고, 검증 데이터셋은 아직 풀어보지 않은 연습 문제기 때문에 훈련 데이터셋의 정확도가 높은 것이 당연하다.
모델 학습 결과 확인
이번엔 학습이 진행되는 과정 동안 정확도가 어떻게 변화하는지 그래프로 확인해보자
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(12, 8))
plt.subplot(1,2,1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legent()
plt.title("Training and Validation Accuracy")
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
정확도와 손실에 대한 그래프를 각각 그려봤다. 두 그래프 모두 훈련 데이터셋에 대한 수치와 검증 데이터셋에 대한 수치를 나타낸다. (훈련 = 파랑, 검증 = 주황)
training accuracy는 학습을 반복할 수록 점점 올라가지만 validation accuracy는 일정 수준에 도달한 이후로는 정체해 있다.
training loss는 점점 줄어들지만 validation loss는 어느 순간 갑자기 확 올라가는 것을 볼 수 있다.
이는 Overfitting(오버피팅, 과적합)이라고 한다. 모델이 훈련 데이터만으로 계속 학습하다보면 학습 데이터에만 과하게 적합되어 학습하지 않은 데이터에 대해서 성능이 떨어지는 현상을 보인다.(일반화 능력이 떨어진다)
모델을 학습시킬때는 오버피팅이 되지않는 적절한 수준을 잘 찾아내는 것이 중요하다
모델 예측
이번엔 모델의 예측 결과를 확인해보자
예측 결과는 predict()를 사용해 확인할 수 있다.
for image_batch, label_batch in test_batches.take(1):
images = image_batch
labels = label_batch
predictions = model.predict(image_batch)
pass
predictionsarray([[9.99896646e-01, 1.03321196e-04],
[9.25450802e-01, 7.45492354e-02],
[9.20293808e-01, 7.97061473e-02],
...
...
[9.9977344e-01, 2.2650993e-04],
[9.9984455e-01, 1.5546533e-04],
[9.9992609e-01, 7.3963456e-05],
[9.7274762e-01, 2.7252322e-02]], dtype=float32)predictions값들은 소수점 값들로 이루어져있다. 이 값은 강아지, 고양이를 분류한 값으로 [1.0, 0.0]에 가까우면 고양이, [0.0, 1.0]에 가까우면 강아지로 예측한 것이다.
좀더 편하게 보기 위해서 predictsions 값을 실제 추론한 label로 변환해 보자.
predictions = np.argmax(predictions, axis=1)
predictions
결과값
array([0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0])32장의 image, 32개의 label, 32개의 prediction을 각각 시각화해서 확인해보자
plt.figure(figsize=(20, 12))
for idx, (image, label, prediction) in enumerate(zip(images, labels, predictions)):
plt.subplot(4, 8, idx+1)
image = (image + 1) / 2
plt.imshow(image)
correct = label == prediction
title = f'real: {label} / pred : {prediction} \n {correct}!'
if not correct:
plt.title(title, fontdict={'color' : 'red'})
else:
plt.title(title, fontdict={'color' : 'blue'})
plt.axis('off')
많이 맞추긴 했지만 틀린 것도 없지않아 있다.
마지막으로 위 32개의 이미지에 대한 예측의 정확도가 얼마인지 계산해보자
count = 0
for image, label, prediction in zip(images, labels, predictions):
correct = label == prediction
if correct:
count += 1
print(count)68.75 약 69%의 정확도를 보이고 있다.
