Tools
- Google colab
- TextRank
주요 코드 분석
경로설정, 패키지 설치 코드는 생략한다.
TextRank 알고리즘 : 각각의 단어를 정점(point)으로 잡고, 한 문장 내에서 같이 등장하는 동시 출현 빈도를 가지고 PMI(단어의 중요도) 도출
텍스트랭크 구현 코드는 아래 사이트를 참고하였다.
https://bab2min.tistory.com/570
TextRank 생성자는 인수로 window, coef, threshold를 받는다.
-
window : 문맥으로 사용할 단어의 개수. 기본값 5로 주면 특정 단어의 좌우 5개씩, 총 10개 단어를 문맥으로 사용함.
-
coef : 동시출현 빈도를 weight에 반영하는 비율. 기본값은 1.0로, 동시출현 빈도를 weight에 전부 반영함. 0.0일 경우 빈도를 반영하지 않고 모든 간선의 weight을 1로 동일하게 간주.
-
threshold: 문서 요약시 관련있는 문장으로 여길 최소 유사도값. 기본값은 0.005이고, 이 값보다 작은 유사도를 가지는 문장쌍은 관련없는 문장으로 처리.
#뉴스가 담긴 엑셀 불러오기
news = pd.read_csv('치안뉴스.csv')
news = news.rename(columns={'0':'기사제목','1':'기사내용','2':'기사URL'})
data2 = news['기사내용'].tolist()키워드 추출
#키워드 추출시에는 load로 문장을 읽어들이고, extract로 키워드를 추출
for i in range(0,len(data2)):
tr = TextRank(window=5, coef=1)
print('Load...')
stopword = set([('있', 'VV'), ('하', 'VV'), ('되', 'VV'), ('없', 'VV') ])
tr.load(RawTagger(data2[i]), lambda w: w not in stopword and (w[1] in ('NNG', 'NNP')))
print('Build...')
tr.build() #단어연관성분석
tr.extract(0.3) #추출비율키워드가 필요하기 때문에 NNG(일반 명사), NNP(고유 명사)를 추출한다.
#데이터프레임 만들기
df = pd.DataFrame(data2)
df['keyword'] = None
for i in range(0,len(df)):
df['keyword'][i] = keywordlist[i].copy()
df = df.rename(columns={0:'기사내용'})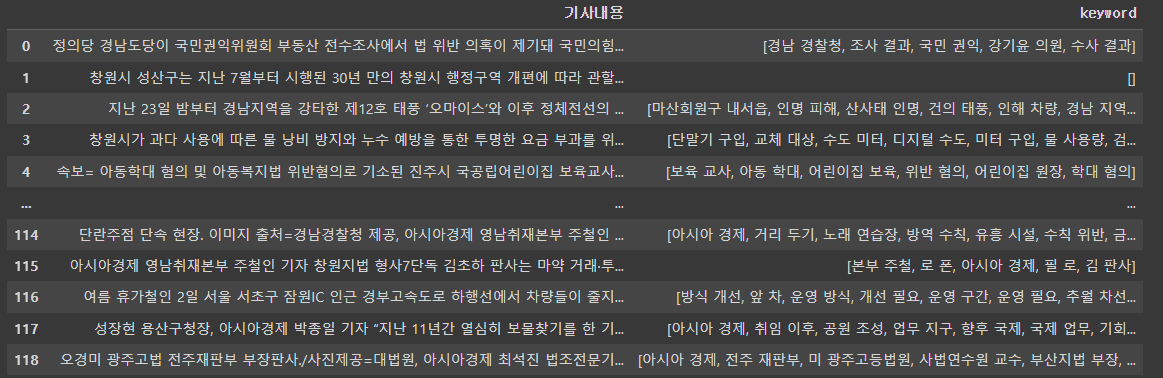

Frontend & Artificial Intelligence