🖋 머신러닝(Machine Learing)
🖋 1. 머신러닝이란 무엇인가?
- 머신러닝은
데이터에서지식을 추출하는 작업이다. 즉, 머신이 스스로 데이터를 바탕으로 그 안에 있는특징과패턴을 찾아내는 것이다. - 과거의 머신러닝 정의:
- "머신러닝은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야" - Arthur Samuel (1959)
- "어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때, 경험 E로 인해 성능이 향상되었다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다" - Tom Mitchell (1997)
🖋 2. AI, ML, DL의 관계
- 인공지능 (AI): 기계가 사람의 지적 능력을 모방하는 것.
- 머신러닝 (ML): 학습을 통해 (사람처럼) 예측을 진행하는 것.
- 딥러닝 (DL): 사람의 인지 과정을 모방하는 것.
🖋 3. 명시적 프로그램과 머신러닝
명시적 프로그램 (Rule-Based Expert System)
- 문제를 해결하기 위한 규칙을 수동으로 사전에 정의하는 방법론.
- 장점:
- 처리 과정을 사람이 이해하기 쉬움.
- 작은 데이터에서 효과적.
- 단점:
- 특정 규칙은 한 분야나 작업에 국한됨.
- 변경에 대응하기 어려움.
- 규칙 설계 시 해당 분야의 전문가가 필요함.
머신러닝
- 데이터 내부에서 자주 발생하는
특징과패턴을 감지하여 문제를 해결하는 기법. - 장점:
- 예상치 못한 상관관계를 파악하는 데 탁월함.
- 특정 도메인에서 전문가가 필요하지 않음.
- 단점:
- 머신이 패턴을 파악할 수 있도록 다양한 데이터가 필요함.
- 결과 분석 과정에서 사람이 이해할 수 없는 포인트가 존재할 수 있음.
🖋 4. 머신러닝의 활용 사례
- 머신러닝은 다양한 어플리케이션과 연구 분야에서 활용된다. 특히 딥러닝의 발전으로 매우 다양한 분야에서 사용되고 있다.
- 추천 시스템: 영화, 음식, 쇼핑 등.
- FaceID: 얼굴 인식.
- 의료 영상 처리: 종양 진단, 병변 예측 등.
- 음성 처리: TTS, STT 등.
- 금융 데이터 예측: 수익 예측, 이상 거래 감지 등.
🖋 5. 머신러닝 프로젝트의 흐름
- 문제 정의: 파이프라인, 모델 입력/출력 정의.
- 데이터 확인: 시각화, 특성 파악.
- 데이터 분할: 학습, 검증, 테스트 데이터 분할 및 편향성 확인.
- 아웃라이어 제거.
- 알고리즘 탐색: 선행 연구 및 프로젝트 참고.
- 데이터 전처리: 알고리즘 고려, 선행 과정 참고.
- 학습과 검증: 최적 모델 탐색 및 반복 작업.
- 최종 테스트: 테스트 데이터 활용 및 보고.
- 시스템 런칭: 모니터링 및 유지 보수.
🖋 머신러닝 종류
🖋 레이블에 대한 이해
- 메타데이터: 주어진 기본 데이터에 추가적으로 제공되는 정보. 데이터의 출처, 형식, 위치 등의 관계와 구조를 파악하거나, 데이터의 속성, 특성, 분류 등을 설명하는 데 사용됨.
- 레이블: 특정 문제에 해당하는 데이터의 설명 혹은 답변을 의미.
- 분류 문제: 데이터가 속할 범주 (클래스).
- 회귀 문제: 데이터가 표현할 특정 숫자.
- 대부분 사람이 직접 생성해야 하는 경우가 많음.
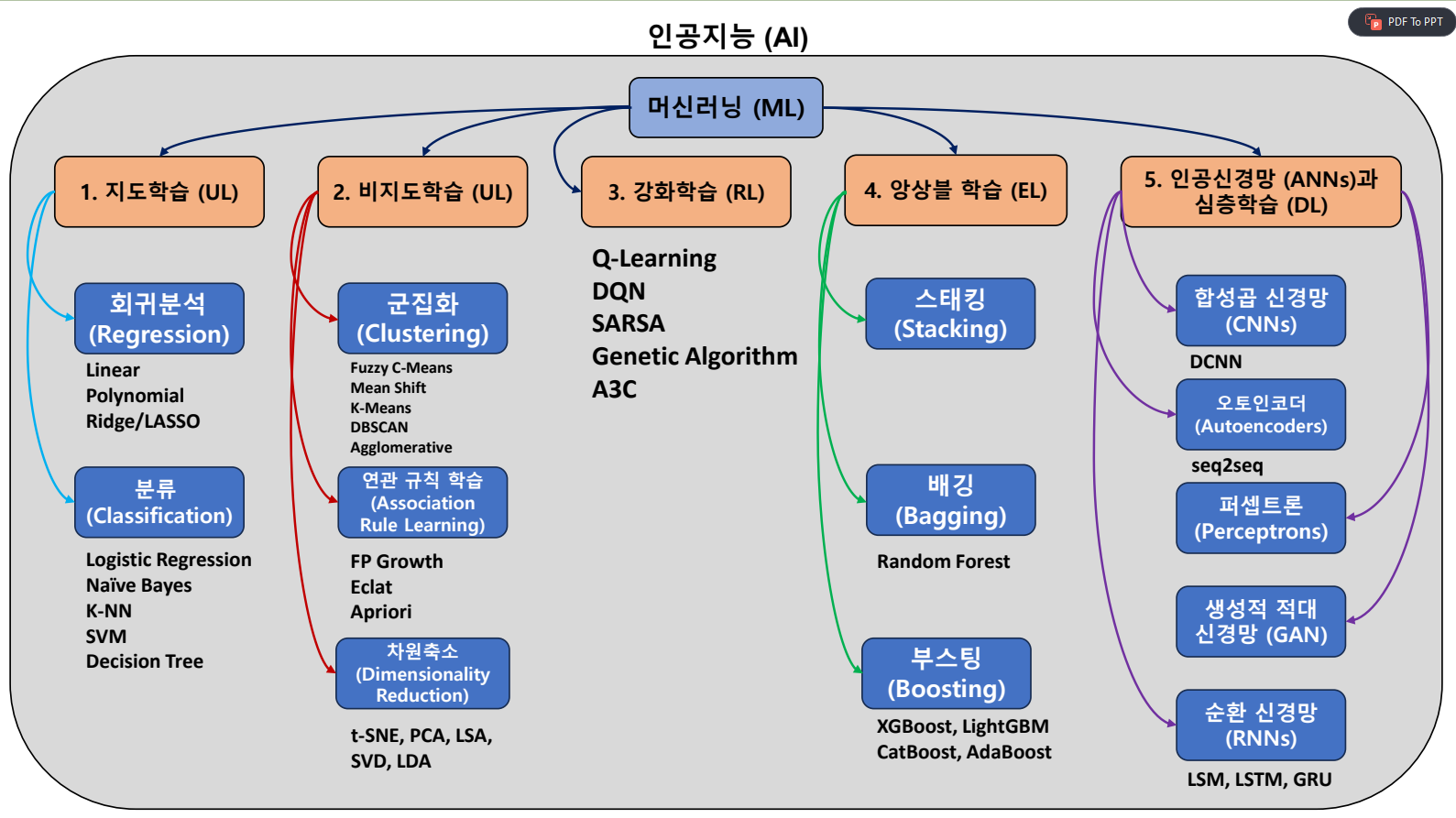 https://www.aieconlab.com/post/ml_category/
https://www.aieconlab.com/post/ml_category/
🖋 1. 지도학습 (Supervised Learning)
- 정의: 정답 레이블 정보를 활용해 알고리즘을 학습하는 방법론.
- 특징 및 장점:
- 정답이 존재하므로 모델이 풀어야 하는 문제가 비교적 쉽고 잘 학습됨.
- 명확한 평가 수치가 존재하며, 학습된 모델의 성능을 쉽게 측정할 수 있음.
- 단점:
- 정답을 매기는 데 추가적인 시간, 노동, 비용이 필요함.
- 정답을 매기는 행위에 필요한 전문 인력 등 추가 비용이 발생함.
🖋 2. 비지도학습 (Unsupervised Learning)
- 정의: 정답 레이블 정보가 없이 입력 데이터만을 활용해 알고리즘을 학습하는 방법론.
- 특징 및 장점:
- 정답을 따로 준비할 필요가 없어 비용적인 이점이 있음.
- 사용자가 의도한 패턴 외의 새로운 패턴을 찾을 가능성이 있으며, 창작과 같은 다양한 활용 분야에 사용할 수 있음.
- 단점:
- 학습된 모델의 성능을 측정하기 위한 기준이 없어 결과 해석이 주관적일 수 있음.
- 신뢰할 수 있는 결과를 얻기 위해 다수의 데이터가 필요함.
🖋 3. 준지도학습 (Semi-Supervised Learning)
- 정의: 일부의 데이터만 정답이 존재하고, 다수의 데이터에는 레이블이 없는 상황에서 알고리즘을 학습하는 방법론.
- 특징 및 장점:
- 레이블이 부족한 데이터셋에서 유용함.
- 많은 데이터를 활용할 수 있으므로 일반화 성능을 향상시킬 수 있음.
- 단점:
- 품질이 낮은 레이블이나 데이터 존재에 특히 취약할 수 있음.
- 알고리즘의 복잡성이 증가하며, 구현 및 활용에 어려움이 있을 수 있음.
🖋 4. 자기지도학습 (Self-Supervised Learning)
- 정의: 정답이 하나도 없는 데이터에서, 정답을 강제로 생성 후 학습하는 방법론.
- 특징 및 장점:
- 레이블 없이 데이터의 특징을 파악할 수 있음.
- 다양한 데이터에 활용할 수 있음.
- 단점:
- 목적하는 문제를 직접적으로 해결하는 것이 아니므로 추가적인 학습 과정이 필요할 수 있음.
- 알고리즘이 잘못된 패턴을 학습할 위험이 있음.
🖋 5. 강화학습 (Reinforcement Learning)
- 정의: 어떤 환경(Environment)에서 상호작용하는 에이전트(Agent)가 보상(Reward)을 이용해 특정 행동을 하도록 유도하는 학습 방법론.
- 특징 및 장점:
- 실시간으로 최적의 행동을 학습함.
- 주로 게임, 로보틱스, 자율주행 등에서 사용됨.
- 단점:
- 학습에 많은 시간과 계산 자원이 필요함.
- 불확실한 환경에서 예측하기 어려운 행동을 할 수 있음.

Data Analyst Challenge