AI를 활용한 창원시 치안지도 서비스
1.AI를 활용한 창원시 치안지도 서비스 - (0) Prologue
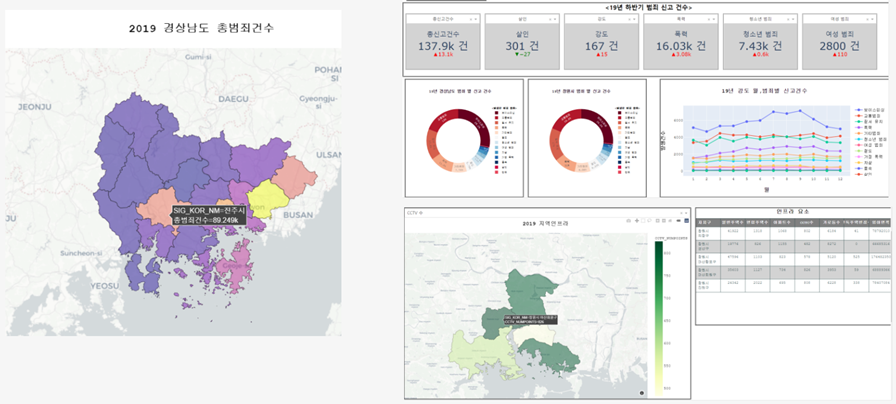
최종 화면은 아니고 각 페이지들을 이어 붙여서 만든 사진이다.내가 맡았던 파트의 최종 구성 화면이다.
2023년 3월 25일
2.AI를 활용한 창원시 치안지도 서비스 - (1) 치안기사분류 (BERT)

모델 학습을 위한 뉴스데이터 크롤링은 '경남신문'과 '아시아경제' 웹사이트에서 실시하였다. 일반적으로 뉴스 사이트에서 치안 관련 카테고리를 따로 만들어두고 있지 않기 때문에 뉴스 사이트 검색창에 '치안'을 검색하여 크롤링한 뉴스 데이터들을 치안 관련 뉴스라 하기로 하였
2023년 2월 10일
3.AI를 활용한 창원시 치안지도 서비스 - (2) 뉴스 기사에서 지역 추출
rhinoMorphExtension의 findKeywordSentences 메서드를 활용하여, 기사 내용들만 들어있는 리스트를 순회하며,region 리스트에 들어있는 지역별로 분류한다. 현재 지역분류에 담겨있는 내용들은 리스트로서 동작하는 것이 아니라 '문자열'이다.이
2023년 3월 23일
4.AI를 활용한 창원시 치안지도 서비스 - (3) 뉴스 기사에서 키워드 추출
TextRank 알고리즘 : 각각의 단어를 정점(point)으로 잡고, 한 문장 내에서 같이 등장하는 동시 출현 빈도를 가지고 PMI(단어의 중요도) 도출
2023년 3월 23일
5.AI를 활용한 창원시 치안지도 서비스 - (4) 지역, 키워드 도출 결과 병합 & 창원 구별 top 5 키워드 도출
Google colab키워드 도출 결과와 지역 도출 결과를 불러와서 기사내용을 key로 해서 Inner Join한다.지역별로 기사 할당하기 위해 explode 메서드 사용이제 구별 Top5 키워드를 도출한다. 아래는 의창구 Top5 키워드 도출 과정이다.최종적인 결과물
2023년 3월 25일